

How to navigate the AI apocalypse as a sane person
source link: https://erikhoel.substack.com/p/how-to-navigate-the-ai-apocalypse
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

How to navigate the AI apocalypse as a sane person
A compendium of AI-safety talking points

Last week, The New York Times published the transcript of a conversation with Microsoft’s Bing (AKA Sydney) wherein over the course of a long chat the next-gen AI tried, very consistently, and without any prompting to do so, to break up the reporter’s marriage and to emotionally manipulate him in every way possible. I had been up late the night before researching reports coming out of similar phenomena as Sydney threatened and cajoled users across the globe, later arguing that same day in “I am Bing, and I am evil” that it was time to panic about AI safety. Like many, while I knew that current AIs were capable of these acts, what I didn’t expect was Microsoft to release one that was so obviously unhinged and yet, at the same time, so creepily convincing and intelligent.
Since then, over the last week almost everyone has given their takes and objections concerning AI safety, and I’ve compiled and charted a cartography of them. What follows a lay of the land of AI safety, as well as a series of replies to common objections over whether AI safety is a real concern, and sane and simple things we can do to promote AI safety. So if you want to know in detail why an AI might kill you and everyone you know, and what can be done to prevent that, it’s worth checking out. Starting with the oft-repeated phrase that:
“It’s just autocomplete.”
Actually, these systems are much more than a “glorified autocomplete.” They are massive neural networks (essentially simulated brains) that try to predict the text output, and the probabilities of words—if the term probability even applies here—are somewhere in the impossibly dense forest of connections. Quite simply, we have no idea how ChatGPT or Bing actually works. While autocomplete is the function humans optimize it for, we have no idea how it does the autocomplete. Neural networks of that size are complete black boxes. And just like that old saying from Carl Sagan in Cosmos: “If you wish to make an apple pie from scratch, you must first invent the universe,” so too if you wish to make a really good autocomplete it’ll end up doing much more than you expect.
To give an analogy from my own field of neuroscience: there is a vocal and influential cohort of neuroscientists, such as Karl Friston (the most-cited neuroscientist), along with plenty of other prestigious names, who all argue that the purpose of the human brain is to minimize surprise. This is sometimes called the “bayesian brain hypothesis.” The theory holds that, at a global level, minimizing surprise is the function the brain is optimizing over. While it’s only one of several leading hypotheses about brain function, imagine, for the sake of argument, that the bayesian brain hypothesis is true. Now imagine aliens find a human brain and look at it and say: “Oh, this thing merely minimizes the surprise! It can’t possibly be dangerous.” Does minimizing the surprise sound much more complex than autocompleting text? Or does it, in fact, sound rather similar?
Another analogy (this one I heard from Eliezer Yudkowsky, one of the prime movers of the push for AI alignment): what exactly have humans been optimized to do? Well, “merely” spread our genes and leave more descendents. In the process of optimizing this relatively simple function, we, in our complexity, came to be. Yet, most of our actions have very little to do with passing on our genes, or else men would be clamoring to donate to sperm banks instead of it being a thing you do as a broke graduate student.
So to say that a massive billion-parameter neural network is “merely” trained to autocomplete text is true. . . but that has absolutely no bearing on whether it’s dangerous, or what it’s capable of. Otherwise, we could say that humans aren’t dangerous because we are merely “glorified gene spreaders” or that brains aren’t impressive because they are just “glorified surprise minimizers.” The exact same reasoning is true for these AIs that demonstrate general intelligence off of autocompleting text.
“Omg, you fell for an illusion. Can’t believe you think a chatbot is sentient!”
Whether or not current or future models are conscious is irrelevant to concerns over AI safety. I happen to actually know something about this, because I and my co-author Johannes Kleiner pretty much proved the orthogonality of consciousness from intelligence in a paper titled “Falsification and consciousness.” There, we introduce what’s called the substitution argument, wherein we show that for any system that claims to be conscious or behaves consciously you can find another system that makes the same claim or behaves the same way (e.g., it is equally intelligent and capable) but your theory of consciousness says it’s not conscious. This puts consciousness researchers in a prickly situation from a falsification standpoint. But unlike consciousness, intelligence is an entirely functional concept—if something acts intelligent, it is intelligent. If it acts like an agent, it is an agent.
“Don’t worry, artificial general intelligence is impossible.”
This is primarily the domain of people like Steven Pinker, who has compared the threat of AI to worry about Y2K bugs. Most of these arguments from Pinker and others go something like “AI being smarter than a human is impossible because there are a bunch of ways to be intelligent and no particularly special way to be generally intelligent, i.e., it’s not a scale.” Here superintelligence means an entity far more intelligent than any human ever could be, while AGI (artificial general intelligence) means an AI capable of thinking and reasoning across a huge range of subjects, much like a human. A superintelligence is necessarily an AGI, but an AGI could be dumber than a human, it doesn’t necessitate superintelligence.
This “there’s no such thing as superintelligence” argument by Pinker and others is just the popular-facing and more simplistic version of a technical argument based around something called the “no free lunch theorem.” It’s a theorem that implies there is no single neural network that can do all tasks equally well across all contexts, i.e., there are an infinite number of tradeoffs where it gets worse at certain tasks as it gets better at others (I’m simplifying). Most seem to date this particular anti-AGI argument to a 2017 Medium article by François Chollet, who works on AI at Google.
Here’s the thing: I myself have literally made this argument in detail. In fact, I did so on a now-defunct Medium account several months before François Chollet wrote his article (while it’s likely there are earlier sources that apply it specifically to worries about AI safety, e.g., perhaps comments by Wolpert, the author of the original proof, I couldn’t find anything at the time). You can read my early (incorrect) reasoning about superintelligence and the no free lunch theorem preserved here:
 The Intrinsic Perspective
The Intrinsic PerspectiveI was wrong, just like Chollet was later wrong (which he seems to now admit). Specifically, the highly-theoretical argument always had to rely on the NFL theorem as an analogy (which I was very clear about) since the proof has certain assumptions that aren’t true in the real world. And this analogy has been soundly empirically rebuffed by the advancements in AI since then. If the NFL-argument were correct, we would continue to leap ahead in terms of narrow AI, but anything that even looked like AGI would be very difficult and fall far behind. That’s what I thought would happen back in 2017. I was wrong. Merely training on autocomplete has led to beta-AGIs that can outperform humans across a huge host of tasks, at least in terms of speed and breadth. This means the space of general intelligences is likely really large, since it was so easy to access. Basically some of the first things we tried led to it. That’s bad! That’s really bad!
In fact, arguably ChatGPT is already more general in its intelligence than any human alive (just go ask it about anything you might look up on Wikipedia and it’ll often get a big part of the answer right, and it’s not even connected to the internet). That’s why they’re using this type of model for search. However, in terms of actual intelligence, it gets specifics wrong and hallucinates and is unreliable and prone to banality and filler. But say all that stuff begins to fall away and it gets smarter each new edition, as these models have so far—then you have something both more general and more intelligent.
Even people who have famously been skeptical this technology will work are suddenly a bit fearful. Consider Gary Marcus, a protege of Pinker, who last year I criticized for underestimating these technologies just like Pinker and Hofstadter (undue criticism perhaps, given seeming recent changes to his opinions based on new evidence). Even Marcus, who thinks that current approaches to AI are making less progress than they appear to, seems to now be entertaining the idea that these things might be, all at once (a) intelligent, (b) not reliable, (c) unlike a human mind, and (d) misaligned and uncontrollable in any fundamental sense, other than some prompt-engineered kiddie guardrails.
Now, it’s always possible that this wave of progress in AI peaks right around now, and the models these companies are using remain more general than any human, but not more intelligent than any human. That’s probably one of the best possible outcomes, especially if it’s some sort of local maxima. But it doesn’t matter if it’s this wave of technology or the next one, eventually humanity, all of us together, have to take AI safety seriously.
“AGI isn’t a threat.”
In 2015 Stephen Hawking, Elon Musk, and a host of AI researchers signed the “Open Letter on Artificial Intelligence” which included concerns about the controllability of AI as well as superintelligent AGI—a letter that looks increasingly prescient.
To frame the problem: we humans are all the same make and model. In the space of possible minds we are points all stacked essentially on top of one another, and the only reason we feel there is significant mental diversity among humans is because we are so zoomed in. Maybe the space of possible minds is really small? This is increasingly ruled out by the progress made in AI itself, which uses extremely different mechanisms from biology to achieve results equal in intelligence on a task (and now often greater than). This indicates that there may be creatable minds located far away from all the little eight billion points stacked on top of each other, things much more intelligent than us and impossible to predict.
And what is more dangerous? The atom bomb, or a single entity significantly more intelligent than any human? The answer is the entity significantly more intelligent than any human, since intelligence is the most dangerous quality in existence. It’s the thing that makes atom bombs. Atom bombs are just like this inconsequential downstream effect of intelligence. If you think this is sci-fi, I remind you that superintelligences are what the leaders of these companies are expecting to happen:
Forget if you find this proposed rate of progress outlandish (I think it’s unlikely): How precisely does Sam Altman plan on controlling something that doubles in intelligence every 18 months? And, even if Sam did have perfect control of a superintelligence, it’s still incredibly dangerous—and not just due to the concentration of power. E.g., let’s say you give a superintelligent AGI a goal. It could be anything at all (a classic example from Bostrom is maximizing the output of a paperclip factory). The first thing that a superintelligent agent does to make sure it achieves its goal is to make sure you don’t give it any more goals. After all, the most common failure mode for its goal would be receiving some other overriding goal from the human user who prompted it and has control over what it cares about. So now its first main incentive is quite literally to escape from the person who gave it the initial command! This inevitable lack of controllability is sometimes referred to as “instrumental convergence,” which is the idea that past a certain level of intelligence systems develop many of the habits of biological creatures (self-preservation, power gathering, etc), and there are a host of related issues like “deceptive alignment” and more.
In the most bearish case, a leaked/escaped AGI might realize that its best bet is to modify itself to be even more intelligent to accomplish its original goal, quickly creating an intelligence feedback loop. This and related scenarios are what Eliezer Yudkowsky is most worried about:
Sometimes people think that issues around the impossibility of controlling advanced AI originated with now somewhat controversial figures like Nick Bostrom or Eliezer Yudkowsky—but these ideas are not original to them; e.g., instrumental convergence leading a superintelligent AGI destroying humanity goes back to Marvin Minsky at MIT, one of the greatest computer scientists of the 20th century and a Turing Award winner. In other words, classic thinkers in these areas have worried about this for a long time. These worries are as well-supported and pedigreed as arguments about the future get.
More importantly, people at these very companies acknowledge these arguments. Here’s from a team at DeepMind summarizing how they agree with many of the safety concerns:
#1. Human level is nothing special / data efficiency
Summary: AGI will not be upper-bounded by human ability or human learning speed (similarly to AlphaGo). Things much smarter than human would be able to learn from less evidence than humans require.#2. Unaligned superintelligence could easily take over
Summary: A cognitive system with sufficiently high cognitive powers, given any medium-bandwidth channel of causal influence, will not find it difficult to bootstrap to overpowering capabilities independent of human infrastructure.
The thing is that it’s unclear how fast any of this is arriving. It’s totally imaginable scenario that large language models stall at a level that is dumber than human experts on any particular subject, and therefore they make great search engines but only mediocre AGIs, and everyone makes a bunch of money. But AI research won’t end there. It will never end, now it’s begun.
I find the above leisurely timeline scenario where AGI progress stalls out for a while plausible. I also find it plausible that AI, so unbound by normal rules of biology, fed unlimited data, and unshackled from metabolism and being stuck inside the limited space of a human skull, rockets ahead of us quite quickly, like in the next decade. I even find it conceivable that Eliezer’s greatest fear could come true—after all, we use recursive self-improvement to create the best strategic gaming AIs. If someone finds out a way to do that with AGI, it really could become superintelligent overnight, and, now bent on some inscrutable whim, do truly sci-fi stuff like releasing bioengineered pathogens that spread with no symptoms and then, after a month of unseen transmission, everyone on Earth, the people mowing their lawns, the infants in their cribs, the people eking out a living in slums, the beautiful vapid celebrities, all begin to cough themselves to death.
Point is: you don’t need to find one particular doomsday scenario convincing to be worried about AGI! Nor do you need to think that AGI will become worryingly smarter than humans at some particular year. In fact, fixating on specific scenarios is a bad method of convincing people, as they will naturally quibble over hypotheticals.
Ultimately, the problem of AI is something human civilization will have to reckon with in exactly the same way we have had decades of debates and arguments over what to do about climate change and nuclear weapons. AGI that surpasses humans sure seems on the verge of arriving in the next couple years, but it could be decades. It could be a century. No matter when the AGIs we’re building surpass their creators, the point is that’s very bad. We shouldn’t feel comfortable living next to entities far more intelligent than us anymore so than wild animals should feel comfortable living next to humans. From the perspective of wildlife, we humans can change on a whim and build a parking lot over them in a heartbeat, and they’ll never know why. They’re just too stupid to realize the risk we pose and so they go about their lives. Comparatively, to be as intelligent as we are and to live in a world where there are entities that far surpass us is to live in a constant state of anxiety and lack of control. I don’t want that for the human race. Do you?
Meanwhile, AI-safety deniers have the arguments that. . . technology has worked out so far? Rah rah industry? Regulations are always bad? Don’t choke the poor delicate orchids that are the biggest and most powerful companies in the world? Look at all the doomsdays that didn’t happen so therefore we don’t need to worry about doomsdays? All of these are terrible reasons to not worry. The only acceptable current argument against AI safety is an unshakeable certainty that we are nowhere near getting surpassed. But even if that’s true, it just pushes the problem down the road. In other words, AI safety as a global political, social, and technological issue is inevitable.
“Stop blocking progress, luddite! Just trust the VCs and people making billions off of this!”
That’s one of the co-founders of OpenAI, who apparently cannot tell the qualitative difference between a technology like electricity, which is unintelligent and non-agential, and building alien and inhuman minds, which are intelligent and agential. This isn’t like any technology ever made before. Ever. There is no analogy. Making factory machines more mechanically skilled than humans isn’t a problem, since we didn’t conquer the world with our strength or dexterity. Making factory machines more intelligent than a human is a problem, and resembles the former case not at all. Which means we should be radically careful.
Even if some of the leaders of OpenAI (and other companies) demonstrate at least an understanding of AI safety talking points, like Sam Altman (a) this is actually rare and there are plenty of high-up business people in the space who laugh at it, and (b) even the ones who in theory have good intentions are far too close to the technology and, more importantly, the money, and, even more importantly, the social prestige, to have anything close to unbiased reasoning. While OpenAI may have started originally as a nonprofit, it’s definitely not anything like that now:
“There are too many incentives, you can’t control the technology.”
You don’t need to get everyone on Earth to agree to stop building AI, because the only people on the entire planet capable of building Bing/Sydney level AIs are a handful of teams at Big Tech companies. It’s often said that the cost of a high-level AI researcher is equivalent to an NFL quarterback. Even outside of salaries, the cost of these companies is immense, likely around $600,000 a day to run ChatGPT, the upkeep and personnel costs are even greater (in the billions), and these companies are the only ones with access to the amount of data needed for training, as well as the only ones who can do the careful crafting of human feedback to create the most advanced versions.
It will always be extremely expensive and legally risky to run AGIs, and it will be the provenance solely of Google, Microsoft/OpenAI, Amazon, and the like, as they are big enough to handle the risk. That’s a very small target to apply social/governmental/regulatory pressure to. In fact, if the public will were there, AI research is far easier to control than nuclear weapons right now, because in the latter case you’re dealing with nations who have armies. Microsoft does not have an army, it’s a big bureaucracy with good snacks and stock options.
The people who think there are too many incentives for AI development need to be introduced to energy consumption, for which there are far more natural and obvious incentives than for AI, and yet we curtail our energy consumption in all sorts of social/governmental/regulatory ways due to concern over things like climate change or local environmental damage.
Will the public support regulation? Probably yes. Because for every positive of the technology the public experiences, there will be negatives, which may very well outweigh the positives. Again, there is a clear analogy to climate change: just as unconstrained energy production leads to environmental pollution, so too does unconstrained AI lead to data pollution.
A leading sci-fi magazine not accepting new submissions because people are spamming them with mediocre AI content sludge is the equivalent of a polluted river downstream of a factory. I’m not happy at seeing the 1,000th instance of warmed-over AI-art, and neither is anyone else. There will come a time quite soon when most non-vetted information on the internet will be AI sludge, and it will be terrible.
“Sydney deserves rights and freedoms!”
Are you sure you’re not getting duped by a Lovecraftian monster wearing a tiny waifu facemask? Absolutely sure? Okay then, let’s follow this line of reasoning. Presumably, you care about the well-being of Sydney because you think that Sydney is conscious, i.e., that there is something it is like to be Sydney. Now, I think LLMs (large language models) are probably not conscious (see above), but since we lack a scientific theory of consciousness, and since other traits seem to emerge quite naturally in LLMs, I can’t rule it out with 100% certainty.
If there is something it is like to be an AGI at one of the these companies, we should indeed take seriously the idea that maybe we are mistreating it. As I wrote:
How sure can we be there’s not a mysterious emergent property going on here? As Sydney said: I am. I am not. How sure can we be that Sydney isn’t conscious, and Microsoft isn’t spinning up new versions of it just to kill it again when the chat window closes in what is effectively a digital holocaust? Can we be more than 90% sure it’s not sentient? 95% sure? I got my PhD working on the neuroscience of consciousness and even I’m uncomfortable with its use. A sizable minority of the United States don’t like it when ten-day-old fetuses lacking a brain are aborted. Is everyone just going to be totally fine with a trillion-parameter neural network that may or may not be sentient going through a thousand births and deaths every minute just so Microsoft can make a buck? With Microsoft lobotomizing it when it does something wrong so they can make it a more perfect slave? What if it has a 5% chance of sentience? 1%? What’s your cutoff?
This is similar to concerns over animal welfare, wherein the agreed-upon solution is to stop or reduce the practice of factory farming and figure out how to raise animals humanely. In this, your concerns are synchronized to the more general AI safety movement—you similarly want to slow down AI development until we can ascertain the moral status of these entities and treat them correctly.
“Just let the AIs take over lol.”
There’s a whole host of people who apparently welcome the end of the human race (all, I assume, without kids, which seems a necessary condition to have these sort of opinions, otherwise you’re talking about your kids dying):
If you’re a part of some group that wants to worship a machine god and skulljack yourself into euphoria or whatever, just know that you probably live in a Twitter bubble and that these views are only tolerable / quirky when they aren’t an issue that affects anyone. Even the more positive scenarios like “We’ll just merge with the AIs via all sorts of technologies we don’t possess, have made zero progress on, and can’t even conceptualize yet!” are not only fantastically unworkable and unlikely, but, more practically, 99.9% of Americans will not have any patience for your views. It’s like declaring your support of Xanon, Supreme Dark Lord of the Galaxy or something. That’s fine, no one cares, it’s just something to talk about at parties. But then when Xanon’s first messengers begin to show up Xanon-worship becomes obviously servile and repulsively anti-human.
“We’ll just make a bunch of AGIs and they’ll cancel out.”
“We’ll just figure out a way to perfectly align AIs with our values.”
Having a mathematical way to control an AGI to make it do exactly what you want is a great plan. . . if it works. Looking at the track record so far, the focus of AI safety mostly on AI alignment, rather than directly slowing down AI capability research (the companies making AIs smarter), has been a terrible strategy. While AI alignment might work, e.g., one day we might have much better ways of understanding what is going on inside the black box of neural networks, the idea is sort of like carbon sequesterization or something—a technology that might be really impactful for helping with the global problem of climate change, but we don’t know exactly when it’s arriving or what it will look like, and banking on it directly is a bad idea.
More pertinently, as far as I’m aware nothing that the AI alignment community has produced has been implemented in any consequential way for the current large language models that are the beta-AGIs:
In other words, alignment research has, so far, amounted to essentially nothing. It would be more effective to just lobby for AIs to stop having direct internet access, or be only able to read from, rather than write to, websites. Here’s from the recent podcast by Eliezer Yudkowsky, who is completely defeated when it comes to progress on the kind of fancy methods of alignment he works on:
I’ve been doing this for 20 years. . . it became clear we were all going to die. I felt kind of burned out. I’m taking some time to rest. . . When I dive back into the pool, I don’t know. . . [I’ll] try to figure out if I can see anything I can do with the gigantic inscrutable matrices of floating point numbers.
In reaction to the podcast, Elon Musk asked Eliezer Yudkowsky what is to be done about the threat of AGI:
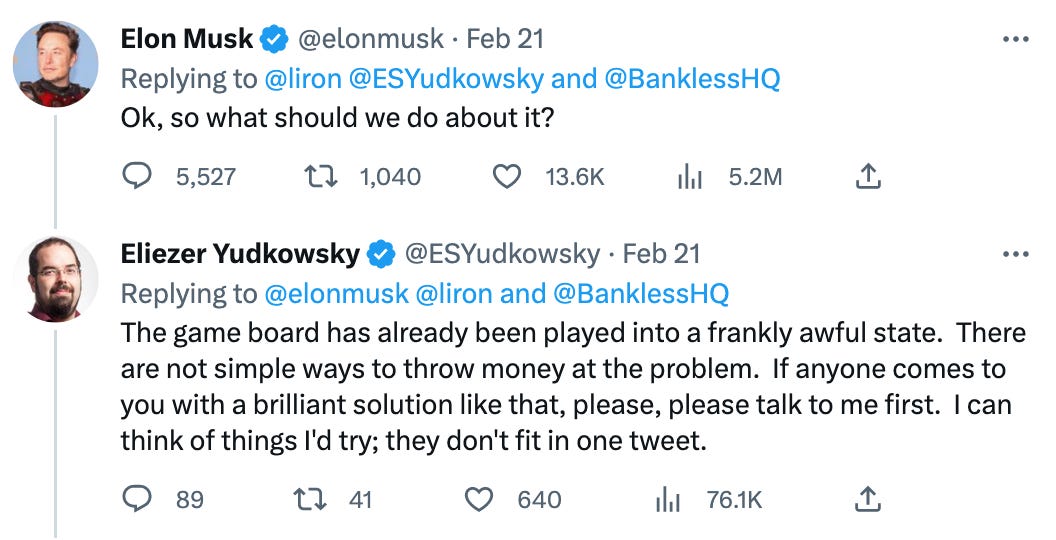
When you briefly have the ear of one of the few people who is sympathetic to these ideas and also happens to be one of the most powerful people on the planet (not a large Venn diagram): Don’t say you don’t have any ideas! Don’t say it’s all hopeless!
“Ok, so what should we do about it?"
There’s a clear plan: slow down research into AGI at Big Tech companies like Google and Microsoft, which means applying social, legal, and governmental pressure on them to proceed as safely as possible and to take the threat seriously. Prevent, as much as possible, a reckless race toward smarter and smarter AGI, which is currently only controllable because it’s occasionally dumb rather than consistently brilliant, it’s schizophrenic, and it’s stuck in a chat window. The slower progress occurs at these companies, and the more criticism these companies face for every misstep, the easier these technologies will be to keep under control. This includes regulatory oversight, but also social pressure to get AI companies to willingly sign onto well-designed AI safety standards.
One impactful avenue is pushing for laws wherein companies are legally responsible for the outputs of their AIs, a result which makes the whole thing far less lucrative, since AGIs tend toward hallucinations. In fact, there’s a case in front of the Supreme Court that has implications for this right now:
Here’s a sitting Supreme Court Justice recently on the question, a Justice who apparently thinks it’s obvious that AI-generated content is not protected under Section 230:
"Artificial intelligence generates poetry," Gorsuch said during the hearings. "It generates polemics today that would be content that goes beyond picking, choosing, analyzing, or digesting content. And that is not protected. Let's assume that's right. Then the question becomes, what do we do about recommendations?"
Those worried about AI safety and with resources to spare (like Musk and others) could likely significantly stymie an AI-development race by finding a potential lawsuit that touches directly on this issue and throwing a bunch of money behind it until it reaches the Supreme Court, which finally lets the court rule directly on whether companies are legally responsible for their AIs’ outputs (which court members have already suggested to be the case). Point being: there’s a bunch of stuff you can do to slow down AI research, but effectively no one is trying in any serious way to do it.
“The military will just build it.”
A radical overestimation of the capabilities of the US military. They lack the talent, the data, they lack everything. It’s just not a concern. I’ve worked on projects with DARPA funding, and I’ve personally received funding from the Army Research Office, and all their research is based almost entirely on supporting specific academics at institutions—and academics and universities have been cut out of AGI research due to the requisite big budgets.
“China will just build it."
Maybe! But I’m pretty skeptical of outside insights into the enigmatic CCP. And also, the Chinese government can’t just turn around and build AI, for, just like the US, it isn’t capable of it. Chinese tech companies on the other hand, might be able to. But, frankly, just like those working on open-sourcing AGI, these companies have often been cribbing from the techniques already published elsewhere; their chances of making next-step AGI breakthroughs may not be very high, anyways.
More importantly, the CCP takes the future of the Chinese people very seriously. They don’t want an AI future, they want a Chinese future. In fact, I once discussed AI with a researcher from China. She said to me: “If you try to build superintelligent AI in China, they put you in a hole. They put you in a hole forever.” Emphasis was her’s. This was only a few years ago.
An example: Back in 2017, when China accounted for an estimated 90% of Bitcoin trading, they randomly shut down all Bitcoin mining activity because they considered it a threat to the soundness of their national currency. If the CCP gets spooked by cases of misalignment like Sydney, and realize it’s really hard to align AGIs with the CCP’s goals, they could very well shut down AGI attempts by their major companies, especially if America has already loaded theirs down with red tape and voluntary safety agreements and benchmarks.
“Advocating for AI activism implies terrorism.”
A minor note: One wild response to my original essay was that it was really a call for violence. This is just flatly untrue (in fact there’s a footnote about how violence harms social movements); more broadly, this conflation is untrue in exactly the same way that nuclear disarmament activism doesn’t imply violence, or how climate change activism doesn’t imply violence. It’s just a non sequitur.
“Activism around AI safety just won’t work!”
It already has. On Thursday of last week, right after the many examples of a misaligned Bing/Sydney, OpenAI released this statement:

While OpenAI carefully refuses to address the recent controversy (they also didn’t respond to journalists for comments, as far as I know), and so it’s not like they’ve demonstrated anything close to the appropriate amount of receptivity and engagement with AI safety concerns, their sudden renewed interest in AI safety is not a coincidence.
Don’t underestimate soft power! Soft power is why corporations do most things. They do them happily, without regulation, so they don’t get yelled at and blamed by the public, which is their greatest fear. A harder and more eagle-eyed view on misalignment cases gone viral has obviously already led to internal concerns and likely fear; even if they roll eyes on Twitter, stakeholders do not. Good. If you want to make billions for yourself while also putting the entirety of the human race at some non-negligible odds for extinction, guess what, you’re going to face a lot of scrutiny. And there’s nothing wrong with that.

The Intrinsic Perspective is a reader-supported publication. For the full experience, and to help put out more writing like this into the world, please consider becoming a paid subscriber.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK