

面向大模型训练,腾讯云发布新一代高性能计算集群
source link: https://www.51cto.com/article/752095.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

面向大模型训练,腾讯云发布新一代高性能计算集群
4月14日,腾讯云正式发布面向大模型训练的新一代HCC(High-Performance Computing Cluster)高性能计算集群。该集群采用最新一代腾讯云星星海自研服务器,搭载了NVIDIA H800 Tensor Core GPU,并提供业界目前最高的3.2T超高互联带宽。
实测结果显示,腾讯云新一代集群的算力性能较前代提升高达3倍。
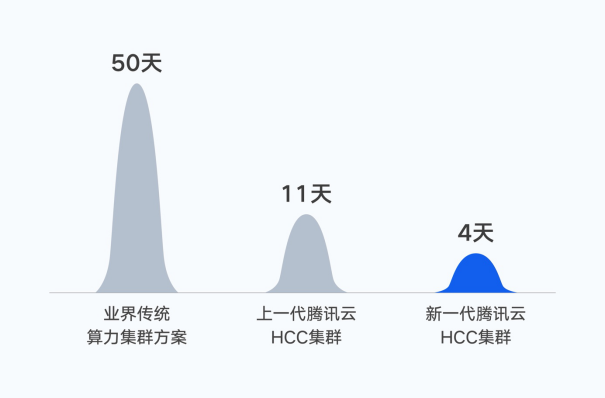
去年10月,腾讯完成首个万亿参数的AI大模型——混元NLP大模型训练。在同等数据集下,将训练时间由50天缩短到11天。如果基于新一代集群,训练时间将进一步缩短至4天。
大模型进入万亿参数时代,对算力的需求陡增。在单体服务器计算能力有限的情况下,需要将上千台服务器相连,打造大规模、分布式的高性能计算集群。腾讯云新一代集群通过对单机算力、网络架构和存储性能进行协同优化,能够为大模型训练提供高性能、高带宽、低延迟的智算能力支撑。
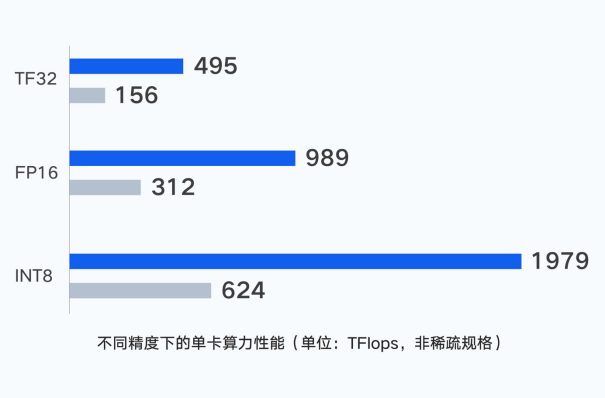
计算层面,服务器的单机性能是集群算力的基础。在非稀疏规格情况下,新一代集群单GPU卡支持输出最高 495 TFlops(TF32)、989 TFlops (FP16/BF16)、1979 TFlops(FP8)的算力。针对大模型训练场景,腾讯云星星海服务器采用6U超高密度设计,相较行业可支持的上架密度提高30%;利用并行计算理念,通过CPU和GPU节点的一体化设计,将单点算力性能提升至最强。
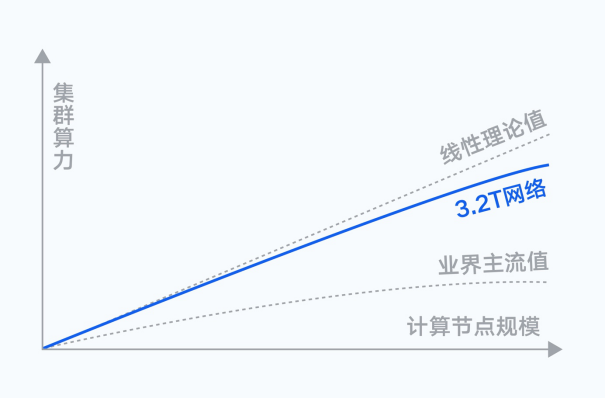
网络层面,计算节点间存在海量的数据交互需求,随着集群规模扩大,通信性能会直接影响训练效率。腾讯自研的星脉网络,为新一代集群带来了业界最高的3.2T的超高通信带宽。节点内外统一的AllReduce通信带宽,实现网络和算力的最大协同。实测结果显示,搭载同样的GPU,最新的3.2T星脉网络相较1.6T网络,能让集群整体算力提升20%。
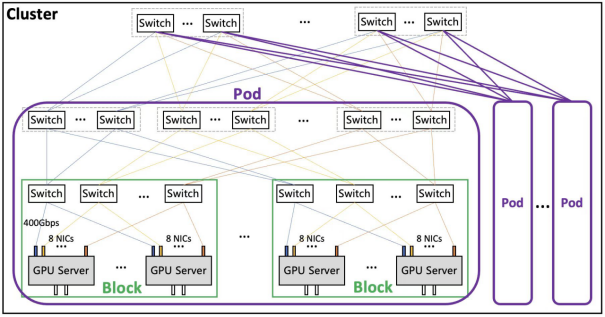
基于多轨道聚合的无阻塞网络架构、主动拥塞控制和定制加速通信库,腾讯云能提供业界领先的集群构建能力,支持单集群高达十万卡级别的组网规模。在超大集群场景下,仍然能保持优秀的通信开销比和吞吐性能,满足大模型训练以及推理业务的横向扩展。
同时,腾讯自研高性能集合通信库TCCL,基于星脉网络硬件平台深度优化,在全局路径规划、拓扑感知亲和性调度、网络故障实时告警/自愈等方面融入了定制设计的解决方案。相对业界开源集合通信库,为大模型训练优化40%负载性能,消除多个网络原因导致训练中断问题。
存储层面,训练场景下,几千台计算节点会同时读取一批数据集,需要尽可能缩短数据集的加载时长。新一代集群,引入了腾讯云最新自研存储架构,支持不同场景下对存储的需求。
COS+GooseFS对象存储方案,提供多层缓存加速,大幅提升端到端的数据读取性能;将公开数据集、训练数据、模型结果统一存储到对象存储COS中,实现数据统一存储和高效流转。同时,GooseFS按需将热数据缓存到GPU内存和本地盘中,利用数据本地性提供高性能访问。
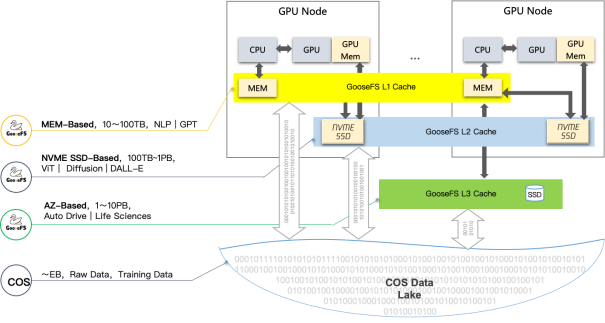
CFS Turbo高性能并行文件存储方案,采取多级缓存加速,基于全分布式架构,提供100GB/s带宽、1000万IOPS的极致性能。并通过持久化客户端缓存技术,将裸金属服务器本地NVMe SSD和Turbo文件系统构成统一命名空间,实现微秒级延时,解Q大模型场景大数据量、高带宽、低延时的诉求。同时,通过智能分层技术,自动对冷热数据分层,节省80%的存储成本,提供极致的性价比。
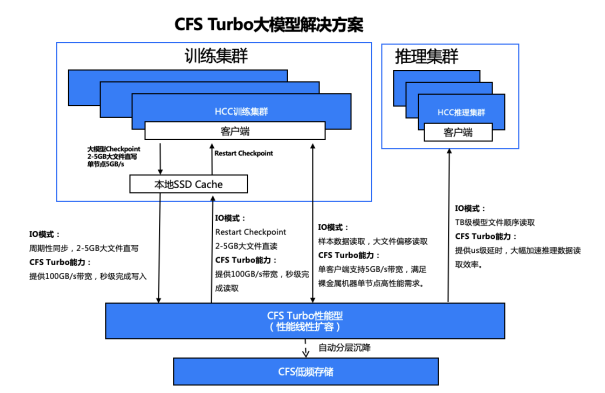
底层架构之上,针对大模型训练场景,新一代集群集成了腾讯云自研的TACO Train训练加速引擎,对网络协议、通信策略、AI框架、模型编译进行大量系统级优化,大幅节约训练调优和算力成本。
腾讯混元大模型背后的训练框架AngelPTM,也已通过腾讯云对外提供服务,帮助企业加速大模型落地。目前,腾讯混元AI大模型已经覆盖了自然语言处理、计算机视觉、多模态等基础模型和众多行业、领域模型。
在腾讯云上,企业基于TI 平台的大模型能力和工具箱,可结合产业场景数据进行精调训练,提升生产效率,快速创建和部署 AI 应用。
此前,腾讯多款自研芯片已经量产。其中,用于AI推理的紫霄芯片、用于视频转码的沧海芯片已在腾讯内部交付使用,性能指标和综合性价比显著优于业界。其中,紫霄采用自研存算架构,增加片上内存容量并使用更先进的内存技术,消除访存能力不足制约芯片性能的问题,同时内置集成腾讯自研加速模块,减少与CPU握手等待时间。目前,紫霄已经在腾讯头部业务规模部署,提供高达3倍的计算加速性能,和超过45%的整体成本节省。
目前,腾讯云的分布式云原生调度总规模超过1.5亿核,并提供16 EFLOPS(每秒1600亿亿次浮点运算)的智算算力。未来,新一代集群不仅能服务于大模型训练,还将在自动驾驶、科学计算、自然语言处理等场景中充分应用。
以新一代集群为标志,基于自研芯片、星星海自研服务器和分布式云操作系统遨驰,腾讯云正通过软硬一体的方式,打造面向AIGC的高性能智算网络,持续加速全社会云上创新。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK