

谈谈GPT 模型背后以数据为中心的 AI
source link: https://www.51cto.com/article/750834.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

谈谈GPT 模型背后以数据为中心的 AI
人工智能 (AI) 在改变我们生活、工作和与技术互动的方式方面取得了巨大的进步。最近,取得重大进展的领域是大型语言模型 (LLM) 的开发,例如GPT-3、ChatGPT和GPT-4。这些模型能够准确的执行语言翻译、文本摘要和问答等任务。
人工智能 (AI) 在改变我们生活、工作和与技术互动的方式方面取得了巨大的进步。最近,取得重大进展的领域是大型语言模型 (LLM) 的开发,例如GPT-3、ChatGPT和GPT-4。这些模型能够准确的执行语言翻译、文本摘要和问答等任务。
虽然很难忽视 LLM 不断增加的模型规模,但同样重要的是要认识到,他们的成功很大程度上归功于用于训练他们的大量高质量数据。
在本文中,我们将从以数据为中心的 AI 角度概述 LLM 的最新进展。我们将通过以数据为中心的 AI 视角研究 GPT 模型,这是数据科学界中一个不断发展的概念。我们通过讨论三个以数据为中心的 AI 目标:训练数据开发、推理数据开发和数据维护,来揭示 GPT 模型背后以数据为中心的 AI 概念。
大型语言模型 (LLM) 和 GPT 模型
LLM 是一种自然语言处理模型,经过训练可以在上下文中推断单词。例如,LLM 最基本的功能是在给定上下文的情况下预测缺失的标记。为此,LLM 接受了训练,可以从海量数据中预测每个候选单词的概率。下图是在上下文中使用 LLM 预测丢失标记的概率的说明性示例。

GPT模型是指OpenAI创建的一系列LLM,如GPT-1、GPT-2、GPT-3、InstructGPT、ChatGPT/GPT-4等。与其他 LLM 一样,GPT 模型的架构主要基于Transformers,它使用文本和位置嵌入作为输入,并使用注意力层来模拟令牌的关系。
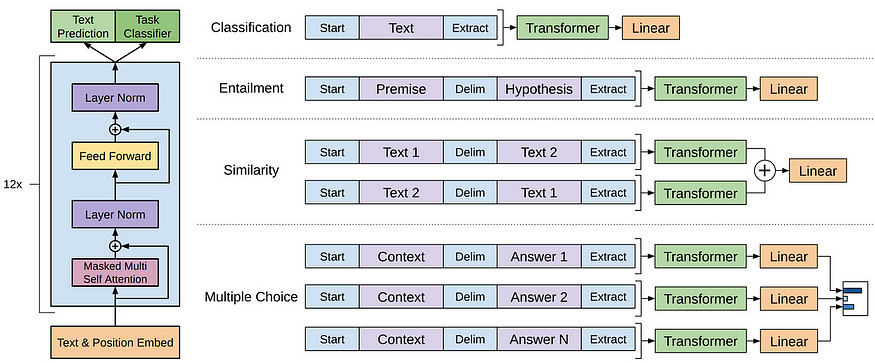
GPT-1 模型架构
后来的 GPT 模型使用与 GPT-1 类似的架构,除了使用更多模型参数和更多层、更大的上下文长度、隐藏层大小等。

什么是以数据为中心的人工智能
以数据为中心的 AI是一种新兴的思考如何构建 AI 系统的新方法。以数据为中心的人工智能是系统地设计用于构建人工智能系统的数据的学科。
过去,我们主要专注于在数据基本不变的情况下创建更好的模型(以模型为中心的 AI)。然而,这种方法在现实世界中可能会导致问题,因为它没有考虑数据中可能出现的不同问题,例如标签不准确、重复和偏差。因此,“过度拟合”数据集不一定会导致更好的模型行为。
相比之下,以数据为中心的人工智能专注于提高用于构建人工智能系统的数据的质量和数量。这意味着注意力在数据本身,模型相对更固定。使用以数据为中心的方法开发人工智能系统在现实场景中具有更大的潜力,因为用于训练的数据最终决定了模型的最大能力。
需要注意的是,“以数据为中心”与“数据驱动”有着根本的区别,后者只强调用数据来指导人工智能的发展,通常仍以开发模型而不是数据为中心。
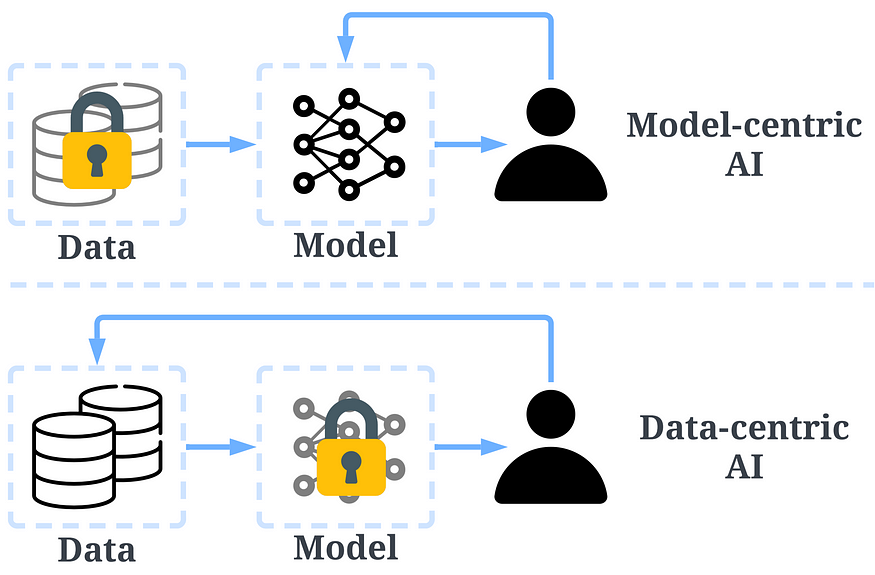
以数据为中心的人工智能与以模型为中心的人工智能之间的比较
以数据为中心的 AI 框架包含三个目标:
- 训练数据开发就是收集和生产丰富、高质量的数据,以支持机器学习模型的训练。
- 推理数据开发是为了创建新的评估集,这些评估集可以提供对模型的更细粒度的洞察力,或者通过数据输入触发模型的特定功能。
- 数据维护是为了在动态环境下保证数据的质量和可靠性。数据维护至关重要,因为现实世界中的数据不是一次性创建的,而是需要持续维护。
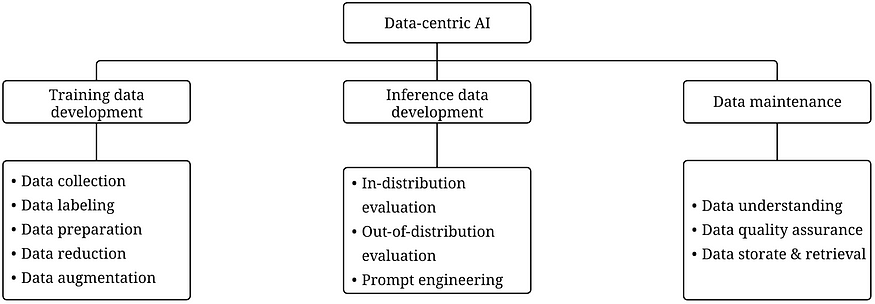
以数据为中心的 AI 框架
为什么以数据为中心的 AI 使 GPT 模型成功
几个月前,Yann LeCun 在推特上表示 ChatGPT 并不是什么新鲜事。事实上,ChatGPT 和 GPT-4 中使用的所有技术(变压器、从人类反馈中强化学习等)一点都不新鲜。然而,他们确实取得了以前模型无法实现的结果。那么,他们成功的原因什么?
训练数据开发。通过更好的数据收集、数据标记和数据准备策略,用于训练 GPT 模型的数据的数量和质量有了显着提高。
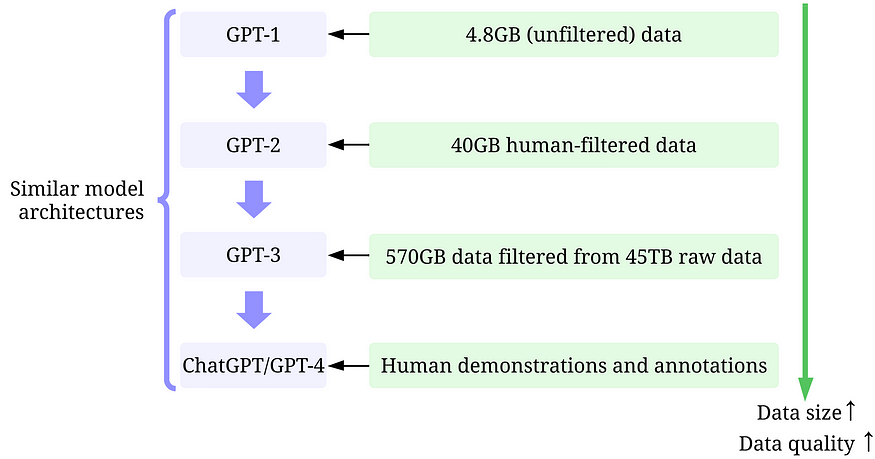
- GPT-1:BooksCorpus 数据集用于训练。该数据集包含4629.00 MB 的原始文本,涵盖各种类型的书籍,例如冒险、幻想和浪漫。
-以数据为中心的 AI 策略:无。
-结果:在该数据集上使用 GPT-1 可以通过微调提高下游任务的性能。 - GPT-2:训练中使用WebText 。这是 OpenAI 中的一个内部数据集,通过从 Reddit 抓取出站链接创建。
-以数据为中心的 AI 策略:(1) 仅使用来自 Reddit 的出站链接来整理/过滤数据,该链接至少获得 3 个业力。(2) 使用工具Dragnet和Newspaper来提取干净的内容。(3) 采用去重和其他一些基于启发式的清洗。
-结果:过滤后得到 40 GB 的文本。GPT-2 无需微调即可获得强大的零样本结果。 - GPT-3:GPT-3的训练主要基于Common Crawl。
-以数据为中心的 AI 策略:(1) 训练分类器根据每个文档与WebText(高质量文档)的相似性过滤掉低质量文档。(2)利用Spark的MinHashLSH对文档进行模糊去重。(3) 使用WebText、图书语料库和维基百科扩充数据。
- 结果:45TB的明文过滤后得到570GB的文本(本次质量过滤只选择了1.27%的数据)。GPT-3 在零样本设置中明显优于 GPT-2。 - InstructGPT:让人类评估调整GPT-3 的答案,使其更好地符合人类的期望。他们为标注者设计了测试,只有通过测试的人才有资格标注。他们甚至设计了一项调查,以确保注释者全心投入到注释过程中。
-以数据为中心的 AI 策略:(1)使用人类提供的提示答案通过监督训练调整模型。(2)收集比较数据以训练奖励模型,然后使用此奖励模型通过人类反馈强化学习(RLHF)调整GPT-3。
- 结果:InstructGPT 表现出更好的真实性和更少的偏差,即更好的对齐。 - ChatGPT/GPT-4:OpenAI 没有透露细节。但众所周知,ChatGPT/GPT-4 很大程度上沿用了之前 GPT 模型的设计,他们仍然使用 RLHF 来调整模型(可能有更多和更高质量的数据/标签)。人们普遍认为,随着模型权重的增加,GPT-4 使用了更大的数据集。
推理数据开发。由于最近的 GPT 模型已经足够强大,我们可以通过在模型固定的情况下调整提示或调整推理数据来实现各种目标。例如,我们可以通过提供要总结的文本以及诸如“总结它”或“TL;DR”之类的指令来引导推理过程,从而进行文本摘要。

设计正确的推理提示是一项具有挑战性的任务。它严重依赖启发式方法。一个很好的调查总结了不同的促销方法。有时,即使是语义相似的提示也会有非常不同的输出。在这种情况下,可能需要基于软提示的校准来减少方差。
LLM推理数据开发的研究仍处于早期阶段。在不久的将来,可以在 LLM 中应用更多已用于其他任务的推理数据开发技术。
数据维护。ChatGPT/GPT-4作为商业产品,不仅训练一次,而且不断更新和维护。显然,我们无法知道在 OpenAI 之外如何进行数据维护。因此,我们讨论了一些通用的以数据为中心的 AI 策略,这些策略已经或将很可能用于 GPT 模型:
- 连续数据收集:当我们使用 ChatGPT/GPT-4 时,我们的提示/反馈可能反过来被 OpenAI 使用进一步推进他们的模型。可能已经设计并实施了质量指标和保证策略,以在此过程中收集高质量数据。
- 数据理解工具:可以开发各种工具来可视化和理解用户数据,促进更好地了解用户需求并指导未来改进的方向。
- 高效的数据处理:随着ChatGPT/GPT-4用户数量的快速增长,需要一个高效的数据管理系统来实现快速的数据采集。

上图是ChatGPT/GPT-4 通过“赞”和“不赞”收集用户反馈的示例。
数据科学界可以从这波 LLM 浪潮中学到什么
LLM的成功彻底改变了人工智能。展望未来,LLM可以进一步彻底改变数据科学生命周期。我们做出两个预测:
- 以数据为中心的人工智能变得更加重要。经过多年研究,模型设计已经非常成熟,尤其是在Transformer之后。数据成为未来改进 AI 系统的关键方式。另外,当模型变得足够强大时,我们就不需要在日常工作中训练模型了。相反,我们只需要设计适当的推理数据来从模型中探索知识。因此,以数据为中心的人工智能的研发将推动未来的进步。
- LLM将实现更好的以数据为中心的人工智能解决方案
许多繁琐的数据科学工作可以在LLM的帮助下更有效地进行。例如,ChaGPT/GPT-4 已经可以编写可工作的代码来处理和清洗数据。此外,LLM 甚至可以用于创建训练数据。例如使用 LLM 生成合成数据可以提高文本挖掘中的模型性能。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK