

算力“神器”加持,第四代英特尔至强可扩展处理器为本土业务创新加速
source link: https://server.51cto.com/article/750288.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

算力“神器”加持,第四代英特尔至强可扩展处理器为本土业务创新加速
原创今年初,英特尔正式发布了第四代英特尔®至强®可扩展处理器。与前一代产品最大的差别在于,除了增加的核心数量和制造工艺之外,第四代英特尔®至强®可扩展处理器专门针对人工智能、5G网络、数据分析、科学计算等现代工作负载,引入针对实际工作负载优化加速的设计理念,采用系统级设计方法,在CPU芯片架构中内置专用的工作负载加速器,以提升性能和效率。
这样的设计,到底能够为现代化的工作负载带来多大的性能提升呢?八周之后,采用第四代英特尔®至强®可扩展处理器的实例应运而生。近期,来自于英特尔的多位技术专家,通过不同的应用案例,详细介绍了第四代英特尔®至强®可扩展处理器在不同应用场景下的性能提升。
七大算力神器之外,再添vRAN Boost
1月11日,英特尔正式推出了第四代英特尔至强可扩展处理器(代号“Sapphire Rapids”),与上一代产品相比,第四代英特尔至强可扩展处理器采用Intel 7制程工艺制造,集成了高性能核心、更多内核数量,英特尔 AMX、英特尔 IAA、英特尔 QAT、英特尔 DLB、英特尔 DSA、英特尔 SGX、英特尔至强CPU MAX系列这七大算力神器,以及业界领先的DDR5、CXL1.1、PCIe 5.0,共同构成了新一代产品的最大特色。
距离发布不到八周时间内,英特尔在七大“算力神器”的基础上,又添加了vRAN Boost。英特尔市场营销集团副总裁、中国区数据中心销售总经理兼中国区运营商销售总经理庄秉翰表示,英特尔vRAN Boost使得运营商能够在通用虚拟化平台上整合所有基站层。未来,客户通过通用处理器来实现基站功能,能够带来很大的性价比提升。
庄秉翰指出,随着“双碳”、新基建、“东数西算”等的发展,对未来数据中心能耗需求越来越严苛,绿色计算也成为可持续发展的关键动力。为此,第四代英特尔至强可扩展处理器通过内置加速器,能够更加高效、以更低能耗处理复杂度越来越高的工作负载。他强调,第四代英特尔至强可扩展处理器包含丰富的内置加速器,帮助提高能效和性能,是英特尔最具可持续性的数据中心处理器。除此之外,通过电源管理解决方案,能够更好地提升处理器运算中的能效比。
目前,大多数主流OEM和ODM厂商都在出货基于该处理器的系统设计,前十大云服务提供商也将在今年部署基于该款处理器的云实例。在新处理器得到越来越多应用的同时,一批采用新处理,利用新处理器优势特性的案例也浮出水面。
引入AMX加速器,最强大的AI通用处理器
在第四代英特尔至强可扩展处理器当中,笔者最关注的是AMX加速器。
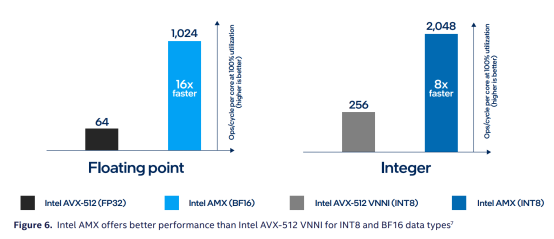
AMX加速器支持INT8和BF16两种计算精度,且两种使用频次都非常高。其中,INT8常用于推理。众所周知,在日常生产环境中,推理用的频次要远远高于训练的次数,比如,每次刷脸完成身份验证就是一次推理过程,社交软件里每一次语音转文字,文字转语音都是推理过程。
混合精度浮点BF16也常用在训练场景中,并且,使用频次在近年来逐渐增加。其主要优势是在可以在保持较高精度的同时,提高计算速度和减少存储空间。与AVX-512相比,每一个计算周期的计算性能大大提升。
借助英特尔专家分享的一组数据,我们能够看到加入AMX加速器之后,第四代英特尔至强可扩展处理器所带来的性能提升。(见下图)
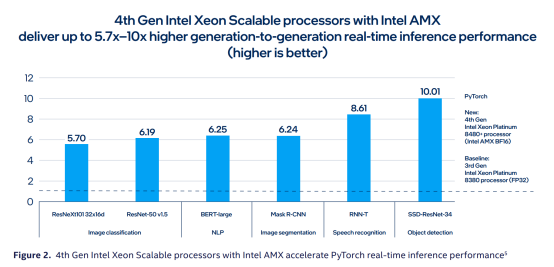
与上一代相比,第四代至强处理器推理性能提高了5.7-10倍
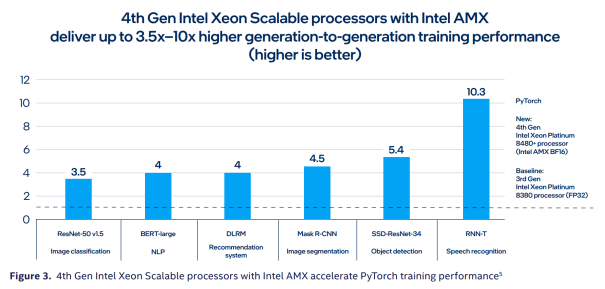
与上一代相比,第四代至强处理器训练性能提高了3.5-10倍
在AMX加速引擎的助力下,英特尔至强不仅能用来做推理,还能用来处理一些机器学习训练的工作负载,这也让英特尔至强成了最适合机器学习的通用x86处理器。由于支持INT8和BF16两种计算精度,这也就意味着至强处理器事实上可以覆盖很多场景。
为多种场景提速,推动AI应用迈上新台阶
AMX加速器在互联网场景、OCR场景、以及生成式模型、大语言模型中的均有多种应用案例。
AMX加速器在腾讯太极机器学习平台支撑搜索和广告业务中应用,解决了搜索数量多,以及对于搜索延迟要求高的问题。太极机器学习平台支撑的搜索业务部署在腾讯云上,所使用的云主机就基于新一代英特尔至强而构建,配合软件上的优化,不仅帮降低了所使用的CPU的数量,同时性能也有2到3倍的提升。
AMX加速器应用于阿里淘宝业务中,使用INT8精度加上软件优化的技术,支撑淘宝的“地址标准化”服务,该服务涉及到语义分析等技术,而AMX则提高了语义分析的性能。此外,阿里还将AMX的BF16计算精度用于手机淘宝首页个性化推荐的场景,配合软件层面上的优化,每天承载着高达亿次的请求,得益于AMX所带来的提升,其最终性能达到了原来的3倍。
在亚信开发的电信智能营业厅方案中,用OCR来识别客户提交上来的身份证件和工商营业执照图片,OCR这种推理负载的需求量非常大,每年大概需要2000万次服务。当把业务迁移到第四代至强可扩展处理器,并针对AMX做了优化之后,性能达到了3.94倍的提升。
用友企业ERP软件中有一个OCR模块,该模块主要是用于识别办公和财务领域发票内容,该业务每年需要支持3000万次的服务请求。当迁移到第四代至强可扩展处理器之后,结合AMX的优势,实际性能达到了原来的3.83倍。
除此之外,AMX加速器还应用于生成式模型、大语言模型中。英特尔技术专家通过Stable Diffusion的案例,进行了详细的介绍。据了解, Stable Diffusion的技术构成上大量使用了注意力机制,而注意力机制需要矩阵相乘和指数运算能力。而新一代英特尔至强的AMX BF16可用于加速矩阵计算,AVX-512可以用来加速指数计算。经测试发现,配合英特尔PyTorch扩展插件用Stable Diffusion,生成512x512图片吞吐性能提高了3.82倍,720P图片的吞吐性能提高了5.26倍。
不难发现,由于AMX加速器的加持,使得机器学习的效率和经济性方面迈向一个新的台阶,也将使得第四代英特尔至强成为目前市场上,最适合人工智能负载的通用x86处理器。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK