

Isolating Noisy Neighbors in Distributed Systems: The Power of Shuffle-Sharding
source link: https://dzone.com/articles/reducing-blast-radius-by-using-connection-pick-str
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Isolating Noisy Neighbors in Distributed Systems: The Power of Shuffle-Sharding
Shuffle-sharding evenly distributes limited resources among clients or tasks to prevent performance issues. Learn how it works and whether it's right for your service.
Effective resource management is essential to ensure that no single client or task monopolizes resources and causes performance issues for others. Shuffle-sharding is a valuable technique to achieve this. By dividing resources into equal segments and periodically shuffling them, shuffle-sharding can distribute resources evenly and prevent any client or task from relying on a specific segment for too long. This technique is especially useful in scenarios with a risk of bad actors or misbehaving clients or tasks. In this article, we'll explore shuffle-sharding in-depth, discussing how it balances resources and improves overall system performance.
Model
Before implementing shuffle-sharding, it's important to understand its key dimensions, parameters, trade-offs, and potential outcomes. Building a model and simulating different scenarios can help you develop a deeper understanding of how shuffle-sharding works and how it may impact your system's performance and availability. That's why we'll explore shuffle-sharding in more detail, using a Colab notebook as our playground. We'll discuss its benefits, limitations, and the factors to consider before implementing it. By the end of this post, you'll have a better idea of what shuffle-sharding can and can't do and whether it's a suitable technique for your specific use case.
In practical applications, shuffle-sharding is often used to distribute available resources evenly among different queries or tasks. This can involve mapping different clients or connections to subsets of nodes or containers or assigning specific cores to different query types (or 'queries' to be short).
In our simulation, we linked queries to CPU cores. The goal is to ensure that the available CPU resources are shared fairly among all queries, preventing any query from taking over the resources and negatively impacting the performance of others.
To achieve this, each query is limited to only 25% of the available cores, and no two queries have more than one core in common. This helps to minimize overlap between queries and prevent any one query from consuming more than its fair share of resources.
Here is a visualization of how the cores (columns) are allocated to each query type (rows) and how overlap between them is minimized (each query has exactly three cores assigned):

The maximum overlap between rows is just one bit (i.e., 33% of the assigned cores), and the average overlap is ~0.5 bits (less than 20% or assigned cores). This means that even if one query type were to take over 100% of the allocated cores, the others would still have enough capacity to run, unlike uniform assignment, where a rogue query could monopolize the whole node CPU.
To evaluate the impact of different factors on the performance of the system, we conducted four simulations, each with different dimensions:
- Uniform query assignment, where any query type can be assigned to any core, vs. shuffle-sharding assignment, where queries are assigned based on shuffle-sharding principles.
- Baseline, where all queries are well-behaved, vs. the presence of a bad query type that takes 100% of the CPU resources and never completes.
Let's take a look at the error rate (which doesn't include the bad query type as it fails in 100% of cases):
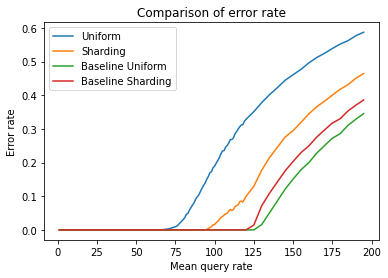
Looking at the error rate plot, we can observe that the Baseline Uniform scenario has a slightly higher saturation point than the Baseline Shuffle-Sharding scenario, reaching around a 5% higher query rate before the system starts to degrade. This is expected as shuffle-sharding partitions the CPU cores into smaller sections, which can reduce the efficiency of the resource allocation when the system is near its full capacity.
However, when comparing the performance of Uniform vs. Shuffle-Sharding in the presence of a noisy neighbor that seizes all the available resources, we see that Shuffle-Sharding outperforms Uniform by approximately 25%. This demonstrates that the benefits of shuffle-sharding in preventing resource taking over and ensuring fair resource allocation outweigh the minor reduction in efficiency under normal operating conditions.
In engineering, trade-offs are a fact of life, and shuffle-sharding is no exception. While it may decrease the saturation point during normal operations, it significantly reduces the risk of outages when things don't go as planned — which is inevitable sooner or later.
System Throughput
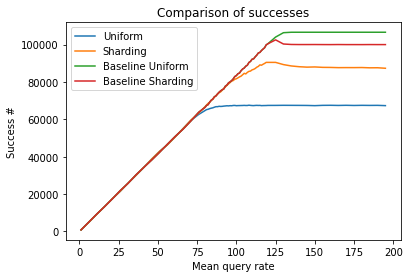
In addition to error rates, another key metric for evaluating the performance of a system is throughput, which measures the number of queries the system can handle depending on the QPS rate. To analyze the system's throughput, we looked at the same data from a different angle.
In the plot below, we can see a slight difference between the Baseline Uniform and Baseline Shuffle-Sharding scenarios, where Uniform slightly outperforms Sharding at low QPS rates. However, the difference becomes much more significant when we introduce a faulty client/task/query that monopolizes all the available resources. In this scenario, Shuffle-Sharding outperforms Uniform by a considerable margin:
Latency
Now let's look at the latency graphs, which show the average, median (p50), and p90 latency of the different scenarios.
In the Uniform scenario, we can see that the latency of all requests approaches the timeout threshold pretty quickly at all levels. This demonstrates that resource monopolization can have a significant impact on the performance of the entire system, even for well-behaved queries:

In the Sharding scenario, we can observe that the system handles the situation much more effectively and keeps the latency of well-behaving queries as if nothing happened until it reaches a saturation point, which is very close to the total system capacity. This is an impressive result, highlighting the benefits of shuffle-sharding in isolating the latency impact of a noisy/misbehaving neighbor.
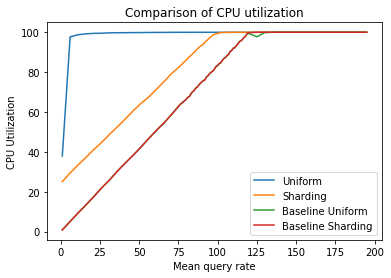
CPU Utilization
At the heart of shuffle-sharding is the idea of distributing resources to prevent the whole ship from sinking, but only allowing a section to become flooded. To illustrate this concept, let's look at the simulated CPU data.
In the Uniform simulation, CPU saturation occurs almost instantly, even with low QPS rates. This highlights how resource monopolization can significantly impact system performance, even under minimal load. However, in the Sharding simulation, the system maintains consistent and reliable performance, even under challenging conditions. These simulation results align with the latency and error graphs we saw earlier — the bad actor was isolated and only impacted 25% of the system's capacity, leaving the remaining 75% available for well-behaved queries.
Closing Thoughts
In conclusion, shuffle-sharding is a valuable technique for balancing limited resources between multiple clients or tasks in distributed systems. Its ability to prevent resource monopolization and ensure fair resource allocation can improve system stability and maintain consistent and reliable performance, even in the presence of faulty clients, tasks, or queries. Additionally, shuffle-sharding can help reduce the blast radius of faults and improve system isolation, highlighting its importance in designing more stable and reliable distributed systems.
Of course, in the event of outages, other measures should be applied, such as rate-limiting the offending client/task or moving it to dedicated capacity to minimize system impact. Effective operational practices are critical to maximize the benefits of shuffle-sharding. For other techniques that can be used in conjunction with shuffle-sharding, check out the links below.
Also, feel free to play around with the simulation and change the parameters such as the number of query types, cores, etc. to get a sense of the model and how different parameters may affect it.
This post continues the theme of improving service performance/availability touched on in previous posts Ensuring Predictable Performance in Distributed Systems, Navigating the Benefits and Risks of Request Hedging for Network Services, and FIFO vs. LIFO: Which Queueing Strategy Is Better for Availability and Latency?.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK