

大模型在金融AIGC领域的前景与应用
source link: https://blog.csdn.net/csdnnews/article/details/130006506
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

随着大模型技术的火爆,人们在思考如何借助 AI 提高编程效率的同时,也在思考 AI 对各行各业都会带来怎样的影响。在 CSDN 与《新程序员》合作举办的「新程序员大会(NPCon)——AIGC 与大模型技术应用论坛」上,来自文因互联工程 VP 兼首席科学家宋劼带来了《探索新技术之大模型在金融 AIGC 领域的前景与应用》的精彩分享。
直播回放地址:https://live.csdn.net/room/programmer_editor/Nc8cfWuo
宋劼提出可以从构造领域语言模型(DLM)、建立并整合领域 Prompt(提示、指令)集、运用 RLHF 的基本原理和降低对进口硬件的依赖等多个方面入手,以有限预算在领域应用落地类 ChatGPT 应用,最终创建一个 FD-LLM(金融领域大模型)。

以下是宋劼的演讲全文:
下午大家下午好,很高兴能来到现场,就我们最近在金融 AIGC 领域的一些前景和应用的思考和大家进行一些分享。
文因互联主要是为金融机构提供相应的,基于自然语言处理,还有知识图谱的解决方案。我们所做的事情其实归纳起来,主要为四个部分。
首先就是文档解析,因为我们知道在金融领域其实存在着大量的非结构化数据,包括 PDF 、Word 等等,在里面有海量的知识,我们负责把这些海量知识去给解析出来,进而迸发出这些数据存在的潜力。
第二步,就是知识的抽取,自动采集关键信息,然后将文本进行具体的。结构化处理,以进一步去促进整个的文本的处理流程,还有自动化。
第三,文档的审核,这样可以保证文档的完整性一致性。
最后,底稿的生成,包括定制式和非定制式底稿生成,协同编辑,边写边搜,一键改写等。
下面我通过回顾 AI 历史来理解 ChatGPT 的贡献。在 2022 年 3 月 15 号创新工厂总部的一场会上,李开复老师提到了说我们正迎来了 AI 1.0 到 AI 2.0 的新机遇,AI 1.0 就是以卷积神经网络开启的感知智能时代,那是的瓶颈就是我们需要有大量的标注数据,并且很难行程一个规模化效应。
如今,AI 2.0 时代已经来临,就是 ChatGPT 给大家带来的冲击,就是我们可以基于这样的基础大模型去进行进一步下层下游任务的构建。同时它也可以以一种非常简单的方式让我们所有的人都可以参与进来。
在 2020 年的时候,张博院士曾经发过一个文章,叫做迈向第三代人工智能。当时他提到了人工智能的四要素就是知识,它已经提到了一个非常重点的位置,在这个时候呢,就代表着认知智能的一个开启。但是呢,我们又仔细回顾了一下,我们觉得现在可能已经是 AI 4.0 时代了。
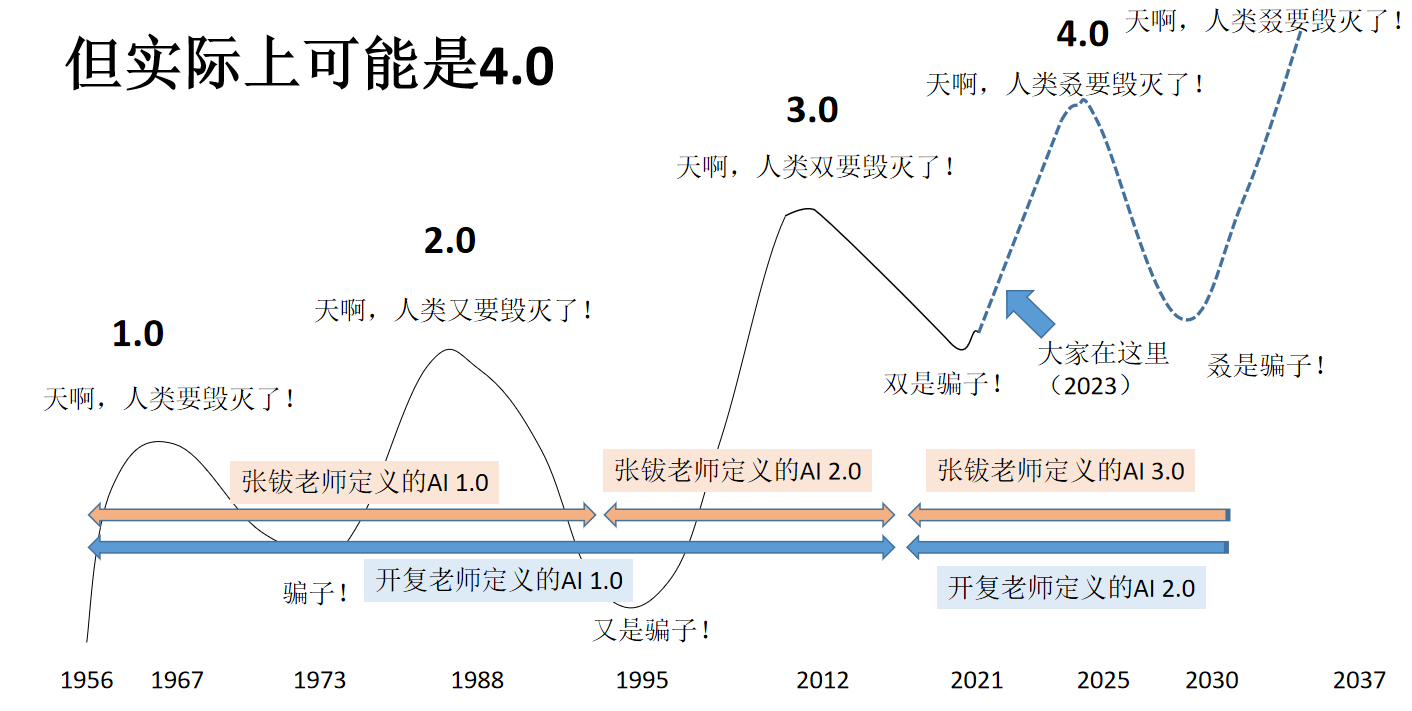
该图是我们 CEO 鲍捷老师经常用的一幅图,在去年的时候呢,AI 整个行业都开始已经面临了一个寒冬,因为在商业化的落地上遇到了一个非常大的瓶颈。
伴随 ChatGPT 的诞生,AI 的春天有来临了。这个对于所有 AI 从业者来说,都是一件非常值得兴奋的事情。在 2022 年的时候,我们发现历史的车轮回到了认知智能的时代,而且甚至出现了智能的涌现。
下面回顾一下 AI 的几个关键时刻:
- 1997年,IBM 推出了深蓝,让机器可以记住大量的现有策略,并高效运用;
- 2011年,Watson 诞生,可以让机器在一个特定的任务下去阅读和评估知识的可信度;
- 2016年,AlphaGo的出现是真正的让人工智能走入了人工大家的一个视野,完全信息博弈机器可以胜任,机器可以发现策略;
- 2022年,ChatGPT 的出现让我们看到,机器可以阅读、掌握不限领域的知识,进行逻辑推理——开放域知识,不完全信息博弈。
当初GPT诞生时,大家把它称为“Gaint Parrot Talking”,也就是“鹦鹉学舌”,因为它本质上是一个语言模型,通过统计方法学习人类语言的使用方式。然而,今天我们发现,它已经具备了初步的“乌鸦智能”定义。就像这只乌鸦一样,它想要打开一颗核桃,但它无法用自己的力量完成,于是它想到了用一辆车将核桃压碎。然而,如果车流量很大的话,它就有可能被压死。因此,乌鸦经过一系列严密的观察后,决定在红灯亮起时,在人行道上放置核桃。这样,当车经过时,红灯会让车停下来,乌鸦就可以安全地过去了。在这个过程中,乌鸦需要进行推理和融合大量知识,同时需要具备一定的逻辑能力和进行四维链推断的能力。而且,它没有试错的机会。这说明,从AI到AGI的领域,我们正在实现从鹦鹉智能到乌鸦智能的过渡,但是我们还没有完全达到目标。
但 ChatGPT 可以说是一个里程碑和强心剂,让更多的人愿意涌入到这个领域。从 2013 年神经网络的出现,包括到 2017 年的 Transformer 到 2020 年的大型语言模型、2022 年的 LLM+强化学习。
在2022年,我们发现机器越来越能够像人类一样进行思考。而ChatGPT最成功的一点在于,它可以基于人类的反馈进行强化学习。ChatGPT并不仅仅是一种庞大的语言模型,更重要的是,它在每一步走向中都会关注人类的反馈,并融合人类的知识,从而更符合人类的要求。虽然它可能不会给出完全正确的答案,但它给出的答案却是最符合人类需求的。它成为了我们的助手和陪伴者,它的存在扩展了我们的思维能力。在这个过程中,最重要的人是那些提问的人。我们也预见到第三代文字处理的革命即将到来,机器将变得更加人性化。那么,在这件事情发生之后,我们一直在思考如何应对。由于我们一直在金融领域工作,所以我们也有一些特殊要求,比如数据隐私、保密性以及对各种规定的严格遵守。
在 TO B 的场景下呢,其实还会面临以下的四种方面,是目前 ChatGPT 还是有一定的局限性的。
-
知识层面上,ChatGPT 缺少知识驱动,对领域问题依然有理解瓶颈。
-
可行层面上,ChatGPT 仍然是一个黑盒模型,不仅计算过程不可解释,产出也不可信。
-
数据层面上,通用大模型本身在数据适配性、合规性和安全性上,针对 ToB 场景应用依然具有限制。
-
成本层面上,大模型的稳定训练并实现优异性能需要极高的计算成本和工程实现能力。
在整个金融领域的深度优化中,我们可以聚焦于四个方面。首先是精准训练,这个过程中我们要特别注意避免不合规的内容污染。其次,研报和公告的重要性会被提到前面,而对于金融财经的舆情新闻,其重要性会被降低。在提示方面,我们采用基于场景的提示学习,建立金融场景的promote指令,并将其收集在一起供应用和复用。鉴于我们的模型还比较小,我们可以在企业内部部署并保证私有化。
在现在的场景下,这种方式的原来顺序会要进行一些调整,但最终在给交付给客户的时候,我们一定要保证可溯源,可置控。
现在我将介绍我们在金融领域的实践。在过去五年中,我们已经深入研究了金融业的各个领域和环节,包括决策、知识、知识分析、知识挖掘和知识抽取等。在当前的环境下,我们能够以更广泛、更深入和更快的方式为我们的业务伙伴提供赋能服务。
我们将所有任务归为五大类:知识抽取、知识搜索、知识生成、知识分类和知识问答。我们期望将金融业务知识与 GPT 类的大型模型相结合,以极大地提高监管、合规、客服、运营和营销的效率。在模型训练方面,我们使用业务知识来建立 GPT 模型,并对其进行训练,使其能够理解业务,基于此解决业务问题。在知识建模方面,我们将业务知识与 GPT 模型相结合,以针对银行、证券、保险等复杂的业务知识进行建模,并根据实际业务需求自动生成相应的解决方案的初稿。在智能方案层面使用 GPT 模型,可以自动生成业务报告,并针对业务问题提出建议和解决方案。最终,我们的影响可以概括为三点:真正的智能交互、真正的智能运营和真正的智能撰写。
在监管层面呢,我们肯定会积极地跟进,在过去五年中,我们参与了所有监管环节,了解到上交所从 2017 年开始、北交所从 2020 年开始积极推进基于机器阅读的监管全流程自动化。当我们和上交所合作时,他们的团队每天只能处理九类公告,而现在已经能够处理 200 多类公告和各种招股说明书,全部由机器自动处理。在过去六年中,成本已经降低了不止十倍,而未来几年在新技术的加持下,自动化和智能化的覆盖程度肯定会进一步提升,成本甚至可能降低百倍。
在监管层面,数据的托管和权益分配是至关重要的。我们将在 AIGC 层面的所有工作分为三类:读、写、查。在读取方面,我们使用自然语言处理来建立端到端的任务学习,并提高整体的泛化能力,以服务于复杂金融文档的信息处理和理解。例如,在科创板审核中,我们使用机器自动提取了 7000 多个数据点。在写作方面,我们使用交互式的 AIGC,提供自动生成的知识文档和代码,服务于投顾投研、资产配置、资讯营销等领域。我们正在进行的研发包括自动生成招股说明书、研究报告的观点聚合等内容。
举例来说,在科创板审核过程中,我们可以用机器自动提取7000多个数据点。在写的方面,我们通过交互式的AIGC,提供了知识文档和代码的自动生成功能,服务于投顾、投研、资产配置和资讯营销等场合。例如,我们正在进行招股说明书的自动写作和研报观点聚合等方面的研发。在查的方面,我们实现了对文档目录、全文摘要、研报和速读的解析,以及图表搜索和热点趋势聚合等功能。同时,我们结合了内部私有化的知识库和大型GPT模型,实现了文档智能阅读,以提高企业内部的协同效率。我们也在针对金融领域的私有化解决方案进行研发,以满足更高的安全性和私密性需求。我们期望AIGC能广泛应用于各个场景,特别是在报告生成方面,以提高效率和准确性。最后,我们强调最后一公里的把控需要交给人来完成,以确保整个机制的完整性。
刚才提到的自动生成招股说明书等文档的功能,虽然极大地提高了效率,但最终内容的准确性和合规性仍需要保证。因此,我们为此引入了AI小助手,其主要任务是协助人工对自动生成的文档进行最终的审校和把控。这样的做法既确保了文档内容的正确性和合规性,又充分利用了AI技术的高效性,实现了人机协同,进一步提升了工作效率和效果。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK