

C Strings and my slow descent to madness
source link: https://www.deusinmachina.net/p/c-strings-and-my-slow-descent-to
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

C Strings and my slow descent to madness
Credit to
For pointing out that "有り難う" means "thank you" instead of "hello". I got my examples mixed up when I was coding and missed this. Thanks for the correction!
I’ve been on a C kick recently as I learn the intricacies involved in low level programming. As a Data Scientist/Python Programmer I work with strings all the time. People say that handling strings in C range anywhere from tricky to downright awful. I was curious so I decided to see how deep the rabbit hole went.
C strings
C strings are an array of characters that end with a null terminator, \0. When C manipulates strings the null terminator is what tells functions that the end of the string has been reached. In C we declare a string in two different ways. The first and most difficult way is as a literal character array.
#include <stdio.h>
int main() {
char myString[] = {'H', 'e', 'l', 'l', 'o', ',', ' ', 'W', 'o', 'r', 'l', 'd','!','\n','\0'};
printf("%s", myString);
return 0;
}This is error prone and requires you to insert the null terminator yourself. It also takes forever to write for long words, 0/10. The second way is as a string enclosed in double quotes.
#include <stdio.h>
int main() {
char myString[] = "Hello, World!\n";
printf("%s", myString);
return 0;
}In this situation C knows exactly how long the string is and can automatically insert the null terminator.
String Operations
Once you have properly encoded a string, there are many operations you can perform. Common functions on strings include strcpy, strlen, and strcmp. strcpy copies the string stored in one variable to another. strlen gets the length of a string (minus the null terminator), and strcmp takes two strings and returns 0 when they are true. Unfortunately, there is a lot of nuances when working with string functions. First, let’s take a look at an example of each starting with strcpy.
int main() {
char source[] = "Hello, world!";
char destination[20];
strcpy(destination, source); // Copy the source string to the destination string
printf("Source: %s\n", source);
printf("Destination: %s\n", destination);
return 0;
}Here is the output of our code from above.
Source: Hello, world!
Destination: Hello, world!As you might have expected strcpy works by copying a string and putting its contents in another string. But you might be asking. “Why can’t I just assign the source variable directly to the destination variable?”
int main() {
char source[] = "Hello, world!";
char* destination = source;
strcpy(destination, source); // Copy the source string to the destination string
printf("Source: %s\n", source);
printf("Destination: %s\n", destination);
return 0;
}You can. It’s just that destination now becomes a char* and exists as a pointer to the source character array. If that isn’t what you want them this will almost certainly cause issues.
Our next string operation is strlen, which gets the size of the string minus the null terminator.
#include <stdio.h>
#include <string.h>
int main() {
char str[] = "Hello, world!"; // The string to find the length of
int length = strlen(str); // Find the length of the string
printf("The length of the string '%s' is %d.\n", str, length);
return 0;
}
The output of our print function for strlen looks like this.
The length of the string 'Hello, world!' is 13.This is pretty straightforward. It just counts the characters until it hits the null terminator.
Our last function is strcmp. It looks at two strings and determines whether they are equal to each other or not. If they are it returns 0. If they aren’t it returns 1
.
#include <stdio.h>
#include <string.h>
int main() {
char str1[] = "Hello, world!";
char str2[] = "hello, world!";
int result = strcmp(str1, str2); // Compare the two strings
if (result == 0) {
printf("The strings are equal.\n");
} else {
printf("The %s is not equal to %s\n", str1, str2);
}
return 0;
}
The output of our strcmp function….
The strings are not equalNow that we know how to copy, get the length, and compare our strings I’ll drop the bombshell. None of these are safe operations, and it’s easy to create undefined behavior. This mostly revolves around the use of \0 as the null terminator. In the case of the above C functions as well as others, C expects to find a \0 which tells the function to stop reading the area in memory where the string lives. But what if there is no null terminator? Well, C will happily keep reading the contents in memory after the string should have ended. If our program’s function was supposed to verify the user’s supplied password, a bad actor could potentially skip the area in memory where the password check happens and go right into the function that is called for password successes, by exploiting a buffer overflow with the string. This would circumvent the entire authorization process. So how do we handle this?

Attempting to make C safe
If you do some poking around, you might find a function called strncpy. When you look at its definition, you’ll see that it copies a source string into a destination string and allows you to specify the number of bytes to copy. “This looks perfect!” you might say. I can make sure that my destination string only receives as many bytes as it can handle. Here is some code below that illustrates that as well as its output.
#include <stdio.h>
#include <string.h>
#define dest_size 12
int main(){
char source[] = "Hello, World!";
char dest[dest_size];
// Copy at most 12 characters from source to dest
strncpy(dest, source, dest_size);
printf("Source string: %s\n", source);
printf("Destination string: %s\n", dest);
return 0;
}
Source string: Hello, World!
Destination string: Hello, WorldAt first this looks great, but there is a problem. What happens when the source string minus the null terminator is as long as the size of the destination string? The answer is that the destination gets filled with all the characters of the source string with no room left for the null terminator. A non-null terminated string will most certainly cause you headaches later on. “Okay” you might say. But at least it can handle the case where the source string is smaller than the destination string? And yes, it can handle that case, but so can strcpy. And if the source string is smaller than the destination string, all the extra space in the destination string that isn’t used is still reserved and padded. So, if the destination string is 20 characters long but the source string is only 13 you get a destination string that effectively looks like this.
char destination[20] = {'H', 'e', 'l', 'l', 'o', ',', ' ', 'W', 'o', 'r', 'l', 'd', '!', '\0', '\0', '\0', '\0', '\0', '\0', '\0'};So no proper null termination and excessive padding. That isn’t great. If you happen to be on Windows and use the strncpy function, the Microsoft Visual C++ (MSVC) Compiler won’t even compile the program. You have to manually set a flag to allow using deprecated features, which is a hint you should probably not be using it.
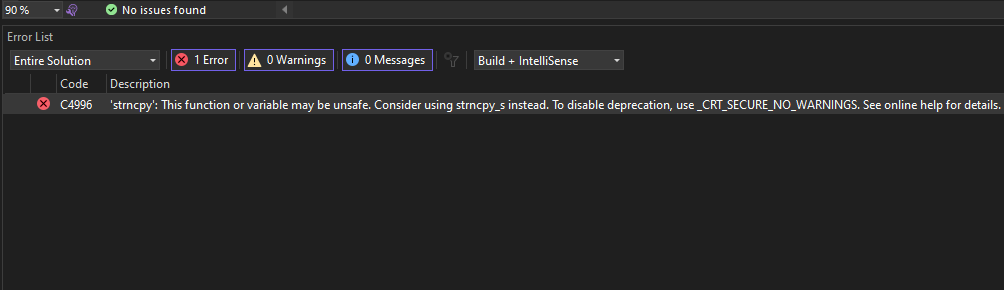
It suggests using strncpy_s instead. Let’s look at that now. strncpy_s accepts these parameters…
char *restrict dest: The destination stringrsize_t destsz: The size of the destination stringconst char *restrict src: The source string to be copiedrsize_t count: The maximum number of bytes to copy from the source string
If the destination string is longer than the source string than everything gets copied fine. But if the destination is smaller than the source, then only the size of the destination -1 is copied over. The additional check that strncpy_s makes is that it ensures that even when a source string is copied into a destination string, the resulting string is always null terminated. This is great, but again we have two problems.
strncpy_s does not handle excessive padding
strncpy_s is not portable to macOS or Linux
Now if at this point you are shaking your fist at the sky cursing the C standards committee for dragging their feet on implementing portable safer string operations for 34 years, I don’t blame you.

So how can we handle this case safely? There are a few ways I can think of.
If you are working with strings of a known length like in our contrived example it could be as simple as initializing our destination string to the
sizeof()source string.You could just work with a pointer to the source string and forgo copying completely. So long as the source string is properly terminated you won’t have to deal with mismatched buffer sizes.
You could forgo portability and use the _s versions of string functions on Windows, or “l” versions of them on macOS.
You could use a different language 🙊
By this point you may have noticed that I’ve spent a lot of time talking about strcpy but have only briefly talked about strcmp and strlen. They all suffer from the same issue that stems from the way C strings are terminated. Because the length of a string is unknown until you hit a null terminator you get all sorts of undefined behavior and attack vectors. This is in contrast to C++ which treats strings as objects and encodes the length of the string along with the number of characters. This is one of the reasons why people tend to write C in C++. Use all the bits you consider “good” and ignore everything else.
To handle these properly in pure C requires carefully implementing checks around string operations. This is error prone, and harder as the program gets larger. This is one of the reasons why C is considered an unsafe language.
Dealing with non Latin languages 💃
Unicode was an important step in text encoding for computers. Today, UTF-8 is the dominate encoding for text. I briefly summarize its history in this article Breaking the Snake: How Python went from 2 to 3, so I won’t belabor the point here. C didn’t gain Unicode support until C99, and even if you handle it properly in C you can run into issues in other ways as you will see in a moment. If we try to print out some Japanese characters…
#include <stdio.h>
#include <string.h>
int main() {
printf("有り難う\n");
return 0;
}The output isn’t what we expect.

This is because we aren’t interpreting the characters as Unicode characters. Let’s rewrite the code to fix that.
#include <stdio.h>
#include <wchar.h>
#include <locale.h>
int main() {
setlocale(LC_ALL, ""); // Set the locale to the user's default locale
wchar_t hello[] = L"有り難う";
wprintf(L"Hello in Japanese is: %ls\n", hello);
return 0;
}I added the string“Hello in Japanese is:” for a good reason. If you look at the screenshot below you can see why. The output still isn’t shown.
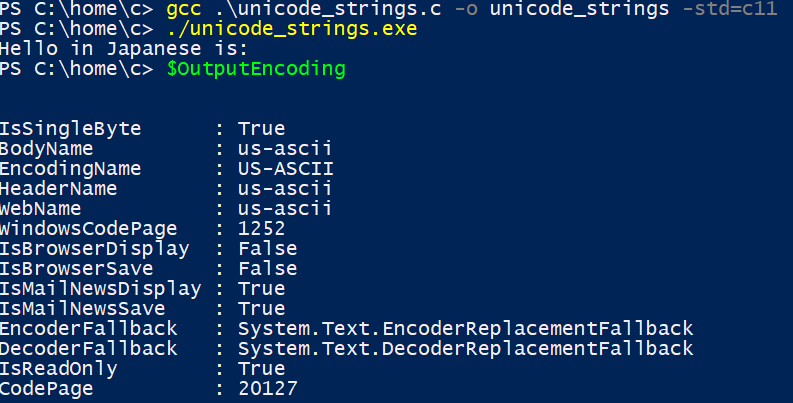
Checking the encoding of the PowerShell Console we see that it’s in ASCII. Okay let’s change the encoding with $OutputEncoding = [System.Text.Encoding]::UTF8. Now it’s in UTF-8. It still doesn’t work. Maybe it’s because the font doesn’t support Japanese. Some quick Googling later I see that the MS Gothic font does, and I switch my font to that.
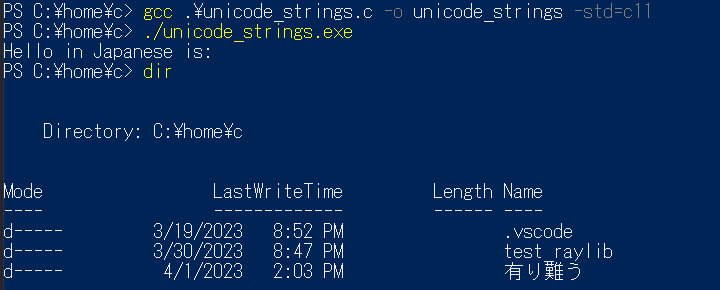
My “\” are now “¥” but I can live with that if this works. I named a test folder 有り難う to make sure that PowerShell displays it correctly. If we look at the test folder now, we see kanji are now being displayed correctly. But even with that change the code still doesn’ t print the characters! I try setting the locale to ja_JP.UTF8, but still can’t get an output. Some more googling and I come across an article title PowerShell console characters are garbled for Chinese, Japanese, and Korean languages on Windows Server 2022
which states....
By default, Windows PowerShell .lnk shortcut is hardcoded to use the "Consolas" font. The "Consolas" font doesn't have the glyphs for CJK characters, so the characters aren't rendered correctly. Changing the font to "MS Gothic" explicitly fixes the issue because the "MS Gothic" font has glyphs for CJK characters.
The Command Prompt (cmd.exe) doesn't have this issue, because the cmd .lnk shortcut doesn't specify a font. The console chooses the right font at runtime depending on the system language.
Resolution
The issue will be fixed in Windows 11 and Windows Server 2022 very soon, but the fix won't be backported to lower versions.
To work around the issue, use either of the following two workarounds.
Okay cool this doesn’t seem like my exact issue, but it seems like PowerShell doesn’t handle Japanese characters well by default. I try using the Command Prompt with MS Gothic but that doesn’t solve it either. Everything that I’ve Googled shows that this should work In C. I switch the code back to…
#include <stdio.h>
#include <wchar.h>
#include <locale.h>
int main() {
setlocale(LC_ALL, ""); // Set the locale to the user's default locale
wchar_t hello[] = L"有り難う";
wprintf(L"Hello in Japanese is: %ls\n", hello);
return 0;
}and I run it on my Raspberry PI and… It works!
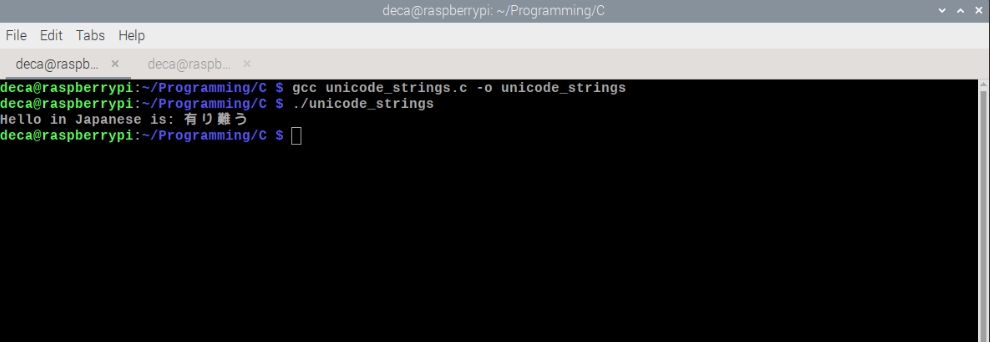
I try it on my Macbook Pro and it works as well. I fire up PowerShell on my Macbook Pro and… It still works… So thankfully this isn’t a bug in C, but it does look like an issue with the way Windows handles non-Latin characters in its terminals. Alls I can say is… Go easy on Microsoft. They are a small indie dev…. But for real if anyone knows how to get this to work on Windows 10 let me know!
Now that we can print Japanese characters correctly in C, lets look at one final case before this article gets too long. As we saw earlier getting the length of a string can be done with strlen. If we modify our naive C code from the beginning to get the strlen of the Japanese string it looks like this…
#include <stdio.h>
#include <string.h>
int main() {
printf("The length of the string is %d characters\n", strlen("有り難う"));
return 0;
}and the output is…
The length of the string is 12 charactersIf we go back to our original print output, we can see this string of characters that is printed out incorrectly.

You’ll notice there are 12 characters. The reason for this is we are interpreting the string as ascii. Since kanji take more than one byte to encode, each byte in a 4 kanji word is being interpreted as an individual letter, as opposed to each cluster of bytes being associated as a kanji. If we change the string to a w_char instead of a char by prefixing it with a “L”, and use wcslen instead of strlen we get the code below…
#include <stdio.h>
#include <wchar.h>
#include <locale.h>
int main() {
printf("The length of the string is %d characters\n", wcslen(L"有り難う"));
return 0;
}
which prints out…
The length of the string is 4 charactersThis article only scratches the surface when it comes to working with C strings. We didn’t even have time to touch on the Unicode literals introduced in C11 like ‘u8’, ‘u’, and ‘U’. Needless to say, when working with C strings you have to be careful. At a minimum you could cause a headache for yourself by creating undefined behavior. On the other hand, you could potentially create an attack vector for someone to exploit. If you’ve only worked in garbage collected programming languages, you might be wondering why go through the trouble to work in C. If you look at a language like Python, and the libraries that is uses in the data science field, most of them are built on top of C and C++. Someone’s got to do it, and if you have the knowledge, almost all languages have a C foreign function interface that can be leveraged to speed up code, so the benefits will usually carry over to other languages as well. So, learn you some C, but maybe don’t start with strings first.
Call To Action 📣
If you made it this far thanks for reading! If you are new welcome! I like to talk about technology, niche programming languages, AI, and low-level coding. I’ve recently started a Twitter and would love for you to check it out. If you liked the article, consider liking and subscribing. And if you haven’t why not check out another article of mine! Thank you for your valuable time.
 Deus In Machina
Deus In MachinaCorrection with credit to Nathell on Hacker news
The strcmp() and strncmp() functions return an integer greater than, equal to, or less than 0, according as the string s1 is greater than, equal to, or less than the string s2. The comparison is done using unsigned characters, so that ‘\200’ is greater than ‘\0’.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK