

"Clean" Code, Horrible Performance
source link: https://www.computerenhance.com/p/clean-code-horrible-performance
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

"Clean" Code, Horrible Performance
Many programming "best practices" taught today are performance disasters waiting to happen.
This is a free bonus video from the Performance-Aware Programming series. It shows the real-world performance costs of following “clean code” guidelines. For more information about the course, please see the About page or the Table of Contents.
A lightly-edited transcript of the video appears below.
Some of the most-often repeated programming advice, especially to beginner programmers, is that they should be writing “clean” code. That moniker is accompanied by a long list of rules that tell you what you should do in order for your code to be “clean”.
A large portion of these rules don't actually affect the runtime of the code that you write. These sorts of rules cannot be objectively assessed, and we don't necessarily have to because they're fairly arbitrary at that point. However, several “clean” code rules — some of the ones most emphatically stressed — are things we can objectively measure because they do affect the runtime behavior of the code.
If you look at a “clean” code summary and pull out the rules that actually affect the structure of your code, you get:
Prefer polymorphism to “if/else” and “switch”
Code should not know about the internals of objects it’s working with
Functions should be small
Functions should do one thing
“DRY” - Don’t Repeat Yourself
These rules are rather specific about how any particular piece of code should be created in order for it to be “clean”. What I would like to ask is, if we create a piece of code that follows these rules, how does it perform?
In order to construct what I would consider the most favorable case for a “clean” code implementation of something, I used existing example code contained in “clean” code literature. This way, I am not making anything up, I’m just assessing “clean” code advocates’ rules using the example code they give to illustrate those rules.
If you look at “clean” code examples, you'll often see an example like this:
/* ========================================================================
LISTING 22
======================================================================== */
class shape_base
{
public:
shape_base() {}
virtual f32 Area() = 0;
};
class square : public shape_base
{
public:
square(f32 SideInit) : Side(SideInit) {}
virtual f32 Area() {return Side*Side;}
private:
f32 Side;
};
class rectangle : public shape_base
{
public:
rectangle(f32 WidthInit, f32 HeightInit) : Width(WidthInit), Height(HeightInit) {}
virtual f32 Area() {return Width*Height;}
private:
f32 Width, Height;
};
class triangle : public shape_base
{
public:
triangle(f32 BaseInit, f32 HeightInit) : Base(BaseInit), Height(HeightInit) {}
virtual f32 Area() {return 0.5f*Base*Height;}
private:
f32 Base, Height;
};
class circle : public shape_base
{
public:
circle(f32 RadiusInit) : Radius(RadiusInit) {}
virtual f32 Area() {return Pi32*Radius*Radius;}
private:
f32 Radius;
};It’s a base class for a shape with a few specific shapes derived from it: circle, triangle, rectangle, square. We then have a virtual function that computes the area.
Like the rules demand, we are preferring polymorphism. Our functions do only one thing. They are small. All that good stuff. So we end up with a “clean” class hierarchy, with each derived class knowing how to compute its own area, and storing the data required to compute that area.
If we image using this hierarchy to do something — say, finding the total area of a series of shapes that we pass in — we would expect to see something like this:
/* ========================================================================
LISTING 23
======================================================================== */
f32 TotalAreaVTBL(u32 ShapeCount, shape_base **Shapes)
{
f32 Accum = 0.0f;
for(u32 ShapeIndex = 0; ShapeIndex < ShapeCount; ++ShapeIndex)
{
Accum += Shapes[ShapeIndex]->Area();
}
return Accum;
}You'll notice I haven't used an iterator here because there was nothing in the rules that suggested you had to use iterators. As such, I figured I would give “clean” code the benefit of the doubt and not add any kind of abstracted iterator that might confuse the compiler and lead to worse performance.
You may also notice that this loop is over an array of pointers. This is a direct consequence of using a class hierarchy: we have no idea how big in memory each of these shapes might be. So unless we were going to add another virtual function call to get the data size of each shape, and use some kind of a variable skipping procedure to go through them, we need pointers to find out where each shape actually begins.
Because this is an accumulation, there's a loop-carried dependency here which might slow the loop down. Since accumulation can be reordered arbitrarily, I also wrote a hand-unrolled version just to be safe:
/* ========================================================================
LISTING 24
======================================================================== */
f32 TotalAreaVTBL4(u32 ShapeCount, shape_base **Shapes)
{
f32 Accum0 = 0.0f;
f32 Accum1 = 0.0f;
f32 Accum2 = 0.0f;
f32 Accum3 = 0.0f;
u32 Count = ShapeCount/4;
while(Count--)
{
Accum0 += Shapes[0]->Area();
Accum1 += Shapes[1]->Area();
Accum2 += Shapes[2]->Area();
Accum3 += Shapes[3]->Area();
Shapes += 4;
}
f32 Result = (Accum0 + Accum1 + Accum2 + Accum3);
return Result;
}If I run these two routines in a simple test harness, I can get a rough measure of the total number of cycles per shape that are required to do that operation:
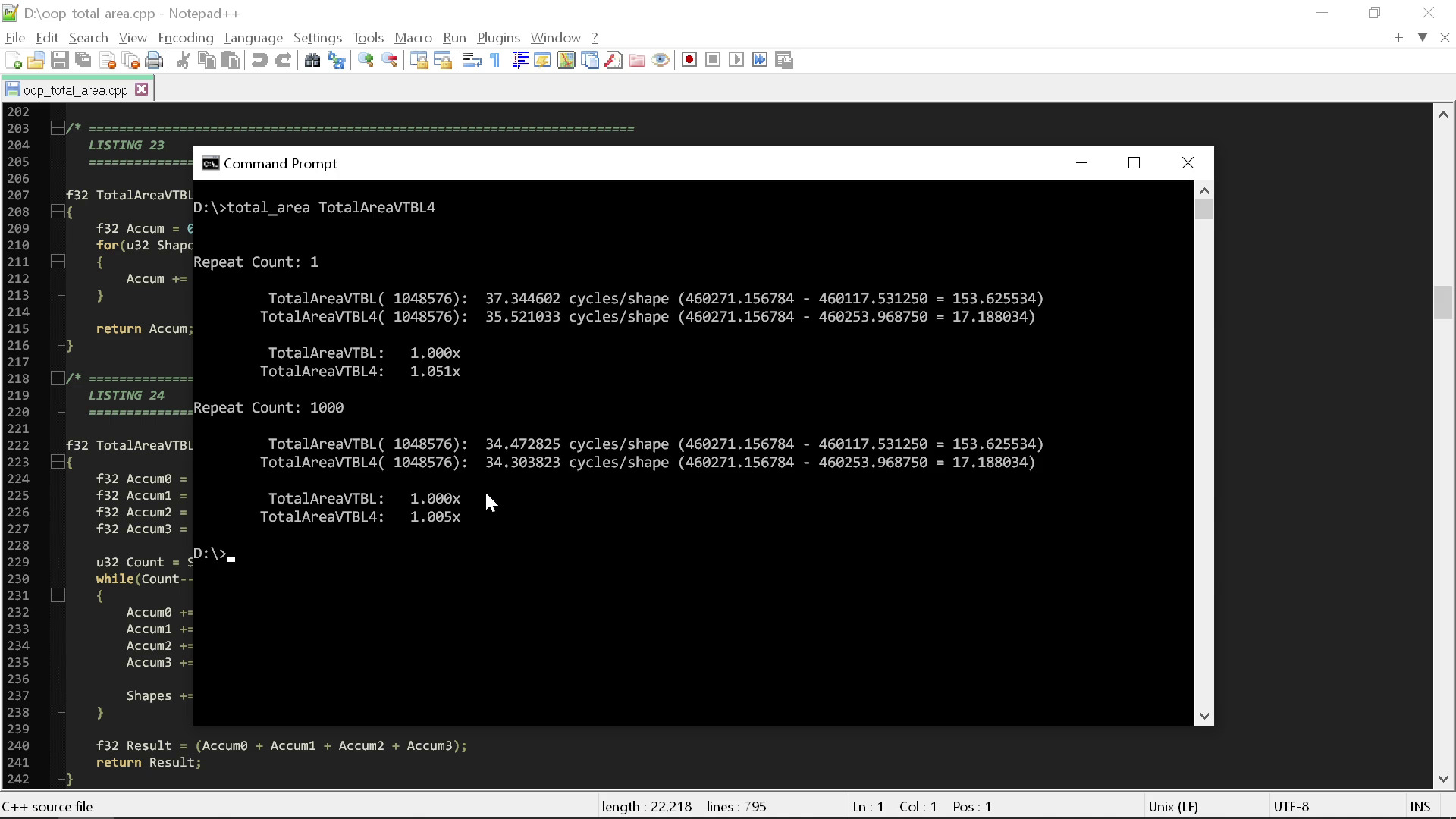
The harness times the code in two different ways. The first way is running the code only once, to show what happens in an arbitrary “cold” state — the data should be in L3 but L2 and L1 have been flushed, and the branch predictor has not “practiced” on the loop.
The second way is running the code many times repeatedly, to see what happens when the cache and branch predictor are operating in their most favorable way for the loop. Note that none of these are hard-core measurements, because as you’ll see, the differences we’ll be looking at are so large that we don’t need to break out any serious analysis tools.
What we can see from the results is there's not much of a difference between the two routines. It's around 35 cycles to do the “clean” code area calculation on a shape. Maybe it gets down more towards 34 sometimes if you're really lucky.
So 35 cycles is what we can expect from following all the rules. What would happen if instead we violated just the first rule? Instead of using polymorphism here, what if we just use a switch statement instead
?
Here I've written the exact same code, but instead of writing it using a class hierarchy (and therefore, at runtime, a vtable), I've written it using an enum and a shape type that flattens everything into one struct:
/* ========================================================================
LISTING 25
======================================================================== */
enum shape_type : u32
{
Shape_Square,
Shape_Rectangle,
Shape_Triangle,
Shape_Circle,
Shape_Count,
};
struct shape_union
{
shape_type Type;
f32 Width;
f32 Height;
};
f32 GetAreaSwitch(shape_union Shape)
{
f32 Result = 0.0f;
switch(Shape.Type)
{
case Shape_Square: {Result = Shape.Width*Shape.Width;} break;
case Shape_Rectangle: {Result = Shape.Width*Shape.Height;} break;
case Shape_Triangle: {Result = 0.5f*Shape.Width*Shape.Height;} break;
case Shape_Circle: {Result = Pi32*Shape.Width*Shape.Width;} break;
case Shape_Count: {} break;
}
return Result;
}This is the “old school” way you would have written this before “clean” code.
Note that because we no longer have specific datatypes for every shape variant, if a type doesn’t have one of the values in question (like “height”, for example), it simply doesn’t use it.
Now, instead of getting the area from a virtual function call, a user of this struct gets it from a function with a switch statement: exactly the thing that a “clean” code lecture would tell you to never ever do. Even so, you’ll note that the code, despite being much more concise, is basically the same. Each case of the switch statement is just the same code as the corresponding virtual function in the class hierarchy.
For the summation loops themselves, you can see that they are nearly identical to the “clean” version:
/* ========================================================================
LISTING 26
======================================================================== */
f32 TotalAreaSwitch(u32 ShapeCount, shape_union *Shapes)
{
f32 Accum = 0.0f;
for(u32 ShapeIndex = 0; ShapeIndex < ShapeCount; ++ShapeIndex)
{
Accum += GetAreaSwitch(Shapes[ShapeIndex]);
}
return Accum;
}
f32 TotalAreaSwitch4(u32 ShapeCount, shape_union *Shapes)
{
f32 Accum0 = 0.0f;
f32 Accum1 = 0.0f;
f32 Accum2 = 0.0f;
f32 Accum3 = 0.0f;
ShapeCount /= 4;
while(ShapeCount--)
{
Accum0 += GetAreaSwitch(Shapes[0]);
Accum1 += GetAreaSwitch(Shapes[1]);
Accum2 += GetAreaSwitch(Shapes[2]);
Accum3 += GetAreaSwitch(Shapes[3]);
Shapes += 4;
}
f32 Result = (Accum0 + Accum1 + Accum2 + Accum3);
return Result;
}The only difference is that instead of calling a member function to get the area, we call a regular function. That’ sit.
However, you can already see an immediate benefit from using the flattened structure as compare to a class hierarchy: the shapes can just be in an array, no pointers necessary. There is no indirection because we’ve made all our shapes the same size.
Plus, we get the added benefit that the compiler can now see exactly what we're doing in this loop, because it can just look at the GetAreaSwitch function and see the entire codepath. It doesn’t have to assume that anything might happen in some virtualized area function only known at run-time.
So with those benefits, what can the compiler do for us? If I run all four together now, these are the results:
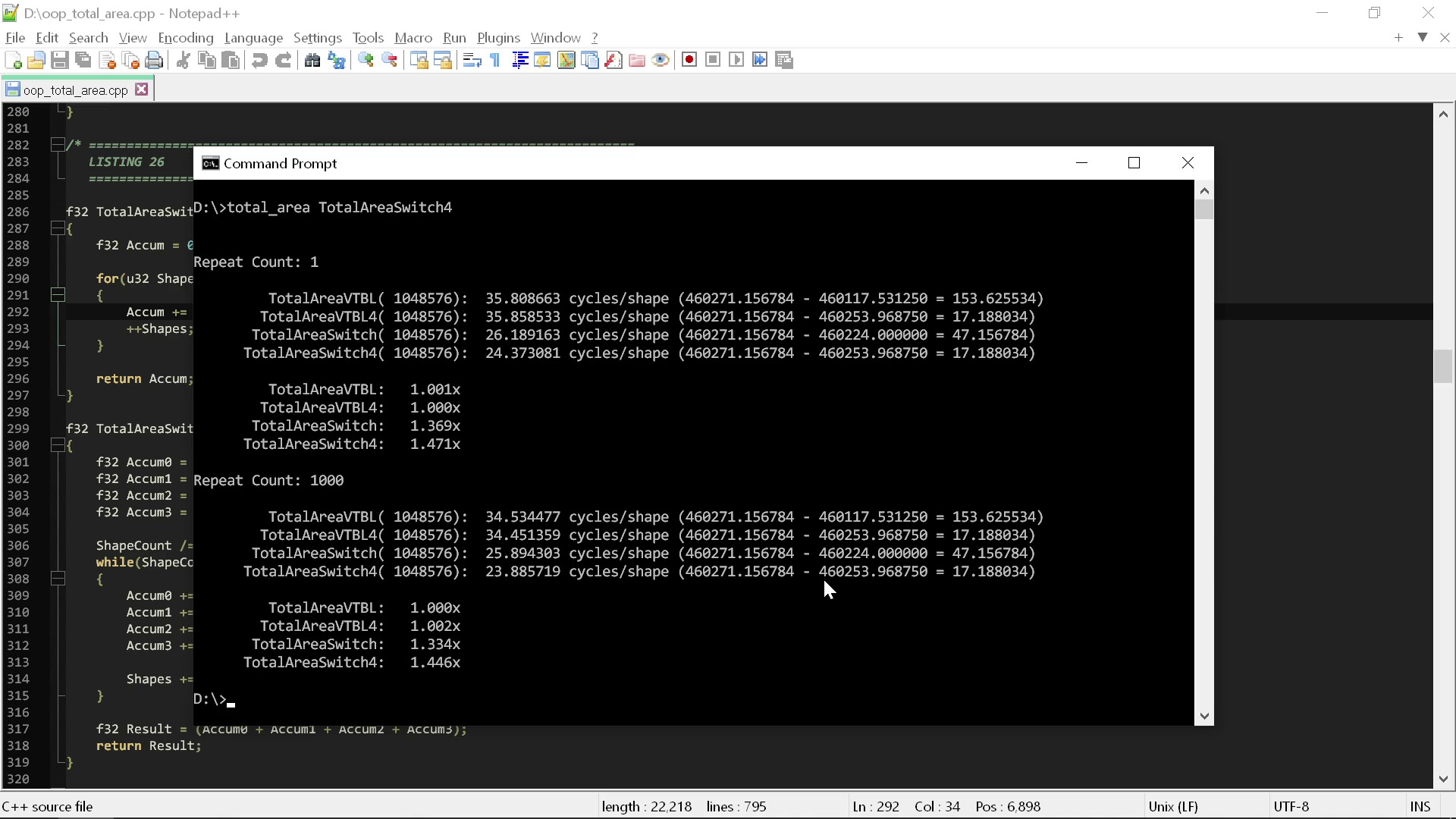
When we look at the results, we see something rather remarkable: just that one change — writing the code the old fashioned way rather than the “clean” code way — gave us an immediate 1.5x performance increase. That’s a free 1.5x for not doing anything other than removing the extraneous stuff required to use C++ polymorphism.
So by violating the first rule of clean code — which is one of its central tenants — we are able to drop from 35 cycles per shape to 24 cycles per shape, impling that code following that rule number is 1.5x slower than code that doesn’t. To put that in in hardware terms, it would be like taking an iPhone 14 Pro Max and reducing it to an iPhone 11 Pro Max. It's three or four years of hardware evolution erased because somebody said to use polymorphism instead of switch statements.
But we're only just getting started.
What if we broke more rules? What if we also broke the second rule, “no internal knowledge”? What if our functions could use knowledge of what they were actually operating on to make themselves more efficient?
If you look back at the get area switch statement, one of the things you can see is that all the area computations are similar:
case Shape_Square: {Result = Shape.Width*Shape.Width;} break;
case Shape_Rectangle: {Result = Shape.Width*Shape.Height;} break;
case Shape_Triangle: {Result = 0.5f*Shape.Width*Shape.Height;} break;
case Shape_Circle: {Result = Pi32*Shape.Width*Shape.Width;} break;They all do something like width times height, or width times width, optionally with a coefficient like π. and then they're gonna multiply by half in the case of a triangle or pie in the case of a circle, something like this.
This is actually one of the reasons that — unlike “clean” code advocates — I think switch statements are great! They make this kind of pattern very easy to see. When your code is organized by operation, rather than by type, it’s straightforward to observe and pull out common patterns. By contrast, if you were to look back at the class version, you would probably never notice this kind of pattern because not only is there a lot more boilerplate in the way, but “clean” code advocates recommend putting each class in a separate file, making it even less likely you’ll ever notice something like this.
So architecturally I disagree with class hierarchies in general, but that's beside the point. The only point I really want to make right now is that we can simplify this switch statement quite a bit by noticing the pattern.
And remember: this is not an example that I picked! This is the example that clean code advocates themselves use for illustrative purposes. So I didn’t intentionally pick an example where you happen to be able to pull out a pattern — it’s just very likely that you can do this, because most things of similar type have similar algorithmic structure, so as expected, it happens here.
To exploit this pattern, we can introduce a simple table that says what the coefficient is that we need to use for each type. If we then make our single-parameter types like circle and square duplicate their width into their height, we can make a dramatically simpler function for area:
/* ========================================================================
LISTING 27
======================================================================== */
f32 const CTable[Shape_Count] = {1.0f, 1.0f, 0.5f, Pi32};
f32 GetAreaUnion(shape_union Shape)
{
f32 Result = CTable[Shape.Type]*Shape.Width*Shape.Height;
return Result;
}The two summation loops for this version are exactly the same — they don’t have to be changed, they can just call GetAreaUnion instead of GetAreaSwitch, and be otherwise identical.
Let's see what happens if we run this new version against our previous loops:

What you can see here is that by taking advantage of what we know about the actual types we have — effectively switching from a type-based mindset to a function-based mindset — we get a massive speed increase. We've gone from a switch statement that was merely 1.5x faster to a table-driven version that’s fully 10x faster or more on the exact same problem.
And to do this, we used nothing other than one table lookup and a single line of code! It’s not only much faster, it’s also much less semantically complex. It’s less tokens, less operations, less lines of code.
So by fusing our data model with our desired operation, rather than demanding that the operation not know the internals, we got all the way down to the 3.0-3.5 cycles per shape range. That's a 10x speed improvement over the “clean” code version that follows the first two rules.
10x is so large a performance increase, it's not even possible to put it in iPhone terms because iPhone benchmarks don't go back far enough. If I went all the way back to the iPhone 6, which is the oldest phone still showing up on modern benchmarks, it's only about three times slower than the iPhone 14 Pro Max. So we can't even use phones anymore to describe this difference.
If we were to look at single-thread desktop performance, a 10x speed improvement is like going from the average CPU mark today all the way back to the average CPU mark from 2010! The first two rules of the “clean code” concept wipe out 12 years of hardware evolution, all by themselves.
But as shocking as that is, this test if only doing a very simple operation. We’re not really using “functions should be small” and “functions should do only one thing” much, because we only have one very simple thing to do in the first place. What if we add another aspect to our problem so that we can follow those rules more directly?
Here I have written the exact same hierarchy that we had before, but this time I’ve added one more virtual function which tells us the number of corners each shape has:
/* ========================================================================
LISTING 32
======================================================================== */
class shape_base
{
public:
shape_base() {}
virtual f32 Area() = 0;
virtual u32 CornerCount() = 0;
};
class square : public shape_base
{
public:
square(f32 SideInit) : Side(SideInit) {}
virtual f32 Area() {return Side*Side;}
virtual u32 CornerCount() {return 4;}
private:
f32 Side;
};
class rectangle : public shape_base
{
public:
rectangle(f32 WidthInit, f32 HeightInit) : Width(WidthInit), Height(HeightInit) {}
virtual f32 Area() {return Width*Height;}
virtual u32 CornerCount() {return 4;}
private:
f32 Width, Height;
};
class triangle : public shape_base
{
public:
triangle(f32 BaseInit, f32 HeightInit) : Base(BaseInit), Height(HeightInit) {}
virtual f32 Area() {return 0.5f*Base*Height;}
virtual u32 CornerCount() {return 3;}
private:
f32 Base, Height;
};
class circle : public shape_base
{
public:
circle(f32 RadiusInit) : Radius(RadiusInit) {}
virtual f32 Area() {return Pi32*Radius*Radius;}
virtual u32 CornerCount() {return 0;}
private:
f32 Radius;
};A rectangle has four corners, a triangle has three, a circle has none, etc. I'm then going to change the definition of the problem from computing the sum of the areas of a series of shapes, to computing the sum of the corner-weighted areas, which I’m going to define as one over one plus the number of corners.
Much like the area summation, there's no reason for this, I’m just trying to work within the example. I added the simplest possible thing I could think of, then did some very basic math on it.
To update the “clean” summation loop, we add the necessary math and the additional virtual function call:
f32 CornerAreaVTBL(u32 ShapeCount, shape_base **Shapes)
{
f32 Accum = 0.0f;
for(u32 ShapeIndex = 0; ShapeIndex < ShapeCount; ++ShapeIndex)
{
Accum += (1.0f / (1.0f + (f32)Shapes[ShapeIndex]->CornerCount())) * Shapes[ShapeIndex]->Area();
}
return Accum;
}
f32 CornerAreaVTBL4(u32 ShapeCount, shape_base **Shapes)
{
f32 Accum0 = 0.0f;
f32 Accum1 = 0.0f;
f32 Accum2 = 0.0f;
f32 Accum3 = 0.0f;
u32 Count = ShapeCount/4;
while(Count--)
{
Accum0 += (1.0f / (1.0f + (f32)Shapes[0]->CornerCount())) * Shapes[0]->Area();
Accum1 += (1.0f / (1.0f + (f32)Shapes[1]->CornerCount())) * Shapes[1]->Area();
Accum2 += (1.0f / (1.0f + (f32)Shapes[2]->CornerCount())) * Shapes[2]->Area();
Accum3 += (1.0f / (1.0f + (f32)Shapes[3]->CornerCount())) * Shapes[3]->Area();
Shapes += 4;
}
f32 Result = (Accum0 + Accum1 + Accum2 + Accum3);
return Result;
}I could argue that I should pull this out into another function, adding yet another layer of indirection. But again, to give the “clean” code the benefit of the doubt, I will leave it explicitly in there.
To update the switch-statement version, we make essentially the same changes. First, we add another switch statement for the number of corners, with cases that exactly mirror the hierarchy version:
/* ========================================================================
LISTING 34
======================================================================== */
u32 GetCornerCountSwitch(shape_type Type)
{
u32 Result = 0;
switch(Type)
{
case Shape_Square: {Result = 4;} break;
case Shape_Rectangle: {Result = 4;} break;
case Shape_Triangle: {Result = 3;} break;
case Shape_Circle: {Result = 0;} break;
case Shape_Count: {} break;
}
return Result;
}Then we compute the exact same thing as the hierarchy version:
/* ========================================================================
LISTING 35
======================================================================== */
f32 CornerAreaSwitch(u32 ShapeCount, shape_union *Shapes)
{
f32 Accum = 0.0f;
for(u32 ShapeIndex = 0; ShapeIndex < ShapeCount; ++ShapeIndex)
{
Accum += (1.0f / (1.0f + (f32)GetCornerCountSwitch(Shapes[ShapeIndex].Type))) * GetAreaSwitch(Shapes[ShapeIndex]);
}
return Accum;
}
f32 CornerAreaSwitch4(u32 ShapeCount, shape_union *Shapes)
{
f32 Accum0 = 0.0f;
f32 Accum1 = 0.0f;
f32 Accum2 = 0.0f;
f32 Accum3 = 0.0f;
ShapeCount /= 4;
while(ShapeCount--)
{
Accum0 += (1.0f / (1.0f + (f32)GetCornerCountSwitch(Shapes[0].Type))) * GetAreaSwitch(Shapes[0]);
Accum1 += (1.0f / (1.0f + (f32)GetCornerCountSwitch(Shapes[1].Type))) * GetAreaSwitch(Shapes[1]);
Accum2 += (1.0f / (1.0f + (f32)GetCornerCountSwitch(Shapes[2].Type))) * GetAreaSwitch(Shapes[2]);
Accum3 += (1.0f / (1.0f + (f32)GetCornerCountSwitch(Shapes[3].Type))) * GetAreaSwitch(Shapes[3]);
Shapes += 4;
}
f32 Result = (Accum0 + Accum1 + Accum2 + Accum3);
return Result;
}Just like in the total area version, the code looks almost identical between the class hierarchy implementation and the switch implementation. The only difference is whether we call a virtual function or go through a switch statement.
Moving on to the table-driven case, you can see how awesome it actually is when we fuse operations and data together! Unlike all the other versions, in this version, the only thing that has to change is the values in our table! We don't actually have to get secondary information about our shape — we can weld both the corner count and the area coefficient directly into the table, and the code stays exactly the same otherwise:
/* ========================================================================
LISTING 36
======================================================================== */
f32 const CTable[Shape_Count] = {1.0f / (1.0f + 4.0f), 1.0f / (1.0f + 4.0f), 0.5f / (1.0f + 3.0f), Pi32};
f32 GetCornerAreaUnion(shape_union Shape)
{
f32 Result = CTable[Shape.Type]*Shape.Width*Shape.Height;
return Result;
}If we run all of these “corner area” functions, we can look at how their performance is affected by the addition of the second shape property:
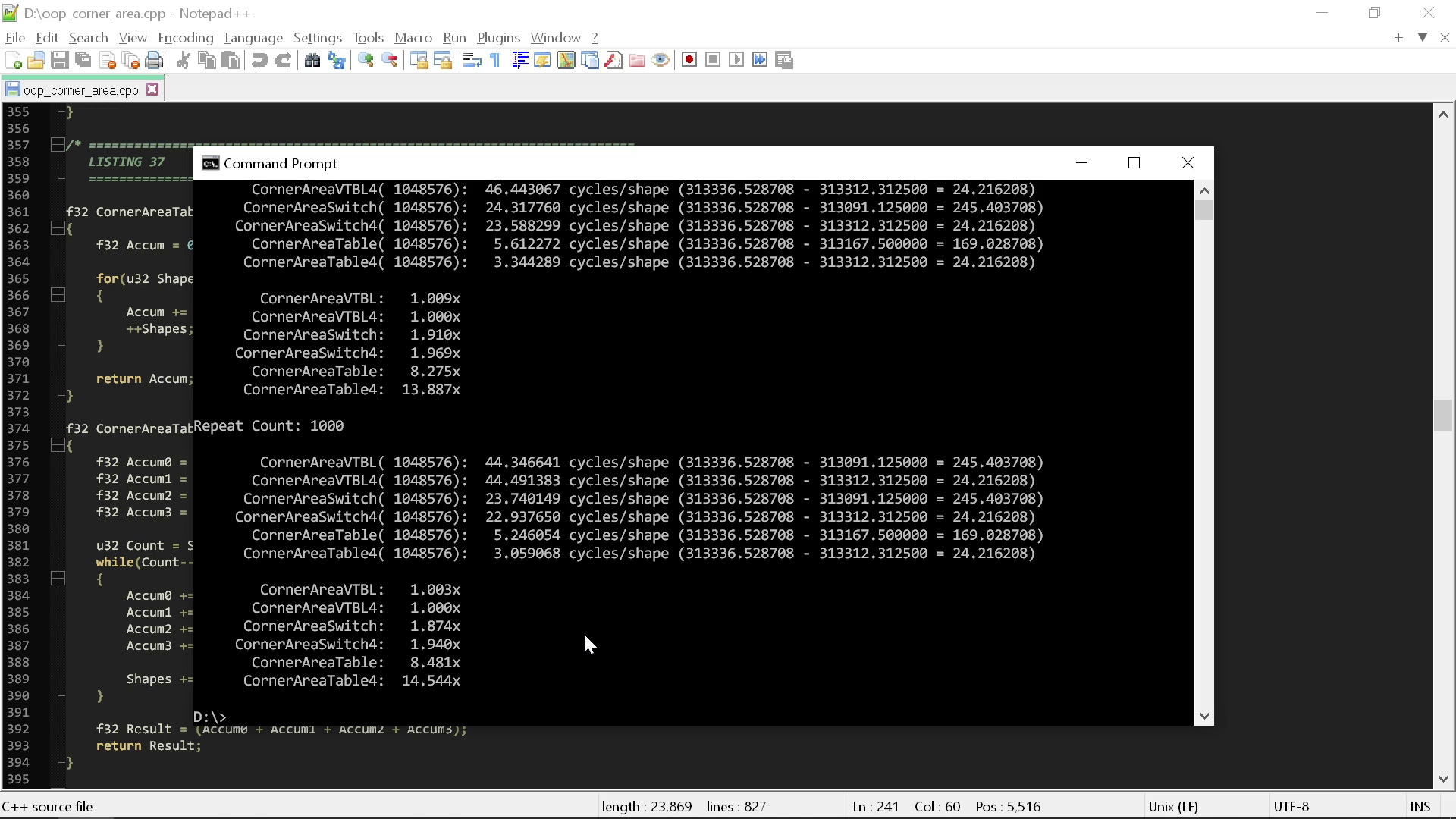
As you can see, these results are even worse for the “clean” code. The switch statement version, which was previously only 1.5x faster, is now nearly 2x faster, and the lookup table version is nearly 15x faster.
This demonstrates the even deeper problem with “clean” code: the more complex you make the problem, the more these ideas harm your performance. When you try to scale up “clean” techniques to real objects with many properties, you will suffer these pervasive performance penalties everywhere in your code.
The more you use the “clean” code methodology, the less a compiler is able to see what you're doing. Everything is in separate translation units, behind virtual function calls, etc. No matter how smart the compiler is, there’s very little it can do with that kind of code.
And to make matters worse, there’s not much you can do with that kind of code either! As I showed before, simple things like pulling values out into a table and removing switch statements are simple to achieve if your codebase is architected around it’s functions. If instead it is architected around it’s types, it is much more difficult — perhaps even impossible without extensive rewrites.
So we've gone from a 10x speed difference to a 15x speed difference just be adding one more property to our shapes. That's like pushing 2023 hardware all the way back to 2008! Instead of erasing 12 years, we're erasing 14 years just by adding one new parameter to our definition of the problem.
That's horrible in and of itself. But you'll notice, I haven’t even mentioned optimization yet! Other than ensuring there wasn’t a loop-carried dependency, for testing purposes, I haven’t optimized anything!
Here's what it looks like if I run these routines against a lightly optimized AVX version of the same calculation:
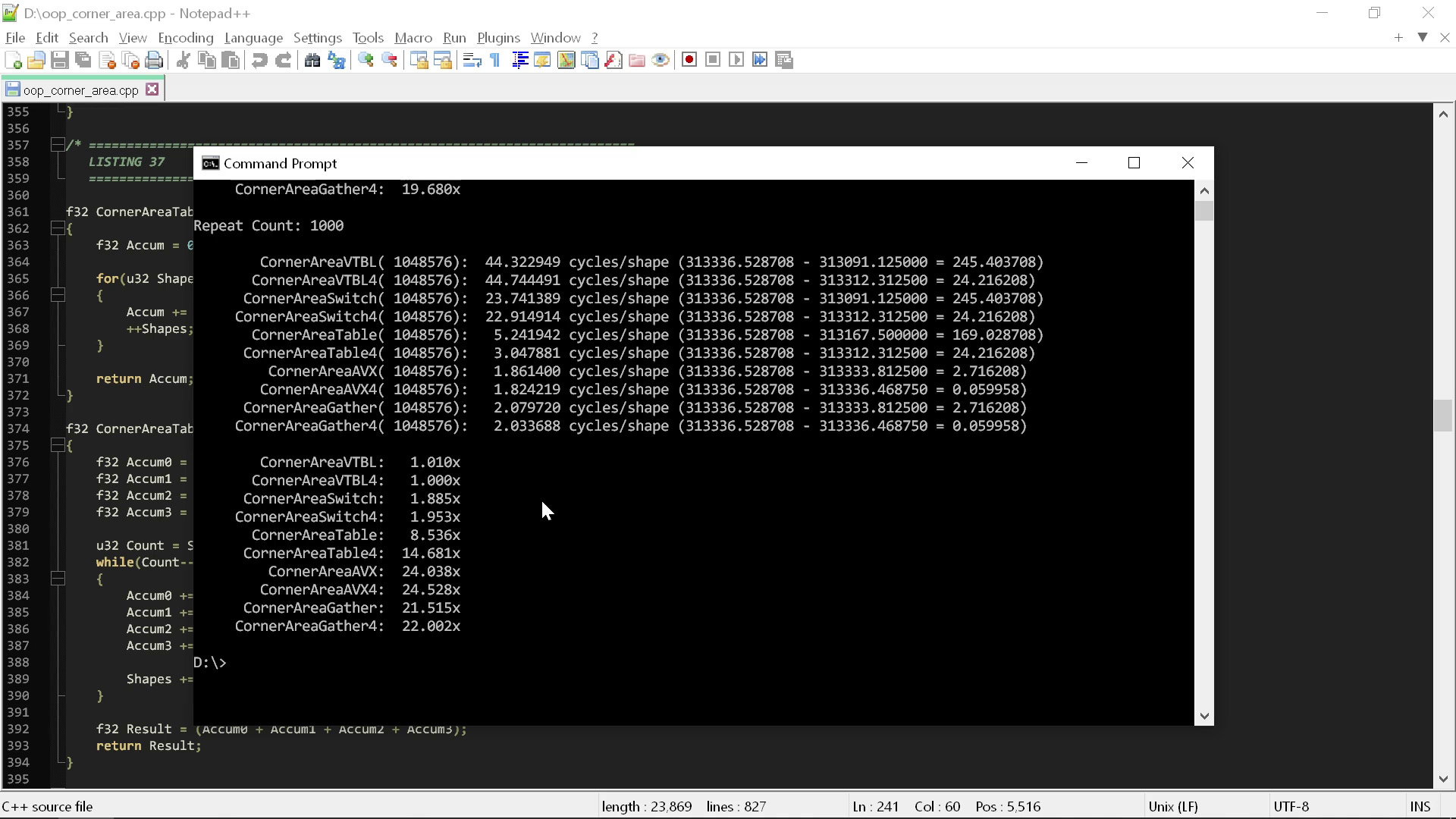
The speed differences range from 20-25x — and of course, none of the AVX-optimized code uses anything remotely like “clean” code principles.
So that’s four rules down the drain. What about number five?
Honestly, “don’t repeat yourself” seems fine. As you saw from the listings, we didn't really repeat ourselves much. Maybe if you count the four-accumulator unrolled versions we did, but that was just for demonstration purposes. You don’t actually have to have both routines unless you’re doing timings like this.
If “DRY” means something more stringent — like don't build two different tables that both encode versions of the same coefficients — well then I might disagree with that sometimes, because we may have to do that for reasonable performance. But if in general “DRY” just means don't write the exact same code twice, that sounds like reasonable advice.
And most importantly, we don’t have to violate it to write code that gets reasonable performance.
So out of the five clean code things that actually affect code structure, I would say you have one you might want to think about and four you definitely shouldn't. Why? Because as you may have noticed, software is extremely slow these days. It performs very, very poorly compared to how fast modern hardware can actually do the things we need our software to do.
If you ask why software is slow, there are several answers. Which one is most dominant depends on the specific development environment and coding methodology.
But for a certain segment of the computing industry, the answer to “why is software so slow” is in large part “because of ‘clean’ code”. The ideas underlying the “clean” code methodology are almost all horrible for performance, and you shouldn’t do them.
The “clean” code rules were developed because someone thought they would produce more maintainable codebases. Even if that were true, you’d have to ask, “At what cost?”
It simply cannot be the case that we're willing to give up a decade or more of hardware performance just to make programmers’ lives a little bit easier. Our job is to write programs that run well on the hardware that we are given. If this is how bad these rules cause software to perform, they simply aren't acceptable.
We can still try to come up with rules of thumb that help keep code organized, easy to maintain, and easy to read. Those aren't bad goals! But these rules ain’t it. They need to stop being said unless they are accompanied by a big old asterisk that says, “and your code will get 15 times slower or more when you do them.”
This post is part of the Performance-Aware Programming series. If you’d like access to the rest of the series, including new installments as they are released, you can subscribe here for $9/month:
Personally, I wouldn’t say that a switch statement is inherently less polymorphic than a vtable. They are just two different implementations of the same thing. But, the “clean” code rules say to prefer polymorphism to switch statements, so I’m using their terminology here, where clearly they don’t think a switch statement is polymorphic.
Recommend
-
65
“OnePlus has been absolutely horrible at managing their git tree. Rather than utilizing the full power of git like Google does, they squash each source drop into one commit, which messes with history.”
-
46
I'm fine with phone displays having a "notch" at the top, but companies need to work on their messaging of _why_ the notches are there.
-
29
Why computers suck and how learning from OpenBSD can make them marginally less horrible Arthur Rasmusson (Co-Founder, Arc Compute) & Louis Castricato (Computer Scientist,...
-
22
My (mis)adventures with async, tokio, and async_std Kevin...
-
18
Join GitHub today GitHub is home to over 50 million developers working together to host and review code, manage projects, and build software together.
-
5
The Most Horrible, Awful Aspect of Startups and Remote Employees Jun 3, 2019 I'm a firm believer in remote work – I have spent the past 20 years as a remote employee for many different organizations and there'...
-
9
Apple's horrible maps, part 3 Yep, I've found more errors in Apple Maps. Once again, my testing device is running the latest build of iOS. Looking for a Sprint sto...
-
9
Apple's horrible new maps shouldn't have been a flag day It's been a couple of months since iOS 6 hit and forced users to deal with a suboptimal mapping experience. I wrote
-
4
1 Comment
-
2
SE Radio 577: Casey Muratori on...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK