

本地推理,单机运行,MacM1芯片系统基于大语言模型C++版本LLaMA部署“本地版”的ChatGPT -...
source link: https://www.cnblogs.com/v3ucn/p/17250139.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

本地推理,单机运行,MacM1芯片系统基于大语言模型C++版本LLaMA部署“本地版”的ChatGPT
OpenAI公司基于GPT模型的ChatGPT风光无两,眼看它起朱楼,眼看它宴宾客,FaceBook终于坐不住了,发布了同样基于LLM的人工智能大语言模型LLaMA,号称包含70亿、130亿、330亿和650亿这4种参数规模的模型,参数是指神经网络中的权重和偏置等可调整的变量,用于训练和优化神经网络的性能,70亿意味着神经网络中有70亿个参数,由此类推。
在一些大型神经网络中,每个参数需要使用32位或64位浮点数进行存储,这意味着每个参数需要占用4字节或8字节的存储空间。因此,对于包含70亿个参数的神经网络,其存储空间将分别为8 GB或12GB。
此外,神经网络的大小不仅取决于参数的数量,还取决于神经元的数目,层数和其他结构参数等。因此,70亿的神经网络可能会占用更多的存储空间,具体取决于网络的结构和实现细节。
因此这种体量的模型单机跑绝对够我们喝一壶,所以本次使用最小的LLaMA 7B模型进行测试。
LLaMA项目安装和模型配置
和Stable-Diffusion项目如出一辙,FaceBook开源的LLaMA项目默认写死使用cuda模式,这也就意味着必须有 NVIDIA 的 GPU来训练和运行,不过好在大神GeorgiGerganov 用 C++ 基于 LLaMA 项目重写了一个跑在 CPU 上的移植版本 llama.cpp应用。
llama.cpp首先适配的就是苹果的M系列芯片,这对于果粉来说无疑是一个重大利好,首先通过命令拉取C++版本的LLaMA项目:
git clone https://github.com/ggerganov/llama.cpp
随后进入项目目录:
llama.cpp
在项目中,需要单独建立一个模型文件夹models:
mkdir models
随后去huggingface官网下载LLaMA的7B模型文件:https://huggingface.co/nyanko7/LLaMA-7B/tree/main
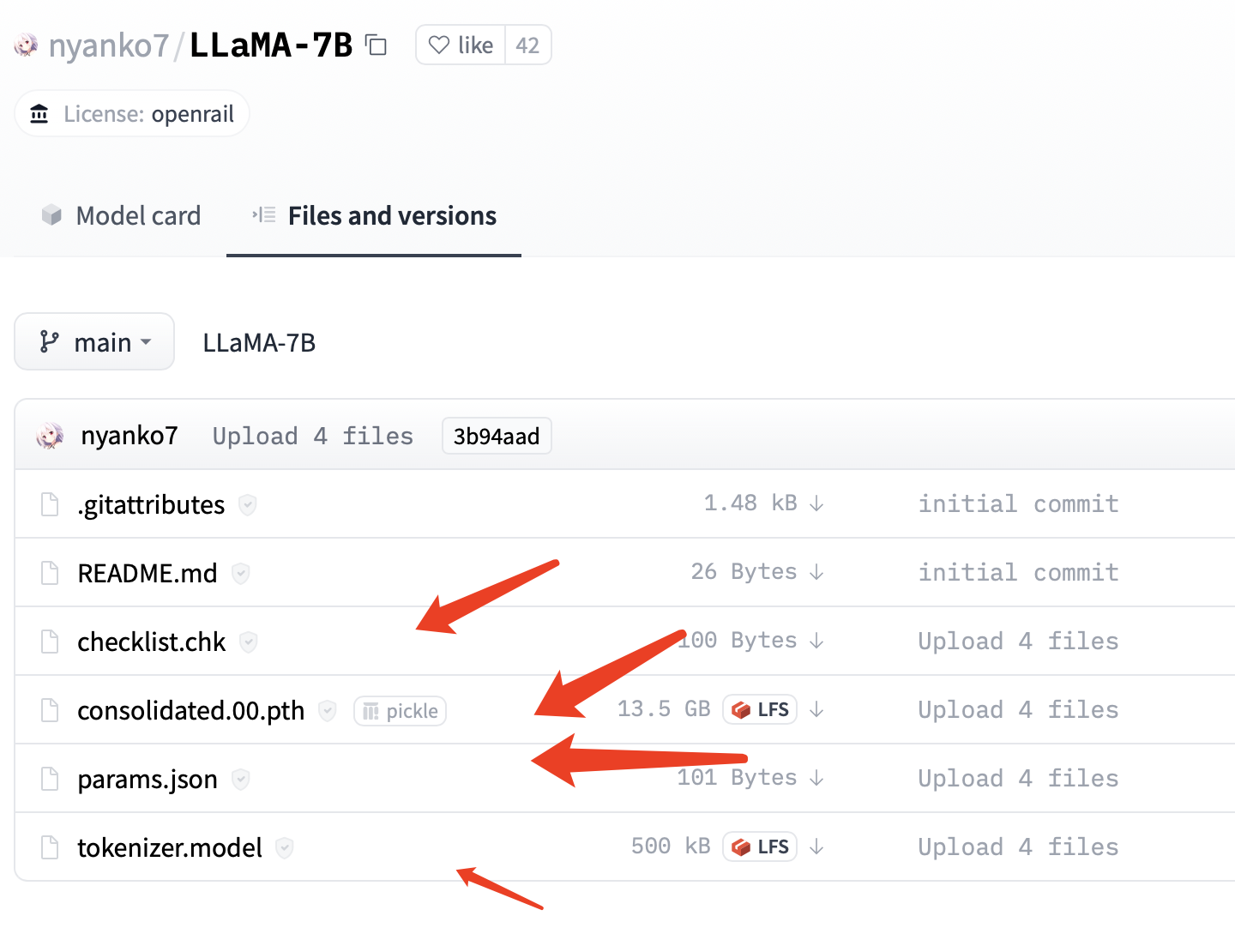
是的,主模型文件已经达到了13.5gb之巨,如果本地硬盘空间告急,请谨慎下载。
随后在models目录建立模型子目录7B:
mkdir 7B
将tokenizer.model和tokenizer_checklist.chk放入和7B平行的目录中:
➜ models git:(master) ✗ ls
7B tokenizer.model tokenizer_checklist.chk
随后将checklist.chk consolidated.00.pth和params.json放入7B目录中:
➜ 7B git:(master) ✗ ls
checklist.chk consolidated.00.pth params.json
至此,模型就配置好了。
LLaMA模型转换
由于我们没有使用FaceBook的原版项目,所以它的模型还需要进行转换,也就是转换为当前C++版本的LLaMA可以运行的模型。
这里通过Python脚本进行转换操作:
python3 convert-pth-to-ggml.py models/7B/ 1
第一个参数是模型所在目录,第二个参数为转换时使用的浮点类型,使用 float32,转换的结果文件会大一倍,当该参数值为 1时,则使用 float16 这个默认值,这里我们使用默认数据类型。
程序输出:
➜ llama.cpp git:(master) ✗ python convert-pth-to-ggml.py models/7B/ 1
{'dim': 4096, 'multiple_of': 256, 'n_heads': 32, 'n_layers': 32, 'norm_eps': 1e-06, 'vocab_size': -1}
n_parts = 1
Processing part 0
Processing variable: tok_embeddings.weight with shape: torch.Size([32000, 4096]) and type: torch.float16
Processing variable: norm.weight with shape: torch.Size([4096]) and type: torch.float16
Converting to float32
Processing variable: output.weight with shape: torch.Size([32000, 4096]) and type: torch.float16
Processing variable: layers.0.attention.wq.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.0.attention.wk.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.0.attention.wv.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.0.attention.wo.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.0.feed_forward.w1.weight with shape: torch.Size([11008, 4096]) and type: torch.float16
Processing variable: layers.0.feed_forward.w2.weight with shape: torch.Size([4096, 11008]) and type: torch.float16
Processing variable: layers.0.feed_forward.w3.weight with shape: torch.Size([11008, 4096]) and type: torch.float16
Processing variable: layers.0.attention_norm.weight with shape: torch.Size([4096]) and type: torch.float16
Converting to float32
Processing variable: layers.0.ffn_norm.weight with shape: torch.Size([4096]) and type: torch.float16
Converting to float32
Processing variable: layers.1.attention.wq.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.1.attention.wk.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.1.attention.wv.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.1.attention.wo.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.1.feed_forward.w1.weight with shape: torch.Size([11008, 4096]) and type: torch.float16
Processing variable: layers.1.feed_forward.w2.weight with shape: torch.Size([4096, 11008]) and type: torch.float16
Processing variable: layers.1.feed_forward.w3.weight with shape: torch.Size([11008, 4096]) and type: torch.float16
Processing variable: layers.1.attention_norm.weight with shape: torch.Size([4096]) and type: torch.float16
Converting to float32
Processing variable: layers.1.ffn_norm.weight with shape: torch.Size([4096]) and type: torch.float16
Converting to float32
Processing variable: layers.2.attention.wq.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.2.attention.wk.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.2.attention.wv.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.2.attention.wo.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.2.feed_forward.w1.weight with shape: torch.Size([11008, 4096]) and type: torch.float16
Processing variable: layers.2.feed_forward.w2.weight with shape: torch.Size([4096, 11008]) and type: torch.float16
Processing variable: layers.2.feed_forward.w3.weight with shape: torch.Size([11008, 4096]) and type: torch.float16
Processing variable: layers.2.attention_norm.weight with shape: torch.Size([4096]) and type: torch.float16
Converting to float32
Processing variable: layers.2.ffn_norm.weight with shape: torch.Size([4096]) and type: torch.float16
Converting to float32
Processing variable: layers.3.attention.wq.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.3.attention.wk.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.3.attention.wv.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.3.attention.wo.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.3.feed_forward.w1.weight with shape: torch.Size([11008, 4096]) and type: torch.float16
Processing variable: layers.3.feed_forward.w2.weight with shape: torch.Size([4096, 11008]) and type: torch.float16
Processing variable: layers.3.feed_forward.w3.weight with shape: torch.Size([11008, 4096]) and type: torch.float16
Processing variable: layers.3.attention_norm.weight with shape: torch.Size([4096]) and type: torch.float16
Converting to float32
Processing variable: layers.3.ffn_norm.weight with shape: torch.Size([4096]) and type: torch.float16
Converting to float32
Processing variable: layers.4.attention.wq.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.4.attention.wk.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.4.attention.wv.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.4.attention.wo.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.4.feed_forward.w1.weight with shape: torch.Size([11008, 4096]) and type: torch.float16
Processing variable: layers.4.feed_forward.w2.weight with shape: torch.Size([4096, 11008]) and type: torch.float16
Processing variable: layers.4.feed_forward.w3.weight with shape: torch.Size([11008, 4096]) and type: torch.float16
Processing variable: layers.4.attention_norm.weight with shape: torch.Size([4096]) and type: torch.float16
Converting to float32
Processing variable: layers.4.ffn_norm.weight with shape: torch.Size([4096]) and type: torch.float16
Converting to float32
Processing variable: layers.5.attention.wq.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.5.attention.wk.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.5.attention.wv.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.5.attention.wo.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.5.feed_forward.w1.weight with shape: torch.Size([11008, 4096]) and type: torch.float16
Processing variable: layers.5.feed_forward.w2.weight with shape: torch.Size([4096, 11008]) and type: torch.float16
Processing variable: layers.5.feed_forward.w3.weight with shape: torch.Size([11008, 4096]) and type: torch.float16
Processing variable: layers.5.attention_norm.weight with shape: torch.Size([4096]) and type: torch.float16
Converting to float32
Processing variable: layers.5.ffn_norm.weight with shape: torch.Size([4096]) and type: torch.float16
Converting to float32
Processing variable: layers.6.attention.wq.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.6.attention.wk.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.6.attention.wv.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.6.attention.wo.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.6.feed_forward.w1.weight with shape: torch.Size([11008, 4096]) and type: torch.float16
Processing variable: layers.6.feed_forward.w2.weight with shape: torch.Size([4096, 11008]) and type: torch.float16
Processing variable: layers.6.feed_forward.w3.weight with shape: torch.Size([11008, 4096]) and type: torch.float16
Processing variable: layers.6.attention_norm.weight with shape: torch.Size([4096]) and type: torch.float16
Converting to float32
Processing variable: layers.6.ffn_norm.weight with shape: torch.Size([4096]) and type: torch.float16
Converting to float32
Processing variable: layers.7.attention.wq.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.7.attention.wk.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.7.attention.wv.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.7.attention.wo.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.7.feed_forward.w1.weight with shape: torch.Size([11008, 4096]) and type: torch.float16
Processing variable: layers.7.feed_forward.w2.weight with shape: torch.Size([4096, 11008]) and type: torch.float16
Processing variable: layers.7.feed_forward.w3.weight with shape: torch.Size([11008, 4096]) and type: torch.float16
Processing variable: layers.7.attention_norm.weight with shape: torch.Size([4096]) and type: torch.float16
Converting to float32
Processing variable: layers.7.ffn_norm.weight with shape: torch.Size([4096]) and type: torch.float16
Converting to float32
Processing variable: layers.8.attention.wq.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.8.attention.wk.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.8.attention.wv.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.8.attention.wo.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.8.feed_forward.w1.weight with shape: torch.Size([11008, 4096]) and type: torch.float16
Processing variable: layers.8.feed_forward.w2.weight with shape: torch.Size([4096, 11008]) and type: torch.float16
Processing variable: layers.8.feed_forward.w3.weight with shape: torch.Size([11008, 4096]) and type: torch.float16
Processing variable: layers.8.attention_norm.weight with shape: torch.Size([4096]) and type: torch.float16
Converting to float32
Processing variable: layers.8.ffn_norm.weight with shape: torch.Size([4096]) and type: torch.float16
Converting to float32
Processing variable: layers.9.attention.wq.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.9.attention.wk.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.9.attention.wv.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.9.attention.wo.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.9.feed_forward.w1.weight with shape: torch.Size([11008, 4096]) and type: torch.float16
Processing variable: layers.9.feed_forward.w2.weight with shape: torch.Size([4096, 11008]) and type: torch.float16
Processing variable: layers.9.feed_forward.w3.weight with shape: torch.Size([11008, 4096]) and type: torch.float16
Processing variable: layers.9.attention_norm.weight with shape: torch.Size([4096]) and type: torch.float16
Converting to float32
Processing variable: layers.9.ffn_norm.weight with shape: torch.Size([4096]) and type: torch.float16
Converting to float32
Processing variable: layers.10.attention.wq.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.10.attention.wk.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.10.attention.wv.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.10.attention.wo.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.10.feed_forward.w1.weight with shape: torch.Size([11008, 4096]) and type: torch.float16
Processing variable: layers.10.feed_forward.w2.weight with shape: torch.Size([4096, 11008]) and type: torch.float16
Processing variable: layers.10.feed_forward.w3.weight with shape: torch.Size([11008, 4096]) and type: torch.float16
Processing variable: layers.10.attention_norm.weight with shape: torch.Size([4096]) and type: torch.float16
Converting to float32
Processing variable: layers.10.ffn_norm.weight with shape: torch.Size([4096]) and type: torch.float16
Converting to float32
Processing variable: layers.11.attention.wq.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.11.attention.wk.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.11.attention.wv.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.11.attention.wo.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.11.feed_forward.w1.weight with shape: torch.Size([11008, 4096]) and type: torch.float16
Processing variable: layers.11.feed_forward.w2.weight with shape: torch.Size([4096, 11008]) and type: torch.float16
Processing variable: layers.11.feed_forward.w3.weight with shape: torch.Size([11008, 4096]) and type: torch.float16
Processing variable: layers.11.attention_norm.weight with shape: torch.Size([4096]) and type: torch.float16
Converting to float32
Processing variable: layers.11.ffn_norm.weight with shape: torch.Size([4096]) and type: torch.float16
Converting to float32
Processing variable: layers.12.attention.wq.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.12.attention.wk.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.12.attention.wv.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.12.attention.wo.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.12.feed_forward.w1.weight with shape: torch.Size([11008, 4096]) and type: torch.float16
Processing variable: layers.12.feed_forward.w2.weight with shape: torch.Size([4096, 11008]) and type: torch.float16
Processing variable: layers.12.feed_forward.w3.weight with shape: torch.Size([11008, 4096]) and type: torch.float16
Processing variable: layers.12.attention_norm.weight with shape: torch.Size([4096]) and type: torch.float16
Converting to float32
Processing variable: layers.12.ffn_norm.weight with shape: torch.Size([4096]) and type: torch.float16
Converting to float32
Processing variable: layers.13.attention.wq.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.13.attention.wk.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.13.attention.wv.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.13.attention.wo.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.13.feed_forward.w1.weight with shape: torch.Size([11008, 4096]) and type: torch.float16
Processing variable: layers.13.feed_forward.w2.weight with shape: torch.Size([4096, 11008]) and type: torch.float16
Processing variable: layers.13.feed_forward.w3.weight with shape: torch.Size([11008, 4096]) and type: torch.float16
Processing variable: layers.13.attention_norm.weight with shape: torch.Size([4096]) and type: torch.float16
Converting to float32
Processing variable: layers.13.ffn_norm.weight with shape: torch.Size([4096]) and type: torch.float16
Converting to float32
Processing variable: layers.14.attention.wq.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.14.attention.wk.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.14.attention.wv.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.14.attention.wo.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.14.feed_forward.w1.weight with shape: torch.Size([11008, 4096]) and type: torch.float16
Processing variable: layers.14.feed_forward.w2.weight with shape: torch.Size([4096, 11008]) and type: torch.float16
Processing variable: layers.14.feed_forward.w3.weight with shape: torch.Size([11008, 4096]) and type: torch.float16
Processing variable: layers.14.attention_norm.weight with shape: torch.Size([4096]) and type: torch.float16
Converting to float32
Processing variable: layers.14.ffn_norm.weight with shape: torch.Size([4096]) and type: torch.float16
Converting to float32
Processing variable: layers.15.attention.wq.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.15.attention.wk.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.15.attention.wv.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.15.attention.wo.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.15.feed_forward.w1.weight with shape: torch.Size([11008, 4096]) and type: torch.float16
Processing variable: layers.15.feed_forward.w2.weight with shape: torch.Size([4096, 11008]) and type: torch.float16
Processing variable: layers.15.feed_forward.w3.weight with shape: torch.Size([11008, 4096]) and type: torch.float16
Processing variable: layers.15.attention_norm.weight with shape: torch.Size([4096]) and type: torch.float16
Converting to float32
Processing variable: layers.15.ffn_norm.weight with shape: torch.Size([4096]) and type: torch.float16
Converting to float32
Processing variable: layers.16.attention.wq.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.16.attention.wk.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.16.attention.wv.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.16.attention.wo.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.16.feed_forward.w1.weight with shape: torch.Size([11008, 4096]) and type: torch.float16
Processing variable: layers.16.feed_forward.w2.weight with shape: torch.Size([4096, 11008]) and type: torch.float16
Processing variable: layers.16.feed_forward.w3.weight with shape: torch.Size([11008, 4096]) and type: torch.float16
Processing variable: layers.16.attention_norm.weight with shape: torch.Size([4096]) and type: torch.float16
Converting to float32
Processing variable: layers.16.ffn_norm.weight with shape: torch.Size([4096]) and type: torch.float16
Converting to float32
Processing variable: layers.17.attention.wq.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.17.attention.wk.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.17.attention.wv.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.17.attention.wo.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.17.feed_forward.w1.weight with shape: torch.Size([11008, 4096]) and type: torch.float16
Processing variable: layers.17.feed_forward.w2.weight with shape: torch.Size([4096, 11008]) and type: torch.float16
Processing variable: layers.17.feed_forward.w3.weight with shape: torch.Size([11008, 4096]) and type: torch.float16
Processing variable: layers.17.attention_norm.weight with shape: torch.Size([4096]) and type: torch.float16
Converting to float32
Processing variable: layers.17.ffn_norm.weight with shape: torch.Size([4096]) and type: torch.float16
Converting to float32
Processing variable: layers.18.attention.wq.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.18.attention.wk.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.18.attention.wv.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.18.attention.wo.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.18.feed_forward.w1.weight with shape: torch.Size([11008, 4096]) and type: torch.float16
Processing variable: layers.18.feed_forward.w2.weight with shape: torch.Size([4096, 11008]) and type: torch.float16
Processing variable: layers.18.feed_forward.w3.weight with shape: torch.Size([11008, 4096]) and type: torch.float16
Processing variable: layers.18.attention_norm.weight with shape: torch.Size([4096]) and type: torch.float16
Converting to float32
Processing variable: layers.18.ffn_norm.weight with shape: torch.Size([4096]) and type: torch.float16
Converting to float32
Processing variable: layers.19.attention.wq.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.19.attention.wk.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.19.attention.wv.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.19.attention.wo.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.19.feed_forward.w1.weight with shape: torch.Size([11008, 4096]) and type: torch.float16
Processing variable: layers.19.feed_forward.w2.weight with shape: torch.Size([4096, 11008]) and type: torch.float16
Processing variable: layers.19.feed_forward.w3.weight with shape: torch.Size([11008, 4096]) and type: torch.float16
Processing variable: layers.19.attention_norm.weight with shape: torch.Size([4096]) and type: torch.float16
Converting to float32
Processing variable: layers.19.ffn_norm.weight with shape: torch.Size([4096]) and type: torch.float16
Converting to float32
Processing variable: layers.20.attention.wq.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.20.attention.wk.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.20.attention.wv.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.20.attention.wo.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.20.feed_forward.w1.weight with shape: torch.Size([11008, 4096]) and type: torch.float16
Processing variable: layers.20.feed_forward.w2.weight with shape: torch.Size([4096, 11008]) and type: torch.float16
Processing variable: layers.20.feed_forward.w3.weight with shape: torch.Size([11008, 4096]) and type: torch.float16
Processing variable: layers.20.attention_norm.weight with shape: torch.Size([4096]) and type: torch.float16
Converting to float32
Processing variable: layers.20.ffn_norm.weight with shape: torch.Size([4096]) and type: torch.float16
Converting to float32
Processing variable: layers.21.attention.wq.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.21.attention.wk.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.21.attention.wv.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.21.attention.wo.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.21.feed_forward.w1.weight with shape: torch.Size([11008, 4096]) and type: torch.float16
Processing variable: layers.21.feed_forward.w2.weight with shape: torch.Size([4096, 11008]) and type: torch.float16
Processing variable: layers.21.feed_forward.w3.weight with shape: torch.Size([11008, 4096]) and type: torch.float16
Processing variable: layers.21.attention_norm.weight with shape: torch.Size([4096]) and type: torch.float16
Converting to float32
Processing variable: layers.21.ffn_norm.weight with shape: torch.Size([4096]) and type: torch.float16
Converting to float32
Processing variable: layers.22.attention.wq.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.22.attention.wk.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.22.attention.wv.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.22.attention.wo.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.22.feed_forward.w1.weight with shape: torch.Size([11008, 4096]) and type: torch.float16
Processing variable: layers.22.feed_forward.w2.weight with shape: torch.Size([4096, 11008]) and type: torch.float16
Processing variable: layers.22.feed_forward.w3.weight with shape: torch.Size([11008, 4096]) and type: torch.float16
Processing variable: layers.22.attention_norm.weight with shape: torch.Size([4096]) and type: torch.float16
Converting to float32
Processing variable: layers.22.ffn_norm.weight with shape: torch.Size([4096]) and type: torch.float16
Converting to float32
Processing variable: layers.23.attention.wq.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.23.attention.wk.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.23.attention.wv.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.23.attention.wo.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.23.feed_forward.w1.weight with shape: torch.Size([11008, 4096]) and type: torch.float16
Processing variable: layers.23.feed_forward.w2.weight with shape: torch.Size([4096, 11008]) and type: torch.float16
Processing variable: layers.23.feed_forward.w3.weight with shape: torch.Size([11008, 4096]) and type: torch.float16
Processing variable: layers.23.attention_norm.weight with shape: torch.Size([4096]) and type: torch.float16
Converting to float32
Processing variable: layers.23.ffn_norm.weight with shape: torch.Size([4096]) and type: torch.float16
Converting to float32
Processing variable: layers.24.attention.wq.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.24.attention.wk.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.24.attention.wv.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.24.attention.wo.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.24.feed_forward.w1.weight with shape: torch.Size([11008, 4096]) and type: torch.float16
Processing variable: layers.24.feed_forward.w2.weight with shape: torch.Size([4096, 11008]) and type: torch.float16
Processing variable: layers.24.feed_forward.w3.weight with shape: torch.Size([11008, 4096]) and type: torch.float16
Processing variable: layers.24.attention_norm.weight with shape: torch.Size([4096]) and type: torch.float16
Converting to float32
Processing variable: layers.24.ffn_norm.weight with shape: torch.Size([4096]) and type: torch.float16
Converting to float32
Processing variable: layers.25.attention.wq.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.25.attention.wk.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.25.attention.wv.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.25.attention.wo.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.25.feed_forward.w1.weight with shape: torch.Size([11008, 4096]) and type: torch.float16
Processing variable: layers.25.feed_forward.w2.weight with shape: torch.Size([4096, 11008]) and type: torch.float16
Processing variable: layers.25.feed_forward.w3.weight with shape: torch.Size([11008, 4096]) and type: torch.float16
Processing variable: layers.25.attention_norm.weight with shape: torch.Size([4096]) and type: torch.float16
Converting to float32
Processing variable: layers.25.ffn_norm.weight with shape: torch.Size([4096]) and type: torch.float16
Converting to float32
Processing variable: layers.26.attention.wq.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.26.attention.wk.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.26.attention.wv.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.26.attention.wo.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.26.feed_forward.w1.weight with shape: torch.Size([11008, 4096]) and type: torch.float16
Processing variable: layers.26.feed_forward.w2.weight with shape: torch.Size([4096, 11008]) and type: torch.float16
Processing variable: layers.26.feed_forward.w3.weight with shape: torch.Size([11008, 4096]) and type: torch.float16
Processing variable: layers.26.attention_norm.weight with shape: torch.Size([4096]) and type: torch.float16
Converting to float32
Processing variable: layers.26.ffn_norm.weight with shape: torch.Size([4096]) and type: torch.float16
Converting to float32
Processing variable: layers.27.attention.wq.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.27.attention.wk.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.27.attention.wv.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.27.attention.wo.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.27.feed_forward.w1.weight with shape: torch.Size([11008, 4096]) and type: torch.float16
Processing variable: layers.27.feed_forward.w2.weight with shape: torch.Size([4096, 11008]) and type: torch.float16
Processing variable: layers.27.feed_forward.w3.weight with shape: torch.Size([11008, 4096]) and type: torch.float16
Processing variable: layers.27.attention_norm.weight with shape: torch.Size([4096]) and type: torch.float16
Converting to float32
Processing variable: layers.27.ffn_norm.weight with shape: torch.Size([4096]) and type: torch.float16
Converting to float32
Processing variable: layers.28.attention.wq.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.28.attention.wk.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.28.attention.wv.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.28.attention.wo.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.28.feed_forward.w1.weight with shape: torch.Size([11008, 4096]) and type: torch.float16
Processing variable: layers.28.feed_forward.w2.weight with shape: torch.Size([4096, 11008]) and type: torch.float16
Processing variable: layers.28.feed_forward.w3.weight with shape: torch.Size([11008, 4096]) and type: torch.float16
Processing variable: layers.28.attention_norm.weight with shape: torch.Size([4096]) and type: torch.float16
Converting to float32
Processing variable: layers.28.ffn_norm.weight with shape: torch.Size([4096]) and type: torch.float16
Converting to float32
Processing variable: layers.29.attention.wq.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.29.attention.wk.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.29.attention.wv.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.29.attention.wo.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.29.feed_forward.w1.weight with shape: torch.Size([11008, 4096]) and type: torch.float16
Processing variable: layers.29.feed_forward.w2.weight with shape: torch.Size([4096, 11008]) and type: torch.float16
Processing variable: layers.29.feed_forward.w3.weight with shape: torch.Size([11008, 4096]) and type: torch.float16
Processing variable: layers.29.attention_norm.weight with shape: torch.Size([4096]) and type: torch.float16
Converting to float32
Processing variable: layers.29.ffn_norm.weight with shape: torch.Size([4096]) and type: torch.float16
Converting to float32
Processing variable: layers.30.attention.wq.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.30.attention.wk.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.30.attention.wv.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.30.attention.wo.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.30.feed_forward.w1.weight with shape: torch.Size([11008, 4096]) and type: torch.float16
Processing variable: layers.30.feed_forward.w2.weight with shape: torch.Size([4096, 11008]) and type: torch.float16
Processing variable: layers.30.feed_forward.w3.weight with shape: torch.Size([11008, 4096]) and type: torch.float16
Processing variable: layers.30.attention_norm.weight with shape: torch.Size([4096]) and type: torch.float16
Converting to float32
Processing variable: layers.30.ffn_norm.weight with shape: torch.Size([4096]) and type: torch.float16
Converting to float32
Processing variable: layers.31.attention.wq.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.31.attention.wk.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.31.attention.wv.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.31.attention.wo.weight with shape: torch.Size([4096, 4096]) and type: torch.float16
Processing variable: layers.31.feed_forward.w1.weight with shape: torch.Size([11008, 4096]) and type: torch.float16
Processing variable: layers.31.feed_forward.w2.weight with shape: torch.Size([4096, 11008]) and type: torch.float16
Processing variable: layers.31.feed_forward.w3.weight with shape: torch.Size([11008, 4096]) and type: torch.float16
Processing variable: layers.31.attention_norm.weight with shape: torch.Size([4096]) and type: torch.float16
Converting to float32
Processing variable: layers.31.ffn_norm.weight with shape: torch.Size([4096]) and type: torch.float16
Converting to float32
Done. Output file: models/7B//ggml-model-f16.bin, (part 0)
可以看到,如果转换成功,会在models/7B/目录生成一个C++可以调用的ggml-model-f16.bin模型文件。
LLaMA模型调用
接下来就可以调用转换后的模型了,首先在编译C++项目:
make
程序返回:
➜ llama.cpp git:(master) ✗ make
I llama.cpp build info:
I UNAME_S: Darwin
I UNAME_P: arm
I UNAME_M: arm64
I CFLAGS: -I. -O3 -DNDEBUG -std=c11 -fPIC -pthread -DGGML_USE_ACCELERATE
I CXXFLAGS: -I. -I./examples -O3 -DNDEBUG -std=c++17 -fPIC -pthread
I LDFLAGS: -framework Accelerate
I CC: Apple clang version 14.0.0 (clang-1400.0.29.202)
I CXX: Apple clang version 14.0.0 (clang-1400.0.29.202)
cc -I. -O3 -DNDEBUG -std=c11 -fPIC -pthread -DGGML_USE_ACCELERATE -c ggml.c -o ggml.o
c++ -I. -I./examples -O3 -DNDEBUG -std=c++17 -fPIC -pthread -c utils.cpp -o utils.o
c++ -I. -I./examples -O3 -DNDEBUG -std=c++17 -fPIC -pthread main.cpp ggml.o utils.o -o main -framework Accelerate
./main -h
usage: ./main [options]
options:
-h, --help show this help message and exit
-i, --interactive run in interactive mode
-ins, --instruct run in instruction mode (use with Alpaca models)
-r PROMPT, --reverse-prompt PROMPT
in interactive mode, poll user input upon seeing PROMPT (can be
specified more than once for multiple prompts).
--color colorise output to distinguish prompt and user input from generations
-s SEED, --seed SEED RNG seed (default: -1)
-t N, --threads N number of threads to use during computation (default: 4)
-p PROMPT, --prompt PROMPT
prompt to start generation with (default: empty)
--random-prompt start with a randomized prompt.
-f FNAME, --file FNAME
prompt file to start generation.
-n N, --n_predict N number of tokens to predict (default: 128)
--top_k N top-k sampling (default: 40)
--top_p N top-p sampling (default: 0.9)
--repeat_last_n N last n tokens to consider for penalize (default: 64)
--repeat_penalty N penalize repeat sequence of tokens (default: 1.3)
-c N, --ctx_size N size of the prompt context (default: 512)
--ignore-eos ignore end of stream token and continue generating
--memory_f16 use f16 instead of f32 for memory key+value
--temp N temperature (default: 0.8)
-b N, --batch_size N batch size for prompt processing (default: 8)
-m FNAME, --model FNAME
model path (default: models/llama-7B/ggml-model.bin)
c++ -I. -I./examples -O3 -DNDEBUG -std=c++17 -fPIC -pthread quantize.cpp ggml.o utils.o -o quantize -framework Accelerate
编译成功后,本地会生成一个main.cpp文件。
随后根据编译后输出的说明文档直接调用模型即可:
./main -m ./models/7B/ggml-model-f16.bin -p 'Hi i am '
程序输出:
➜ llama.cpp git:(master) ✗ ./main -m ./models/7B/ggml-model-f16.bin -p 'hi i am'
main: seed = 1679400707
llama_model_load: loading model from './models/7B/ggml-model-f16.bin' - please wait ...
llama_model_load: n_vocab = 32000
llama_model_load: n_ctx = 512
llama_model_load: n_embd = 4096
llama_model_load: n_mult = 256
llama_model_load: n_head = 32
llama_model_load: n_layer = 32
llama_model_load: n_rot = 128
llama_model_load: f16 = 1
llama_model_load: n_ff = 11008
llama_model_load: n_parts = 1
llama_model_load: ggml ctx size = 13365.09 MB
llama_model_load: memory_size = 512.00 MB, n_mem = 16384
llama_model_load: loading model part 1/1 from './models/7B/ggml-model-f16.bin'
llama_model_load: .................................... done
llama_model_load: model size = 12853.02 MB / num tensors = 291
system_info: n_threads = 4 / 10 | AVX = 0 | AVX2 = 0 | AVX512 = 0 | FMA = 0 | NEON = 1 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | VSX = 0 |
main: prompt: ' hi i am'
main: number of tokens in prompt = 6
1 -> ''
13450 -> ' hi'
423 -> 'i'
25523 -> ' am'
sampling parameters: temp = 0.800000, top_k = 40, top_p = 0.950000, repeat_last_n = 64, repeat_penalty = 1.300000
hi i am a pythoner, but sunk to become a ruby
说实话,推理速度实在不敢恭维,也可能是因为笔者的电脑配置太渣导致。
LLaMA 7B模型总体上需要纯英文的提示词(prompt),对中文的理解能力还不够,优势是确实可以单机跑起来,当然本地跑的话,减少了网络传输数据的环节,推理效率自然也就更高,对于普通的AI爱好者来说,足矣。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK