

CURL: Contrastive Unsupervised Representations for Reinforcement Learning 阅读
source link: https://mathpretty.com/15731.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

CURL: Contrastive Unsupervised Representations for Reinforcement Learning 阅读
摘要本文是阅读论文 CURL: Contrastive Unsupervised Representations for Reinforcement Learning 的一些记录。这篇论文主要是引入了对比学习在强化学习中,从而提升数据的利用效率。可以学习一下如何构建对比学习所需要的正样本和负样本的。
本文是阅读论文 CURL: Contrastive Unsupervised Representations for Reinforcement Learning 的一些记录。
在强化学习领域,当面对复杂输入的情况的时候,RL 的数据利用率是不高的。特别的,使用 state-based input 的效果会比 image-based input 要好。于是作者在本文中使用对比学习的方法来提升网络信息提取的能力。
本文的核心就是下面这句话,CURL extracts high-level features from raw pixels using contrastive learning and performs off-policy control on top of the extracted features.
最终的实验结果表明,对于使用 pixel-based input,使用该方法在 DMControl 和 Atari 环境与目前最好的模型分别提升 1.9x 和 1.2x。
CURL 介绍
在强化学习领域,解决复杂输入问题一直是一个挑战,特别是考虑直接输入图像(或视频)。 现在主流的有两种方法:
- 增加对输入的特征提取任务,保证输入信息有效;
- 采用model based的方式,建立世界模型,对未来进行预测。同期的
Dreamer就是采用这个模型。
这篇文章采用了第一种方式,采用「对比学习方法」来保证提取的特征对是有效的特征。整个文章其实基于下面的一个假设:
Our hypothesis is simple: If an agent learns a useful semantic representation from high-dimensional observations, control algorithms built on top of those representations should be significantly more data-efficient.
后来作者又做了一篇发现只用数据增强可以获得更好的效果,特别是使用 crop 的方式。Reinforcement Learning with Augmented Data 阅读。
CURL 的主要贡献
Our paper makes the following key contributions:
- We present CURL, a simple framework that integrates contrastive learning with model-free RL with minimal changes to the architecture and training pipeline.(提出了 CURL 框架,且不需要对之前的 RL 训练的框架进行很大的修改)
- Using 16 complex control tasks from the DeepMind control (DMControl) suite and 26 Atari games, we empirically show that contrastive learning combined with model-free RL outperforms the prior state-of-the-art by 1.9x on DMControl and 1.2x on Atari compared across leading prior pixel-based methods.(在不同的任务上都可以获得较好的表现)
- CURL is also the first algorithm across both model-based and model-free methods that operate purely from pixels, and nearly matches the performance and sample efficiency of a SAC algorithm trained from the state-based features on the DMControl suite.(还是再说这个方法不挑强化学习的算法)
因为本文用到了「对比学习」,因此在这里进行了一个简单的介绍。
- 现在有一个 query
q,和 keys 的集合K={k1, k2, ...,} - 有一个
k+,表示和q的对应; - 我们的目标是使得
q和k+更加接近,比起其他的k,也就是K\k+;
下面是一些名词介绍:
q被称为anchor;K被称为targets;k+被称为positive,在这里是同一个obs的不同裁减;K\k+被称为negative,在本文中是不同obs的裁减(一个batch中的不同obs);
为了计算相似度,我们使用 qWk 的方式,结果是一个数字。于是可以定义以下的 loss,称为 InfoNCE loss。这个 loss 也是 label 是 k+ 的 log softmax 的 loss。
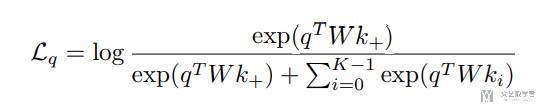
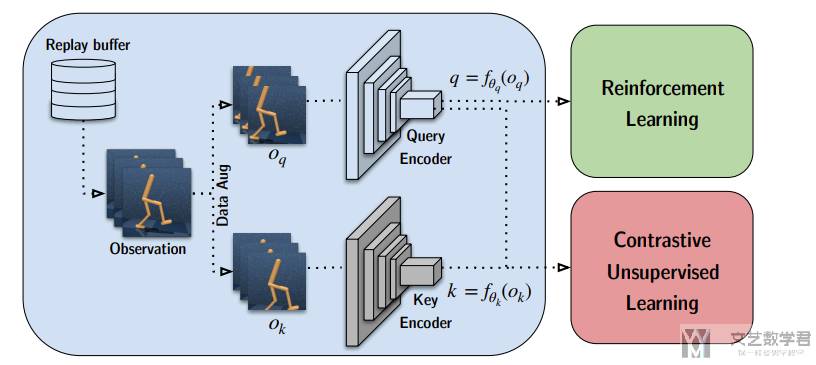
CURL 的整体框架
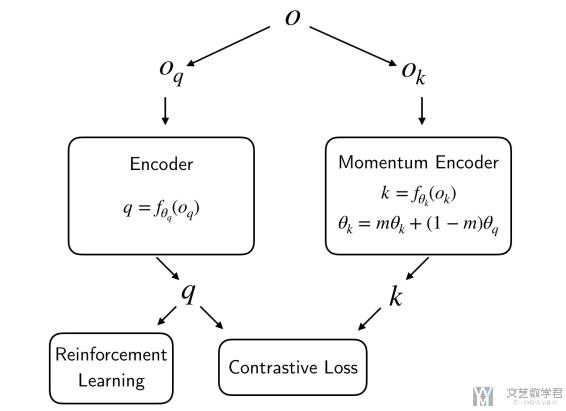
CURL 的整体思想很简单,就是在训练的时候加上对比学习的 loss:CURL minimally modifies a base RL algorithm by training the contrastive objective as an auxiliary loss during the batch update. 整个框架结构如下图所示:
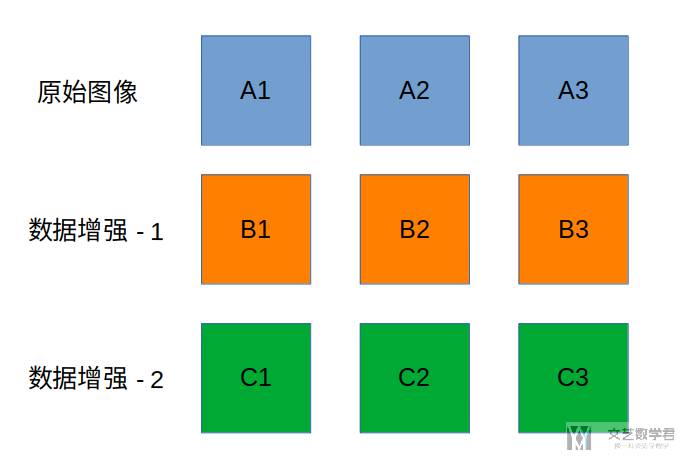
对于如何生成上面的 positive 和 negative 的数据,核心想法就是下面这句话:The anchor and positive observations are two different augmentations of the same image while negatives come from other images.
直观的理解一下,如下图所是,现在假设 mini-batch 中有三张图片,分别是 A1,A2,A3。我们分别对这三张图片进行两次数据增强,于是可以分别获得 A1,A2,A3 和 A1,A2,A3。于是 A1 和 B1 就是应该相似度较高,A1 和 B2 和 B3。
关于相似度的计算,我们使用下面的式子进行计算,其中 W 是可以学习的参数:
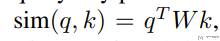
于是我们可以得到下面的相似度矩阵,其中对角线上都是相似度应该比较高的值,所以我们可以直接当作分类问题来计算 loss:
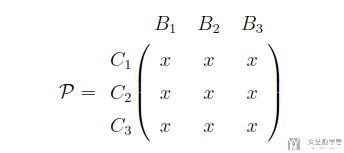
下面是 Pytorch 的伪代码,其中 x_q,x_k 对应上面两个数据增强的结果:

还有一个值得注意的就是这里 Encoder 的更新使用了 Momentum Encoder,也就是每次 Encoder K 更新的时候会和 Encoder Q 做一些融合,如下图所示:
上面介绍了 CURL 的主要思想,下面简单来看一下实验结果(这里就简单说一下实验,完整的实验内容请查看原始的论文)。作者在实验中,在 DMControl 环境下使用 SAC 算法;在 Atari 环境中使用 Rainbow DQN 算法。
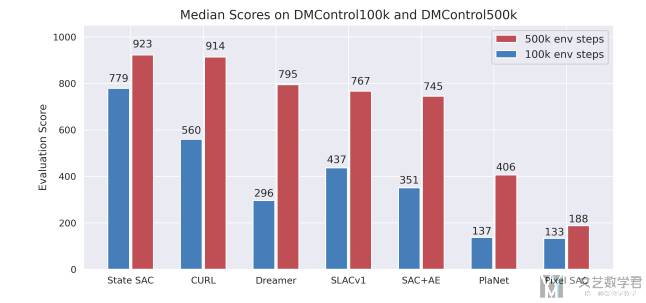
在 DMControl 环境下的结果如下图所示,可以看到:
- 在
100k的时候,比其他算法效果更好,也就是数据利用效率更高; - 在
500k的时候,同样优于其他算法,同时结果可以和state-based的结果相当;
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK