

MySQL 并行复制方案演进历史及原理分析 - MySQL - dbaplus社群:围绕Data、Blockchain...
source link: https://dbaplus.cn/news-11-5250-1.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

MySQL 并行复制方案演进历史及原理分析
作者介绍
陈臣,甲骨文MySQL首席解决方案工程师,公众号《MySQL实战》作者,有大规模的MySQL,Redis,MongoDB,ES的管理和维护经验,擅长MySQL数据库的性能优化及日常操作的原理剖析。
有过线上 MySQL 维护经验的童鞋都知道,主从延迟往往是一个让人头疼不已的问题。
不仅仅是其造成的潜在问题比较严重,而且主从延迟原因的定位尤其考量 DBA 的综合能力:既要熟悉复制的内部原理,又能解读主机层面的资源使用情况,甚至还要会分析 binlog。
导致主从延迟的一个常见原因是,对于 binlog 中的事务,从库上只有一个 SQL 线程进行重放,而这些事务在主库中是并发写入的。
就好比你多个人(多线程)挖坑,我一个人(单线程)来填,本来就双拳难敌四手,在你挖坑速度不快的情况下,我尚能应付。一旦你稍微加速,我则力有不逮,只能眼睁睁地看着你挖的坑越来越深。
具体在 MySQL 中,则意味着 Seconds_Behind_Master 的值越来越大。
本文主要包括以下几部分:
1、主从延迟的危害。
2、并行复制方案简介。
3、MySQL 5.7 基于组提交的并行复制方案,包括 Commit-Parent-Based 方案和 Lock-Based 方案。
4、MySQL 8.0 基于 WRITESET 的并行复制方案。
5、对 COMMIT_ORDER,WRITESET_SESSION,WRITESET 这三种方案的压测结果。
6、如何开启并行复制。
一、主从延迟的危害
主从延迟带来的问题,主要体现在以下两个方面:
1、对于读写分离的业务,主从延迟意味着业务会读到旧数据。
2、主从延迟过大,会影响数据库的高可用切换。这一点尤其需要注意。
如果等待从库应用完差异的 binlog 才做高可用切换,无疑会影响数据库服务的可用性。
如果不等待,直接切换,则意味着没应用完的这部分 binlog 的数据会丢失,业务不一定能接受这种情况。
二、并行复制方案简介
MySQL官方先后提出了多个不同的并行复制方案,具体如下。
1、MySQL 5.6 基于库级别的并行复制方案。
2、MySQL 5.7 基于组提交的并行复制方案。
3、MySQL 8.0 基于 WRITESET 的并行复制方案。
因为线上大部分环境都是单库多表的,所以基于库级别的并行复制实际上用得并不多。
下面,重点看看后两个方案的实现原理。
三、基于组提交的并行复制方案
MySQL 5.7 基于组提交的并行复制方案,先后经历了两个版本的迭代:Commit-Parent-Based 方案和 Lock-Based 方案。
1、Commit-Parent-Based 方案
MySQL 会将一个事务拆分为两个阶段进行处理:Prepare 阶段和 Commit 阶段。
另外,InnoDB 使用的锁机制是悲观锁。在悲观锁中,事务是在操作之初执行加锁操作,如果锁资源被其它事务占用了,则该事务会被阻塞。
基于这两点,我们不难推断出,两个事务如果都进入了 Prepare 阶段,则意味着它们之间是没有锁冲突的,在从库重放时可并行执行。这就是 Commit-Parent-Based 方案的核心思想。
具体实现上:
(1)主库有个全局计数器(global counter),每次在事务存储引擎层提交之前,都会增加这个计数器。
(2)在事务进入 Prepare 阶段之前,会将全局计数器的当前值记录在事务中,这个值称为事务的 commit-parent。
(3)这个 commit-parent 会写入 binlog,记录在事务的头部。
(4)从库重放时,如果发现两个事务的 commit-parent 相同,会并行执行这两个事务。
以下面这 7 个事务为例,看看这 7 个事务在从库的并行执行情况。
Trx1 ------------P----------C-------------------------------->|Trx2 ----------------P------+---C---------------------------->| |Trx3 -------------------P---+---+-----C---------------------->| | |Trx4 -----------------------+-P-+-----+----C----------------->| | | |Trx5 -----------------------+---+-P---+----+---C------------->| | | | |Trx6 -----------------------+---+---P-+----+---+---C---------->| | | | | |Trx7 -----------------------+---+-----+----+---+-P-+--C------->| | | | | | |
示例中的 Trx 指的是事务,P 指的是事务在进行 Prepare 阶段之前,读取 commit-parent 的时间点。C 指的是事务在进行 Commit 阶段之前,增加全局计数器的时间点。
下面看看这 7 个事务的并行执行情况。
-
Trx1、Trx2、Trx3 并行执行。
-
Trx4 串行执行。
-
Trx5、Trx6 并行执行。
-
Trx7 串行执行。
这在很大程度上实现了并行,但还不够完美。
实际上,Trx4、Trx5、Trx6 可并行执行,因为它们同时进入了 Prepare 阶段。同理,Trx6、Trx7 也可并行执行。
基于此,官方迭代了并行复制方案,推出了新的 Lock-Based 方案。
2、Lock-Based 方案
该方案引入了锁区间(locking interval)的概念,锁区间定义了一个事务持有锁的时间范围。具体来说,
(1)将 Prepare 阶段,最后一个 DML 语句获取锁的时间点,定义为锁区间的开始点。
(2)将存储引擎层提交之前,锁释放的时间点,定义为锁区间的结束点。
如果两个事务的锁区间存在交集,则意味着这两个事务没有锁冲突,可并行重放。例如,
Trx1 -----L---------C------------>Trx2 ----------L---------C------->
反之,则不可并行重放,例如,
Trx1 -----L----C----------------->Trx2 ---------------L----C------->
这里的 L 代表锁区间的开始点,C 代表锁区间的结束点。
在具体实现上,主库引入了以下 4 个变量:
-
global.transaction_counter:事务计数器。
-
transaction.sequence_number:事务序列号。
在事务进入 Prepare 阶段之前,会将 global.transaction_counter 自增加 1 并赋值给 transaction.sequence_number。
transaction.sequence_number = ++global.transaction_counter序列号不是一直递增的,每切换一个 binlog,都会将 transaction.sequence_number 重置为 1。
-
global.max_committed_transaction:当前已提交事务的最大序列号。
在事务进行存储引擎层提交之前,会取 global.max_committed_transaction 和当前事务的 sequence_number 的最大值,赋值给 global.max_committed_transaction。
global.max_committed_transaction = max(global.max_committed_transaction,transaction.sequence_number)
-
transaction.last_committed:在事务进入 Prepare 阶段之前,已提交事务的最大序列号。
transaction.last_committed = global.max_committed_transaction在这 4 个变量中,transaction.sequence_number 和 transaction.last_committed 会写入 binlog。
具体来说,对于 GTID 复制,它们会写入 GTID_LOG_EVENT;对于非 GTID 复制,则写入 ANONYMOUS_GTID_LOG_EVENT 。
对于示例中的 7 个事务,记录在 binlog 中的 last_committed、sequence_number 如下所示:
Trx1: last_committed=0 sequence_number=1Trx2: last_committed=0 sequence_number=2Trx3: last_committed=0 sequence_number=3Trx4: last_committed=1 sequence_number=4Trx5: last_committed=2 sequence_number=5Trx6: last_committed=2 sequence_number=6Trx7: last_committed=5 sequence_number=7
3、从库并行重放的逻辑
下面说说从库并行重放的逻辑。
从库引入了一个事务队列( transaction_sequence ),包含了当前正在执行的事务。
该队列是有序的,按照事务的 sequence_number 从小到大排列。这个队列中的事务可并行执行。
一个新的事务能否插入这个队列,唯一的判断标准是,事务的 last_committed 是否小于队列中第一个事务的 sequence_number。只有小于才允许插入。
transaction.last_committed < transaction_sequence[0].sequence_number 最后,回到示例中的 7 个事务,结合 binlog 中的 last_committed 和 sequence_number,我们看看这 7 个事务的并行执行情况。
-
Trx1、Trx2、Trx3 并行执行。
-
Trx1 执行完毕后,Trx4 可加入队列。
-
Trx2 执行完毕后,Trx5、Trx6 可加入队列。
-
Trx5 执行完毕后,Trx7 可加入队列。
不难发现,相对于 Commit-Parent-Based 方案,Lock-Based 方案的并行度确实大大提高了。
4、组提交方案小结
无论是 Commit-Parent-Based 方案,还是 Lock-Based 方案,依赖的都是组提交(Group Commit)。
组提交方案有以下两个特点:
(1)适用于高并发场景。因为只有在高并发场景下,才会有更多的事务放到一个组(Group)中提交。
(2)在级联复制中,层级越深,并行度越低。
针对低并发场景,如果要提升从库的并行效率,可调整以下两个参数:
binlog_group_commit_sync_delay
binlog 刷盘(fsync)之前等待的时间。单位微秒,默认为 0,不等待。
该值越大,一个组内的事务就越多,相应地,从库的并行度也就越高。但该值越大,客户端的响应时间也会越长。
binlog_group_commit_sync_no_delay_count
在 binlog_group_commit_sync_delay 时间内,允许等待的最大事务数。
如果 binlog_group_commit_sync_delay 设置为 0,则此参数无效。
四、WRITESET 方案
MySQL 8.0 推出了 WRITESET 方案。该方案推出的初衷实际上是为 Group Replication 服务的,主要是用于认证阶段(Certification)的冲突检测。
WRITESET 方案的核心思想是,两个来自不同节点的并发事务,只要没修改同一行,就不存在冲突。对于没有冲突的并发事务,在写入relay log 中时,可以共享一个 last_committed。
这里的冲突检测,实际上比较的是两个事务之间的写集合(writeset)。
注意,writeset 和 WRITESET 两者的区别,前者指的是事务的写集合,后者则特指 WRITESET 方案。
1、事务写集合的生成过程
下面来看看事务 writeset 的生成过程。具体步骤如下:
(1)首先提取被修改行的主键、唯一索引、外键信息。一张表,如果有主键和一个唯一索引,则每修改一行,会提取两条约束信息:一条针对主键,另一条针对唯一索引。针对主键的,提取的信息包括主键名、库名、表名、主键值,这些信息会拼凑为一个字符串。
(2)计算该字符串的哈希值,具体的哈希算法由 transaction_write_set_extraction 参数指定。
(3)将计算后的哈希值插入当前事务的写集合。
2、WRITESET 方案的实现原理
接下来,结合源码看看 WRITESET 方案的实现原理。
void Writeset_trx_dependency_tracker::get_dependency(THD *thd,int64 &sequence_number,int64 &commit_parent) {Rpl_transaction_write_set_ctx *write_set_ctx =thd->get_transaction()->get_transaction_write_set_ctx();std::vector<uint64> *writeset = write_set_ctx->get_write_set();#ifndef NDEBUG/* 空事务的写集合必须为空 */if (is_empty_transaction_in_binlog_cache(thd)) assert(writeset->size() == 0);#endif/*判断一个事务能否使用 WRITESET 方案*/bool can_use_writesets =// 事务写集合的大小不为 0 或者事务为空事务(writeset->size() != 0 || write_set_ctx->get_has_missing_keys() ||is_empty_transaction_in_binlog_cache(thd)) &&// 事务的 transaction_write_set_extraction 必须与全局设置一致(global_system_variables.transaction_write_set_extraction ==thd->variables.transaction_write_set_extraction) &&// 不能被其它表外键关联!write_set_ctx->get_has_related_foreign_keys() &&// 事务写集合的大小不能超过 binlog_transaction_dependency_history_size!write_set_ctx->was_write_set_limit_reached();bool exceeds_capacity = false;if (can_use_writesets) {/*检查 m_writeset_history 加上事务写集合的大小是否超过 m_writeset_history 的上限,m_writeset_history 的上限由参数 binlog_transaction_dependency_history_size 决定*/exceeds_capacity =m_writeset_history.size() + writeset->size() > m_opt_max_history_size;/*计算所有冲突行中最大的 sequence_number,并将被修改行的哈希值插入 m_writeset_history*/int64 last_parent = m_writeset_history_start;for (std::vector<uint64>::iterator it = writeset->begin();it != writeset->end(); ++it) {Writeset_history::iterator hst = m_writeset_history.find(*it);if (hst != m_writeset_history.end()) {if (hst->second > last_parent && hst->second < sequence_number)last_parent = hst->second;hst->second = sequence_number;} else {if (!exceeds_capacity)m_writeset_history.insert(std::pair<uint64, int64>(*it, sequence_number));}}// 如果表上都存在主键,则会取 last_parent 和 commit_parent 的较小值作为事务的 commit_parent。if (!write_set_ctx->get_has_missing_keys()) {commit_parent = std::min(last_parent, commit_parent);}}if (exceeds_capacity || !can_use_writesets) {m_writeset_history_start = sequence_number;m_writeset_history.clear();}}
该函数的处理流程如下:
(1)调用函数时,会传入事务的 sequence_number,commit_parent(last_committed),这两个值是基于 Lock-Based 方案生成的。
(2)获取事务的写集合。可以看到,事务的写集合是数组类型。
(3)判断一个事务能否使用 WRITESET 方案。
以下场景不能使用 WRITESET 方案,此时,只能使用 Lock-Based 方案生成的 last_committed。
-
事务没有写集合。常见的原因是表上没有主键。
-
当前事务 transaction_write_set_extraction 的设置与全局不一致。
-
表被其它表外键关联。
-
事务写集合的大小超过 binlog_transaction_dependency_history_size。
(4)如果能使用 WRITESET 方案。
①首先判断 m_writeset_history 的容量是否超标。
具体来说,m_writeset_history + writeset 的大小是否超过 binlog_transaction_dependency_history_size 的设置。
②将 m_writeset_history_start 赋值给变量 last_parent。
m_writeset_history_start 代表不在 m_writeset_history 中最后一个事务的 sequence_number,其初始值为 0。
当参数 binlog_transaction_dependency_tracking 发生变化或清空 m_writeset_history 时,会更新 m_writeset_history_start。
③循环遍历事务的写集合,判断被修改行对应的哈希值是否在 m_writeset_history 存在。
若存在,则意味着 m_writeset_history 存在同一行的操作。既然是同一行的不同操作,自然就不能并行重放。这个时候,会将 m_writeset_history 中该行的 sequence_number 赋值给 last_parent。
需要注意的是,这里会循环遍历完事务的写集合,毕竟这个事务中可能有多条记录在 m_writeset_history 中存在。
在遍历的过程中,会判断 m_writeset_history 中冲突行的 sequence_number 是否大于 last_parent,只有大于才会赋值。换言之,这里会取所有冲突行中最大的 sequence_number,赋值给 last_parent。
若不存在,则判断 m_writeset_history 的容量是否超标,若不超标,则会将被修改行的哈希值插入 m_writeset_history。
可以看到,m_writeset_history 是个字典类型。其中 key 存储的是被修改行的哈希值,value 存储的是事务的 sequence_number。
(5)判断被操作的表上是否都存在主键。
若存在,才会取 last_parent 和 commit_parent 的较小值作为事务的 commit_parent。否则,使用的还是 Lock-Based 方案生成的commit_parent。
(6)如果 m_writeset_history 容量超标或者事务不能使用 WRITESET 方案,则会将当前事务的 sequence_number 赋值给m_writeset_history_start,同时清空 m_writeset_history。
3、WRITESET 方案的相关参数
下面看看 WRITESET 方案的三个参数。
binlog_transaction_dependency_tracking
指定基于何种方案决定事务的依赖关系。对于同一个事务,不同的方案可生成不同的 last_committed。
该参数有以下取值:
-
COMMIT_ORDER:基于 Lock-Based 方案决定事务的依赖关系。默认值。
-
WRITESET:基于 WRITESET 方案决定事务的依赖关系。
-
WRITESET_SESSION:同 WRITESET 类似,只不过同一个会话中的事务不能并行执行。
transaction_write_set_extraction
指定事务写集合的哈希算法,可设置的值有:OFF,MURMUR32,XXHASH64(默认值)。
对于 Group Replication,该参数必须设置为 XXHASH64。
注意,若要将 binlog_transaction_dependency_tracking 设置为 WRITESET 或 WRITESET_SESSION,则该参数不能设置为 OFF。
binlog_transaction_dependency_history_size
m_writeset_history 的上限,默认 25000。
一般来说,binlog_transaction_dependency_history_size 越大,m_writeset_history 能存储的行的信息就越多。在不出现行冲突的情况下,m_writeset_history_start 也会越小。相应地,新事务的 last_committed 也会越小,在从库重放的并发度也会越高。
五、压测结果
接下来,看看 MySQL 官方对于 COMMIT_ORDER,WRITESET_SESSION,WRITESET 这三种方案的压测结果。
主库环境:16 核,SSD,1个数据库,16 张表,共 800w 条数据。
压测场景:OLTP Read/Write, Update Indexed Column 和 Write-only。
压测方案:在关闭复制的情况下,在不同的线程数下,注入 100w 个事务。开启复制,观察不同线程数下,不同方案的从库重放速度。
三个场景下的压测结果如图所示。
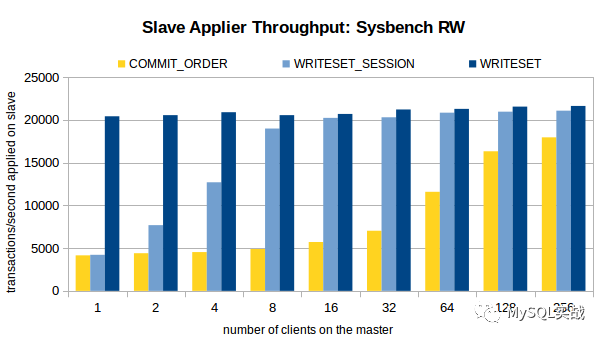
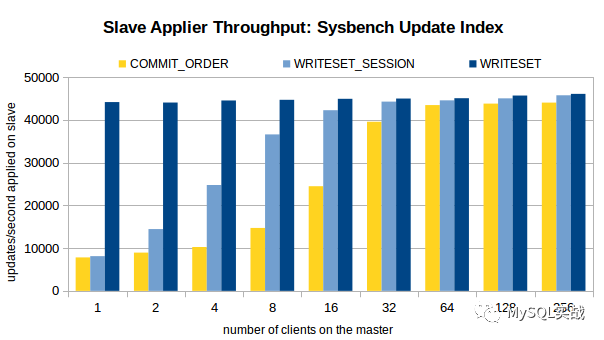
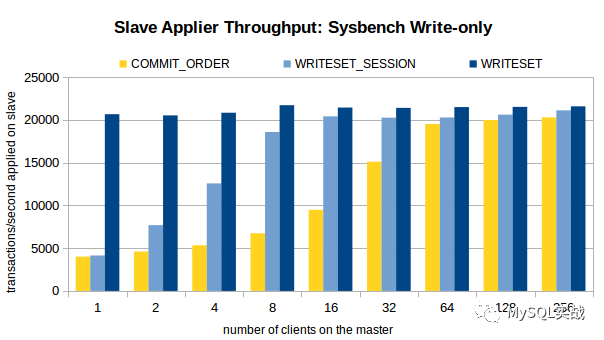
分析压测结果,我们可以得出以下结论。
1、对于 COMMIT_ORDER 方案,主库并发度越高,从库的重放速度越快。
2、对于 WRITESET 方案,主库的并发线程数对其几乎没有影响。甚至,单线程下 WRITESET 的重放速度都超过了 256 线程下的COMMIT_ORDER。
3、与 COMMIT_ORDER 一样,WRITESET_SESSION 也依赖于主库并发。只不过,在主库并发线程数较低(4 线程、8 线程)的情况下,WRITESET_SESSION 也能实现较高的吞吐量。
六、如何开启并行复制
在从库上设置以下三个参数。
slave_parallel_type = LOGICAL_CLOCKslave_parallel_workers = 16slave_preserve_commit_order = ON
下面看看这三个参数的的具体含义。
slave_parallel_type
设置从库并行复制的类型。该参数有以下取值:
DATABASE:基于库级别的并行复制。MySQL 8.0.27 之前的默认值。
LOGICAL_CLOCK:基于组提交的并行复制。
slave_parallel_workers
设置 Worker 线程的数量。开启了多线程复制,原来的 SQL 线程将演变为 1 个 Coordinator 线程和多个 Worker 线程。
slave_preserve_commit_order
事务在从库上的提交顺序是否与主库保持一致,建议开启。
需要注意的是,调整这三个参数,需要重启复制才能生效。
从 MySQL 5.7.22、MySQL 8.0 开始,可使用 WRITESET 方案进一步提升并行复制的效率,此时,需在主库上设置以下参数。
binlog_transaction_dependency_tracking = WRITESET_SESSIONtransaction_write_set_extraction = XXHASH64binlog_transaction_dependency_history_size = 25000binlog_format = ROW
注意,基于 WRITESET 的并行复制方案,只在 binlog 格式为 ROW 的情况下才生效。
>>>>
参考资料
-
1、WL#6314: MTS: Prepared transactions slave parallel applier:
https://dev.mysql.com/worklog/task/?id=6314
-
2、WL#6813: MTS: ordered commits (sequential consistency):
https://dev.mysql.com/worklog/task/?id=6813
-
3、WL#7165: MTS: Optimizing MTS scheduling by increasing the parallelization window on master:
https://dev.mysql.com/worklog/task/?id=7165
-
4、WL#8440: Group Replication: Parallel applier support:
https://dev.mysql.com/worklog/task/?id=8440
-
5、WL#9556: Writeset-based MTS dependency tracking on master:
https://dev.mysql.com/worklog/task/?id=9556
-
6、WriteSet并行复制:
https://www.jianshu.com/p/616703533310
-
7、Improving the Parallel Applier with Writeset-based Dependency Tracking:
https://mysqlhighavailability.com/improving-the-parallel-applier-with-writeset-based-dependency-tracking/
作者丨陈臣 来源丨公众号:MySQL实战(ID:MySQLInAction) dbaplus社群欢迎广大技术人员投稿,投稿邮箱:[email protected]
Recommend
-
54
一、并行复制的背景 首先,为什么会有并行复制这个概念呢? 1.DBA都应该知道,MySQL的复制是基于binlog的。 2.MySQL复制包括两部分,IO线程 和 SQL线程。 3.IO线程主要是用于拉取接收Master传递过来...
-
3
在MySQL 5.7版本,官方称为enhanced multi-threaded slave(简称MTS),复制延迟问题已经得到了极大的改进,可以说在MySQL 5.7版本后,复制延迟问题永不存在。 5.7的MTS本身就是:master基于组提交(group commit)来实现的并发事务分组,...
-
3
直播预告丨猪八戒网DevOps演进及CI/CD最佳实践 dbaplus社群 2022-07-17 09:49:00 ...
-
6
今晚直播丨猪八戒网DevOps演进及CI/CD最佳实践 dbaplus社群 2022-07-20 09:16:07
-
6
系统成功率99.99%+,美团CI/CD流水线引擎演进实践 - 运维 - dbaplus社群:围绕Data、Blockchain、AiOps的企业级专业社群。技术大咖、原创干货,每天精品原创文章推送,每周线上技术分享,每月线下技术沙龙。 经过近3年的建设打...
-
4
应用监控系统演进:从选型到落地,链路追踪一气呵成 陆家靖 2022-09-14 09:41:45
-
2
从蚂蚁集团数据库演进之路看未来数据库的选择丨DAMS峰会 DAMS 2022-09-22 09:33:35 ...
-
1
Redis高可用之主从复制原理演进分析 在很久之前写过一篇 Redis 主从复制原理的简略分析,基本是一个笔记类文章。 一、...
-
2
从青铜到钻石:Redis分布式锁的五大演进攻略 悟空聊架构 2022-12-12 15:12:51 本文我们来探讨下如何引入分...
-
3
较ClickHouse降低50%成本,湖仓一体在B站的演进 李呈祥 2023-04-19 10:47:56 本文根据李呈祥老师在〖2023 中国数据智能...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK