
4

Papers Ideas | 一直进步 做喜欢的
source link: https://xfliu1998.github.io/2023/03/25/Papers-Ideas/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Papers Ideas
Created2023-03-25|Updated2023-03-25|Reading Notes
Word count:575|Reading time:2min|Post View:1|Comments:
在我科研迷茫时,感谢朱老师的分享:大模型时代下做科研的四个思路【论文精读·52】
Efficient
由于缺少计算资源,可以关注现有模型费时费力的模块进行efficient优化,如Efficient Attention优化( Lean Former; Performer; Flash Attention)和主要应用于大模型的微调的Parameter Efficient Fine Tuning(PEFT)。PEFT包括Adapter和Prompt。
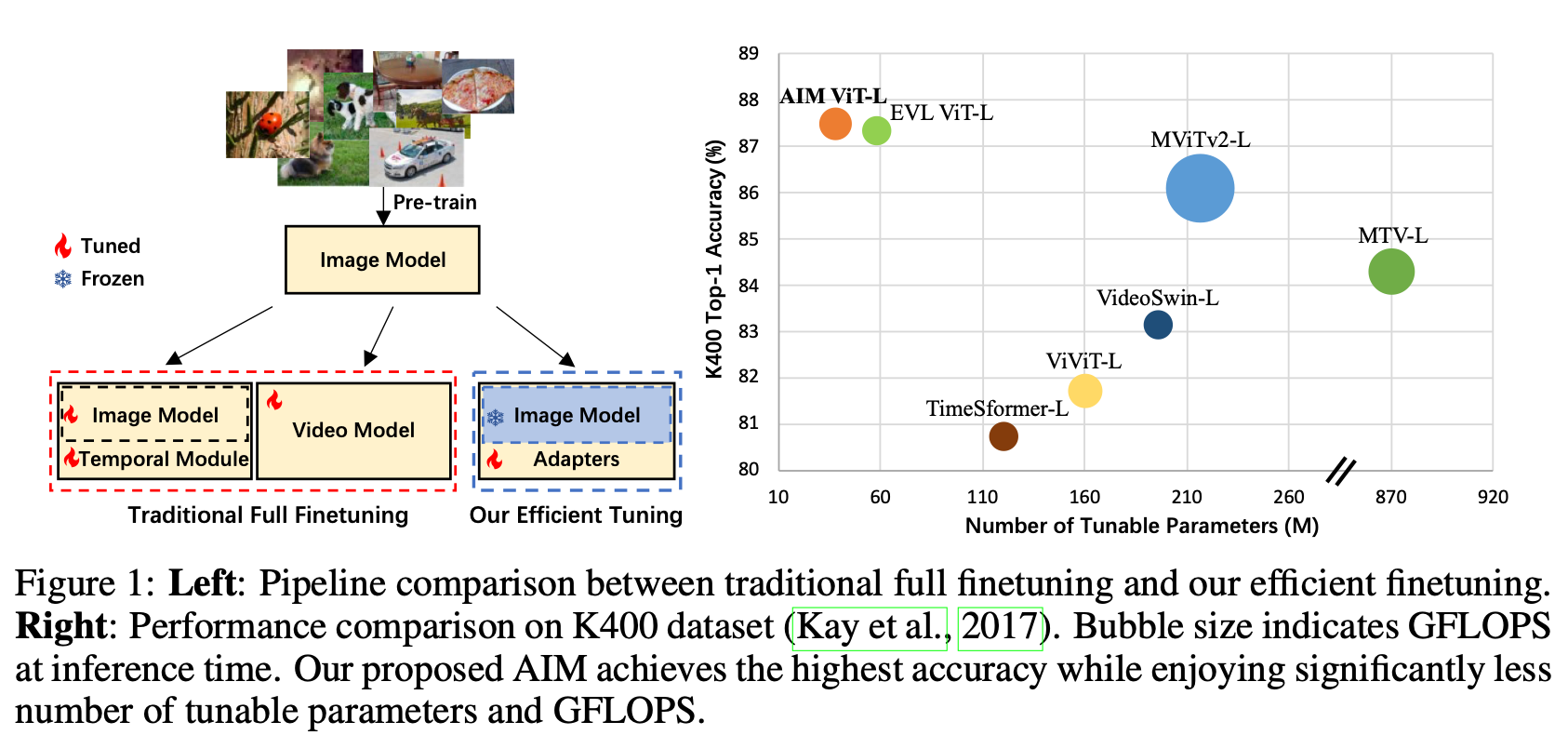
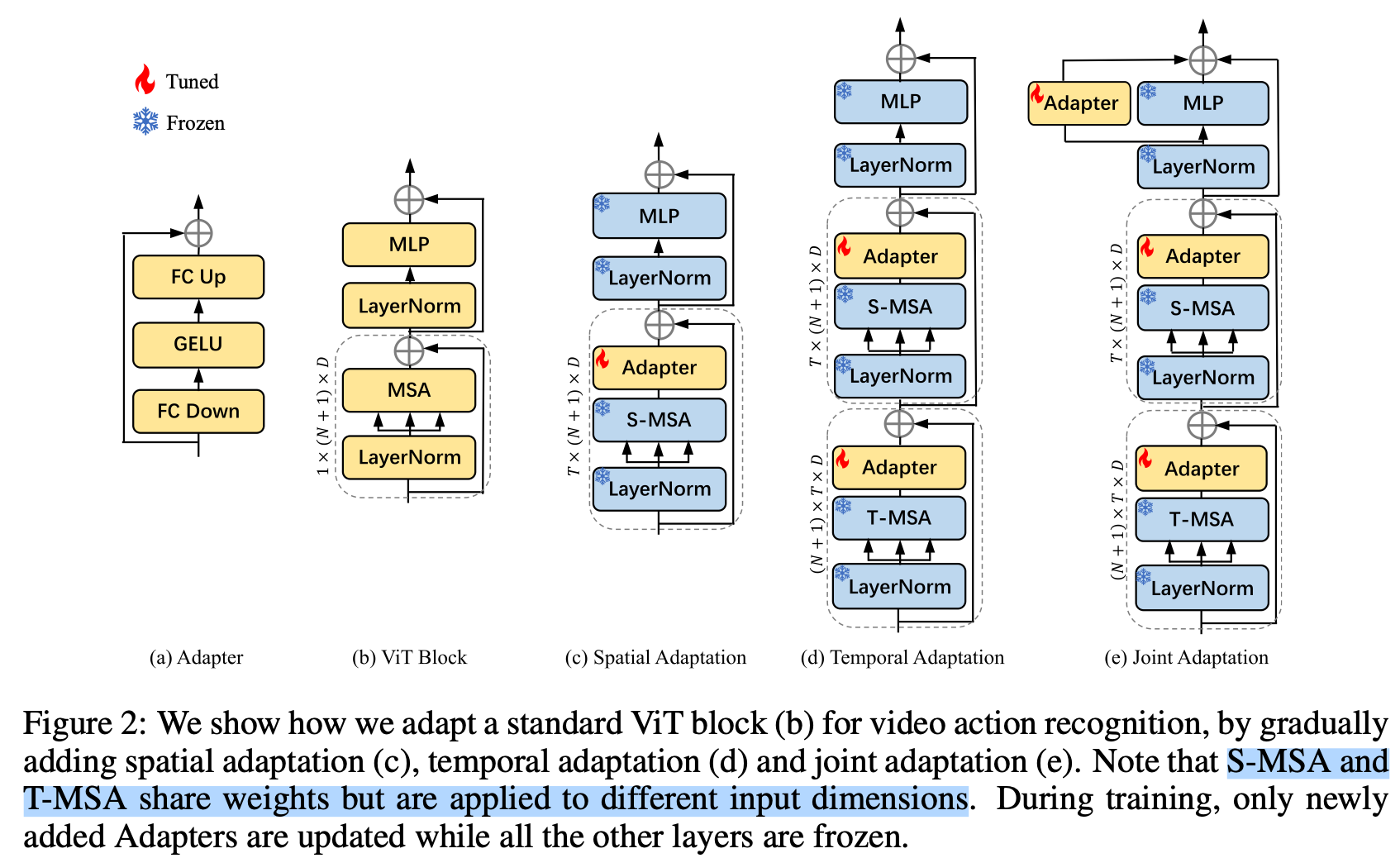
- 《AIM: Adapting Image Models for Efficient Video Action Recognition》【ICLR2023】Arxiv
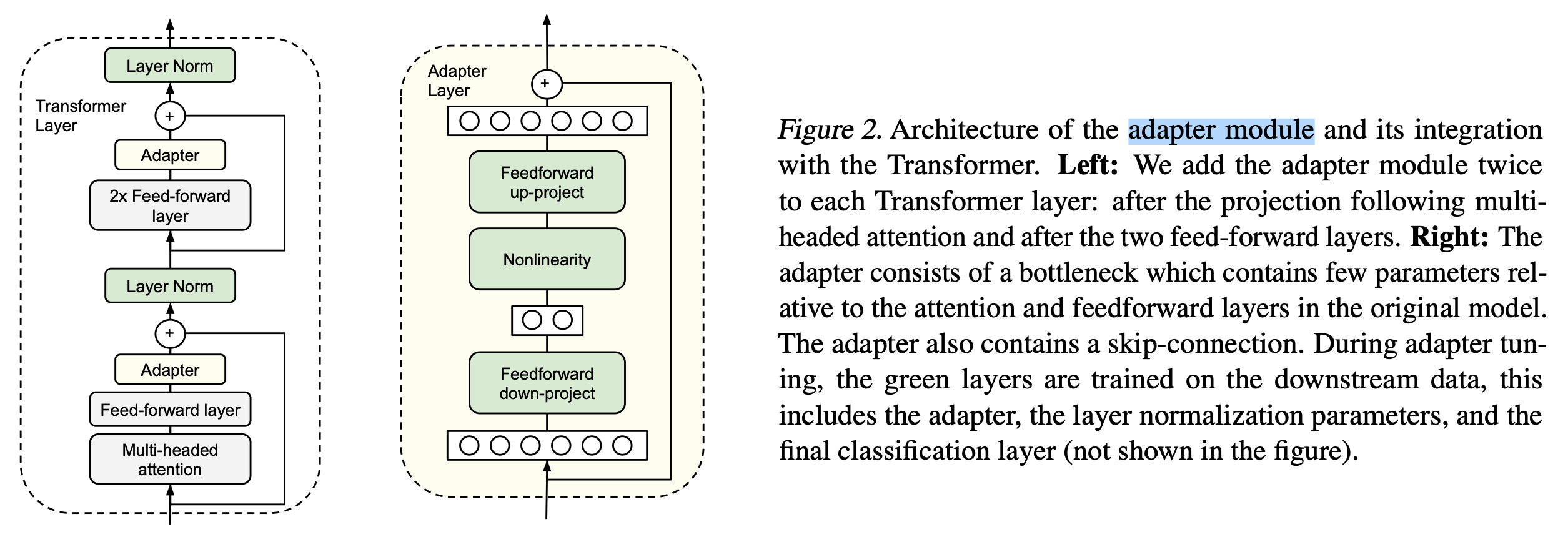
一个即插即用的模块,加入到Transformer中,原有的大模型训练时参数frozen,模型微调时只训练Adapter的模块参数。 - 《Parameter-Efficient Transfer Learning for NLP》Arxiv
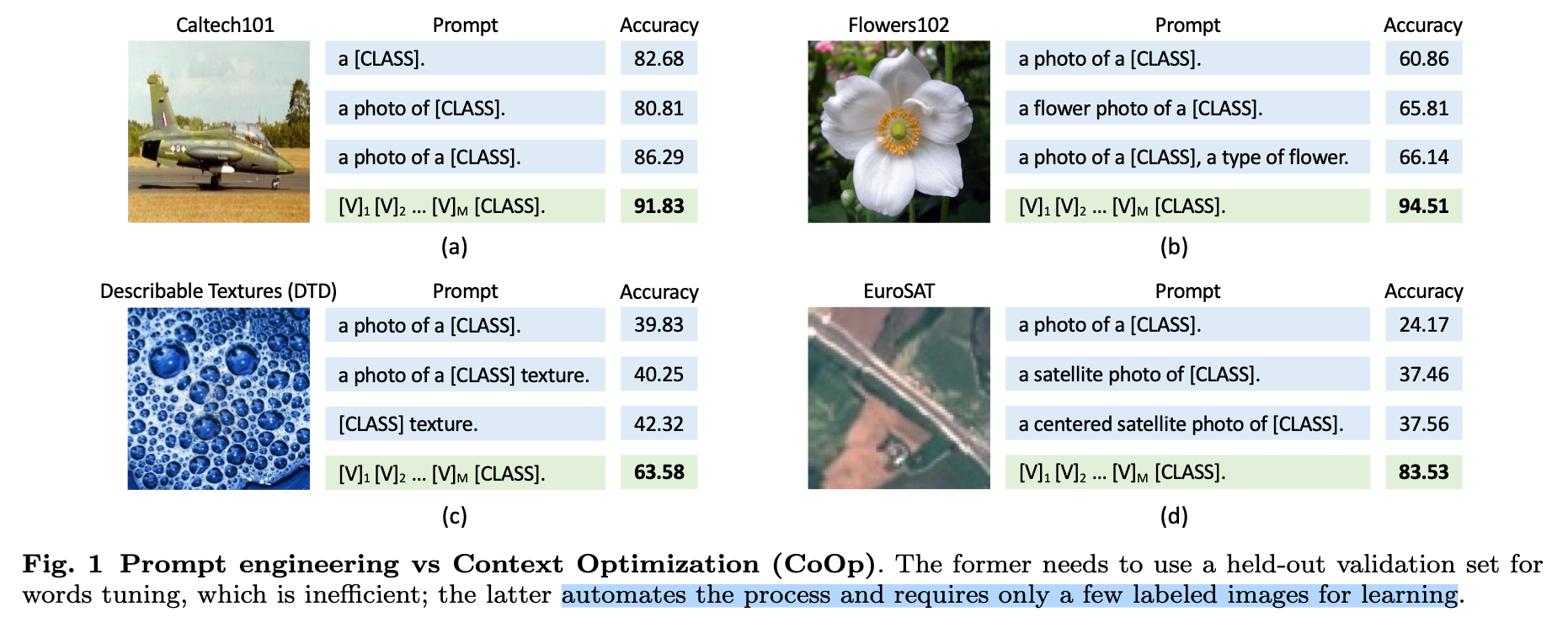
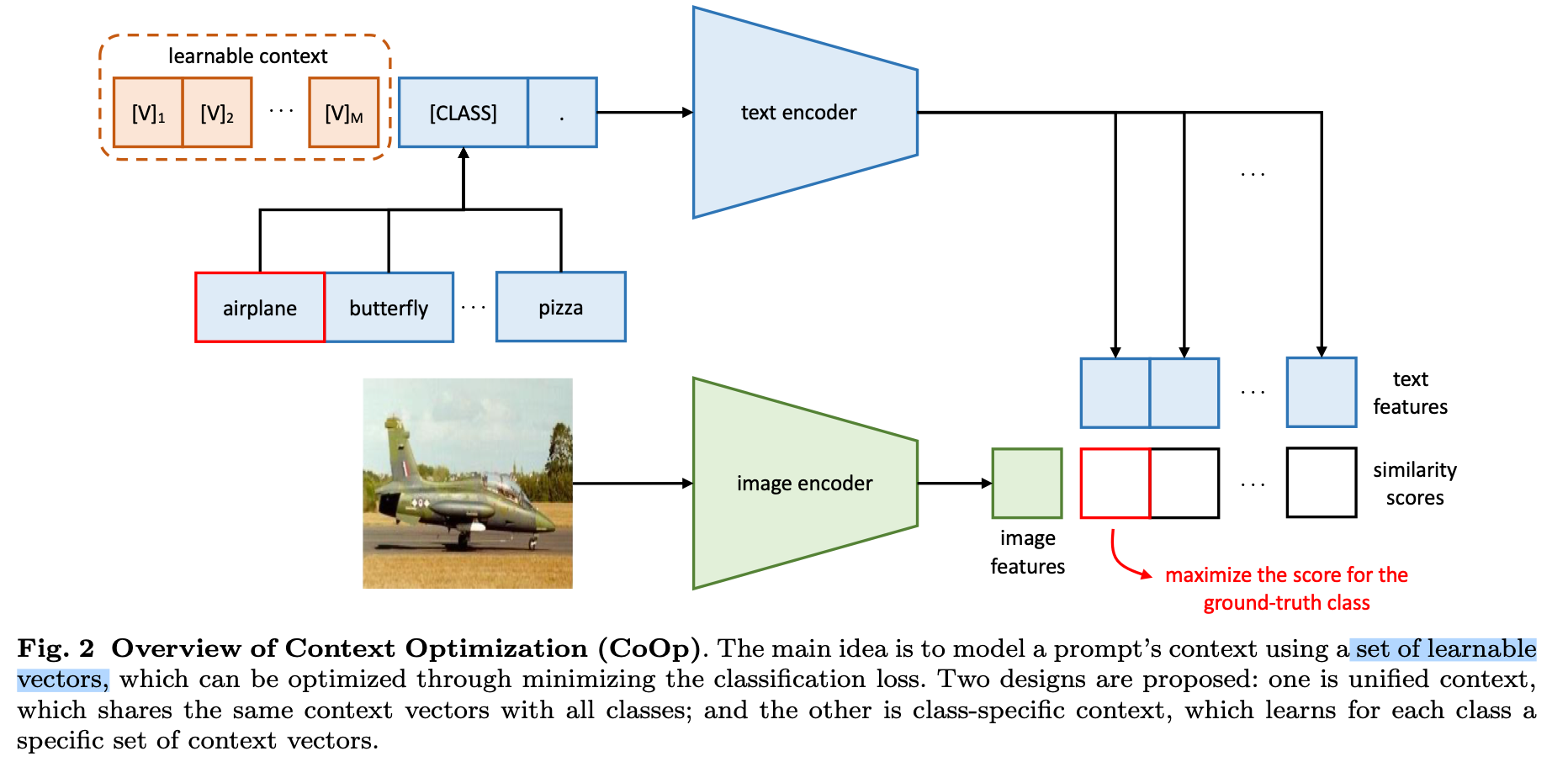
- 《Learning to Prompt for Vision-Language Models》【IJCV2022】Arxiv
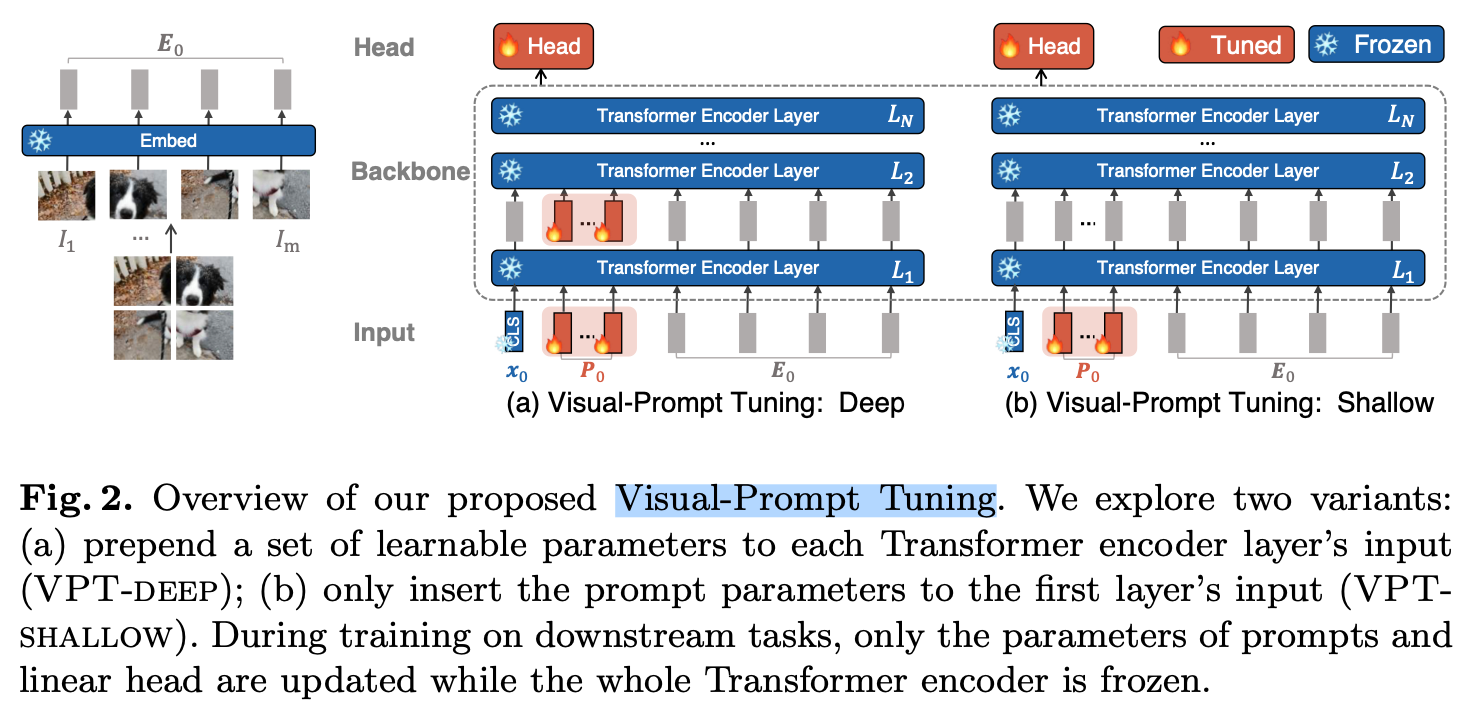
- 《Visual Prompt Tuning》【ECCV2022】Arxiv
- PEFT综述《Towards a Unified View of Parameter-Efficient Transfer Learning》【ICLR2022】Arxiv
Existing Stuff
目前的预训练模型和数据规模都很大,当计算资源少时尽量不要用预训练模型,可以选择Zero-shot或者Few-shot,或者Fine-tuning。可以借助存在的预训练模型(如CLIP);融入新的研究方向(如Causality Learning因果学习;FFNet;In-Context Learning;Chain of Thought Prompting)也是很好的选择,不用担心竞争和刷榜。
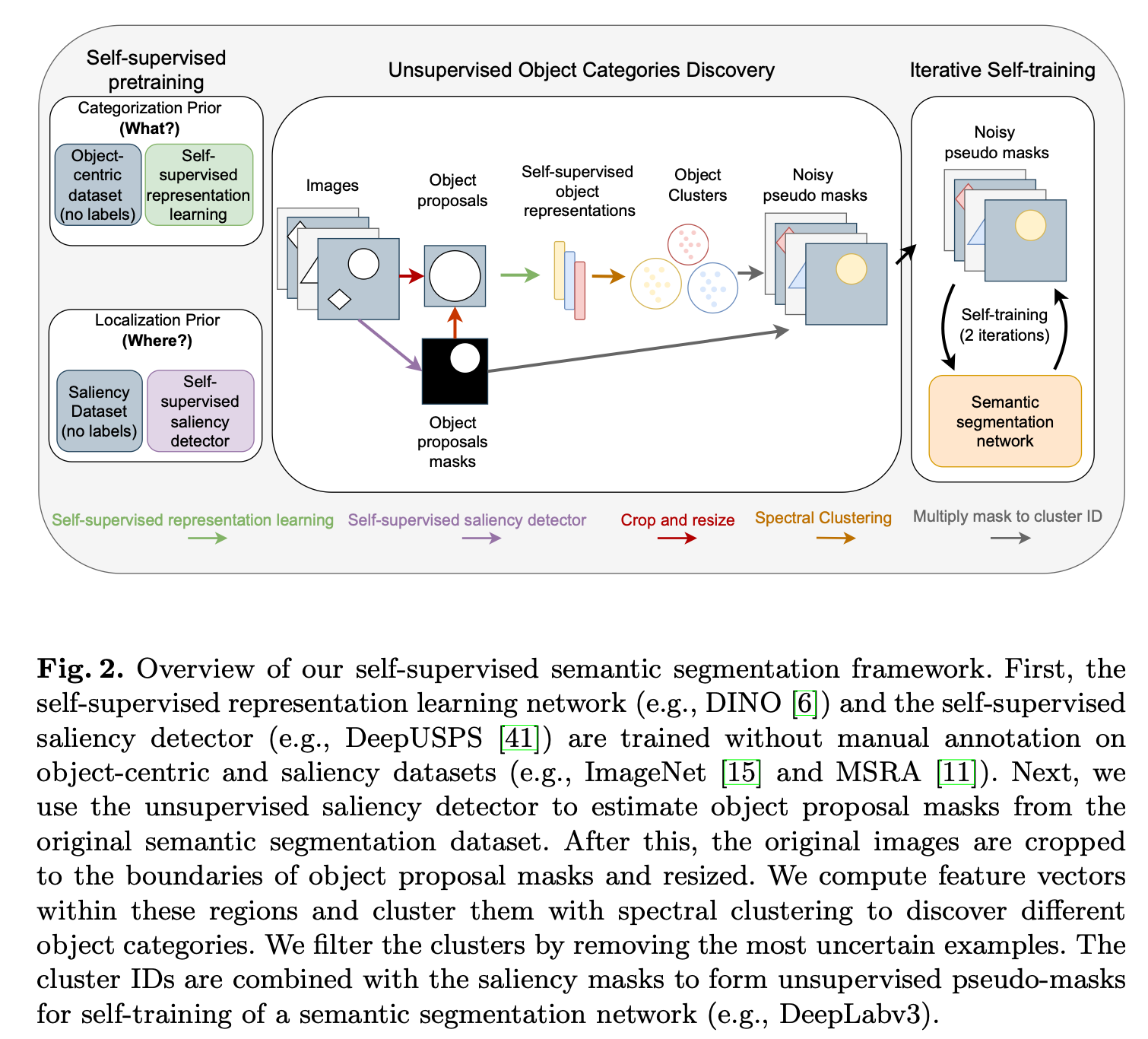
- 《Unsupervised Semantic Segmentation with Self-supervised Object-centric Representations》【ICLR2023】Arxiv
使用两个已经训练好的模型进行Object-centric Representations任务(较新的方向)
Plug and play
做一些通用的即插即用的模块,包括模型模块(ResNet+Non-Local)、loss函数(Focal Loss)、数据增强方式(Mixup)。选取baseline进行实验,在模型上有一个统一的提升即可,而不需要在大模型上训练。
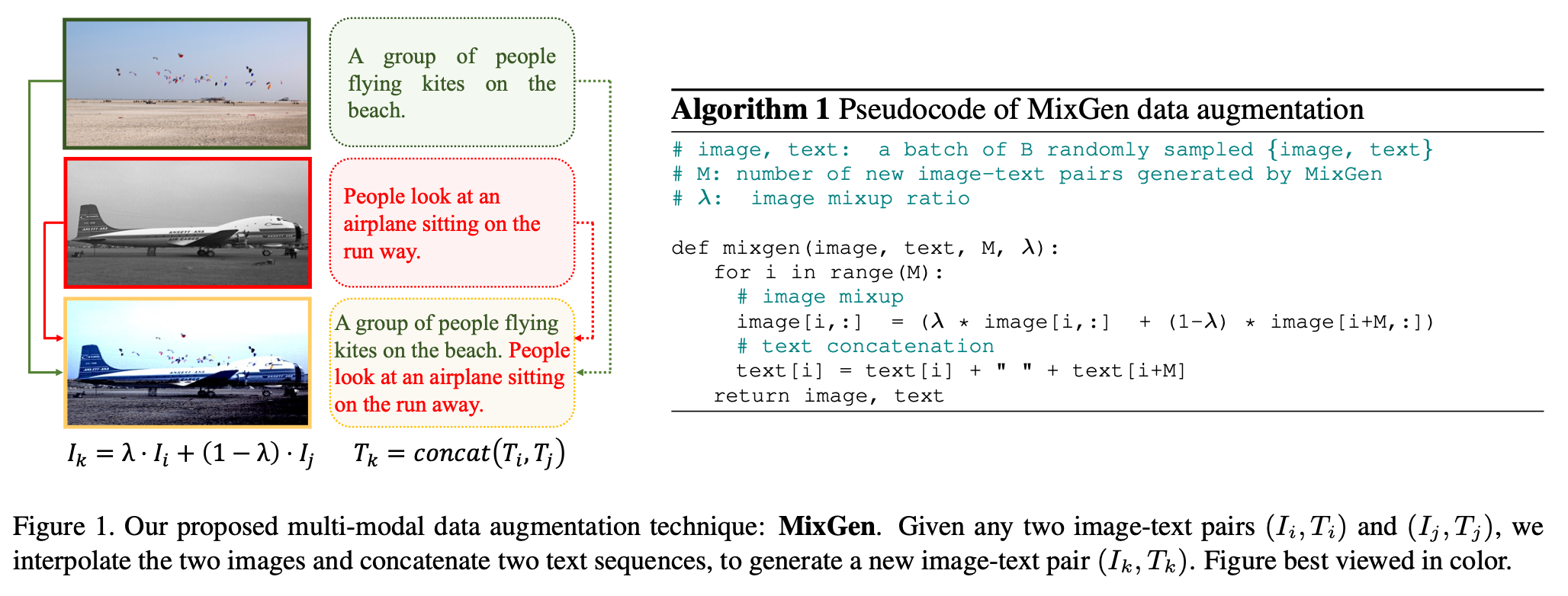
- 《MixGen: A New Multi-Modal Data Augmentation》【WACV2023】Arxiv
多模态预训练任务的原属数据量已经很多,不需要进行数据增强,但是下游任务不同仍然需要数据增强。问题是多模态数据增强时有些信息会丢失(如颜色、位置)导致图像文本对不匹配。MixGen的初衷即尽可能保留更多的信息。
Dataset, evaluation and survey
构建数据集;主要以分析为主的文章(如HELM语言模型评估);综述文章。可以加深对领域的理解同时也具有一定的影响力。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK