

Kafka: The Basics
source link: https://dzone.com/articles/kafka-the-basics
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Data synchronization is one of the most important aspects of any product. Apache Kafka is one of the most popular choices when designing a system that expects near-real-time propagation of large volumes of data. Even though Kafka has simple yet powerful semantics, working with it requires insight into its architecture. This article summarizes the most important design aspects of Kafka as a broker and applications that act as data producers or consumers.
About Kafka
Apache Kafka originated on LinkedIn and was developed as a highly scalable distribution system for telemetry and usage data. Over time, Kafka evolved into a general-purpose streaming data backbone that combines high throughput with low data delivery latencies. Internally, Kafka is a distributed log. A (commit) log is an append-only data structure to whose end the producers append the data (log records), and subscribers read the log from the beginning to replay the records. This data structure is used, for example, in the database write-ahead log. Distributed log means that the actual data structure is not hosted on a single node but is distributed across many nodes to achieve both high availability and high performance.
Internals and Terminology
Before we jump into how Kafka is used by applications, let's quickly go through the basic terminology and architecture so we understand the guarantees that Kafka provides to its users.
A single Kafka node is called a Broker. The broker receives messages from producers and distributes these to consumers. Producers send the messages into distributed logs, which are called topics (in traditional messaging, this corresponds to a queue). To scale up the performance of a single topic over the capacity of a single node, each topic may be split into multiple partitions. To achieve high availability and durability of the data stored, each partition has a leader (performing all read and write operations) and multiple followers. Partitions are assigned to brokers automatically, and the failover of a broker is also automatic and transparent to developers using Kafka. On the backend, the assignment of leader/replica roles is orchestrated using leader election in Apache ZooKeeper or in the newer versions of Kafka using the KRaft protocol.
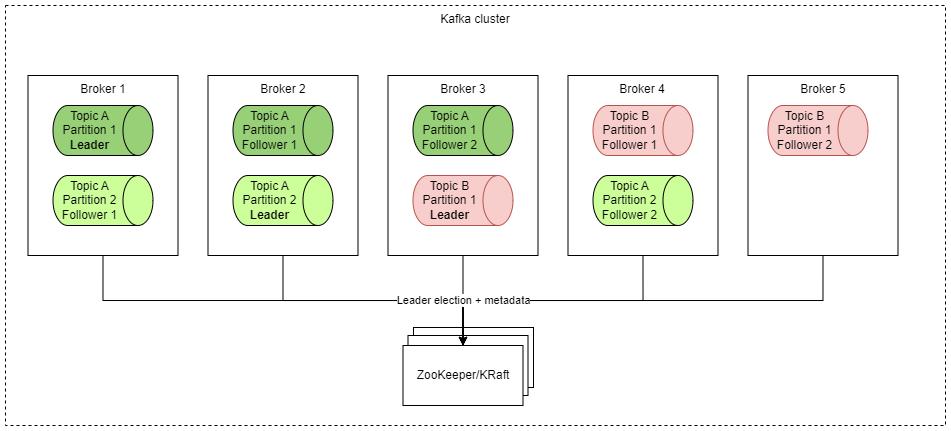
In the diagram, we can see a Kafka cluster, which consists of five brokers. In this scenario, two topics (A and B) were created. Topic A has two partitions, while topic B has only a single partition. The cluster was set up with replication factor 3 — this means there are always three copies of the data stored, allowing two nodes to fail without losing the data. The replication factor of 3 is a sane default since it guarantees tolerance of a node failure even during the maintenance of one other broker.
You may ask why topic A was divided into two partitions; what is the benefit? First, please notice that leader of Partition 1 is on a different node than the leader of Partition 2. This means that if clients produce/consume data to/from this topic, they may use the disk throughput and performance of 2 nodes instead of 1. On the other hand, there is a cost to this decision: message ordering is guaranteed only within a single partition.
Producers and Consumers
Now that we have some understanding of how Kafka works internally, let's take a look at how the situation looks from the perspective of producers/consumers.
Producer
Let's start with the producer. As mentioned above, replication or assignment of topics/partitions is a concern of Kafka itself and is not visible to producers or consumers. So the producer only needs to know which topics it wishes to send data to and if these topics have multiple partitions. In case the topic is partitioned (entity-1), the producer may create as part of its code a "partitioner," which is a simple class that decides to which partition the given record belongs. So in Kafka, the partitioning is driven by the producer. In case the producer does not specify any partitioner (but the topic is partitioned), a round-robin strategy is used. Round-robin is completely fine for entities where the exact ordering is not important — there is no causal relation between the records. For example, if you have a topic with sensor measurements, these measurements may be sent by the sensors on a scheduled basis — hence there is no particular order of the records. And round-robin provides an easy way to balance the records among the individual partitions.
Our example with sensors also shows another important detail: there may be multiple producers sending the records into one topic.
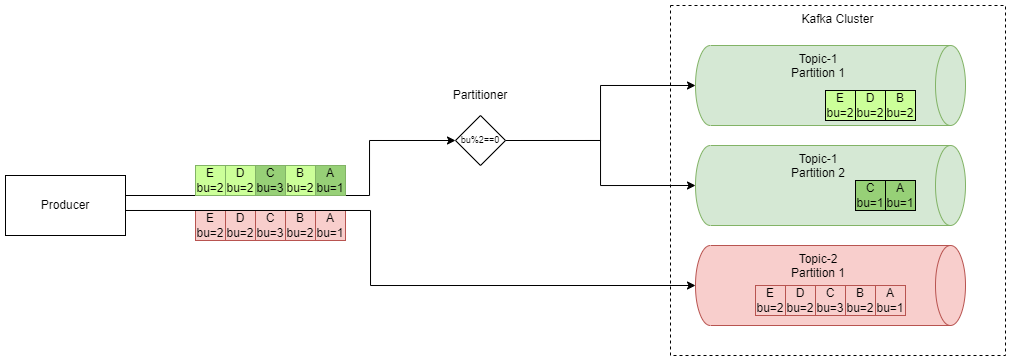
In the diagram above, we see that we have many sensors (producers) creating two types of records: humidity (in green) and CO2 concentration (in red). Each of the records also contains information about the sensor itself (such as its (serial) number, in this example integer is used for the sake of simplicity). Because each of the sensors ever produced has the capability of measuring humidity, while only some of the sensors support CO2 measurements, the designers of the systems have decided to split the humidity records into two partitions using the serial number of the sensor.
Notice that there is strict ordering within each of the humidity partitions (and within the CO2 partition), but there is no ordering of records between the partitions — in other words: B will be always processed before D and E. A will always be processed before C, but there is no ordering guarantee between B and A (or C).
Consumer
Kafka consumer is an application that reads the records from the topic. In Kafka, there is one more concept through the consumer group — a set of consumers that cooperate. When there are multiple consumers from the same group subscribed to the same topic, Kafka always distributes the partitions among the consumers in the same group in a way that each partition is read exactly once (there may be multiple partitions read by a single consumer, but one partition will not be read by multiple consumers). In case some of the consumers fail, Kafka will automatically reassign partitions to other consumers (please note that consumers do not need to subscribe to all topics).
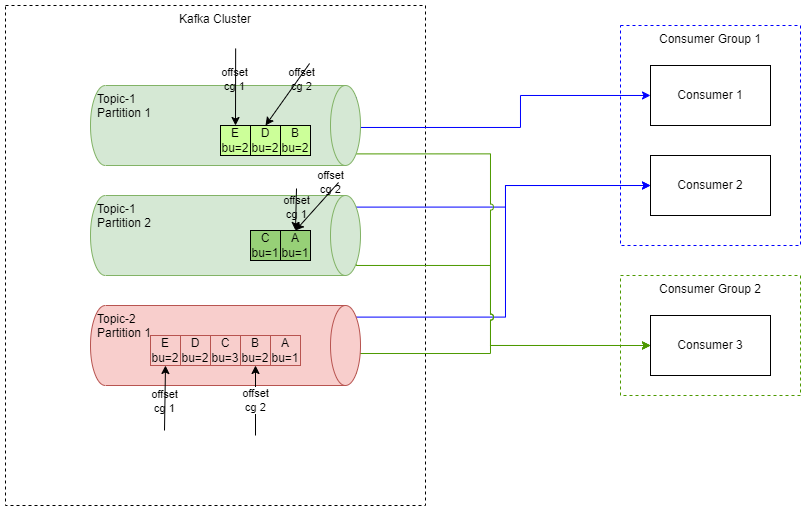
But in case of a failover or switchover, how does Kafka know where to continue? We have already said that a topic contains all the messages (even the messages that were already read). Does this mean that the consumer must read again the whole topic? The answer is that the consumer is able to continue where the previous one stopped. Kafka uses a concept called an offset, which is essentially a pointer to a message in the partition, which stores the position of the last processed message by any given consumer group.
Offset
While it may seem trivial, the concept of offsets and distributed logs is extremely powerful. It is possible to dynamically add new consumers, and these consumers (starting from offset=0) are able to catch up with the full history of data. While with traditional queues, the consumers would need to somehow fetch all the data from consumers (because messages are deleted once read in classic messaging). This data sync is more complex because either the producer produces the messages into the one queue used for increments (and affects all other consumers), or the consumer needs to use some other mechanism (such as REST or another dedicated queue), which creates data synchronization issues (as two independent unsynchronized mechanisms are used).
Another huge benefit is that the consumer may any time decide to reset the offset and read from the beginning of the time. Why would one do that? Firstly there is a class of analytical applications (such as machine learning) that requires processing the whole dataset, and offset reset gives such a mechanism. Secondly, it may happen that there is a bug in the consumer, which corrupts the data. In this case, the consumer product team may fix the issue and reset the offset – effectively reprocessing the whole dataset and replacing corrupt data with the correct one. This mechanism is heavily used in Kappa-architecture.
Retention and Compaction
We have above stated that the commit log is append-only, but this does not imply that the log is immutable. In fact, this is true only for certain types of deployments, where it is necessary to hold the full history of all changes (for auditing purposes or to have real kappa architecture). This strategy is powerful but also has a price. Firstly performance: the consumer needs to go through huge volumes of data in order to get on top of the log. Secondly, if the log contains any sensitive information, it is hard to get rid of it (which makes this type of log unfriendly to regulations that require the data to be erased on request).
But in many cases, the logs have some fixed retention — either size or time-based. In this case, the log contains only a window of messages (and any overflow is automatically erased). Using a log as a buffer makes the log size reasonable and also ensures that the data does not stay in the log forever (making it easier to adhere to compliance requirements). However, this also makes the log unusable for certain use cases — one of these use cases is when you want to have all the records available to newly subscribed consumers.
The last type of log is the so-called compacted log. In a compacted log, each record has not only a value but also a key. Whenever a new record is appended to the topic, and there is already a record with the same key, Kafka will eventually compact the log and erase the original record. Be aware that this means for a certain time, there will be multiple records with the same key, and the up-to-date value is always in the most recently inserted record — this does not require any additional handling in case you go with at-least-once semantics (it is guaranteed that the message will be delivered, but in case of any uncertainty (for example due to network issues), the message may be delivered multiple times).
You can picture the compacted log as a streaming form of a database that allows anyone to subscribe to the newest data. This image of Kafka is a very correct one because there is a duality between a stream and a table. Both these concepts are merely different views of the same thing — in SQL DB, we also use tables, but under the hood, there is a commit log. Similarly, any Kafka topic (compacted included) can be viewed as a table. In fact, the Kafka Streams library builds on this duality. There is even ksqlDB (Kafka SQL) that allows you to issue SQL statements over records in Kafka.
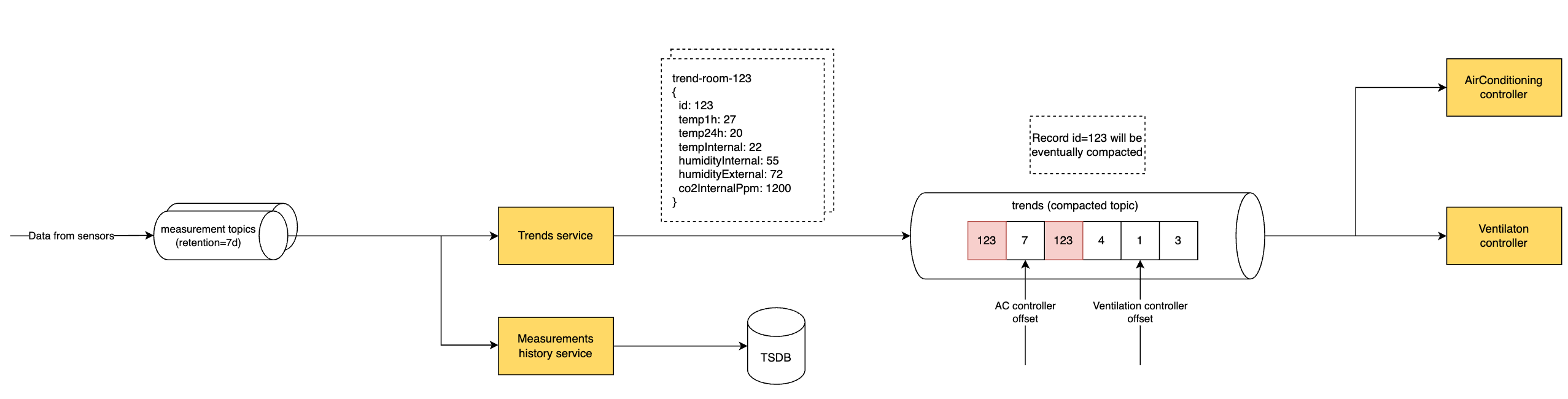
In the topology above, we see that the inbound measurement topics (temperature, humidity, co2…) are normal topics with retention set to seven days. The retention allows the developers to time travel a week back in case they find a bug in their implementation. From these inbound topics, the data are read by two services (each in a separate consumer group). The measurements history service stores the telemetry into a time-series database (long-term storage), which may be used as a source for graphs and widgets in the UI of the system.
The trends service aggregates the data (creates 24h windows of the measurements in the given room), so these can be used by downstream controllers and sends the results through a compacted topic. The topic is compacted because there is no need to keep any historical records (only the latest trend is valid). On the other hand, the customer may add a new device (and associated controller) at any time, so we want to ensure that the latest readings for the given room are always present.
Patterns and Principles
In the previous paragraphs, we presented basic concepts. In this section, we'll expand on those and discuss a few other Kafka patterns.
Eventually Consistent Architecture
In data synchronization architecture based on messaging, we want to ensure that whenever new data is produced in one product, it will be available to all relevant products in near-real-time. This means that if the user creates/modifies some entity in product A and navigates to product B, he/she should (ideally) see the up-to-date version of this entity.
However, since the individual products use multiple independent databases, it is not practical to have a distributed transaction mechanism and have atomical consistency between these databases. Instead, we go with the eventual consistency. In this model, the data producer is responsible for publishing any record it creates/updates/deletes to Kafka, from which an interested consumer may retrieve the record and store it locally.
This propagation between systems takes some time.
- Less than a second (expected) between the publishing of the record and the moment when the record is available to subscribers
- Also, the consumer may optimize writes to his database (e.g., batch writes).
During this time period, some of the systems (the replicas) have slightly stale data. It may also happen that some of the replicas will not be able to catch up for some time (downtime, network partition). But structurally, it is guaranteed that all the systems will eventually converge to the same results and will hold a consistent dataset — hence the term "eventual consistency."
Optimizing Writes to the Local Database
As alluded to in the previous paragraph, consumers may want to optimize writes to their local database. For example, it is highly undesirable to commit on a per-record basis in relational databases because transaction commit is a relatively expensive operation. It may be much wiser to commit in batches (commit every 5000 records; at a maximum of 500ms intervals — whatever comes first). Kafka is well able to support this (because committing to an offset is in hands of the consumer).
Another example is AWS Redshift, which is a data warehouse/OLAP database in which commits are very expensive. Also, in Redshift, every commit invalidates its query caches. And as a result, the cluster takes the hit of the commit twice — once to perform the commit itself and for the second time when all previously cached queries must be re-evaluated. For these reasons, you may want to commit to Redshift (and similar technologies) on a scheduled basis every X minutes to limit the blast radius of this action.
The last example may be NoSQL databases that do not support transactions. It may be just fine to stream the data on a per-record basis (obviously, depending on the capabilities of the DB engine).
There is one takeaway: different replicas may use a slightly different persistence strategy, even if they consume the same data. Always assume that there is a possibility that the other side does not have the data available yet.
Referential Integrity Between Topics
It is important to understand that since the Kafka-based data synchronization is eventually consistent, there is no implicit referential integrity or causal integrity between the individual topics (or partitions). When it comes to referential integrity, the consumers should be written in a way that they expect that they may receive, for example, measurements for a room that they have not received yet. Some of the consumers may overcome this situation either by not showing the data at all till all the dimensions are present (for example, you can't turn on ventilation when you do not know the room). For other systems, the missing reference is not really an issue: the average temperature in the house will be the same, regardless of the presence of room details.
For these reasons, it may be impractical to impose any strict restrictions centrally.
Stateful Processing
Kafka consumers may require stateful processing — such as aggregation, window function, and deduplication. Also, the state itself may not be of a trivial size, or there may be a requirement that in case of a failure, the replica is able to continue almost instantly. In these cases, storing the results in the RAM of the consumer is not the best choice. Luckily, the Kafka Streams library has out-of-the-box support for RocksDB — a high-performance embedded key-value store. RocksDB is able to store the results both in RAM and on disk.
Caching Strategy and Parallelism
Closely related to stateful processing is a caching strategy. Kafka is, by its design, not well suited for the competing consumer's style of work because each partition is assigned to exactly one processor. If one wants to implement competing consumers, he needs to create significantly more partitions than there are consumers within the system to emulate the behavior. However, this is not the way parallelism should be handled in Kafka-based systems (in case you really need a job queue of unrelated jobs, you will be much better off with RabbitMQ, SQS, and ActiveMQ…).
Kafka is a stream processing system, and it is expected that the records in one partition somehow relate to each other and should be processed together. The individual partitions act as data shards, and since Kafka guarantees that each of these partitions will be assigned to one and exactly one consumer, the consumer can be sure that there is no other competing processor — so it can cache the results as it sees fit in its local cache and does not need to implement any distributed caching (such as Redis). In case the processor fails/crashes, Kafka will just reassign the partition to another consumer, which will populate its local caches and continue. This design of stream processing is significantly easier than competing consumers.
There is one consideration, though. That is the partitioning strategy because that is defined by default by the producer, while different consumers may have multiple mutually incompatible needs. For this reason, it is common in Kafka's world to re-partition the topic. In our scenario, it would work the following way:
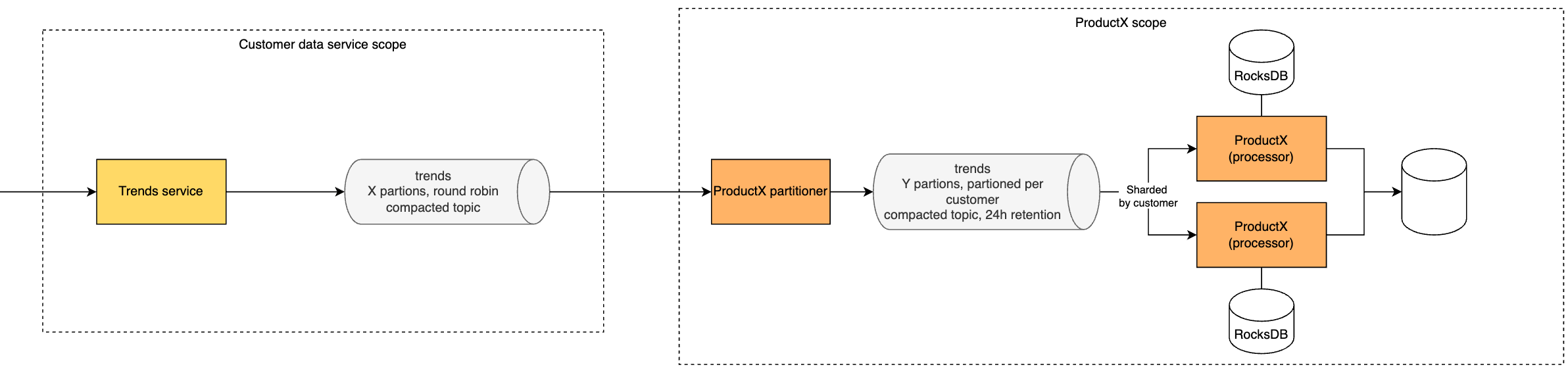
In Kafka Streams, you may want to join several entities in order to combine the data (this is a common use case). Beware that in case you have multiple consumers, you need to have the inbound topics partitioned in the exact same way (same partitioner (join key based), same number of partitions). Only this way, you have guaranteed that the entities with matching join keys will be received by the same consumer (processor).
Summary
In this article, we have discussed how the overall architecture of Kafka and how this low-level architecture allows the broker to easily scale horizontally (thanks to partitioning) and ensure high availability and durability (thanks to leader/replica design and master election). We also went through the basics of designing Kafka-based topologies, explained eventual consistency and how that affects the guarantees given to our applications, and learned how to use Kafka's different types of logs and their retention.
While Kafka may seem overwhelming at first, it is important to realize that internally it is based on the plain old good distributed log. This relatively simple internal structure is what gives Kafka its straightforward semantics, high throughput, and low data propagation latencies. Qualities are crucial for building any data pipeline.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK