

Apache hudi 核心功能点分析 - Aitozi
source link: https://www.cnblogs.com/Aitozi/p/17373573.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

文中部分代码对应 0.14.0 版本
初始的需求是Uber公司会有很多记录级别的更新场景,Hudi 在Uber 内部主要的一个场景,就是乘客打车下单和司机接单的匹配,乘客和司机分别是两条数据流,通过 Hudi 的 Upsert 能力和增量读取功能,可以分钟级地将这两条数据流进行拼接,得到乘客-司机的匹配数据。
为了提升更新的时效性,因此提出了一套新的框架作为近实时的增量的解决方案
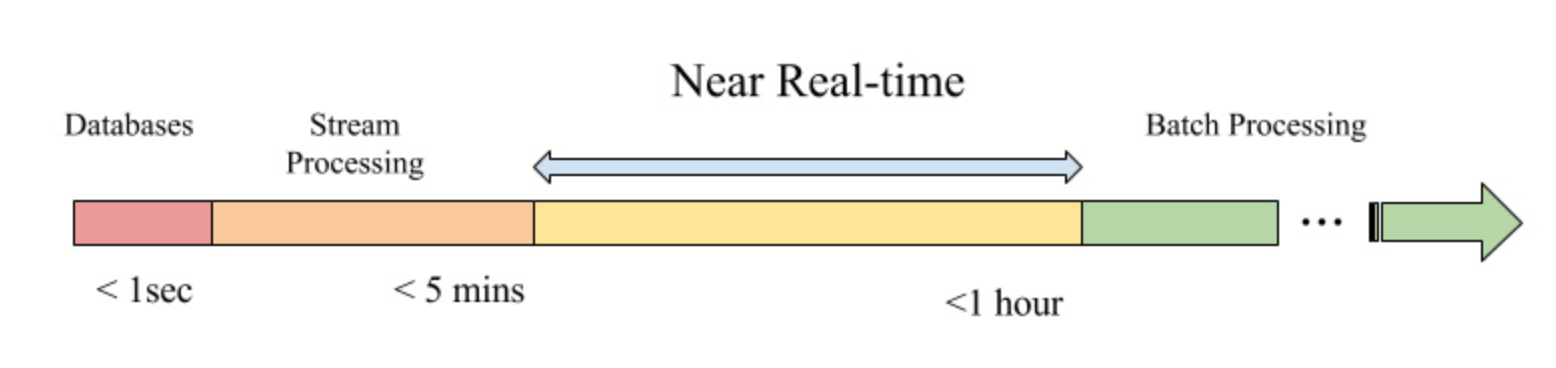
从名字Hadoop Upsert and Incremental 也可以看出hudi的主要功能是upsert 和 incremental 的能力,架在Hadoop之上。
核心功能点
支持更新删除
https://hudi.apache.org/cn/docs/indexing
主要是通过索引技术来实现高效的upsert和delete。通过索引可以将一条记录的Hoodie key (record key)映射到一个文件id,然后根据表的类型,以及写入数据的类型,来决定更新和删除输入的插入方式。
- BloomFilter 默认实现,默认会在每次commit文件时,将这个文件的所包含的key所构建的bloomfilter以及key的range 写出到parquet 文件的footer中。
- HBase 全局索引,依赖外部集群
- Simple Index (根据key的字段去查询相应file 中是否存在)
- Bucket Index 先分桶再取hash,为了解决大规模场景下bloomfilter 索引效率低的问题
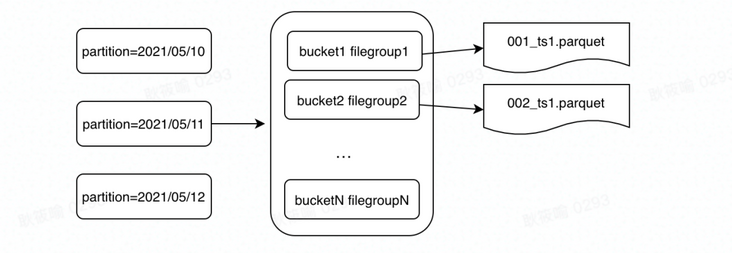
索引的类型还分为global 和 非 global 两种,BloomFilter Index和 Simple Index这两种有global的选项,hbase天然就是global的选项,global index会保障全局分区下键的唯一性,代价会更高。
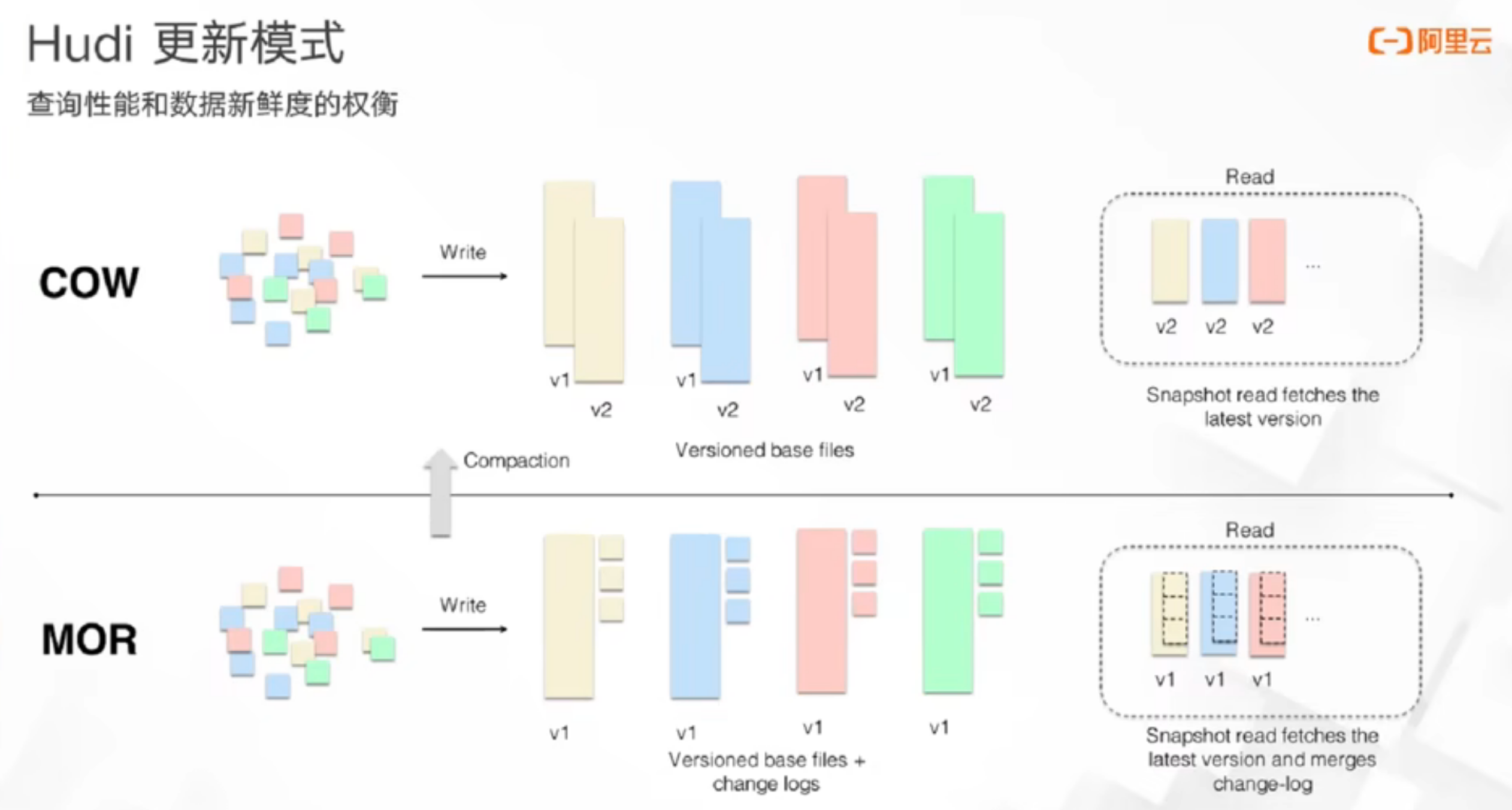

Odps/MaxCompute也支持更新删除
https://help.aliyun.com/document_detail/205825.html
也是用过base file + delta log的思路来实现
Hive3.0 也支持更新删除和ACID语义
https://www.adaltas.com/en/2019/07/25/hive-3-features-tips-tricks/
https://cwiki.apache.org/confluence/display/Hive/Hive+Transactions
差别在于hudi是支持了数据表的upsert,也就是能在写入时就保证数据主键的唯一性,而odps 和 hive应该只是支持了通过update 和 delete dml语句来更新数据,覆盖场景不同。后者应该主要只是在数据订正的场景,作为入湖的选型还是需要天然支持upsert才行。
ACID事务支持
我认为事务支持是hudi中最核心的部分,因为数据的更新删除都强依赖事务的能力,传统数仓中只提供insert语义并且文件只能追加,对事务保障的需求会弱很多,最多就是读到了不完整的数据(写入分区数据后还发生append)。
但是当需要支持update和delete语义时,对事务的保障的需求就会强很多,所以可以看到hive和odps中想要开启表的更新和删除能力,首先需要开启表的事务属性。
hudi中事务的实现
**MVCC **通过mvcc机制实现多writer和reader之间的快照隔离
OCC 乐观并发控制
默认hudi是认为单writer写入的,这种情况下吞吐是最大的。如果有多writer,那么需要开启多writer的并发控制
hoodie.write.concurrency.mode=optimistic_concurrency_control # 指定锁的实现 默认是基于filesystem 的锁机制(要求filesystem能提供原子性的创建和删除保障)hoodie.write.lock.provider=<lock-provider-classname>
支持文件粒度的乐观并发控制,在写入完成commit时,如果是开启了occ,那么会先获取锁,然后再进行commit。看起来这个锁是全局粒度的一把锁,以filesystem lock为例
commit 流程
protected void autoCommit(Option<Map<String, String>> extraMetadata, HoodieWriteMetadata<O> result) {final Option<HoodieInstant> inflightInstant = Option.of(new HoodieInstant(State.INFLIGHT, getCommitActionType(), instantTime));// 开始事务,如果是occ并发模型,会获取锁this.txnManager.beginTransaction(inflightInstant, lastCompletedTxn.isPresent() ? Option.of(lastCompletedTxn.get().getLeft()) : Option.empty());try { setCommitMetadata(result); // reload active timeline so as to get all updates after current transaction have started. hence setting last arg to true. // 尝试解冲突,冲突判定的策略是可插拔的,默认是变更的文件粒度查看是否有交集. 目前冲突的文件更改是无法处理的,会终止commit请求 TransactionUtils.resolveWriteConflictIfAny(table, this.txnManager.getCurrentTransactionOwner(), result.getCommitMetadata(), config, this.txnManager.getLastCompletedTransactionOwner(), true, pendingInflightAndRequestedInstants); commit(extraMetadata, result);} finally { this.txnManager.endTransaction(inflightInstant);}}
锁获取流程
@Overridepublic boolean tryLock(long time, TimeUnit unit) {try { synchronized (LOCK_FILE_NAME) { // Check whether lock is already expired, if so try to delete lock file // 先检查lock file 是否存在,默认路径是 base/.hoodie/lock 也就是所有的commit操作都会操作这个文件 if (fs.exists(this.lockFile)) { if (checkIfExpired()) { fs.delete(this.lockFile, true); LOG.warn("Delete expired lock file: " + this.lockFile); } else { reloadCurrentOwnerLockInfo(); return false; } } // 如果文件不存在,则获取锁,创建文件 acquireLock(); return fs.exists(this.lockFile); }} catch (IOException | HoodieIOException e) { // 创建时可能会发生失败,则返回false获取锁失败 LOG.info(generateLogStatement(LockState.FAILED_TO_ACQUIRE), e); return false;}}
如果两个写入请求修改的文件没有重叠,在resolveConflict阶段直接通过,如果有重叠,那么后提交的写入会失败并回滚。
FileLayouts
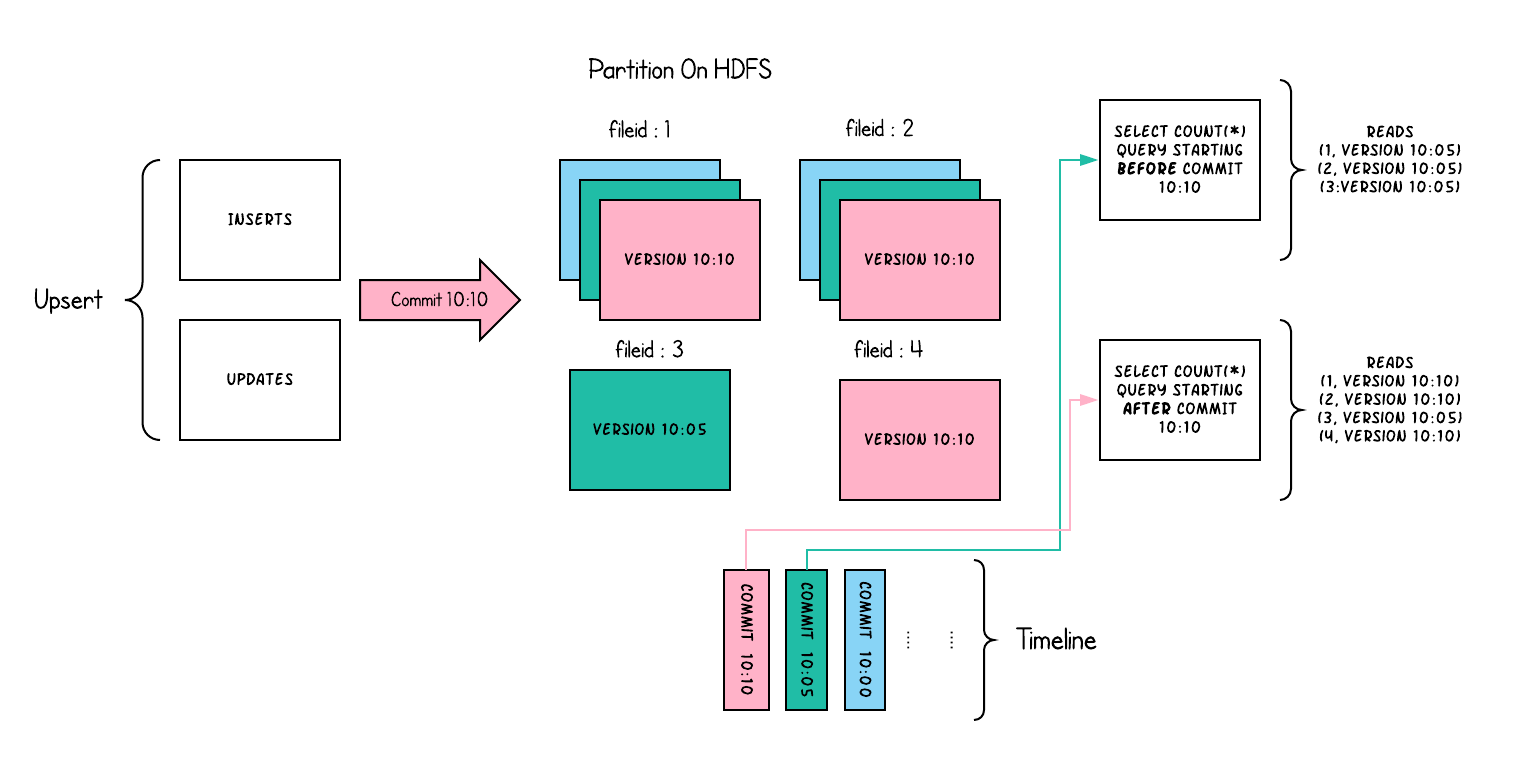
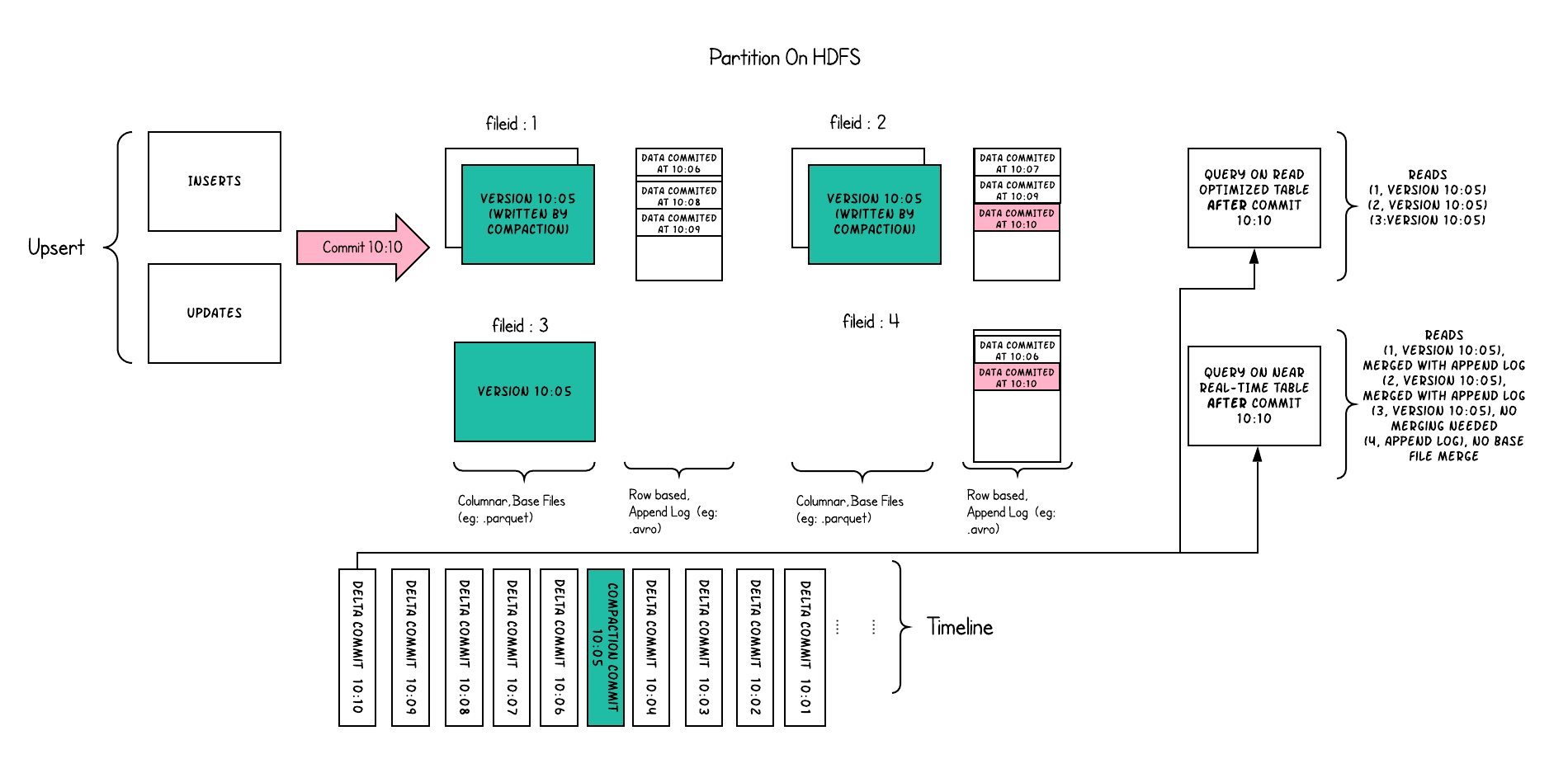
- 一个表对应一个分布式文件的base dir
- 每个分区中文件按照file groups组织,每个file groups对应一个 file ID
- 每个file group 包含多个 file slice
- 每个slice有一个base file (parquet 文件),以及一组 .log 文件 delta 文件
Base File是存储Hudi数据集的主体文件,以Parquet等列式格式存储。格式为
<fileId>_<writeToken>_<instantTime>.parquet
Log File是在MOR表中用于存储变化数据的文件,也常被称作Delta Log,Log File不会独立存在,一定会从属于某个Parquet格式的Base File,一个Base File和它从属的若干Log File所构成的就是一个File Slice。
.<fileId>_<baseCommitTime>.log.<fileVersion>_<writeToken>
File Slice,在MOR表里,由一个Base File和若干从属于它的Log File组成的文件集合被称为一个File Slice。File Slice是针对MOR表的特定概念,对于COW表来说,由于它不生成Log File,所以File Silce只包含Base File,或者说每一个Base File就是一个独立的File Silce。
FileId相同的文件属于同一个File Group。同一File Group下往往有多个不同版本(instantTime)的Base File(针对COW表)或Base File + Log File的组合(针对MOR表),当File Group内最新的Base File迭代到足够大( >100MB)时,Hudi就不会在当前File Group上继续追加数据了,而是去创建新的File Group。
这里面可以看到根据大小上下限来决定是否创建新的File Group在hudi中叫自适应的file sizing。这里其实就是在partition的粒度下创建了更小粒度的group. 类似于Snowflake中的micro partition技术。这个对于行级别的更新是很友好的,不管是cow还是mor表都减少了更新带来的重写数据的范围。
多种查询类型
- Snapshot Queries可以查询最新COMMIT的快照数据。针对Merge On Read类型的表,查询时需要在线合并列存中的Base数据和日志中的实时数据;针对Copy On Write表,可以查询最新版本的Parquet数据。Copy On Write和Merge On Read表支持该类型的查询。 批式处理
- Incremental Queries支持增量查询的能力,可以查询给定COMMIT之后的最新数据。Copy On Write和Merge On Read表支持该类型的查询。 流式/增量处理。 增量读取的最开始的意义应该是能加速数仓计算的pipeline,因为在传统离线数仓里面只能按照partition粒度commit,因为无法将paritition做到特别细粒度,最多可能到小时,30min,那么下游调度就只能按这个粒度来调度计算。而hudi里面基于事务就可以非常快速的commit,并提供commit 之后的增量语义,那么就可以加速离线数据处理pipeline。衍生的价值应该是可以让他提供类似消息队列的功能,这样就可以也当做一个实时数仓来用(如果时效性够的话)
- Read Optimized Queries只能查询到给定COMMIT之前所限定范围的最新数据。Read Optimized Queries是对Merge On Read表类型快照查询的优化,通过牺牲查询数据的时效性,来减少在线合并日志数据产生的查询延迟。因为这种查询只查存量数据,不查增量数据,因为使用的都是列式文件格式,所以效率较高。
Metadata管理
Hudi默认支持了写入表的元数据管理,metadata 也是一张MOR的hoodie表. 初始的需求是为了避免频繁的list file(分布式文件系统中这一操作通常很重)。Metadata是以HFile的格式存储(Hbase存储格式),提供高效的kv点查效率
Metadata 相关功能的配置org.apache.hudi.common.config.HoodieMetadataConfig
提供了哪些元数据?
hoodie.metadata.index.bloom.filter.enable保存数据文件的bloom filter indexhoodie.metadata.index.column.stats.enable保存数据文件的column 的range 用于裁剪优化
flink data skipping支持: https://github.com/apache/hudi/pull/6026
Catalog 支持 基于dfs 或者 hive metastore 来构建catalog 来管理所有在hudi上的表的元数据
CREATE CATALOG hoodie_catalog WITH ( 'type'='hudi', 'catalog.path' = '${catalog default root path}', 'hive.conf.dir' = '${directory where hive-site.xml is located}', 'mode'='hms' -- supports 'dfs' mode that uses the DFS backend for table DDLs persistence );
其他表服务能力
schema evolution, clustering,clean, file sizing..
https://hudi.apache.org/cn/docs/write_operations
- Upsert 默认,会先按索引查找来决定数据写入更新的位置或者仅执行插入。如果是构建一张数据库的镜像表可以使用这种方式。
- Insert 没有去重的逻辑(不会按照record key去查找),对于没有去重需求,或者能容忍重复,仅仅需要事务保障,增量读取功能可以使用这种模式
- bulk_insert 用于首次批量导入,通常通过Flink batch任务来运行,默认会按照分区键来排序,尽可能的避免小文件问题
- delete 数据删除 软删除和硬删除
Flink
插件支持多种写入模式, 参见org.apache.hudi.table.HoodieTableSink#getSinkRuntimeProvider。常见的有
https://hudi.apache.org/cn/docs/hoodie_deltastreamer#flink-ingestionBULK_INSERT, bulk insert 模式通常是用来批量导入数据,
每次写入数据RowData时,会同时更新bloom filter索引(将record key 添加到bloom filter 中). 在一个parquet文件写完成之后,会将构建的bloom filter信息序列化成字符串, 以及此文件的key range,序列化后保存到file footer中(在没开启bloom filter索引时也会做这一步).
public Map<String, String> finalizeMetadata() { HashMap<String, String> extraMetadata = new HashMap<>(); extraMetadata.put(HOODIE_AVRO_BLOOM_FILTER_METADATA_KEY, bloomFilter.serializeToString()); if (bloomFilter.getBloomFilterTypeCode().name().contains(HoodieDynamicBoundedBloomFilter.TYPE_CODE_PREFIX)) { extraMetadata.put(HOODIE_BLOOM_FILTER_TYPE_CODE, bloomFilter.getBloomFilterTypeCode().name()); } if (minRecordKey != null && maxRecordKey != null) { extraMetadata.put(HOODIE_MIN_RECORD_KEY_FOOTER, minRecordKey.toString()); extraMetadata.put(HOODIE_MAX_RECORD_KEY_FOOTER, maxRecordKey.toString()); } return extraMetadata;}
Append Mode: 仅只有Insert的数据Upsert:
- bootstrap index 生成
BootstrapOperator用于基于已经存在的hoodie表的历史数据集,构建初始的index索引(可选)通过参数index.bootstrap.enabled开启,默认为false。加载过程会可能会比较慢,开启的情况下需要等到所有task都加载完成才能处理数据。这个加载需要获取所有分区的 索引,加载到state中. 这个理论上是需要读取metadata列_hoodie_record_key和_hoodie_partition_path然后构建出IndexRecord,所以会很慢。 - stream writer 写入时会先通过
BucketAssignFunction计算数据应该落到哪个bucket(file group)去, 感觉bucket这个词和bucket index有点冲突,这里是两个概念,这里主要还是划分数据所属哪个file,这一步就会用到前面构建的索引,所以默认情况下flink的索引是基于state的
// Only changing records need looking up the index for the location,// append only records are always recognized as INSERT.HoodieRecordGlobalLocation oldLoc = indexState.value();// change records 表示会更改数据的写入类型如update,deleteif (isChangingRecords && oldLoc != null) { // Set up the instant time as "U" to mark the bucket as an update bucket. // 打标之后如果partition 发生变化了,例如partition 字段发生了变化 ? 状态中存储的就是这个数据应该存放的location if (!Objects.equals(oldLoc.getPartitionPath(), partitionPath)) { if (globalIndex) { // if partition path changes, emit a delete record for old partition path, // then update the index state using location with new partition path. // 对于全局索引,需要先删除老的分区的数据,非全局索引不做跨分区的改动 HoodieRecord<?> deleteRecord = new HoodieAvroRecord<>(new HoodieKey(recordKey, oldLoc.getPartitionPath()), payloadCreation.createDeletePayload((BaseAvroPayload) record.getData())); deleteRecord.unseal(); deleteRecord.setCurrentLocation(oldLoc.toLocal("U")); deleteRecord.seal(); out.collect((O) deleteRecord); } location = getNewRecordLocation(partitionPath); } else { location = oldLoc.toLocal("U"); this.bucketAssigner.addUpdate(partitionPath, location.getFileId()); }} else { location = getNewRecordLocation(partitionPath);}
可以看到在BucketAssigner这一步就已经确定了record 已经落到哪个fileid中(也就是打标的过程),所以默认就走的是基于state的索引。 在这里org.apache.hudi.table.action.commit.FlinkWriteHelper#write区别于org.apache.hudi.table.action.commit.BaseWriteHelper#write。好处就是不用像BloomFilter 索引去读取文件key 以及并且没有假阳的问题,坏处就是需要在写入端通过state来维护索引。除了默认基于State索引的方式, Flink 也支持BucketIndex。
总体感觉,索引的实现比较割裂,交由各个引擎的实现端来完成。而且流式写入依赖内部状态索引可能稳定性的问题。
- 相比传统数仓支持update, delete(更轻量)
- ACID 事务特性 (地基功能) + 索引机制。
- 支持增量读取和批式读取
- 提供健全的文件和表的metadata,加速查询端数据裁剪能力
- 目前看不支持dim join
- 定位是流批一体的存储 + 传统数仓的升级。无法替代olap 和 kv 存储系统。
总的来看,hudi的核心价值有
端到端数据延迟降低
在传统基于 Hive 的 T + 1 更新方案中,只能实现天级别的数据新鲜度,取决于partition的粒度。因为在传统离线数仓里面只能按照partition粒度commit,因为无法将paritition做到特别细粒度,文件管理的压力会很大,最多可能到小时,30min,那么下游调度就只能按这个粒度来调度计算。而hudi里面基于事务就可以非常快速的commit,并提供commit 之后的增量语义,那么就可以加速离线数据处理pipeline。
高效的Upsert
不用每次都去 overwrite 整张表或者整个 partition 去更新,而是能够精确到文件粒度的局部更新来提升存储和计算效率。
而这两者都是以ACID事务作为保障。因此Hudi的名字取的很好,基本把他的核心功能都说出来了。
https://github.com/leesf/hudi-resources hudi resources
https://github.com/apache/hudi/tree/master/rfc hudi rfcs
https://www.liaojiayi.com/lake-hudi/ hudi 核心概念解读
https://cwiki.apache.org/confluence/display/HUDI/RFC+-+29%3A+Hash+Index hash 索引设计
https://stackoverflow.com/questions/19128940/what-is-the-difference-between-partitioning-and-bucketing-a-table-in-hive bucket in hive
https://www.cnblogs.com/leesf456/p/16990811.html 一文聊透hudi 索引机制
https://github.com/apache/hudi/blob/master/rfc/rfc-45/rfc-45.md async metadata indexing rfc
https://mp.weixin.qq.com/s/Moehs1Ch3j7IVANJQ1mfNw Apache Hudi重磅RFC解读之记录级别全局索引
https://blog.csdn.net/weixin_47482194/article/details/116357831 MOR表的文件结构分析
https://juejin.cn/post/7160589518440153096#heading-1 实时数据湖 Flink Hudi 实践探索
https://segmentfault.com/a/1190000041471105 hudi Bucket index
https://mp.weixin.qq.com/s/n_Kd6FhWs4_QZN_gmAuPhw file layouts
https://mp.weixin.qq.com/s?__biz=MzIyMzQ0NjA0MQ== file sizing
https://mp.weixin.qq.com/s/Te2zaF6AoJuTxY8ILzxlQg Clustering
https://docs.snowflake.com/en/user-guide/tables-clustering-micropartitions snowflake micropartition
https://cloud.tencent.com/developer/article/1827930 17张图带你彻底理解Hudi Upsert原理
https://hudi.apache.org/cn/docs/concurrency_control/ 并发控制
https://www.infoq.cn/article/Pe9ejRJDrJsp5AIhjlE3 对象存储
https://www.striim.com/blog/data-warehouse-vs-data-lake-vs-data-lakehouse-an-overview/#dl data lake vs data warehouse vs lake house
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK