

围观!Twitter算法已开源
source link: https://www.51cto.com/article/751173.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

编译 | 王瑞平
审校 | 云昭
3月的最后一天,推特的推荐算法终于在Github上开源了,马斯克的承诺兑现了。
图注:马斯克在推特上表示,上周发布的是“大部分推荐算法”,并表示其余部分将在未来发布
按照马斯克之前的承诺,上周,Twitter已在GitHub上发布了“时间轴上显示哪些推文”的代码,并发布了一篇博客文章阐述了具体细节。
博客文章特别深入介绍了推荐算法的工作原理。开源代码的做法不仅帮助马斯克兑现了承诺,还有助于增加用户信任度、利于产品优化改进。
1、Twitter的推荐算法
文章详细描述了算法执行的每一步,并介绍了推荐系统由许多相互关联的服务和工作组成。虽然Twitter的很多区域都推荐推文(往往以搜索、探索、广告的形式出现),但是,这篇文章主要介绍了For You时间轴上的推荐系统。
Twitter每时每刻都在为用户提供来自世界各地的新闻。这就需要一种独特的推荐算法,从每天发布的大约5亿条推文中提炼出几条最热门的推文,最终显示在设备的For You时间轴上。
具体来讲,推荐的算法系统以一组核心模型和功能为基础,从Twitter、用户和参与度数据中提取潜在信息。模型旨在回答关于Twitter网络的重要问题,比如,“你未来与另一个用户互动的概率是多少?”“Twitter上有哪些社区,这些社区里有哪些热门推文?”准确回答这些问题可以让Twitter提供更相关的建议。
推文途径主要由3个阶段组成:第一个阶段,系统会从不同的推荐源获取最好的推文,这个过程称为推荐源候选;第二个阶段,系统会使用机器学习模型对每条推文进行排名;第三个阶段,启发式和过滤器开始执行命令,例如,过滤来自已经屏蔽的用户的推文、不适合在上班时浏览的内容和已看到的推文。
顺便说一句,负责构建和服务For You时间轴的服务系统叫做Home Mixer。它构建在Product Mixer上,是自定义的Scala框架,可以方便地构建内容提要。该服务充当连接不同候选源、评分函数、启发式和过滤器的软件主干。
2、For You时间轴模型
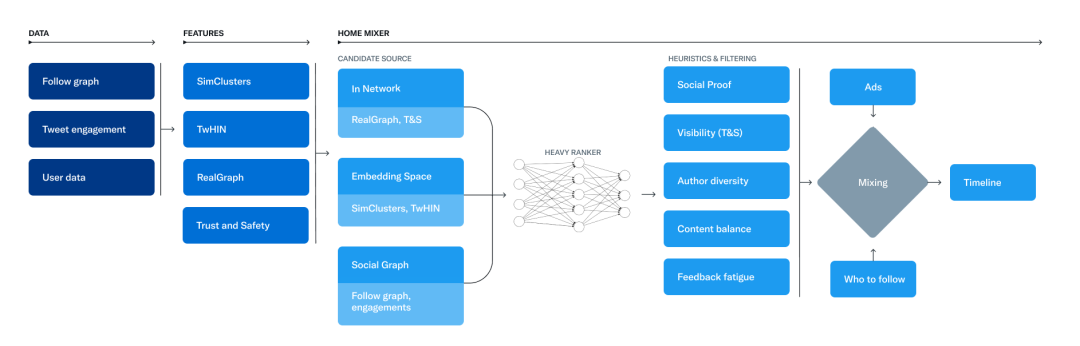
模型的关键部分以在单个时间轴请求期间的调用顺序开展,首先需要从Candidate Sources中检索出候选源。
Twitter有几个候选源,用来为用户检索最近的和相关的推文。对于每个用户请求,系统试图通过候选源从数亿条推文中提取出最好的1500条推文。然后,从你关注的人(网络内)和你不关注的人(网络外)中寻找候选源。
具体来讲,For You时间轴可以让用户时间轴中大约有50%来自用户关注的人(称为“内部网络”)的推文,以及50%来自用户没有关注的“外部网络”账户的推文。排名旨在“优化积极参与(例如,点赞、转推和回复)”,最后一步将试图确保用户不会看到太多来自同一个人的推文。
3、内部与外部网络消息源
下面再来具体介绍下上文提到的内部与外部网络消息源。内部网络消息源是最大的候选消息源,旨在提供你关注的用户最新发布的最相关推文。它使用逻辑回归模型根据你关注的推文的相关性有效地排名。排名靠前的推文会被送到下一个阶段。
内部网络消息源最重要的组成部分是Real Graph(实数图)。Real Graph是一种预测两个用户之间产生互动可能性的模型。用户和推文作者之间的Real Graph得分越高,模型中就会包含更多他们的推文。
那么,什么是外部网络消息源呢?众所周知,在用户所关注的网络之外寻找相关推文是一项棘手的问题,原因是如果用户不关注作者,怎么知道某条推文是否与其相关?Twitter采取了两种方法解决这个问题。
第一种方法是构建社交图谱。图谱通过分析用户关注的人或有相似兴趣的人的活动估算出与你相关的信息。在此期间,系统将自动浏览相关业务图表,并回答以下问题:“我关注的人最近都发了哪些推文? 谁喜欢和我相似的推文,他们最近为哪些文章点赞?系统根据这些问题的答案生成候选推文,并使用逻辑回归模型对结果推文进行排名。
第二种方法是构建嵌入空间,旨在回答系统关于内容相似性的更普遍问题:哪些推文和用户与我的兴趣相似?
嵌入空间的工作原理是生成用户感兴趣和推文内容的数字表达式。然后,用户可以在这个嵌入空间中计算任意两个用户、推文或用户-推文对之间的相似性。如果生成准确的嵌入,模型可以用这种相似性替代相关性消息。
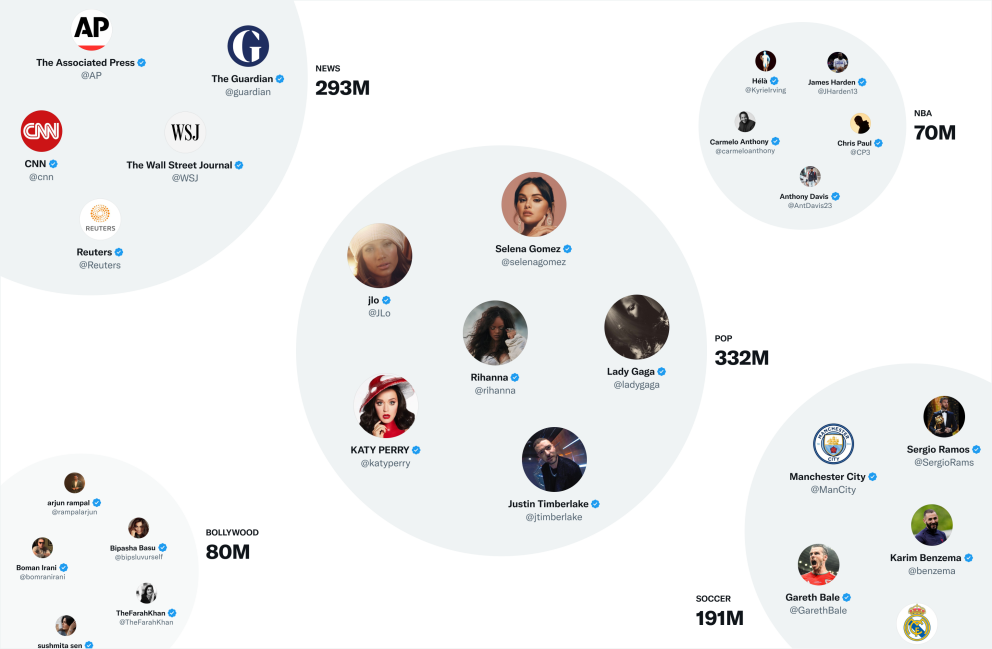
例如,Twitter最有用的嵌入空间之一是SimClusters。SimClusters使用自定义矩阵分解算法,能够发现由有影响力的用户集群锚定的社区。目前,共有145000个社区,每三周更新一次。社区的规模从个人朋友群的几千用户到新闻中出现的数亿用户不等,下图展示出一些最大的社区:
4、For You时间轴上的排行
下面再来介绍下推荐途径的第二阶段,即推文排名。For You时间轴上的排名是通过一个约48M参数的神经网络实现。该神经网络不断地训练推文交互,以优化积极的参与度(例如,点赞、转发和回复)。这种排名机制“考虑”数千个特征,并输出10个标签给每条推文打分。每个标签代表用户参与的概率,根据分数对推文进行排名。
5、将推文发送至设备
在排名阶段之后,启发式和过滤器能够帮助优化推文功能。这些功能共同创建出平衡和多样化的推文质量,包括:根据内容和个人喜好过滤推文、避免同一作者连续发布过多推文、确保网络内和外的推文数量平衡。
Home Mixer将推文准备发送到终端设备。系统将推文与其它非推文内容(如,广告、关注推荐和登录提示)混合在一起,这些内容将返回到终端上显示。至此,一个完整的推文过程就结束了。
6、Twitter未来的动作
未来,Twitter将以此为基础,不断打造出更好的分析平台,为创作者提供更多关于覆盖面和参与度的信息。并且,用户推文或账户上的任何安全标签都会变得更透明。
为此,Twitter正在努力寻找新的机会扩展其推荐系统,包括:新的实时功能、嵌入和用户表示,旨在构建出世界上最有趣的数据集和用户基础。但是,Twitter也将因此面临来自开源社区的潜在竞争。
参考资料:
https://blog.twitter.com/engineering/en_us/topics/open-source/2023/twitter-recommendation-algorithm
https://www.theverge.com/2023/3/31/23664849/twitter-releases-algorithm-musk-open-source

Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK