

微服务 - Redis缓存 · 数据结构 · 持久化 · 分布式 · 高并发
source link: https://www.cnblogs.com/Sol-wang/p/17329270.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

系列目录:
微服务 - 概念 · 应用 · 通讯 · 授权 · 跨域 · 限流
微服务 - 集群化 · 服务注册 · 健康检测 · 服务发现 · 负载均衡
微服务 - Redis缓存 · 数据结构 · 持久化 · 分布式 · 高并发
本篇内容基于 Redis v7.0 的阐述;官网:https://redis.io/
本篇计划用 Docker 容器辅助部署,所以需要了解点 Docker 知识;官网:https://www.docker.com
一、分布式解决 Session 的问题
在单站点中,可以将在线用户信息存储在Session中,随时变更获取信息;在多站点分布式集群如何做到Session共享呢?架设一个Session服务,供多服务使用。
频繁使用的数据存在DB端,频繁的DB连接,频繁的IO;数据存于内存中更能减少性能的消耗,更能提高使用效率。
集群化分布式时,为解决以上现象,建立缓存服务显得尤为重要。
建立缓存服务选择性很多,如:Redis、MongoDB等,以下以 Redis 为例:
二、内存数据库 Redis
Remote Dictionary Server;
远程字典服务,Key/Value 存储系统、列存储、文档型存储等,NoSQL开源内存数据库。最多的使用场景是作为数据缓存,存在于应用与DB之间,减少对DB的访问,提高数据操作的性能。
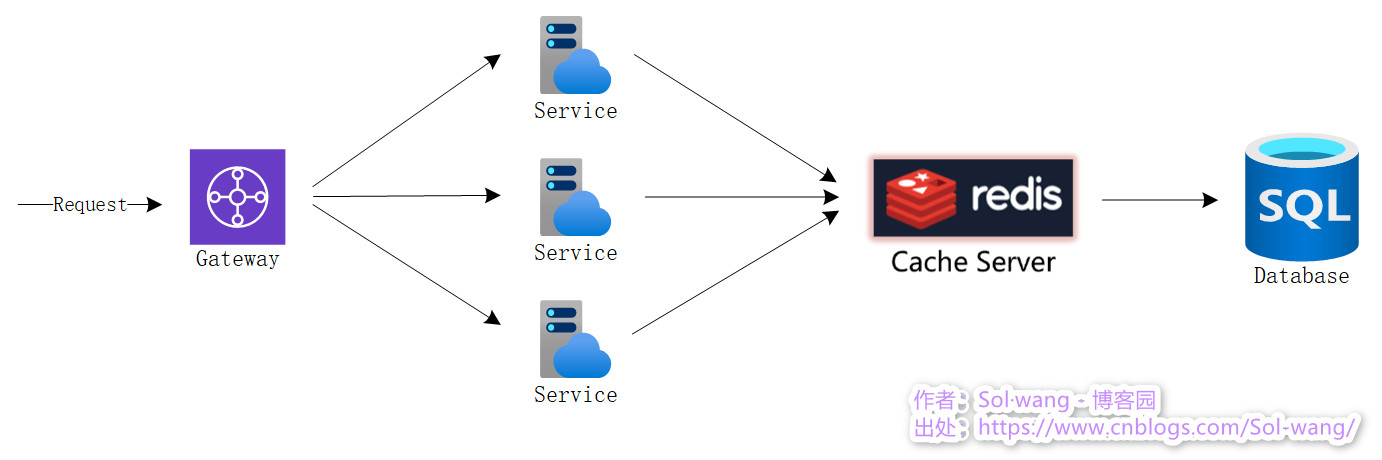
下图展示了缓存服务在整体架构中的位置:
2.1 Redis 特性
高性能 / 高可用 / 持久化 / 集群化,单实例每秒读写达10万次;
丰富的数据类型 :String / Hash / Set / Zset / 队列 / 订阅 / 发布;
高性能数据结构:SDS / Intset / ziplist / listpack / quicklist / skiplist;
支持 ACL:Access Control List;精细化的权限管理策略;
单线程处理事务:顺序执行,容易上锁;
多线程处理辅助功能:连接请求 / 持久化等;
单线程处理事务的优缺点
优点:顺序执行,不存在脏读脏写幻读等情况,不存在死锁,不存在线程管理的开销。
缺点:单线程的性能瓶颈,多处理器的资源浪费。
2.2 单线程IO多路复用
通常情况下,同时连接 Redis 的客户端有成千上万的,但 Redis 只有一个主线程处理事务,那如何做到多路连接集中到一个线程处理呢?
当多个客户端同时发起连接后,这也是需要一个过程的,也是有连接完成的先后,谁连接完成就会告诉 Redis,这里的告诉用的是回调方式,Redis就会把他的任务放到单一的队列中,队列的另一头连接着主线程。
在这个过程当中,多路的连接汇集到一个有足够处理能力的队列中进行传输;是不是可以理解为:多路连接重复利用了单个管道;我想...这里也是体现了 Redis 的多路复用技术。当然,单单就多路复用来讲,也会是多路集中到一路,然后这一路又分成了多路到各各目标。
多路复用也有不同的算法:select、poll、epoll,Redis用的是epoll算法,所以其中有回调的动作,目前而言,epoll是最高效的;关于每个具体的算法,有兴趣的同学可以继续研究一下。
2.3 启动 Redis
用 Docker 启动 Redis 简单示例:
1、拉取镜像docker pull redis
2、运行容器 docker run -d --name=some-redis redis
3、连接到 Redis docker exec -it some-redis redis-cli
Redis Docker版默认是没有配置文件的,官网说:可以再生成镜像方式解决...
既然没有配置文件,那 Redis 启动完全是按所有配置项的默认值运行的;如下传参启动:
# 启动 redis-server,多参数配置
docker run -d --name some-redis -p 6379:6379 redis redis-server \
--bind 0.0.0.0 \ # 支持任意的连接
--save 60 1 \ # 每60秒 持久化一次
--protected-mode no \ # 取消保护模式
--requirepass 123456 # 登录密码 123456;连接后用 auth {passwd} 方式登录传参也就是覆盖了配置项的默认值,以下查看覆盖后的配置项效果:config get *列出所有配置项

Redis 启动后,都包含 redis-server / redis-client;
所以任意 Redis 都可用 redis-client 连接到其它 redis-server:docker exec -it some-redis redis-cli -h {目标IP} -p {目标端口}
2.4 重要配置项
通常配置参数于配置文件中;比如:/etc/redis/redis.conf
| 配置项 | 说明 |
|---|---|
| bind | 可访问限制,白名单;注释后不限制 |
| port | 对外端口 |
| timeout | 连接后,没有通信任务的空闲时间,超出此时长后自动断开 |
| daemonize | 后台运行(容器运行时忽略) |
| protected-mode | 只能本地访问的保护模式 |
| tcp-backlog | 网络连接队列最大连接数(对应Linux内核参数 net.core.somaxconn,有关命令sysctl) |
| tcp-keepalive | 网路通信检测间隔,网络是否已断开(当timeout为0才起效吧) |
| pidfile | 存放ProcessID编号的文件Pid的存放目录(后台运行时才会产生pid文件,容器时是否忽略) |
| loglevel | 日志级别 |
| logfile | 日志文件目录 |
| database | 数据库个数 |
| requirepass | Client 连接密码 |
| maxclients | 客户端同时最大连接数(对应Linux user openfile limit,必设;有关命令ulimit) |
| maxmemory | 内存最大使用量,推荐70% |
三、数据类型 / 常用命令
Key/Value 的存储系统,Key相当于区分的变量名称,类型区别在于Value;常用数据类型有:
String:字符,基础类型,过期时长,递增
SET/GET key value写入/取值GET key key key取多个值INCR/DECR key递增1/递减1
List:队列,先进先出,先进后出
LPUSH/RPUSH key value头/尾添加LPOP/RPOP key头/尾移除LLEN key队列长度
Set:无序集合,可查询 交集、并集、差集等
SADD|SREM key member member member插入/移除 元素SISMEMBER key member是否存在成员SINTER key1 key2多集合取交集SCARD key元素个数总数
ZSet:带排序的Set集合;比Set多出一个专用的score值,又可排出名次列
ZADD key score member score member新增成员及序列数,可覆盖ZRANGE key start stop按序列范围取集合ZRANK key member取正序排名;从0开始的名次ZREVRANK key member取倒序排名;从0开始的名次
Hash:可同时设置/获取多个属性值
HSET key field value field value成对设置多个属性与值HMGET key field [field field]取多个列的值HINCRBY key field -5指定属性的值,递增/递减
四、数据结构
为什么 Redis 要有自己的数据结构
- 查询要快:体现在单条Key用了连续性的内存空间
- 占用空间少,节约内存:体现在了集合的数据压缩
Redis 中有这么几种数据结构:sds (动态字符串)、hashtable (字典)、linkedlist (链表)、intset (整数集合)、ziplist (压缩列表)、listpack (紧凑列表)、quicklist (混合列表)、skiplist (跳表);它们分别应用于Redis各数据类型中,使得Redis在资源利用和运行效率上有着明显的效果。
以下列出了数据类型与数据结构的应用关系图:
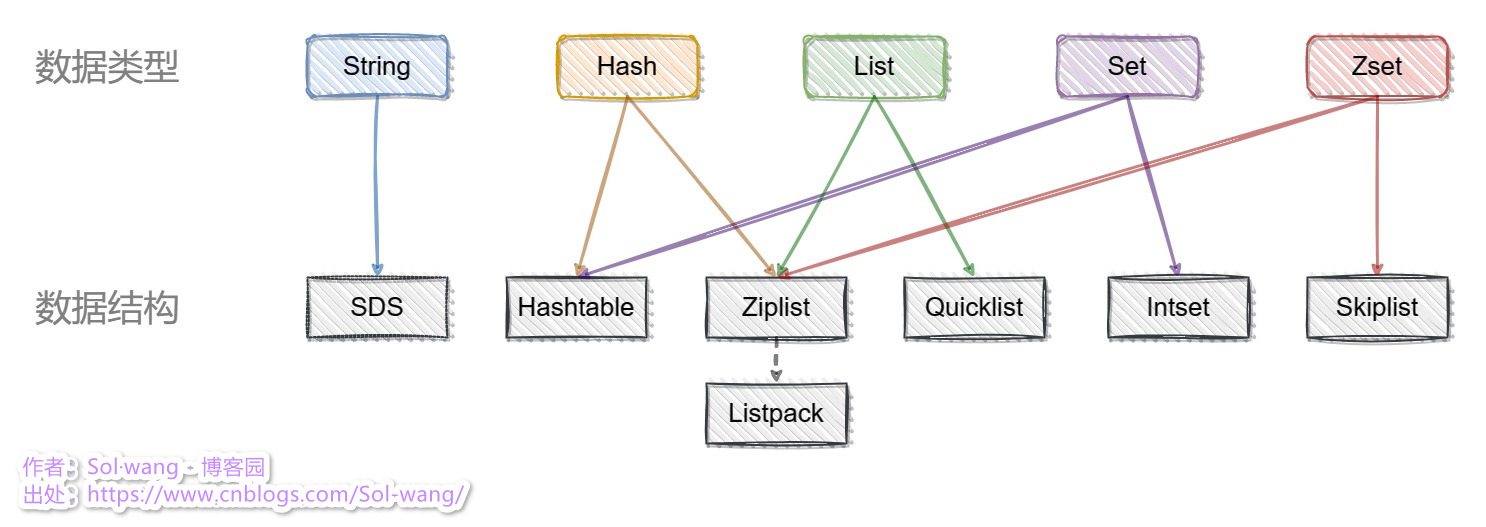
关于 Listpack;未来作为 Ziplist 的升级替代品,v7.0版本也会有 Ziplist 的存在,后续版本中逐渐被替代。
数据结构的自动切换
每种数据类型也会有多种数据结构,至于何种数据类型在什么情况下用何种数据结构,取决于存储的数据;
比如:List 每元素小于8KB时,自动使用 Ziplist,否则自动切换为 Quicklist;
比如:Set 每元素为数字,元素小于512个时,自动使用 Intset,否则自动切换为 Hashtable;
比如:Hash 元素小于512个,每元素长度小于64字节,自动使用 Ziplist;否则自动切换为 Hashtable。
影响数据结构转换的配置项
# 配置文件中 各数据类型中的数据结构
# 能承载的最大长度/个数/容量
# 超出最大限制后,变更为其它数据结构
hash-max-listpack-value 64
hash-max-listpack-entries 512
list-max-listpack-size -2(8KB)
set-max-intset-entries 512
set-max-listpack-value 64
set-max-listpack-entries 128
zset-max-listpack-value 64
zset-max-listpack-entries 128以下主要以 sds / ziplist / listpack / skiplist 为例的阐述,基本涵盖了重要的数据结构,一些扩展性的数据结构有兴趣的同学再深入了解下。
4.1 动态字符串 - SDS
很多计算机语言都一样,Redis 也是基于C语言写的;对于String类型,当给一个变量拼接一个字符串时,都是以一个新对象在内存中重新开辟新的更长的连续空间来存储;重新开辟/释放旧空间这样的内存损耗。。。所以为什么开发人员会避免strname + "xxx"这样的拼接方式;字符串长度也是底层每次通过遍历得出的结果。。。Redis为了避免这样的损耗,于是就有了 Simple Dynamic Strings 这样的解决方案 SDS。
Redis String 会事先分配好比实际字符串更长的内存空间,并记录实际字符串的长度,也记录存储后剩余的空间长度。
- 取字符串长度时,直接返回记录的长度值
- 追加字符串时,直接使用空闲的剩余空间
预分配空间有多长?总有用完的时候:
- 当实际字符串长度<1M时,预分配实际字符串两倍的连续长度,相当于本次只会占用一半
- 当实际字符串长度>1M时,每次预分配多出1M的长度空间。便于下次直接存储
- 当字符串减少缩短时,多出的剩余空间保留,便于下次追加,或手动命令清除空闲空间
这种 空间预分配策略 和 惰性删除策略 就是SDS的性能优势。
4.2 压缩列表 - ziplist
一块连续性的内存空间存放了整个Value,也就是一个ziplist,如何做的呢?一个集合的示例:
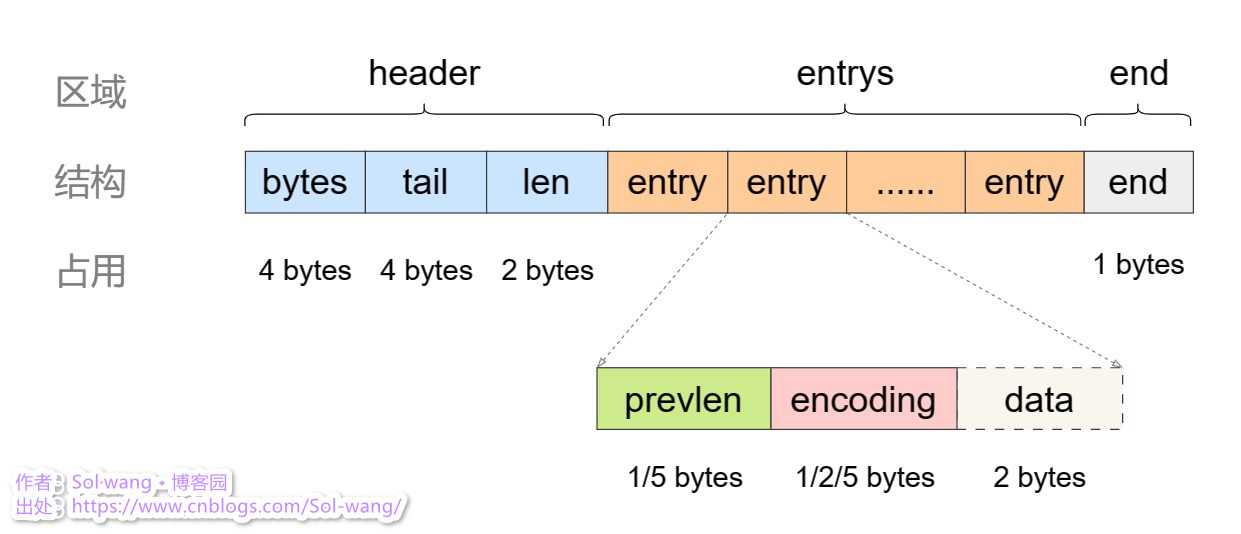
bytes:记录 ziplist 的总长度
tail:记录最后一个 entry 的偏移量,便于快速定位
len:记录 entry 的总个数
entry:列表元素,数据存放的元素
end:单个 ziplist 的结束符
prevlen:记录上个 entry 的总长度;这里记录值所占用的空间长度,取决于上个 entry 的长度,所以1-5会自动切换
encoding:记录 data 的实际数据类型 及长度;如:int时占空间小,可直接存到 encoding,就不用 data 了
data:实际数据;占用空间小的数据类型,可直接放到 encoding 中,所以这时候没有 data 的存在,省空间。
ziplist 的取值:
结构图中,有总长/个数/偏移量/结束符/上个元素长度;所以 ziplist 正序倒序是都可以算出每个 entry 具体位置并取出数据。
ziplist 的写入,插/改/删 统一为覆盖方式:
1、为新元素找到被覆盖元素的位置,位置之前的元素 + 新元素 + 位置之后的元素 = 新的ziplist的完整结构
2、申请新ziplist所需长度的内存连续空间,并存入新空间
3、释放旧空间
看起来挺不错的,相比链表的非连续性存储所带来的性能提升明显。。那为什么还会有新的改进版本 listpack 的出现?
ZIPLIST 的弊端
ziplist 的问题出在 prevlen;
也就是上面蓝色部分的描述,存了相邻 entry 的长度;如果 entry 长度过长,相邻的 prevlen 所占空间长度就会从1变为5;也就是说 entry 数据变更,会影响到相邻的 entry;最严重的情况是很多entry长度恰好都在一个临界值,会导致相邻prevlen长度的变化,连锁反应是之后位置上的entry级联性的连续重复多次变更;
上面提到,变更:就是重新申请新的内存连续空间,释放旧空间;那么级联性的连锁反应呢?一个写操作,引发的恶性灾难事件!!!
4.3 紧凑列表 - listpack
listpack 是 ziplist 的升级版于v7.0中,作为替代品都有什么变化,listpack结构如下图:
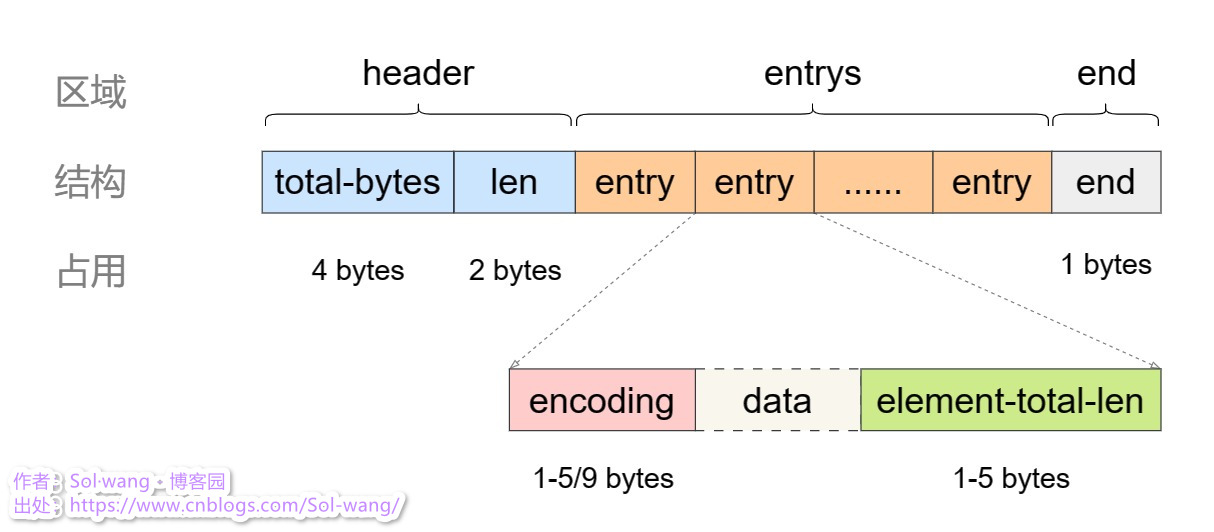
上图看出,listpack 与 ziplist 的区别在于:
1、header 取消 tail
2、entry 取消 prevlen
3、当前 entry 中增加 encoding + data 的总长度 element-total-len
4、element-total-len 中的首位会标识出左侧是否还有值,主要用于逆序读
element-total-len 编码
长度 1-5 bytes 是可变的,不固定长度如何读出整个 element-total-len?这其中0/1标识了左侧是否有数据;
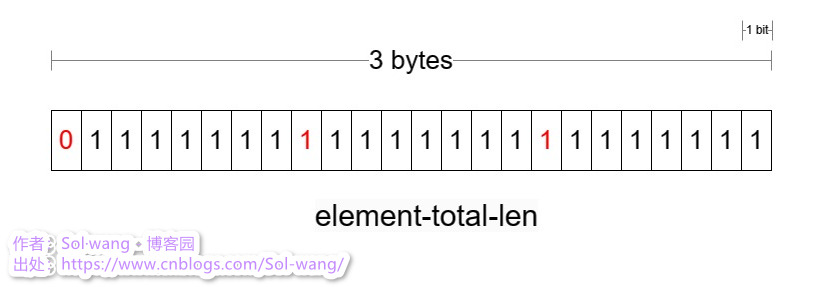
listpack 的读,假设逆序读出每个元素的值,已知end固定长度,跳过 1 bytes 到 element-total-len 中读固定(7)位数,就会知道左侧是否有值,这样会把 element-total-len 整个读下来,也就知道了当前 entry 长度,那么也就知道了相邻 entry 的起始位置;继续这样按序把每个 entry 读出来就完成逆序读数据。
listpack 的写入,同样是基于 ziplist 的方式,新元素替换旧元素组成新的长度,存储到新申请的内存连续空间,释放旧空间;由于未影响到其它元素,申请一次新空间后完成写入操作。
这样以来,listpack 任何写入的操作,entry 都是在变更自己,不会牵连到其它 entry,这就是对 ziplist 改善的地方。
4.4 跳跃列表 - skiplist
跳表是在链表的基础上追加了更多指针的存储;链表的指针指向了相邻元素的地址,但跳表又追加了指向间隔元素的指针;这使得跳表在查询元素的效率上更快。
下表 Linkedlist 与 Skiplist 的查询区别:
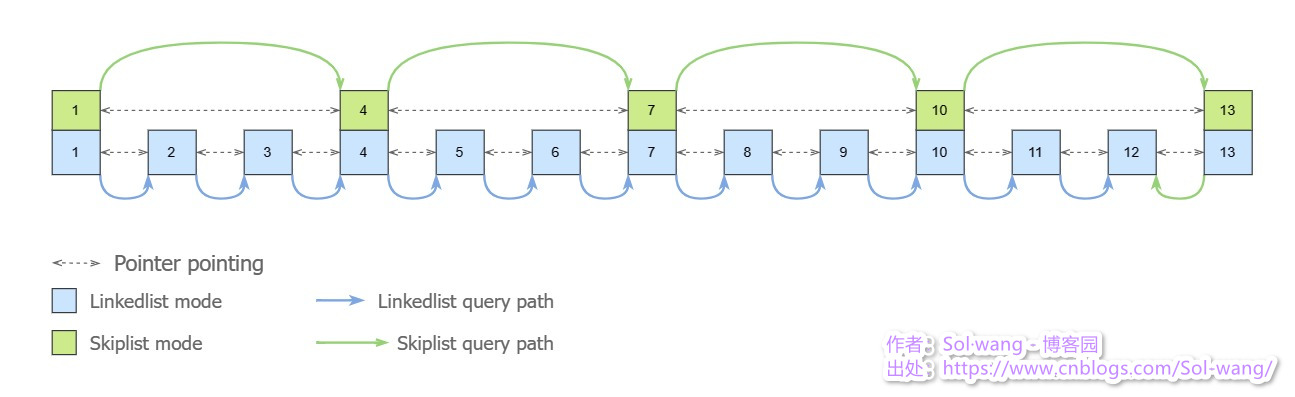
上图:两种查询的路径不同,影响到的元素数量也不同,链表搜了11次才找到指定的元素,而跳表仅搜了5次就找到了指定的元素。
比如:元素1 既存了指向下个元素2 的指针,也存了指向元素4 的指针;所以跳表多存的指针让其可以跳跃搜索,相对于链表减少了搜索次数,这就体现了相比链表搜索的高效率。
其它数据结构
除以上几种数据结构外,Redis也会有Intset、quicklist、Hashtable等,由于基本原理相识,这里简单描述:
Intset:与ziplist、listpack相似的连续性集合,主要区别在于Intset仅支持数字型;
quicklist:在 ziplist 基础上扩展的数据结构,其中每个成员是一个ziplist,插入元素时:插入到前个元素ziplist中的末尾、后ziplist的开头、或独立的ziplist。
五、持久化
5.1 RDB 模式
Redis Database:持久化以指定的时间间隔执行数据集的时间点的快照整库备份。
触发RDB配置:save 36000 1 600 10 30 100
以上从右往左,成对解释:
当30秒内写入了100次,触发持久化,如果未满足条件,继续下一对;
当600秒内写入了10次,触发持久化,如果未满足条件,继续下一对;
当36000秒内写入了1次,触发持久化。
持久化过程:内存 -> 临时文件 -> 磁盘。
影响RDB效率的配置项:
stop-writes-on-bgsave-error yes当持久化失败后强制停止写入
rdbcompression yes快照数据压缩,损耗CPU
rdbchecksum yes是否检测备份文件,损耗CPU≈10%
关闭RDB持久化模式:save ""
模式优劣
优势:体积小,占用磁盘少。
劣势:当持久化发生异常时,最后一次的持久化有可能失效,不能确保整体数据的绝对完整性。
5.2 AOF 模式
Append Only File:追加记录服务器接收到的每个写入命令,增量保存;如果写入错误,Redis 也会具有自动修复受损的AOF文件;恢复时,重新按序执行指令,从而重建内存库。
配置开启AOF模式:appendonly yes
持久化频率策略配置:appendfysnc always|everysec|no
- 每次命令追加:每次写命令立刻记录,太频繁,太耗性能
- 每秒追加一次:每秒集中记录一次,依然有可观的性能表现
文件压缩 Rewrite
主进程 redis-server 创建出一个子进程 bgrewriteaof 对 AOF文件的重新整理,先整理出一个临时文件,再覆盖原AOF文件。
Rewrite 的重写策略:
- 只针对写入命令的整理
- 相同数据只记录最后写入命令
- 过期数据不记录
- 多命令合并记录
多命令合并示例:如累加命令 Incrby 的累加总和合并成一次累加;如集合命令 rpush 的多次追加合并成一次追加多个。
手动触发执行重写命令:bgrewriteaof。
自动触发重写相关配置:no-appendfsync-on-rewrite no重写开关auto-aof-rewrite-min-size 64mb重写触发条件,文件超过指定大小auto-aof-rewrite-percentage 100重写触发条件,文件超过已使用%
AOF文件64MB是不是显得太小了,可适当增加容量如3GB,以防止过多的触发压缩重写后影响性能;也不可过大,影响数据恢复效率。
模式优劣
优势:丢失率低,数据较完整。
劣势:AOF占用磁盘空间大;恢复时重新全部执行一遍命令,恢复速度慢了点;持久化失败时,最后一秒写入命令可能丢失。
Redis 默认开启 RDB,可同时开启 RDB + AOF,恢复数据时以 AOF 为优先。
由于是单线程方式,Redis 会创建子线程负责持久化处理,不管是哪种持久化方式,在创建子进程的瞬间,都会有阻塞的现象。
六、分布式集群
6.1 虚拟插槽
Redis 分布式给出一个 16384 长度的集合,每个元素称为一个 Slot,将所有 Slots 分段平均映射到各个 Master 节点上;数据通过对 Key 的算法映射到各Slot,也就存到了对应的 Master 节点上,所以每个节点实例负责其中一部分的Slot读写。
通过控制节点与槽 Slot 的关系,决定每个 Master 节点所承载的数据量;这在集群节点维护的时候非常有用。
6.2 创建集群
集群必须了解的conf配置项:
# 每个节点必须的配置项
cluster-enabled yes
# 节点失去连接超时时间
cluster-node-timeout 15000
# 节点间传输效率 默认 no(yes:单次多量发送/no:单次少量多次发送)
tcp-nodelay no
# DOCKER/NAT support
# (地址端口可能被转发)静态配置公共地址
cluster-announce-ip <外部访问IP>
cluster-announce-port <外部访问端口>
cluster-announce-bus-port <节点互通外部端口>按 Redis 要求的最低 Master 节点数量3实例,多主多从的模式,需要创建6个运行实例:(6371-6376,16371-16376)
# 实例示例1(6371,16371)
docker run -d --name clu-rds-1 \
-p 6371:6371 -p 16371:16371 \ # 容器分别开放 对外连接端口 和 节点间通信端口
redis \
redis-server \ # 启动 Redis 服务命令
--bind 0.0.0.0 \ # 不限连接的客户端来源
--port 6371 \ # 实例对外连接端口
--protected-mode no \ # 非保护模式
--cluster-enabled yes \ # 开启集群
--cluster-announce-ip 13.13.1.16 \ # 对外的访问IP
--cluster-announce-port 6371 \ # 集群对外的连接端口
--cluster-announce-bus-port 16371 # 集群节点间通讯端口(通常为:10000+Port)Docker 查看6个容器实例:
Docker 3主3从模式 创建集群:
docker exec -it clu-rds-1 \
# 连接到任意实例
redis-cli -p 6371 \
# 创建集群 并指定 1主几从
--cluster create --cluster-replicas 1 \
# 要包含的所有(6个)运行实例<ip:port>
13.13.1.16:6371 13.13.1.16:6372 13.13.1.16:6373 \
13.13.1.16:6374 13.13.1.16:6375 13.13.1.16:6376
连接到任意容器节点,查看集群成员:docker exec -it <container-name> redis-cli -p <container-port> cluster nodes

6.3 节点管理
# 集群信息
redis-cli -p <port> cluster info
# 查看现有节点成员
redis-cli -p <port> cluster nodes
# 加入新成员,从节点
redis-cli --cluster add-node <new-node-ip:port> <cluster-member-ip:port> \
--cluster-slave --cluster-master-id <to-master-id>
# 删除集群成员节点
redis-cli --cluster del-node <del-ip:port> <del-node-id>
# 重新分配节点与插槽映射
redis-cli --cluster reshard <member-ip:port>
# 查看某节点同步信息
redis-cli -p <port> info replication
# 停止某节点实例运行
redis-cli -p <port> shutdown分布式带来的影响
事务支持有限;
跨节点的多Key操作有限;如:SET集合不能计算两KEY的交集等
6.4 分布式锁
6.4.1 为什么会需要锁?
🔲场景 A:
多用户对同一产品下单购买,库存有10个,同一时间进来100个用户各买一个;
购买前都会看下库存是否够买,才会生成订单,否则提醒无货;
当前10个用户还没有下单成功并未扣库存完成时,后90个用户看到有库存,也继续生成订单;
最后卖出100各产品,实际库存不够。。。
如何确保有库存,不超买。
对库存加锁,每个用户按序进来扣库存,当前用户扣完库存后,释放自己加的锁,以视完成操作继续后续用户,下个用户再进来看库存是否能购买。
🔲场景 B:
当某个用户下单扣库存时,倘若发送了异常,导致未能释放自己加上去的锁,那么。。。没人负责释放此锁了,后续不能查扣库存,谁也不能下单了。
如何确保防止不能解锁。
对库存锁加过期时间,时间超出后,自动强制解锁。
是的,加锁、过期自动解锁,是确保以上场景能够顺利进行的必要条件,共享数据被多用户处理的时候,同一时间点,只能被一个用户访问处理,多用户有序访问处理,及时更新处理结果。
共享锁:数据统一放缓存中做业务处理,在缓存中加锁,供所有服务利用。
6.4.2 SET NX EX 命令
- SET:String 类型的KV操作
- NX:Key唯一,仅当没有Key时才能写入
- EX:Key 的有效时长,到期后自动删除
所以完整的命令为:set {business-key} {value} nx ex {过期时长}
返回失败,表示上个用户正使用
返回成功,表示自己已开始使用
符合分布式锁的必要条件
1、当 get {business-key} 有值时,表示已有用户在占用,需要等待
2、当 占用用户处理完成后,正常释放自己加的锁,del {business-key}
3、当 占用用户处理发生异常退出时,等ex {过期时长}后,系统自动解锁,后续用户继续购买
命令演示案例:(ttl:剩余过期时间秒)

也可以在 Value 中保存用户的标识,解锁的时候只能解除自己的锁,防止某些场景下解锁错误。
分布式Id
由于 Redis Incrment (Incr/Incrby),过期时长等,可以限制用户短时间内的下单量等场景,也可以生成唯一标识,用到各服务中。
6.4.3 Lua 脚本
持续更新。。。
七、高并发带来的问题
7.1 缓存穿透
现象:
DB没有查询结果或为NULL,导致查询结果没有进入到缓存;当大批量的这种请求时,就会每次“穿透”缓存“直抵”DB,引发DB的高并发查询导致宕机,这种现象就叫缓存穿透。
方案:
黑名单策略(IP/用户名),防止恶意行为
对结果为空的DB查询,给出默认值于缓存中
7.2 缓存击穿
现象:
单个访问量大的 Key (热门数据)过期后,缓存需要重建该Key,大量的访问到DB引发高并发查询,导致DB宕机,这种情况称为缓存击穿。
方案:
当然也可以使用队列,就降低了并发的性能;也可以设置过期时间为永不过期;以下的重点是缓存重建Key的过程:双重锁机制
双重锁逻辑阐述:(也常应用于单例模式中)
第一把锁处理首个请求动作是否已有缓存,并挡住了第二或大量的后续请求动作;
当首个请求动作处理完成后结果于缓存中,并释放锁,处于等待的大量的请求动作会陆续进来,这就不对了,等待的请求动作应该直接用首个请求处理的结果才对;
所以,后续的请求进来后应该再次锁验证缓存中是否已有数据,也就是第二次的锁是为了解决并发时被阻塞的请求动作,防止重复查询DB更新缓存。
7.3 缓存雪崩
现象:
缓存中的热门 Key 短时间内大批量的同时过期,缓存运行正常,导致DB查询压力短时间内上升至宕机的现象。
方案:
随机的过期时间,分散过期时间,避免统一生成过期时间
为热度追加排名,时时调整热度数据,自动延长过期时间
Recommend
-
126
如何基于 webpack 做持久化缓存似乎一直处于没有最佳实践的状态。网路上各式各样的文章很多,open 的 bug 反馈和建议成堆,很容易让人迷茫和心智崩溃。 作为开发者最大的诉求是:在 entry 内部内容未发生变更的情况下构建之后也能稳定不变。...
-
53
一,Redis作缓存服务器 本篇博客是接着 上一篇 博客未分享完的技术点。 redis作为缓存服务器是众多企业中的选择之一,虽然该技术很成...
-
30
一、前言 本篇主要使用StackExchangeRedis在.Net Core中使用Redis,使用基础见:点击此处。 二、五种基础数据结构 1.字符串类型String 字符串类型是Redis中最基本的数据类型,它能存储任何形式的...
-
20
元旦期间 订单业务线 告知 推送系统 无法正常收发消息,作为推送系统维护者的我正外面潇洒,无法第一时间回去,直接让 ops 帮忙重启服务,一切好了起来,重启果然是个大杀器。由于推送系统本身是分布式部署,消息有做各种的可...
-
11
高并发服务遇redis瓶颈引发time-wait事故 – 峰云就她了 峰云就她了 专注于Golang、Python、DB、cluster 高并发服务遇redis瓶颈引发time-w...
-
5
英文名和中文名意思相反?!In OI By Rapiz 2017-02-13 数据结构你有一...
-
4
可持久化数据结构简介 简介¶ 可持久化数据结构 (Persistent data structure) 总是可以保留每一个历史版本,并且支持操作的不可变特性 (immutable)。 可持久化分类
-
12
## [SDB](https://github.com/yemingfeng/sdb) :纯 golang 开发、分布式、数据结构丰富、持久化、简单易用的 NoSQL 数据库 ------ ### 为什么需要 SDB? 试想以下业务场景: - 计数服务:对内容的点赞、播放等数据进行统计 - 评论服务...
-
2
为什么需要分布式锁 1.为了解决Java共享内存模型带来的线程安全问题,我们可以通过加锁来保证资源访问的单一,如JVM内置锁synchronized,类级别的锁ReentrantLock。 2.但是随着业务的发展,单机服务毕竟存在着限制,故会往多台组合形成集群...
-
4
高并发环境下构建缓存服务,你需要注意这6点 精选 原创 华为云开发者联盟 2023-01...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK