

盛宝银行基于数据网格的分布式领域驱动架构最佳实践
source link: https://www.jdon.com/66079.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

盛宝银行基于数据网格的分布式领域驱动架构最佳实践
这篇博客文章概述了如何 盛宝银行 通过采用一种 数据网格架构学在数据平台团队的推动下,这一变化要求我们彻底重新思考整个组织的数据使用。
大规模分布式数据管理
数据网格是一种架构范式,自2019年Zhamak Delgahni首次提出以来,它已经慢慢获得了关注。盛宝银行在2018年底开始实施新的数据架构时也走上了类似的道路,并很快意识到我们的想法非常一致。
我们将概述盛宝银行是如何处理这种架构范式的,从数据网格的关键原则开始;盛宝如何开始将其付诸实践;以及未来的挑战
- 分布式领域驱动架构
- 与数据单体相反的是一个分散的联邦架构,它迫使您重新考虑处理和所有权的位置。
- 数据网格规定,数据域应该以易于使用的方式托管和服务其域数据集,而不是将数据从域流入中央拥有的数据湖或平台。
- 自助平台设计
- 正如《2020年DevOps状况报告》所概述的那样,DevOps的高度发展与自助服务能力密切相关,因为它允许应用程序团队提高效率,改进控制,平台团队专注于持续的基础设施改进。
- 在这种情况下,盛宝的自助服务平台超越了纯粹的基础设施,专注于使领域团队能够发布自己的数据资产并使用其他团队发布的数据资产。
- 数据与产品思维融合
- 在盛宝,我们将数据视为一种产品,并认为产品的可用性可以直接归因于其易于发现、理解和使用。我们鼓励领域数据团队将产品思维应用到他们提供的数据集上,就像他们提供任何其他功能一样严格。
分布式领域驱动架构
盛宝相关的数据域与任何其他投资银行或经纪公司没有什么不同。生产者对齐的域(诸如交易)表示业务的交易(事实),主数据集(诸如当事人)提供用于这样的域的上下文,并且消费者对齐的域(诸如风险)倾向于消耗大量数据但产生非常少的数据(例如,度量)。
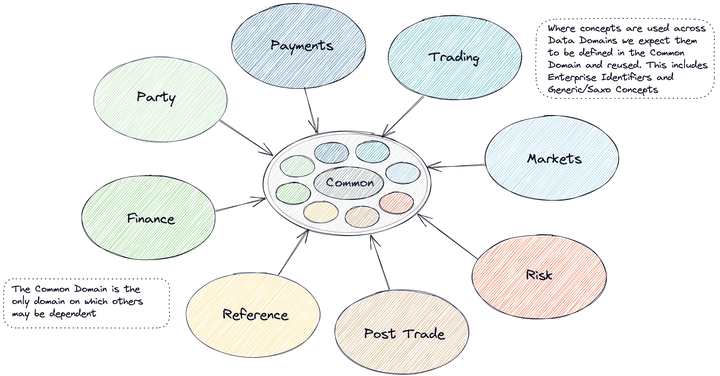
图1.数据域
考虑到整个组织的变化速度,我们知道我们不能依赖一个中央团队来为企业创建和填充规范的数据模型。我们的方法必须扩大规模。相反,我们联合了域数据的所有权及其表示和集中监督。
挑战在于确保整体大于部分之和域“啮合”,而不是生活在真空中。图2显示了盛宝银行的数据操作模型。其意图是“刚刚好”的治理:
- 消费者与生产者解耦(命令之上的事件)
- 有待确定和商定的权威来源
- 一种标准的语言,以确保信息可以在整个业务中有效使用;这种标准的或“普遍存在的”语言是领域驱动设计(DDD)思想的核心,是消除开发人员和领域专家之间障碍的一种手段
- 公共领域在这方面起着关键作用,因为我们希望标准化整个银行使用的基本概念
与数据办公室的同事一起,我们也认为这是一个机会,可以确保所有权得到适当的锚定(通常在业务中),并开始讨论每个领域的数据问题和战略。
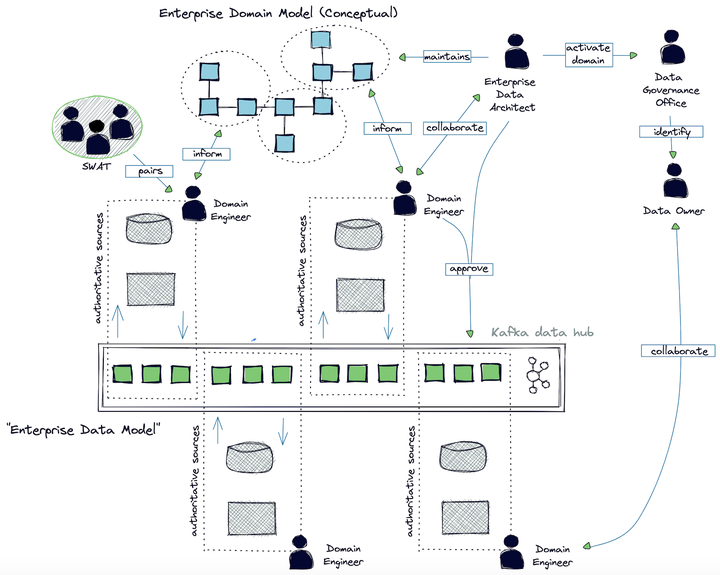
图2.数据操作模型
- 域团队负责:
- 标识数据集的权威来源
- 创建相关数据模型
- 通过数据结构向其他团队提供数据产品
- 数据质量(DQ)问题的补救;问题应该从源头上解决,而不是从消费上解决
- 企业数据架构师负责:
- 管理和塑造我们的数据域,使其对盛宝具有长期价值
- 批准对物理域模型的更改
- 与领域团队合作开发概念模型
- 数据治理办公室负责:
- “激活”数据域,包括识别所有权、已知数据质量问题等。
领域语言在概念模型(挑战在于使其尽可能简洁)和物理模型(我们用元数据修饰)中表现出来。我们不关心从概念图生成物理模型,因为我们相信这会将焦点从关于域的推理转移到可视化编程。
这个过程并不容易,我们才刚刚开始。审查步骤当然发挥了作用,教育和建立实践社区也是如此。那些命名一致、文档记录良好、语义强类型化并且以小增量更改的模式很快就会得到批准。而那些不需要的则不可避免地需要更长的时间。
此外,这个过程还依赖于一种接受,即我们不会在第一次就把它做对,并且需要对领域模型进行持续的管理。事实上,企业数据架构师的角色同样可以被描述为“数据保管人”。学习、迭代和改进。
当然,操作模型是动态的,这只是作为一个时间点的参考。
自助服务平台设计
数据网格是一种与技术无关的体系结构范例。在盛宝,我们将Confluent作为我们数据结构的基础层-一个数据域的权威接口,以及一个更传统的请求-响应接口。
尽管Apache Kafka基于日志的基础很简单,但将其作为企业骨干引入并非没有挑战。我们的目的是让领域团队不必考虑部署连接器的机制,生成语言绑定,如何处理个人身份数据等,这并不是小事,特别是考虑到开发平台的广度-主要是C#,但我们已经与使用Python,C++和现在的科特林的团队合作。
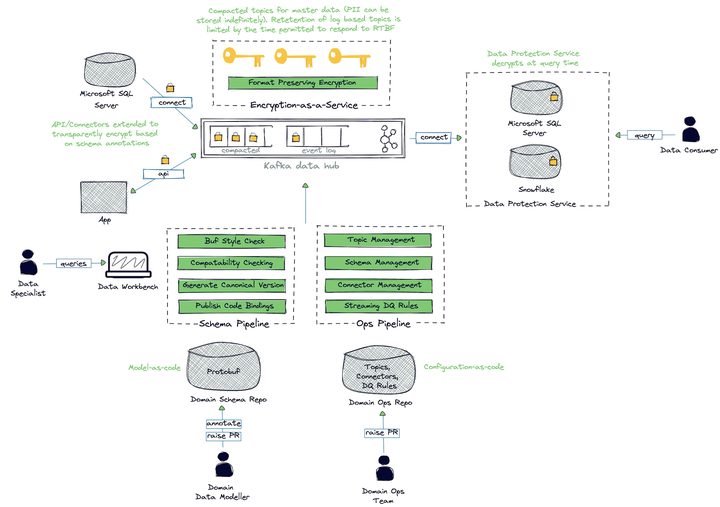
图3.盛宝银行的架构
我们的自助服务功能非常依赖GitOps,每个数据域都通过两个存储库进行管理:
- 主题配置,包括ACL
- Kafka连接器的管理
- 数据质量规则,使用Great Expectations’DSL 表达
- 图式Schema
- Protobuf模式验证和批准
- 为所有支持的语言生成代码绑定并发布到我们的工件存储库
可发现性不仅与数据的结构有关,还与使整个银行的数据专家能够了解数据产品的血统、所有权和相对健康状况(以一系列量化指标表示)有关。
为了解决这个问题,元数据和指标被发布到DataWorkbench--我们对LinkedIn开源项目的实现 DataHub- 让整个银行的数据专家了解发布到Apache Kafka的数据资产及其关系。这里还有很多改进的空间,例如,允许在工具本身中进行元数据管理,而不是直接在模式文件中进行。
数据与产品思维融合
(数据)产品的可用性归结为它可以被发现、理解和消费的容易程度。集中式架构的一个优点是,在不同的数据域之间保持一致的用户体验要容易得多,并确保用户能够将他们的心理模型从一个域转移到另一个域。我们的联邦体系结构需要完全不同的方法。
考虑到这一点,我们的自助服务平台对Kafka应该如何在Saxo中使用持有某种固执己见的观点。标准管道确保了所有域之间的通用方法-样式检查、代码绑定的生成、数据质量规则执行/报告以及如何将元数据推送到Data Workbench等。
我们努力使数据资产能够自我描述,并使概念能够被显式地表示。我们的信念是,通过一致和有效地使用元数据在和跨域,我们可以提高数据的可用性和时间上市的新数据产品。从根本上说,我们不希望生产者的数据形态发生重大变化,至少在第一个实例中是如此。小的改变可以带来大的不同:
- 跨领域采用一致的样式指南
- 重点强调强类型(“Currency”具有业务含义,而“string”没有)
- 尽可能符合行业标准
- 记录下一切
- 禁止“幻数”
- 在源头捕捉信息分类
- 链接相关概念
然后,这些信息通过Data Workbench浮出水面,Data Workbench在我们的实现中发挥着关键作用-不仅是为了发现数据资产,而且相信在意义、所有权和质量方面创建每个数据域和资产的可见性将有助于推动持续改进。
有效图式
那么,我们如何鼓励跨每个数据域的数据具有一致的外观和感觉呢?下一节涉及我们鼓励团队在设计数据契约时考虑的最佳实践,从消息格式本身开始。
选择格式
有许多文章讨论了结构化数据的不同序列化机制的优点,例如Martin Kleppmann的《Avro中的Schema Evolution》、《Protocol Buffers》和《Thrift》。通常,这些与模式管理和编码效率有关。
一个经常被忽略的考虑因素是语义注释(又称元数据)嵌入模式的难易程度。尽管XSD(XML的模式定义语言)名声不好,但 FpML已经证明在全球银行中非常成功,因为它们允许比其他情况下更严格的消息定义。事实上,考虑到FpML的开放性,许多人已经将其作为自己普遍存在的语言的基础。
然而,随着XML不再是必需的,我们寻找替代方案-特别是Confluent目前支持的那些:Avro、JSON和Protocol Buffers(Protobuf)。
在研究使用JSON编码的可行性时,FpML架构师工作组指出,在JSON中表达相同的不同数据类型和语言约束是不可能的。除此之外,表示十进制值的唯一可靠方法是将其编码为字符串。此外,JSON Schema没有表达自定义语义注释的方法。由于这些原因,我们没有考虑JSON Schema。
Avro在这种情况下表现稍好,特别是与Avro接口定义语言(IDL)结合使用时,它允许模式组合性。我们可以将语义注释表示为松散类型的名称-值对,以向类型和字段添加其他属性。虽然Avro定义了一小部分原语,但该语言已扩展为包括许多核心逻辑类型(十进制,UUID,日期和时间)。
Protobuf更进一步,允许使用“自定义选项”进行强消息类型和字段级注释。这使得编译时检查成为可能,这当然是有利的。
另一个考虑因素是语言绑定的成熟度。虽然盛宝最初选择了Avro,但我们不情愿地意识到这是我们推出的一个主要摩擦点。C和Python实现落后于JVM,尽管我们确实贡献了一些修复(感谢Matt Howlett的支持),但我们觉得围绕C实现的支持太分散注意力了。
Protobuf优于Avro的另一个优点是,您的绑定将遵循目标语言的类型和属性的风格规范,而不管模式中使用的命名约定。虽然这看起来是一个微不足道的问题,但如果不正确地考虑,它是另一个摩擦的来源。
我们最终在2020年底转向Protobuf,不久之后,它被Confluent Schema Registry作为一级公民支持。当然,对于感兴趣的语言绑定-C#,Python,C/C++,以及随着Kafka Streams获得更多兴趣,JVM-我们发现实现比Avro更一致。
自描述模式
对于那些不熟悉Protobuf的人,请放心,如果您已经掌握了XSD的复杂性,您会发现这是在公园散步。
简而言之,复杂类型表示为“消息”,而不管它是事件还是事件引用的类型。虽然语法稍有不同,但“选项”(即,语义注释)可以在消息(类型)或字段(属性)的级别上表达。有关详细信息,请参阅Proto3语言指南。
命名
命名很难 ,但使用Uber的风格指南可以鼓励一致性,并提供一种经过深思熟虑的版本化方法。
我们也有许多你希望在任何编码标准中看到的准则:奇异值应该有一个单数的名字,重复的字段应该有一个复数的名字,等等。
文件
所有记录和属性都需要文件记录。即使是看似显而易见的领域,往往也有不明显的细节。
标识符
企业标识符的一致使用是使这种分布式模型工作的关键要求之一。毕竟,考虑一下这个词背后的含义 网孔:“以正确的位置连接在一起。”标识符唯一地标识实体,并且可以被认为是域的“主键”,这是我们的数据网格实现背后的基本原则之一。
标识符使用Protobuf的IDL定义如下:
// This is how we pass 'Thing' by reference
message ThingIdentifier {
int64 id = 1;
}
|
按照惯例,对于数字标识符,我们将标识符的唯一属性命名为id,对于字母数字标识符,我们将其命名为code。企业标识符在各个域中普遍存在,必须以通用的方式定义。
引用参考
引用可以被认为是具有较弱约束的替代标识符。例如,PaymentReference可以是由客户提供的自由形式的文本字段。下面是一个例子:
// User supplied reference. Not necessarily unique
message ThingReference {
string ref = 1;
}
|
按照惯例,我们将引用的唯一属性命名为ref(通常为类型string)。企业引用必须以通用的方式定义。
枚举和方案
多个数据元素被限制为仅保存有限的可能值集合中的一个。这种受限的值集合通常被称为枚举。
Protobuf与许多其他语言类似,支持枚举类型的使用。在值的范围较小的情况下(例如,<10)并且不希望经常改变,使用enum是完全可以接受的。然而,通常期望类型将引用外部编码方案,这是取自FpML的概念。
IDL中引用的方案如下:
// Currency as represented by the three character alphabetic code as per ISO 3166
// https://www.iso.org/iso-4217-currency-codes.html
// https://spec.edmcouncil.org/fibo/ontology/FND/Accounting/CurrencyAmount/Currency
message CurrencyIdentifier {
option (metadata.coding_scheme) = "topic://reference-currency-compact-v1";
// Alphabetic (three letter) code
string code = 1;
}
|
在该示例中,读者被引导到压缩主题reference-currency-compact-v1以获得货币代码及其含义的明确列表。
方案不仅帮助接收者理解值的范围,而且还打开了自动化数据质量监控的大门。理想情况下,模式引用另一个主题,但如果团队引用文档,我们(几乎)也会很高兴。
信息分类
盛宝银行定义了四种信息分类,每种分类都意味着特定的敏感度水平。这反映在下面所示的架构中:
// Name of a natural person
message Name {
option (metadata.msg_info_class) = INFO_CLASS_PERSONAL;
// The given name or first name of a person, that is the name chosen for them
// at birth or changed by them subsequently from the name give at birth
string given_name = 1;
}
|
虽然这一点预计将反映在信息一级,但在外地一级表达这一点可能有正当理由。在这种情况下,应指定field_info_class选项。如果未说明,则假定默认为“仅内部”分类。
我们迈向云端之旅的一个关键部分是确保PII数据得到加密。我们的意图是最终直接从模式注释中驱动这一点,使开发团队不必担心这些细节。
外部模式
虽然我们已经对Protobuf进行了标准化,但我们支持在某些用例中“带来自己的模式”的想法。在这种情况下,必须使用external_schema选项显式引用实际使用的模式:
// An example of an external schema
message EventWithExternalSchema {
XmlString vendor_string = 1 [(metadata.external_schema) = "https://example/third-party.xsd"];
}
|
注意,虽然由vendor_string表示的有效载荷可以包含对third-party.xsd的引用,但是为了便于在“设计时”使用,它必须在元数据中被显式引用。
弃用
弃用是进化过程中不可或缺的一部分,它为消费者提供了对您未来计划的洞察力。弃用可以在字段或消息级别表示,如下所示:
// An example of a deprecated attribute
message EventWithDeprecatedField {
// Seemed like a good idea at the time. Will be removed (or reserved) at a later date
int32 old_field = 1 [deprecated = true];
// Much better idea
int64 new_field = 2;
}
|
外部标准
您应该如何表示电子邮件地址?约会?产品?监管申报?很可能已经有了一个标准,所以让我们使用它。
只要可行,我们总是在我们的文档中引用这些标准-无论是作为唯一的定义,还是与盛宝的实施有关。我们通过使用如下所示的term_source和term_ref选项的“业务术语”选项将域模型链接到外部标准:
// The measure which is an amount of money specified in monetary units (number with a
// currency unit). Where the currency is inferred (i.e. not populated) references to this types
// should clearly articulate in which currency the price is denominated.
message MonetaryAmount {
option (metadata.term_source) = TERM_SOURCE_FIBO;
option (metadata.term_source_ref) = "https://spec.edmcouncil.org/fibo/ontology/FND/Accounting/CurrencyAmount/MonetaryAmount";
// Financial amount
DecimalValue amount = 1;
// Optional currency code
CurrencyIdentifier ccy = 2;
}
|
该示例明确指出,MonetaryAmount的定义直接取自金融行业业务本体的同名术语。
链接术语
当我们迭代域模型时,我们可能会无意中在不同的数据域中复制概念。这是不可避免的,无论执行了多少前期设计。与其等待一个突破性的变化,不如有一个机制,允许我们引用现有的概念,而不影响现有的生产者或消费者。
我们通过field_term_link选项将领域模型中的元素链接到公认的业务术语的权威定义:
// An example of linking to a 'business term'
message EventWithLinkedTerm {
// the trade currency
string trade_currency = 1 [(metadata.field_term_link) = "CurrencyIdentifer"];
}
|
在这个例子中,我们注释了trade_currency来引用“currency”的普遍存在的表示,而不影响模式的兼容性。这不仅可以用于改进文档,还可以作为领域模型未来迭代的辅助备忘录。
衡量
这种设计的价值在于我们进一步利用数据的能力。我们怎么知道我们走在正确的道路上?在我们的案例中,盛宝银行已经确定了一些指标,我们将使用这些指标来衡量我们实现愿景的进展:
- 网格中的连接数(断开连接的域不太可能提供更大的价值)
- 生产者:消费者比率
- 创建与消费者一致的数据产品的交付周期
- 数据产品度量(例如,数据质量覆盖趋势)
- 测试覆盖率(变化弹性)
未来方向
尽管盛宝银行已经迭代了这些想法一段时间,但直到最近,随着我们寻求解决扩展挑战,采用率才有所增长。我们的主要重点是:
- 继续降低平台准入门槛
- 通过自动对账框架等方式增加平台的附加值
- 与数据办公室和整个银行的同事合作,嵌入领域思维
- 以领域为中心的用户界面
- 领域健康的游戏化Gamification of domain health
- 对模式文档的众包改进
- 在用户界面中显示数据质量规则和结果
- 包括所有其他上游/下游平台
- 使团队能够轻松采用ksqlDB等工具
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK