

【深入浅出 Yarn 架构与实现】4-6 RM 行为探究 - 申请与分配 Container - 大数据王小...
source link: https://www.cnblogs.com/shuofxz/p/17169563.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

本小节介绍应用程序的 ApplicationMaster 在 NodeManager 成功启动并向 ResourceManager 注册后,向 ResourceManager 请求资源(Container)到获取到资源的整个过程,以及 ResourceManager 内部涉及的主要工作流程。
一、整体流程#
整个过程可看做以下两个阶段的送代循环:
- 阶段1 ApplicationMaster 汇报资源需求并领取已经分配到的资源;
- 阶段2 NodeManager 向 ResourceManager 汇报各个 Container 运行状态,如果 ResourceManager 发现它上面有空闲的资源,则进行一次资源分配,并将分配的资源保存到对应的 应用程序数据结构中,等待下次 ApplicationMaster 发送心跳信息时获取(即阶段1)。
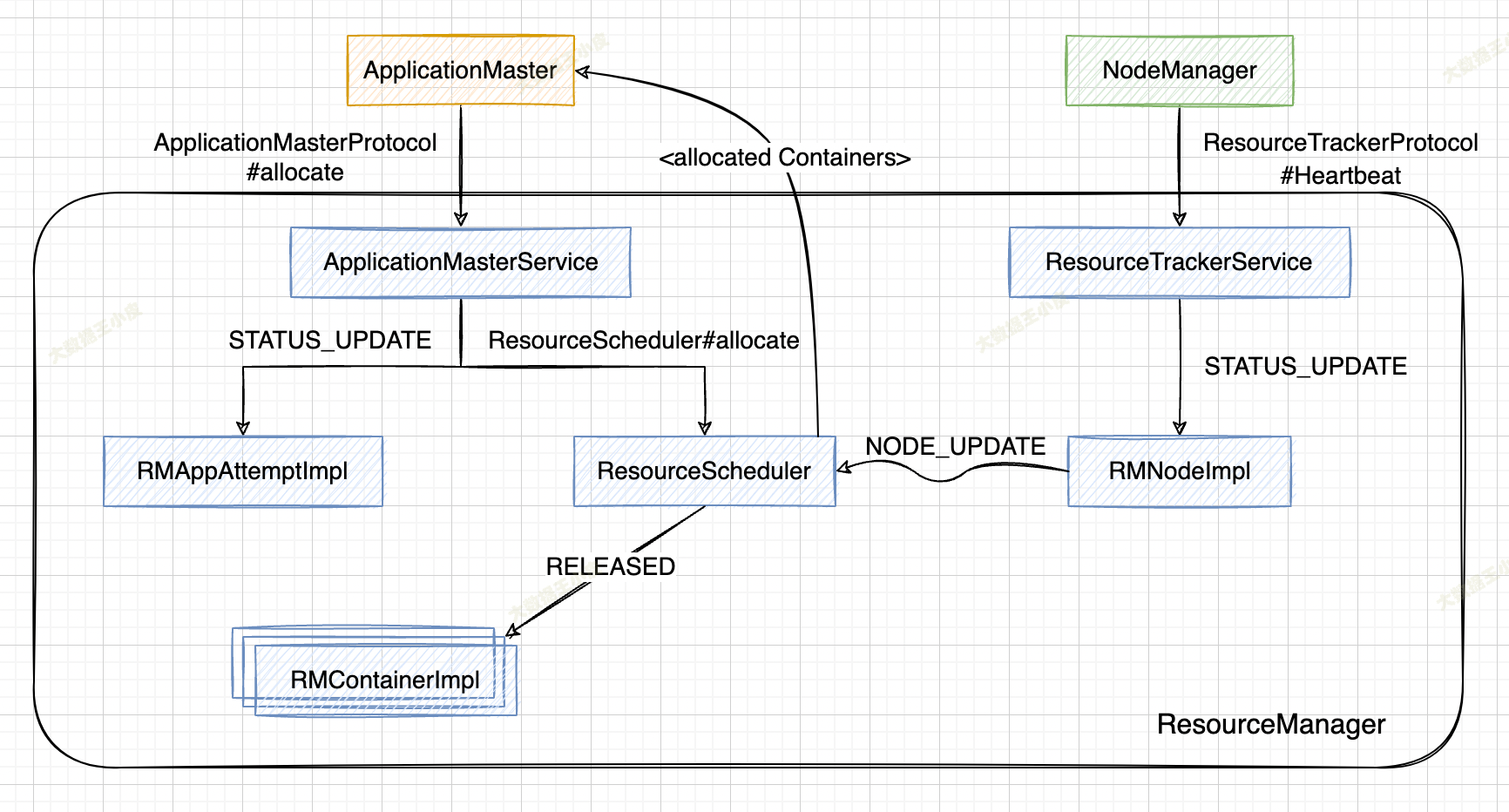
一)AM 汇报心跳#
1、ApplicationMaster 通过 RPC 函数 ApplicationMasterProtocol#allocate 向 ResourceManager 汇报资源需求(由于该函数被周期性调用,我们通常也称之为“心跳”),包括新的资源需求描述、待释放的 Container 列表、请求加入黑名单的节点列表、请求移除黑名单的节点列表等。
public AllocateResponse allocate(AllocateRequest request) {
// Send the status update to the appAttempt.
// 发送 RMAppAttemptEventType.STATUS_UPDATE 事件
this.rmContext.getDispatcher().getEventHandler().handle(
new RMAppAttemptStatusupdateEvent(appAttemptId, request.getProgress()));
// 从 am 心跳 AllocateRequest 中取出新的资源需求描述、待释放的 Container 列表、黑名单列表
List<ResourceRequest> ask = request.getAskList();
List<ContainerId> release = request.getReleaseList();
ResourceBlacklistRequest blacklistRequest = request.getResourceBlacklistRequest();
// 接下来会做一些检查(资源申请量、label、blacklist 等)
// 将资源申请分割(动态调整 container 资源量)
// Split Update Resource Requests into increase and decrease.
// No Exceptions are thrown here. All update errors are aggregated
// and returned to the AM.
List<UpdateContainerRequest> increaseResourceReqs = new ArrayList<>();
List<UpdateContainerRequest> decreaseResourceReqs = new ArrayList<>();
List<UpdateContainerError> updateContainerErrors =
RMServerUtils.validateAndSplitUpdateResourceRequests(rmContext,
request, maximumCapacity, increaseResourceReqs,
decreaseResourceReqs);
// 调用 ResourceScheduler#allocate 函数,将该 AM 资源需求汇报给 ResourceScheduler
// (实际是 Capacity、Fair、Fifo 等实际指定的 Scheduler 处理)
allocation =
this.rScheduler.allocate(appAttemptId, ask, release,
blacklistAdditions, blacklistRemovals,
increaseResourceReqs, decreaseResourceReqs);
}
2、ResourceManager 中的 ApplicationMasterService#allocate 负责处理来自 AM 的心跳请求,收到该请求后,会发送一个 RMAppAttemptEventType.STATUS_UPDATE 事件,RMAppAttemptImpl 收到该事件后,将更新应用程序执行进度和 AMLivenessMonitor 中记录的应用程序最近更新时间。
3、调用 ResourceScheduler#allocate 函数,将该 AM 资源需求汇报给 ResourceScheduler,实际是 Capacity、Fair、Fifo 等实际指定的 Scheduler 处理。
以 CapacityScheduler#allocate 实现为例:
// CapacityScheduler#allocate
public Allocation allocate(ApplicationAttemptId applicationAttemptId,
List<ResourceRequest> ask, List<ContainerId> release,
List<String> blacklistAdditions, List<String> blacklistRemovals,
List<UpdateContainerRequest> increaseRequests,
List<UpdateContainerRequest> decreaseRequests) {
// Release containers
// 发送 RMContainerEventType.RELEASED
releaseContainers(release, application);
// update increase requests
LeafQueue updateDemandForQueue =
updateIncreaseRequests(increaseRequests, application);
// Decrease containers
decreaseContainers(decreaseRequests, application);
// Sanity check for new allocation requests
// 会将资源请求进行规范化,限制到最小和最大区间内,并且规范到最小增长量上
SchedulerUtils.normalizeRequests(
ask, getResourceCalculator(), getClusterResource(),
getMinimumResourceCapability(), getMaximumResourceCapability());
// Update application requests
// 将新的资源需求更新到对应的数据结构中
if (application.updateResourceRequests(ask)
&& (updateDemandForQueue == null)) {
updateDemandForQueue = (LeafQueue) application.getQueue();
}
// 获取已经为该应用程序分配的资源
allocation = application.getAllocation(getResourceCalculator(),
clusterResource, getMinimumResourceCapability());
return allocation;
}
4、ResourceScheduler 首先读取待释放 Container 列表,向对应的 RMContainerImpl 发送 RMContainerEventType.RELEASED 类型事件,杀死正在运行的 Container;然后将新的资源需求更新到对应的数据结构中,之后获取已经为该应用程序分配的资源,并返回给 ApplicationMasterService。
二)NM 汇报心跳#
1、NodeManager 将当前节点各种信息(container 状况、节点利用率、健康情况等)封装到 nodeStatus 中,再将标识节点的信息一起封装到 request 中,之后通过RPC 函数 ResourceTracker#nodeHeartbeat 向 ResourceManager 汇报这些状态。
// NodeStatusUpdaterImpl#startStatusUpdater
protected void startStatusUpdater() {
statusUpdaterRunnable = new Runnable() {
@Override
@SuppressWarnings("unchecked")
public void run() {
// ...
Set<NodeLabel> nodeLabelsForHeartbeat =
nodeLabelsHandler.getNodeLabelsForHeartbeat();
NodeStatus nodeStatus = getNodeStatus(lastHeartbeatID);
NodeHeartbeatRequest request =
NodeHeartbeatRequest.newInstance(nodeStatus,
NodeStatusUpdaterImpl.this.context
.getContainerTokenSecretManager().getCurrentKey(),
NodeStatusUpdaterImpl.this.context
.getNMTokenSecretManager().getCurrentKey(),
nodeLabelsForHeartbeat);
// 发送 nm 的心跳
response = resourceTracker.nodeHeartbeat(request);
2、ResourceManager 中的 ResourceTrackerService 负责处理来自 NodeManager 的请 求,一旦收到该请求,会向 RMNodeImpl 发送一个 RMNodeEventType.STATUS_UPDATE 类型事件,而 RMNodelmpl 收到该事件后,将更新各个 Container 的运行状态,并进一步向 ResoutceScheduler 发送一个 SchedulerEventType.NODE_UPDATE 类型事件。
// ResourceTrackerService#nodeHeartbeat
public NodeHeartbeatResponse nodeHeartbeat(NodeHeartbeatRequest request)
throws YarnException, IOException {
NodeStatus remoteNodeStatus = request.getNodeStatus();
/**
* Here is the node heartbeat sequence...
* 1. Check if it's a valid (i.e. not excluded) node
* 2. Check if it's a registered node
* 3. Check if it's a 'fresh' heartbeat i.e. not duplicate heartbeat
* 4. Send healthStatus to RMNode
* 5. Update node's labels if distributed Node Labels configuration is enabled
*/
// 前 3 步都是各种检查,后面才是重点的逻辑
// Heartbeat response
NodeHeartbeatResponse nodeHeartBeatResponse =
YarnServerBuilderUtils.newNodeHeartbeatResponse(
getNextResponseId(lastNodeHeartbeatResponse.getResponseId()),
NodeAction.NORMAL, null, null, null, null, nextHeartBeatInterval);
// 这里会 set 待释放的 container、application 列表
// 思考:为何只有待释放的列表呢?分配的资源不返回么? - 分配的资源是和 AM 进行交互的
rmNode.setAndUpdateNodeHeartbeatResponse(nodeHeartBeatResponse);
populateKeys(request, nodeHeartBeatResponse);
ConcurrentMap<ApplicationId, ByteBuffer> systemCredentials =
rmContext.getSystemCredentialsForApps();
if (!systemCredentials.isEmpty()) {
nodeHeartBeatResponse.setSystemCredentialsForApps(systemCredentials);
}
// 4. Send status to RMNode, saving the latest response.
// 发送 RMNodeEventType.STATUS_UPDATE 事件
RMNodeStatusEvent nodeStatusEvent =
new RMNodeStatusEvent(nodeId, remoteNodeStatus);
if (request.getLogAggregationReportsForApps() != null
&& !request.getLogAggregationReportsForApps().isEmpty()) {
nodeStatusEvent.setLogAggregationReportsForApps(request
.getLogAggregationReportsForApps());
}
this.rmContext.getDispatcher().getEventHandler().handle(nodeStatusEvent);
3、ResourceScheduler 收到事件后,如果该节点上有可分配的空闲资源,则会将这些资源分配给各个应用程序,而分配后的资源仅是记录到对应的数据结构中,等待 ApplicationMaster 下次通过心跳机制来领取。(资源分配的具体逻辑,将在后面介绍 Scheduler 的文章中详细讲解)。
三、总结#
本篇分析了申请与分配 Container 的流程,主要分为两个阶段。
第一阶段由 AM 发起,通过心跳向 RM 发起资源请求。
第二阶段由 NM 发起,通过心跳向 RM 汇报资源使用情况。
之后就是,RM 根据 AM 资源请求以及 NM 剩余资源进行一次资源分配(具体分配逻辑将在后续文章中介绍),并将分配的资源通过下一次 AM 心跳返回给 AM。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK