

NCCL源码解析③:机器内拓扑分析
source link: https://blog.csdn.net/OneFlow_Official/article/details/130418182
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

NCCL源码解析③:机器内拓扑分析

更新|潘丽晨
上节介绍所有节点执行了bootstrap网络连接的建立,接下来介绍下拓扑分析。
由于GPU机器架构是多种多样的,一台机器上可能有多个网卡,多个GPU卡,卡间连接也各不相同,因此需要对机器内设备连接拓扑进行分析,以使性能在各种拓扑结构下都尽可能好。
接着上回继续看initTransportsRank。

创建nrank个allGather1Data,然后通过fillInfo 填充当前rank的peerInfo,ncclPeerInfo是rank的一些基本信息,比如rank号,在哪个机器的哪个进程等。
获取当前卡的rank,PCIe busId,/dev/shm的设备号,填充到ncclPeerInfo,然后通过ncclGpuGdrSupport查看是否支持gdr,rdma在通信前需要注册一段内存,使得网卡知道虚拟地址和物理地址的映射,但是如果每次通信都需要将data从显存拷贝到内存再通信的话效率就比较低。
而IB提供了peer memory的接口,使得ib网卡可以访问其他PCIe空间,nv基于peer memory实现了自己的驱动,使得rdma可以直接注册显存,这样通信就可以避免host和device的内存拷贝,IB可以直接dma显存,即gdr。
这里会遍历每一个网卡,获取网卡的信息,由第一节可以知道这里的ncclNet就是ncclNetIb。
这里主要是获取网卡名,PCIe路径,guid等信息,然后查看是否有/sys/kernel/mm/memory_peers/nv_mem/version判断是否安装了nv_peermem,即nv的驱动,如果安装了的话则设置props->ptrSupport |= NCCL_PTR_CUDA,表示可以注册显存。
然后尝试注册显存,如果可以注册则设置gdrSupport为1,这里其实会创建rdma连接,这个在后边会单独介绍,本次先略过。
然后bootstrapAllGather广播allGather1Data,将获取到的其他节点peerinfo拷贝到comm里。
在看具体拓扑分析流程之前先简单了解一下PCIe的一些概念,一个简单的PCIe系统示例如下。
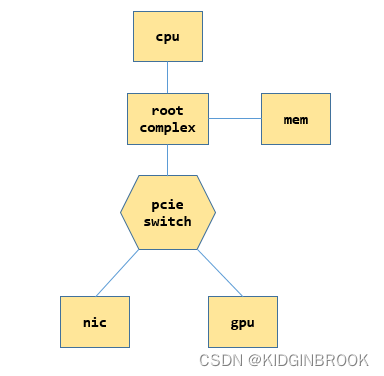
每个CPU都有自己的root complex,后简称为RC,RC会帮助cpu和其他部分通信,比如和内存,和PCIe系统,当cpu发送过来一个物理地址之后,如果这个地址是在PCIe空间,会被RC转换成PCIe请求进行通信。
switch的作用是扩展PCIe端口,下边可以连接设备或者其他switch,上游来的请求被被他转发,PCIe设备可以连在RC,也可以连在swtich,一个switch的内部如下所示。
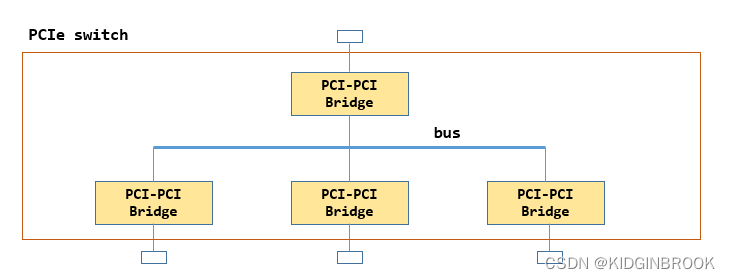
内部有一个PCIe总线 ,然后通过多个Bridge扩展出多个端口,其中上边的那个称为上游端口,其他的叫做下游端口。
前文有提到NCCL中很常用的一个变量名叫busId,比如gpu和ib网卡,注意区分NCCL里的busId并不是指的总线号,指的其实是定位一个PCIe设备用到的id,即BDF(bus + device + function),一个bus上有多个设备,一个设备有多个功能,因此通过BDF就可以定位一个设备,在机器启动完成PCIe的配置之后会将相关信息通过sysfs提供给用户,NCCL就是通过sysfs来完成拓扑检测的。
然后看下执行的ncclTopoGetSystem,这个函数就是本节的重点,会将当前rank的PCI树建立起来,分为两个步骤,先使用xml表示整个PCI树结构,然后基于xml转成ncclTopoNode,其中xml定义如下,一个ncclXmlNode表示了PCI树的一个节点。
ncclXmlNode表示一个节点,记录了父节点和所有子节点,节点有name和attr,通过xmlSetAttr进行设置属性。
ncclXml中预分配了所有的node,maxIndex表示分配到了哪里,然后简单介绍下几个xml相关的api。
static ncclResult_t xmlAddNode(struct ncclXml* xml, struct ncclXmlNode* parent, const char* subName, struct ncclXmlNode** sub);xmlAddNode进行node的分配,表示在xml里新申请一个节点sub,sub的name设置为subName,父节点为parent。
static ncclResult_t xmlFindTagKv(struct ncclXml* xml, const char* tagName, struct ncclXmlNode** node, const char* attrName, const char* attrValue)xmlFindTagKv会遍历xml已分配的节点,找到节点名为tagName的节点n,然后判断节点n["attrName"]是否等于attrValue,如果相等,则设置node为n。
static ncclResult_t xmlGetAttrIndex(struct ncclXmlNode* node, const char* attrName, int* index)xmlGetAttrIndex会查看attrName是node的第几个属性。
然后开始看拓扑分析的过程。
首先通过xmlAddNode创建根节点"system"(后续使用双引号表示xml树节点),并设置根节点属性"system" ["version"] = NCCL_TOPO_XML_VERSION,然后遍历每个rank的hosthash,如果相等的话说明在同一个机器,然后执行ncclTopoFillGpu,将gpu加入到xml树。
通过ncclTopoGetPciNode获取xml中的有没有创建当前卡的xml node,此时没有,所以就新建一个xml node叫做"pci",表示当前gpu卡,设置"pci"["busid"]=busd。
然后执行ncclTopoGetXmlFromSys,这个函数主要逻辑就是在sysfs中获取gpu节点到cpu的路径,通过这个路径转成xml树,并读取该路径下相关属性设置到xml里。
首先设置pciNode的各种属性,通过getPciPath获取busId对应的sysfs路径path,其实这个路径就是PCI树中根到叶结点的路径。
举个例子比如path是 /sys/devices/pci0000:10/0000:10:00.0/0000:11:00.0/0000:12:00.0/0000:13:00.0/0000
:14:00.0/0000:15:00.0/0000:16:00.0/0000:17:00.0,其中GPU的busId是0000:17:00.0,那么这个path对应下图,注意,下图略去了15:00.0对应的switch。
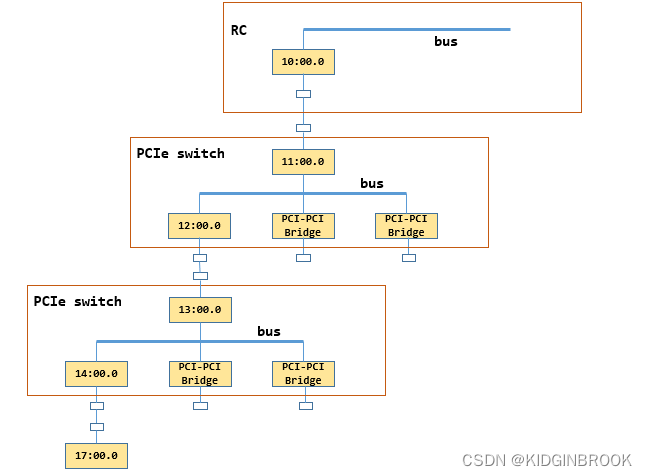
然后读取path下的属性,获取class(PCI设备类型),link_speed,link_width等设置到xml pciNode中,ncclTopoGetStrFromSys其实就是读取path下的内核文件保存到strValue。
然后从pciNode开始往上跳,因为一个switch的上游端口和下游端口分别对应了一个bridge,NCCL使用上游端口bridge的busid表示这个switch,因此这里要向上跳两次再建立一个xml node表示这个switch,往上找到一个PCI设备就将slashCount加一。
当slashCount==2就找到了一个switch上游端口,这个时候创建一个新的xml pci节点parent表示当前switch,然后将当前节点pciNode链接到parent,此时parent仍然是xml pci节点。
因此,继续递归执行ncclTopoGetXmlFromSys,直到遇到RC,此时给"system"创建一个子节点"cpu",停止递归,然后执行ncclTopoGetXmlFromCpu,设置"cpu"的各种属性,比如arch(比如x86还是arm),affinity(该cpu的numa都有哪些cpu core),numaid等。
到这里ncclTopoGetXmlFromSys就执行结束了,接着看ncclTopoFillGpu。
然后通过wrapNvmlSymbols加载动态库libnvidia-ml.so.1,用来获取gpu的相关信息。
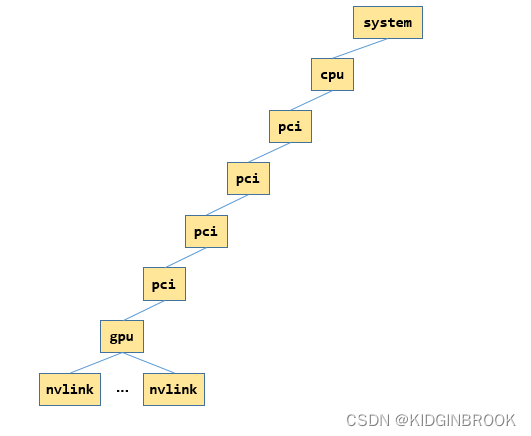
首先在xml gpu节点"pci"下创建节点"gpu",然后设置"gpu"节点的属性,比如dev,计算能力sm,然后开始查询nvlink相关信息,遍历所有可能的nvlink,通过nvmlDeviceGetNvLinkCapability查询nvlink信息。
如果这个nvlink被启用,那么在"gpu"节点下新建一个"nvlink"节点,设置"target"属性表示nvlink对端的PCIe busId,将"target"相同的"nvlink"节点表示为一个,用"count"表示起止点之间有多少条nvlink,然后设置属性"tclass"表示"target"是什么类型的PCI设备。
到这里ncclTopoFillGpu就执行结束了,此时xml如下所示,图里只展示了一张网卡的情况,其中"gpu"和他的父节点其实都是指的同一个gpu。
然后回到ncclTopoGetSystem,会设置"gpu"的rank和gdr属性。
然后是对于所有的网卡,类似上述gpu的过程,通过ncclTopoGetXmlFromSys建立xml树,如下所示,只展示一张网卡的情况,其中"net","nic"和"nic"的父节点都表示同一张网卡。
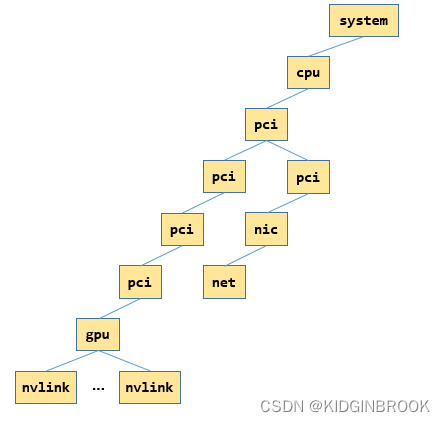
总结一下,本节主要介绍了NCCL拓扑分析的过程,通过sysfs将gpu和网卡对应的pci树结构建立出来了xml树。
https://blog.csdn.net/KIDGIN7439/article/details/126990961)
其他人都在看
欢迎Star、试用OneFlow: github.com/Oneflow-Inc/oneflow/
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK