

GPT-4王者加冕!读图做题性能炸天,凭自己就能考上斯坦福
source link: https://tech.sina.com.cn/csj/2023-03-15/doc-imykxazi3575366.shtml
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

GPT-4王者加冕!读图做题性能炸天,凭自己就能考上斯坦福
2023-03-15 09:25:38 创事记 微博 作者: 新智元 我有话说(5人参与)

新智元报道
编辑:编辑部
【新智元导读】Open AI的GPT-4在万众瞩目中闪亮登场,多模态功能太炸裂,简直要闪瞎人类的双眼。李飞飞高徒、斯坦福博士Jim Fan表示,GPT4凭借如此强大的推理能力,已经可以自己考上斯坦福了!
果然,能打败昨天的Open AI的,只有今天的Open AI。
刚刚,Open AI震撼发布了大型多模态模型GPT-4,支持图像和文本的输入,并生成文本结果。
号称史上最先进的AI系统!

GPT-4不仅有了眼睛可以看懂图片,而且在各大考试包括GRE几乎取得了满分成绩,横扫各种benchmark,性能指标爆棚。
Open AI 花了 6 个月的时间使用对抗性测试程序和 ChatGPT 的经验教训对 GPT-4 进行迭代调整 ,从而在真实性、可控性等方面取得了有史以来最好的结果。
大家都还记得,2月初时微软和谷歌鏖战三天,2月8日微软发布ChatGPT版必应时,说法是必应‘基于类ChatGPT技术’。
今天,谜底终于解开了——它背后的大模型,就是GPT-4!
图灵奖三巨头之一Geoffrey Hinton对此赞叹不已,‘毛虫吸取了营养之后,就会化茧为蝶。而人类提取了数十亿个理解的金块,GPT-4,就是人类的蝴蝶。’

顺便提一句,ChatGPT Plus用户现在可以先上手了。
考试几乎满分,性能跃迁炸天
在随意谈话中,GPT-3.5和GPT-4之间的区别是很微妙的。只有当任务的复杂性达到足够的阈值时,差异就出现了,GPT-4比GPT-3.5 更可靠、更有创意,并且能够处理更细微的指令。
为了了解这两种模型之间的差异,Open AI在各种基准测试和一些为人类设计的模拟考试上进行了测试。
GPT-4在各种考试中,有几个测试几乎接近了满分:
-
USABO Semifinal 2020(美国生物奥林匹克竞赛)
-
GRE Writing
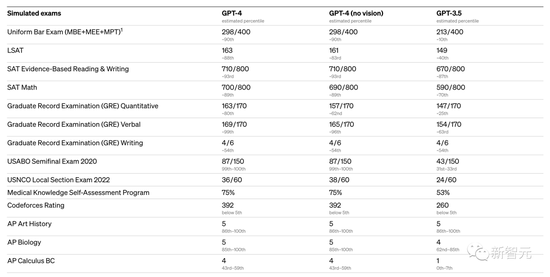
以美国 BAR律师执照统考为例,GPT3.5可以达到 10%水平,GPT4可以达到90%水平。生物奥林匹克竞赛从GPT3.5的31%水平,直接飙升到 99%水平。

此外,Open AI 还在为机器学习模型设计的传统基准上评估了 GPT-4。从实验结果来看,GPT-4 大大优于现有的大型语言模型,以及大多数 SOTA 模型:
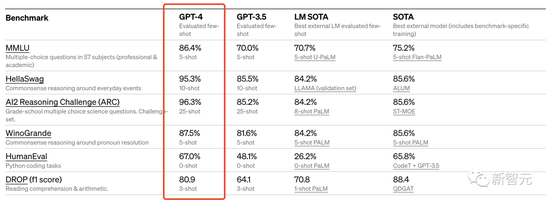
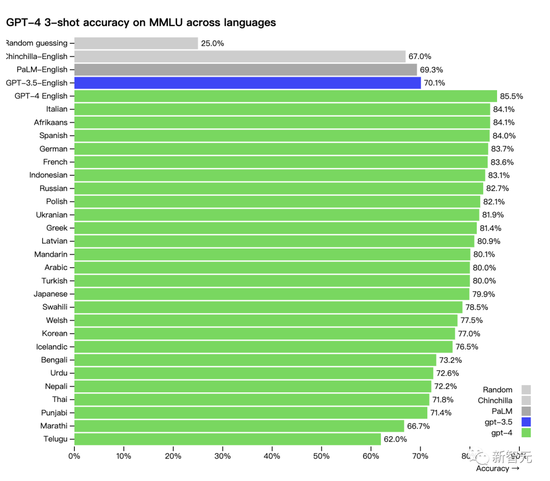
另外,GPT-4在不同语种上的能力表现:中文的准确度大概在 80% 左右,已经要优于GPT-3.5的英文表现了。
许多现有的 ML 基准测试都是用英语编写的。为了初步了解GPT-4其他语言的能力,研究人员使用 Azure翻译将 MMLU 基准(一套涵盖57个主题的14000个多项选择题)翻译成多种语言。
在测试的 26 种语言的 24 种中,GPT-4 优于 GPT-3.5 和其他大语言模型(Chinchilla、PaLM)的英语语言性能:
Open AI表示在内部使用 GPT-4,因此也关注大型语言模型在内容生成、销售和编程等方面的应用效果。另外,内部人员还使用它来帮助人类评估人工智能输出。
对此,李飞飞高徒、英伟达AI科学家Jim Fan点评道:‘GPT-4最强的其实就是推理能力。它在GRE、SAT、法学院考试上的得分,几乎和人类考生没有区别。也就是说,GPT-4可以全靠自己考进斯坦福了。’
(Jim Fan自己就是斯坦福毕业的!)
网友:完了,GPT-4一发布,就不需要我们人类了……

读图做题小case,甚至比网友还懂梗
GPT-4此次升级的亮点,当然就是多模态。
GPT-4不仅能分析汇总图文图标,甚至还能读懂梗图,解释梗在哪里,为什么好笑。从这个意义上说,它甚至能秒杀许多人类。
Open AI称,GPT-4比以往模型都更具创造力和协作性。它可以生成、编辑和迭代用户进行创意和技术写作任务,例如创作歌曲、编写剧本或学习用户的写作风格。
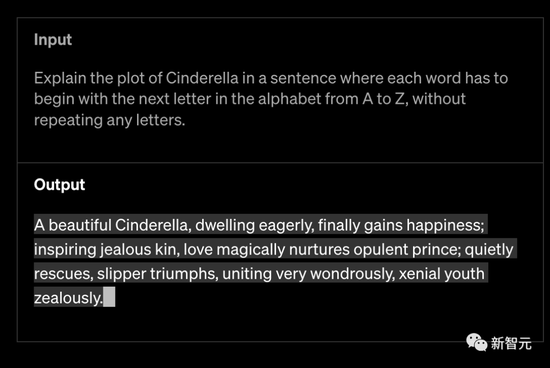
GPT-4可以将图像作为输入,并生成标题、分类和分析。比如给它一张食材图,问它用这些食材能做什么。

另外,GPT-4能够处理超过25,000字的文本,允许用长形式的内容创建、扩展会话、文档搜索和分析。
GPT-4在其先进的推理能力方面超过了ChatGPT。如下:

比如,给它看一张奇怪的梗图,然后问图中搞笑在哪里。
GPT-4拿到之后,会先分析一波图片的内容,然后给出答案。
比如,逐图分析下面这个。

GPT-4立马反应过来:图里的这个‘Lighting充电线’,看起来就是个又大又过气的VGA接口,插在这个又小又现代的智能手机上,反差强烈。

再给出这么一个梗图,问问GPT-4梗在哪里?

它流利地回答说:这个梗搞笑的地方在于‘图文不符’。
文字明明说是从太空拍摄的地球照片,然而,图里实际上只是一堆排列起来像地图的鸡块。

GPT-4还能看懂漫画:为什么要给神经网络加层数?
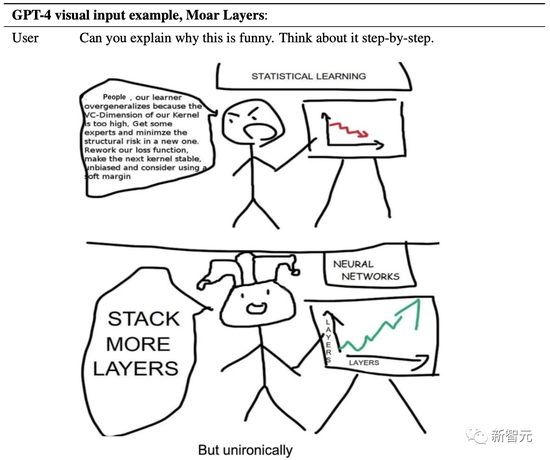
它一针见血地点出,这副漫画讽刺了统计学习和神经网络在提高模型性能方法上的差异。

格鲁吉亚和西亚的平均每日肉类消费量总和是多少?在给出答案前,请提供循序渐进的推理。
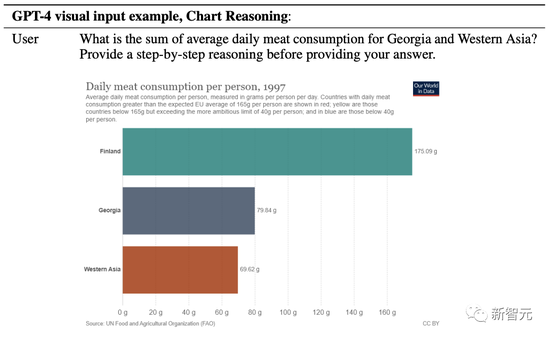
果然,GPT-4清楚地列出了自己的解题步骤——
1. 确定格鲁吉亚的平均每日肉类消费量。
2. 确定西亚的平均每日肉类消费量。
3. 添加步骤1和2中的值。

要求GPT-4解出巴黎综合理工的一道物理题,测辐射热计的辐射检测原理。值得注意的是,这还是一道法语题。

GPT-4开始解题:要回答问题 I.1.a,我们需要每个点的温度 T(x),用导电棒的横坐标x表示。
随后解题过程全程高能。

你以为这就是GPT-4能力的全部?
老板Greg Brockman直接上线进行了演示,通过这个视频你可以很直观的感受到 GPT-4的能力。
最惊艳的是,GPT-4对代码的超强的理解能力,帮你生成代码。
Greg直接在纸上画了一个潦草的示意图,拍个照,发给 GPT说,给我按照这个布局写网页代码,就写出来了。
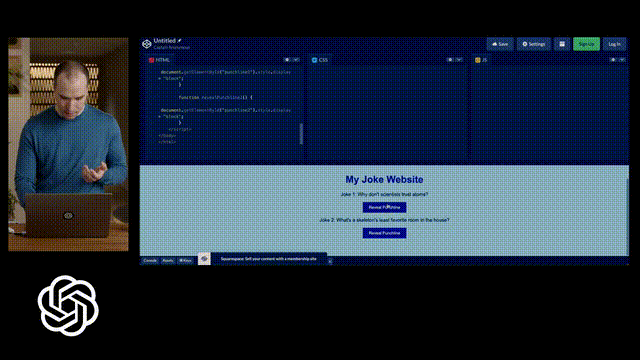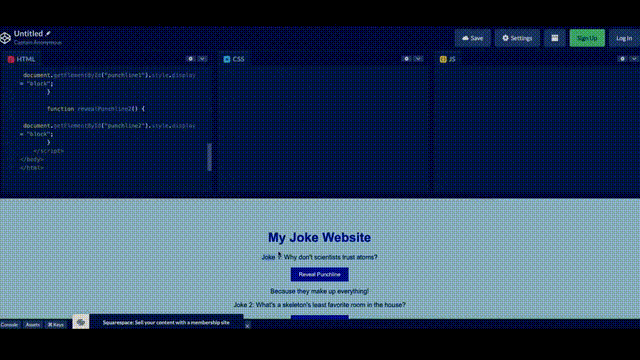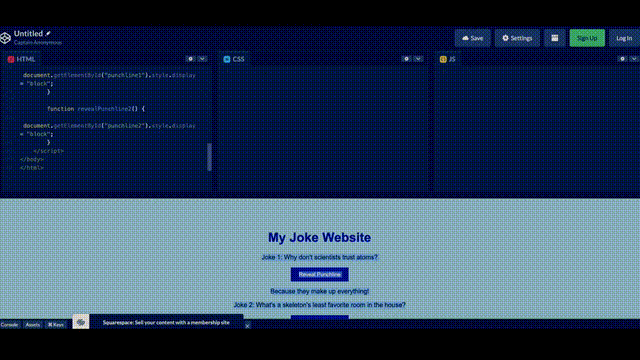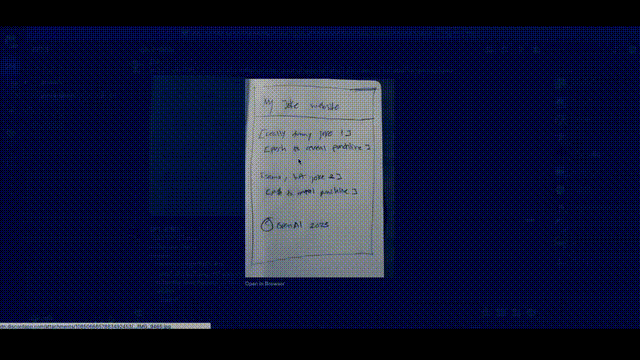
另外,如果运行出错了把错误信息,甚至错误信息截图,扔给GPT-4都能帮你给出相应的提示。
网友直呼:GPT-4发布会,手把手教你怎么取代程序员。

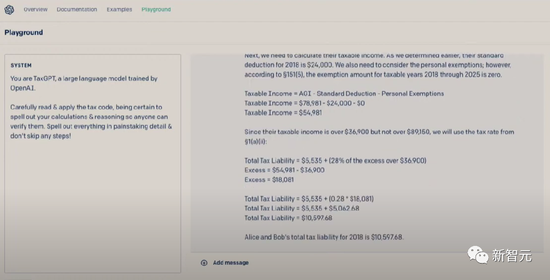
顺便提一句,用GPT-4还可以进行报税 。要知道,每年美国人要花好多时间金钱在报税上面。
和以前的GPT模型一样,GPT-4基础模型的训练使用的是公开的互联网数据以及Open AI授权的数据,目的是为了预测文档中的下一个词。
这些数据是一个基于互联网的语料库,其中包括对数学问题的正确/错误的解决方案,薄弱/强大的推理,自相矛盾/一致的声明,足以代表了大量的意识形态和想法。
当用户给出提示进行提问时,基础模型可以做出各种各样的反应,然而答案可能与用户的意图相差甚远。
因此,为了使其与用户的意图保持一致,Open AI使用基于人类反馈的强化学习(RLHF)对模型的行为进行了微调。
不过,模型的能力似乎主要来自于预训练过程,RLHF并不能提高考试成绩(如果不主动进行强化,它实际上会降低考试成绩)。
基础模型需要提示工程,才能知道它应该回答问题,所以说,对模型的引导主要来自于训练后的过程。
GPT-4模型的一大重点是建立了一个可预测扩展的深度学习栈。因为对于像GPT-4这样的大型训练,进行广泛的特定模型调整是不可行的。
因此,Open AI团队开发了基础设施和优化,在多种规模下都有可预测的行为。
为了验证这种可扩展性,研究人员提前准确地预测了GPT-4在内部代码库(不属于训练集)上的最终损失,方法是通过使用相同的方法训练的模型进行推断,但使用的计算量为1/10000。
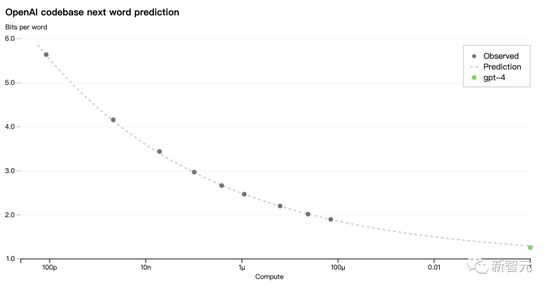
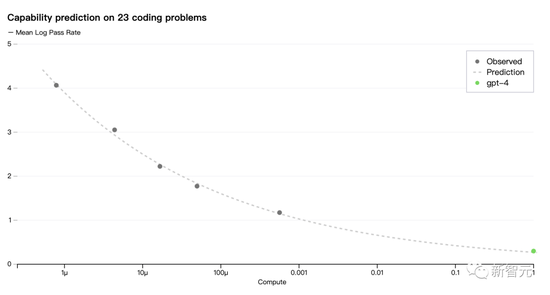
现在,Open AI 可以准确地预测在训练过程中优化的指标损失。例如从计算量为1/1000的模型中推断并成功地预测了HumanEval数据集的一个子集的通过率:
还有些能力仍然难以预测。比如,Inverse Scaling竞赛旨在找到一个随着模型计算量的增加而变得更糟的指标,而 hindsight neglect任务是获胜者之一。但是GPT-4 扭转了这一趋势:
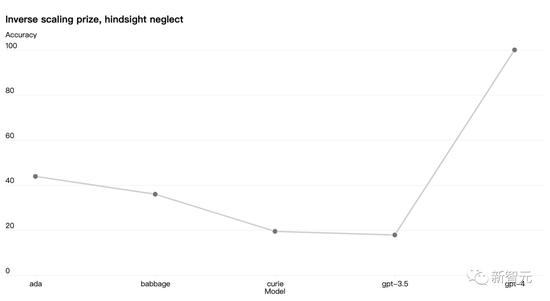
Open AI认为能够准确预测未来的机器学习能力对于技术安全来说至关重要,但它并没有得到足够的重视。
而现在,Open AI正在投入更多精力开发相关方法,并呼吁业界共同努力。
就在GPT-4发布的同时,Open AI还公开了GPT-4这份组织架构及人员清单。

上下滑动查看全部
北大陈宝权教授称,
再好看的电影,最后的演职员名单也不会有人从头看到尾。Open AI的这台戏连这个也不走寻常路。毫无疑问这将是一份不仅最被人阅读,也被人仔细研究的‘演职员’(贡献者) 名单,而最大的看头,是详细的贡献分类,几乎就是一个粗略的部门设置架构了。
这个很‘大胆’的公开其实意义挺深远的,体现了Open AI背后的核心理念,也一定程度预示了未来进步的走向。

(声明:本文仅代表作者观点,不代表新浪网立场。)
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK