

Meta开源多感官大模型,AI用6种模态体验虚拟世界,听引擎声就会画汽车
source link: https://www.36kr.com/p/2251704915963784
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Meta最新6模态大模型,让AI以更接近人类的方式理解这个世界。
比如当你听见倒水声的时候就会想到杯子,听到闹铃声会想到闹钟,现在AI也可以。
尽管画面中没有出现人类,AI听到掌声也能指出最有可能来自电脑。

这个大模型ImageBind以视觉为核心,结合文本、声音、深度、热量(红外辐射)、运动(惯性传感器),最终可以做到6个模态之间任意的理解和转换。
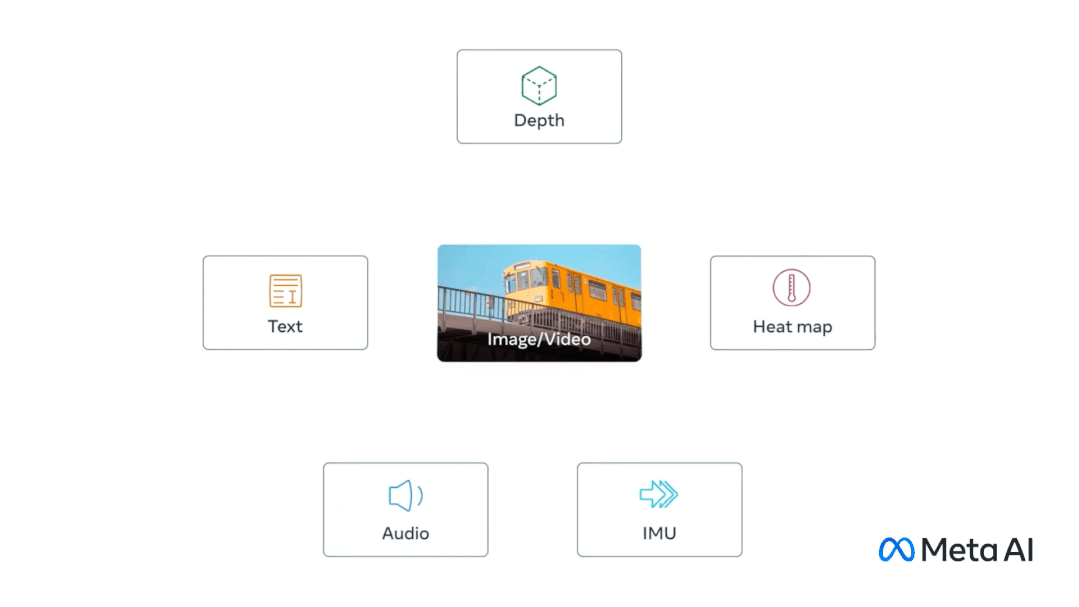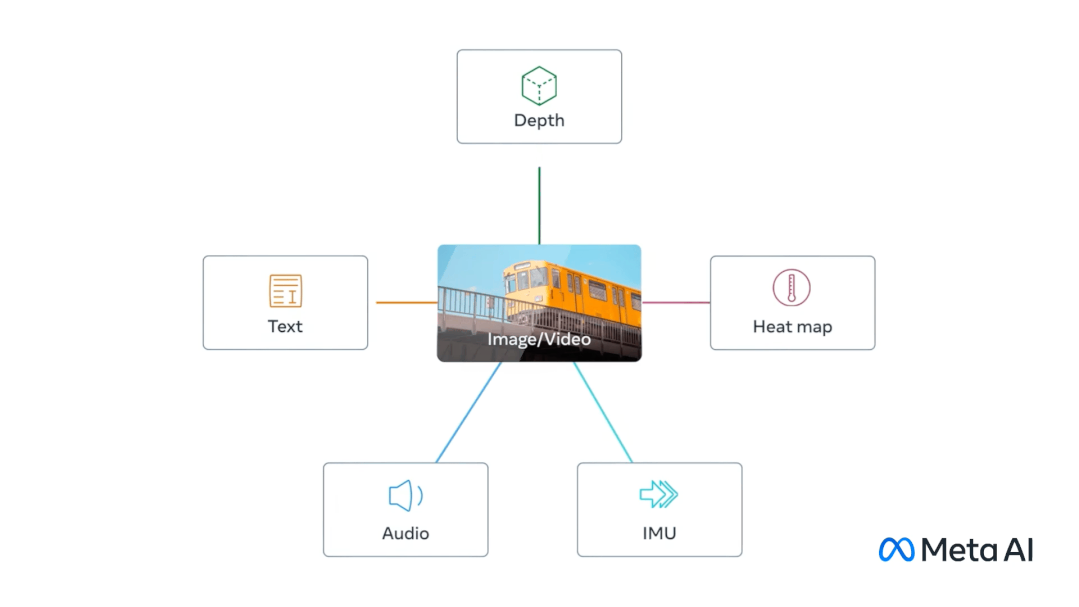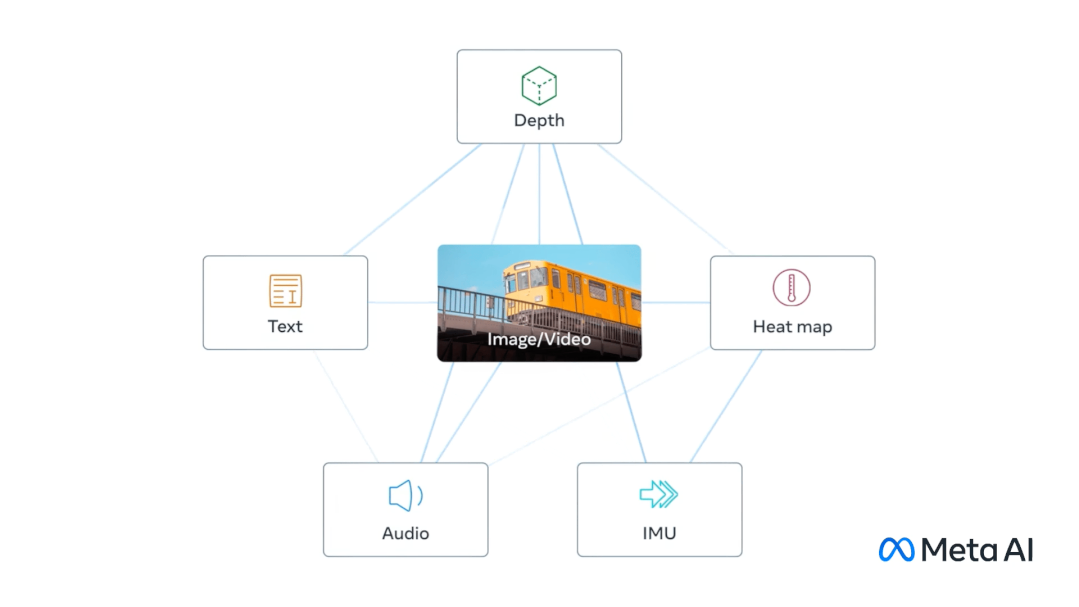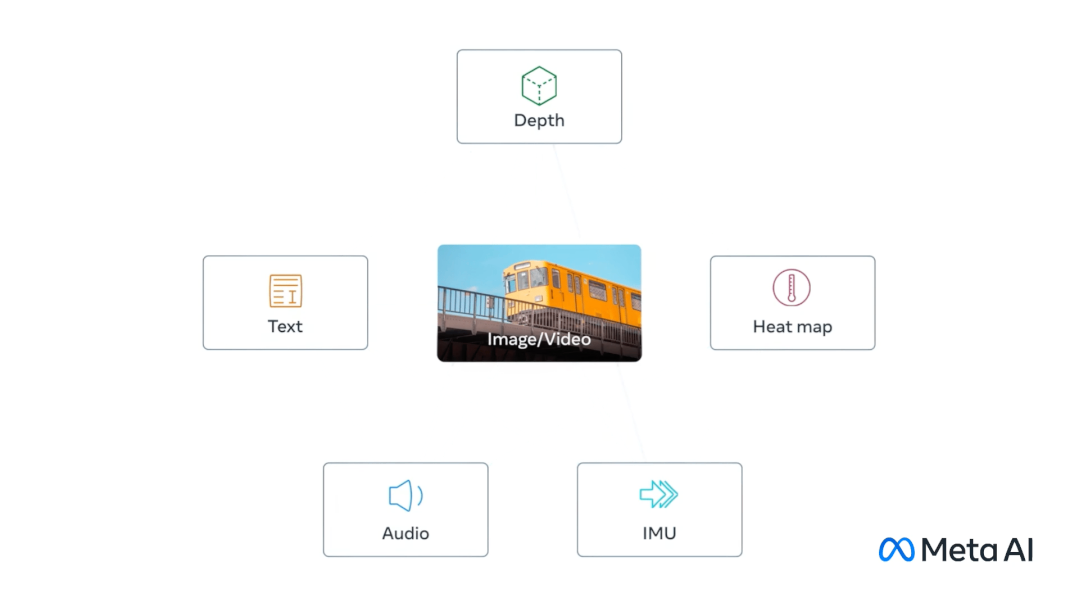
如果与其他AI结合,还可以做到跨模态的生成。
比如听到狗叫画出一只狗,同时给出对应的深度图和文字描述。
甚至做到不同模态之间的运算,如鸟的图像+海浪的声音,得到鸟在海边的图像。

团队在论文中写到,ImageBind为设计和体验身临其境的虚拟世界打开了大门。
也就是离Meta心心念念的元宇宙又近了一步。
网友看到后也表示,又是一个掉下巴的进展。
ImageBind代码已开源,相关论文也被CVPR 2023选为Highlight。

生成理解检索都能干
对于声音-图像生成,论文中透露了更多细节。
并不是让AI听到声音后先生成文字的提示词,而是Meta自己复现了一个DALL·E 2,并把其中的文本嵌入直接替换成了音频嵌入。

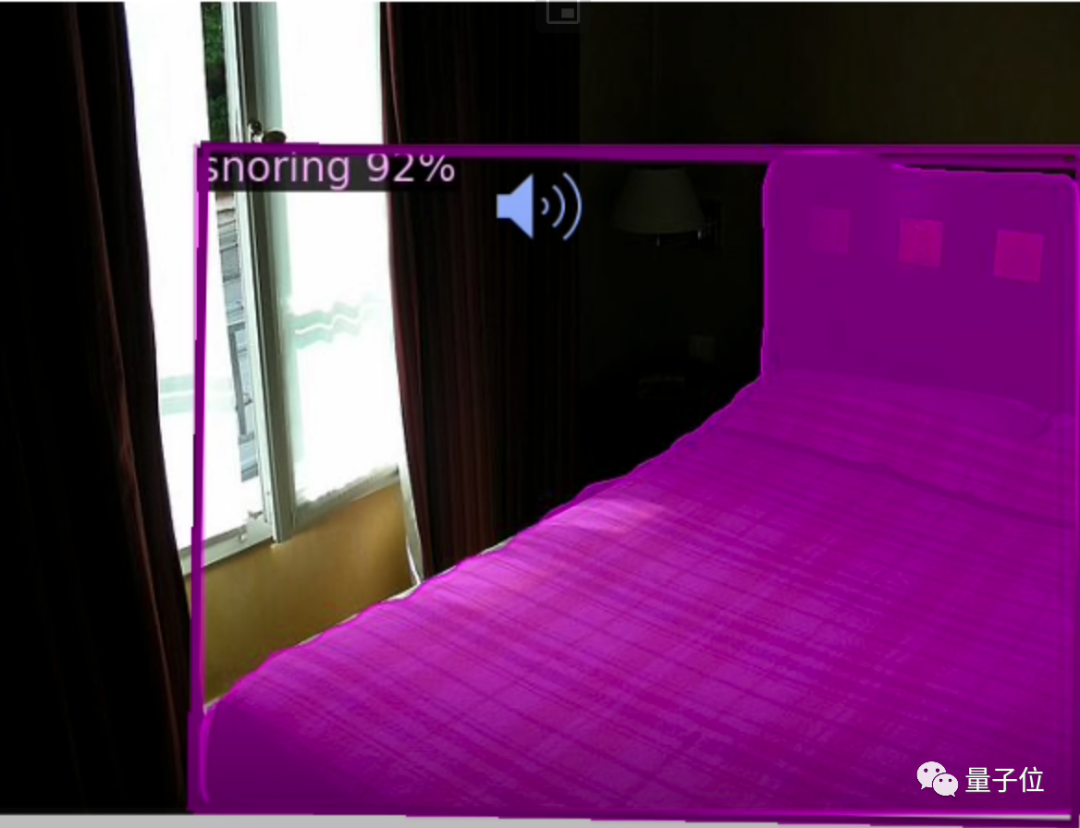
结果就是AI听到雨声可以画出一张雨景,听到快艇发动机启动声可以画出一条船。

如果想看更多示例,这里也放上论文的补充视频。
其中比较有意思的是,床上没有人,但AI也认为打呼噜声应该来自床。
ImageBind能做到这些,核心方法是把所有模态的数据放入统一的联合嵌入空间,无需使用每种不同模态组合对数据进行训练。

并且用这种方法,只需要很少的人类监督。
如视频天然就把画面与声音做了配对,网络中也可以收集到天然把图像和文字配对的内容等。
而以图像/视频为中心训练好AI后,对于原始数据中没有直接联系的模态,比如语音和热量,ImageBind表现出涌现能力,把他们自发联系起来。
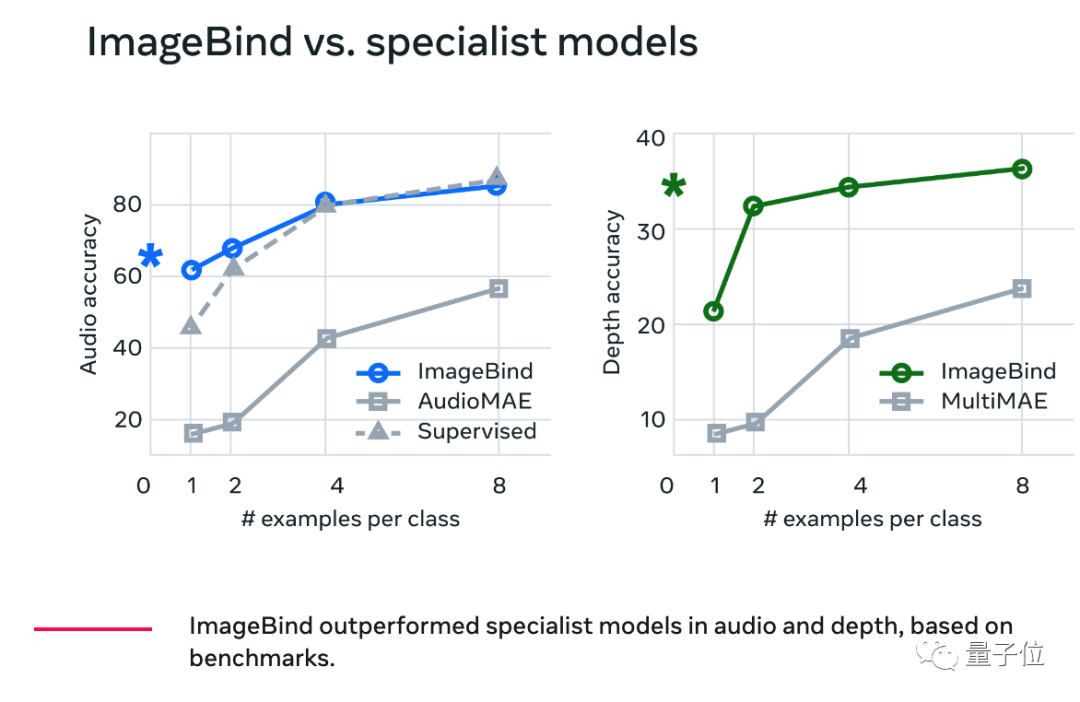
在定量测试中,统一多模态的ImageBind在音频和深度信息理解上也超越了对应的专用模型。
Meta团队认为,当人类从世界吸收信息时,我们天生会使用多种感官,而且人仅用极少数例子就能学习新概念的能力也来自于次。
比如人类在书本中读到对动物的描述,之后就能在生活中认出这种动物,或看到一张不熟悉的汽车照片就能预测起发动机的声音。
过去AI没有掌握这个技能,一大障碍就是要把所有可能的模态两两组合做数据配对难以实现。
现在有了多模态联合学习的方法,就能规避这个问题。
团队表示未来还将加入触觉、语音、嗅觉和大脑 fMRI,进一步探索多模态大模型的可能性
对于目前版本,Meta也放出了一个简单的在线Demo,感兴趣的话可以去试试。
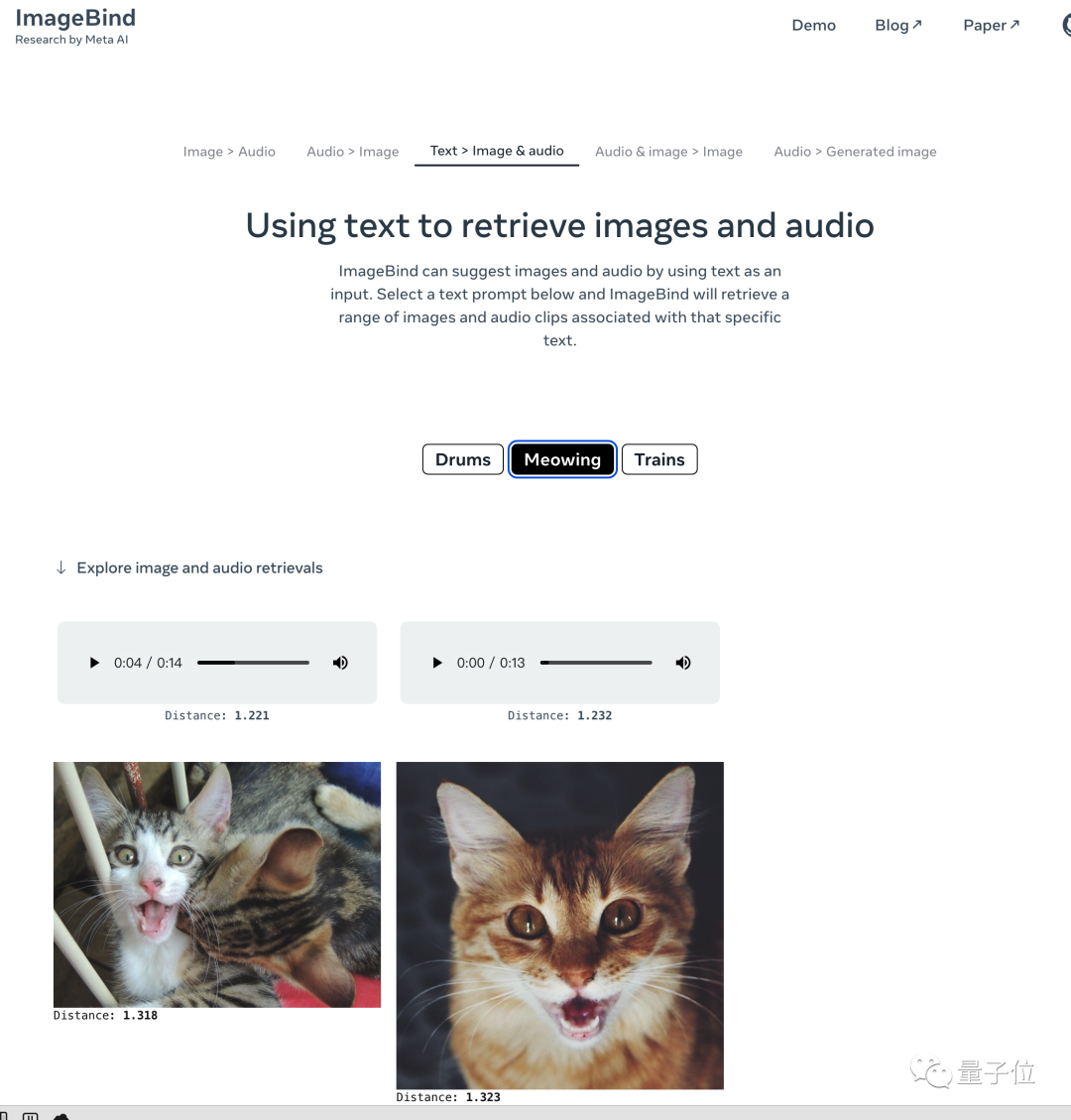
Demo:https://imagebind.metademolab.com/demo
GitHub:https://github.com/facebookresearch/ImageBind
论文:https://dl.fbaipublicfiles.com/imagebind/imagebind_final.pdf
参考链接:[1]https://ai.facebook.com/blog/imagebind-six-modalities-binding-ai/
本文来自微信公众号“量子位”(ID:QbitAI),作者:梦晨 ,36氪经授权发布。
该文观点仅代表作者本人,36氪平台仅提供信息存储空间服务。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK