

浏览器就能跑大模型了!陈天奇团队发布WebLLM,无需服务器支持
source link: https://www.qbitai.com/2023/04/47499.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

浏览器就能跑大模型了!陈天奇团队发布WebLLM,无需服务器支持

GitHub 3.2K星
金磊 发自 凹非寺
量子位 | 公众号 QbitAI
现在,只需一个浏览器,就能跑通“大力出奇迹”的大语言模型(LLM)了!
不仅如此,基于LLM的类ChatGPT也能引进来,而且还是不需要服务器支持、WebGPU加速的那种。
例如这样:
这就是由陈天奇团队最新发布的项目——Web LLM。
短短数日,已经在GitHub上揽货3.2K颗星。

一切尽在浏览器,怎么搞?
首先,你需要下载Chrome Canary,也就是谷歌浏览器的金丝雀版本:

因为这个开发者版本的Chrome是支持WebGPU的,否则就会出现如下的错误提示:
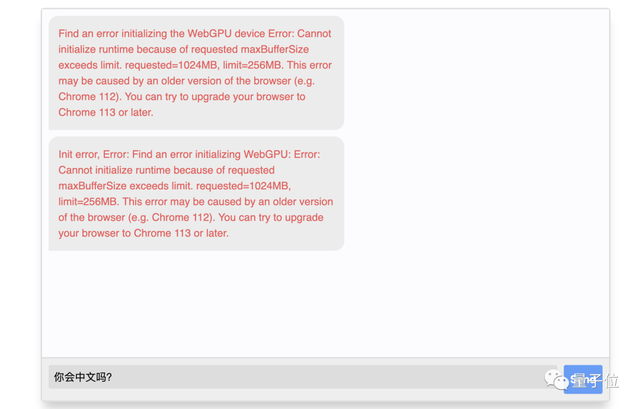
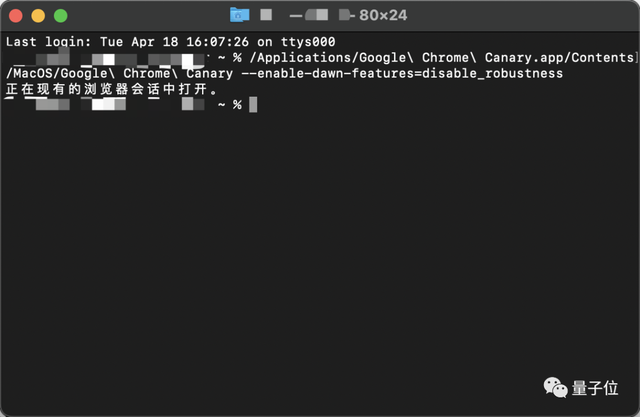
在安装完毕后,团队建议用“终端”输入如下代码启动Chrome Canary:
/Applications/Google Chrome Canary.app/Contents/MacOS/Google Chrome Canary —enable-dawn-features=disable_robustness
启动之后,便可以来到官网的demo试玩处开始体验了。
不过在第一次展开对话的时候,系统还会出现一个初始化的过程(有点漫长,耐心等待)。
机器学习编译(MLC)是关键
接下来,我们来看一看Web LLM如何做到“一切尽在浏览器”的。
根据团队介绍,其核心关键技术是机器学习编译(Machine Learning Compilation,MLC)。
整体方案是站在开源生态系统这个“巨人肩膀”上完成的,包括Hugging Face、来自LLaMA和Vicuna的模型变体,以及wasm和WebGPU等。
并且主要流程是建立在Apache TVM Unity之上。
团队首先在TVM中bake了一个语言模型的IRModule,以此来减少了计算量和内存使用。
TVM的IRModule中的每个函数都可以被进一步转换并生成可运行的代码,这些代码可以被普遍部署在任何最小TVM运行时支持的环境中(JavaScript就是其中之一)。
其次,TensorIR是生成优化程序的关键技术,通过结合专家知识和自动调度程序快速转换TensorIR程序,来提供高效的解决方案。
除此之外,团队还用到了如下一些技术:
- 启发式算法:用于优化轻量级运算符以减轻工程压力。
- int4量化技术:用来来压缩模型权重。
- 构建静态内存规划优化:来跨多层重用内存。
- 使用Emscripten和TypeScript :构建一个在TVM web运行时可以部署生成的模块。
上述所有的工作流程都是基于Python来完成的。
但Web LLM团队也表示,这个项目还有一定的优化空间,例如AI框架如何摆脱对优化计算库的依赖,以及如何规划内存使用并更好地压缩权重等等。
Web LLM背后的团队是MLC.AI社区。
据了解,MLC.AI 社区成立于 2022 年 6 月,并由 Apache TVM 主要发明者、机器学习领域著名的青年学者陈天奇,带领团队上线了 MLC 线上课程,系统介绍了机器学习编译的关键元素以及核心概念。
值得一提的是,该团队此前还做过Web Stable Diffusion,链接都放在下面了,赶快去体验吧~
Web LLM体验地址:
https://mlc.ai/web-llm/
Web Stable Diffusion体验地址:
https://mlc.ai/web-stable-diffusion/
参考链接:
[1]https://twitter.com/HongyiJin258/status/1647062309960028160
[2]https://github.com/mlc-ai/web-llm
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK