

如何应对外包公司(文思海辉)的Python后端面试
source link: https://v3u.cn/a_id_151
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

如何应对外包公司(文思海辉)的Python后端面试

最近春招如火如荼,我接触到的几位同学也纷纷去市场里试了试水,不得不说由于疫情的影响,导致目前中等水平的开发者择业有了些许困难,毕竟不是所有人都能去一二线的大厂,有的时候海浪过大,我们不得不收起风帆,卧薪尝胆,入港蛰伏,所以我们可以把目光投向一些相对要求不是特别高的岗位,比如外包岗,当然了业内其实对外包公司有一些偏见,评价不高。客观的说,外包公司确实有一些不尽如人意的地方,但是其实也有一些好处不能忽略:比如接触的项目多,接触的人多,积累的经验快,适合想积累经验的人,同时有进入甲方的机会,如果业务做得不错,有一定机会能进入甲方公司,一般甲方如果是大厂的话直接进不去但通过外包进去后有一定概率能转甲方,不失为一条曲线救国的路线。文思海辉作为国内外包公司的执牛耳者,它的面试题相对有代表性,这里我们针对文思海辉的外包岗面试题进行分析和总结,技术栈以Python为主,辅以一些简单的前端知识点。
1.自我介绍
关于自我介绍这个其实是老生常谈的问题,很多人的介绍都很模式化
,比如我叫某某,今年多大,几几年在某家公司都做过什么,其实这些基本信息都在简历上已经明确注明了,所以自我介绍完全可以说一点简历上没写的东西,比如可以说说自己最近关注的新技术,对于一些最近的业内新闻有哪些自己的见解,也可以借助自我介绍环节主动和面试官搭讪,问问老家在哪儿之类的,一开始和面试官简单的交流可以判断这位面试官关注点在哪里,比如是注重细节还是着眼大局,为下面的面试题打好基础。
2.range和xrange的区别
这是一个相当古老的问题,古老到可以追溯到Python2时代,由此可见文思海辉的Python面试题更新频率并不高,首先一定要明确python3已经没有xrange方法,之前的xrange已经重命名为range,而在python2时代,range返回的是一个包含所有元素的列表,xrange返回的是一个生成器,生成器是一个可迭代对象,在对生成器进行迭代时,元素是逐个被创建的。而列表需要根据列表长度而开辟出相应的内存空间用来遍历,一般来看,在对大序列进行迭代的时候,因为xrange的特性,所以它会比较节约内存。
3.请谈谈Python的深浅拷贝
这也是一个python面试经常会被问到的问题,一般人的简单理解就是浅拷贝会影响原对象而深拷贝不会,其实这道题是有坑的,深拷贝之后对原对象不产生影响基本问题不大,但是浅拷贝一定要分三种情况来讨论
1.拷贝不可变对象:只是增加一个指向原对象的引用,改变会互相影响。
>>> a = (1, 2, [3, 4])
>>> b = copy.copy(a)
>>> b
... (1, 2, [3, 4])
# 改变一方,另一方也改变
>>> b[2].append(5)
>>> a
... (1, 2, [3, 4, 5])2.拷贝可变对象(一层结构):产生新的对象,开辟新的内存空间,改变互不影响。
>>> import copy
>>> a = [1, 2, 3]
>>> b = copy.copy(a)
>>> b
... [1, 2, 3]
# 查看两者的内存地址,不同,开辟了新的内存空间
>>> id(b)
... 1833997595272
>>> id(a)
... 1833997595080
>>> a is b
... False
# 改变了一方,另一方关我卵事
a = [1, 2, 3] b = [1, 2, 3]
>>> b.append(4)
>>> a
... [1, 2, 3]
>>> a.append(5)
>>> b
... [1, 2, 3, 4]3.拷贝可变对象(多层结构):产生新的对象,开辟新的内存空间,不改变包含的子对象则互不影响、改变包含的子对象则互相影响。
>>> import copy
>>> a = [1, 2, [3, 4]]
>>> b = copy.copy(a)
>>> b
... [1, 2, [3, 4]]
# 查看两者的内存地址,不同,开辟了新的内存空间
>>> id(b)
1833997596488
>>> id(a)
1833997596424
>>> a is b
... False
# 1.没有对包含的子对象进行修改,另一方关我卵事
a = [1, 2, [3, 4]] b = [1, 2, [3, 4]]
>>> b.append(5)
>>> a
... [1, 2, [3, 4]]
>>> a.append(6)
>>> b
... [1, 2, [3, 4], 5]
# 2.对包含的子对象进行修改,另一方也随之改变
a = [1, 2, [3, 4]] b = [1, 2, [3, 4]]
>>> b[2].append(5)
>>> a
... [1, 2, [3, 4, 5]]
>>> a[2].append(6)
>>> b
... [1, 2, [3, 4, 5, 6]]4.请谈谈Python中对内存是怎么管理的
内存管理也是一道经典的高频面试题,使用一门语言,如果不了解它的内存管理机制,显然有点说不过去,后期涉及代码性能优化方面可能会力不从心。
Python有一个私有堆空间来保存所有的对象和数据结构。作为开发者,我们无法访问它,是解释器在管理它。但是有了核心API后,我们可以访问一些工具。Python内存管理器控制内存分配。
另外,内置垃圾回收器会回收使用所有的未使用内存,所以使其适用于堆空间。
一、垃圾回收:python不像C++,Java等语言一样,他们可以不用事先声明变量类型而直接对变量进行赋值。对Python语言来讲,对象的类型和内存都是在运行时确定的。这也是为什么我们称Python语言为动态类型的原因(这里我们把动态类型可以简单的归结为对变量内存地址的分配是在运行时自动判断变量类型并对变量进行赋值)。
二、引用计数:Python采用了类似Windows内核对象一样的方式来对内存进行管理。每一个对象,都维护这一个对指向该对对象的引用的计数。当变量被绑定在一个对象上的时候,该变量的引用计数就是1,(还有另外一些情况也会导致变量引用计数的增加),系统会自动维护这些标签,并定时扫描,当某标签的引用计数变为0的时候,该对就会被回收。
一个对象, 会记录着自身被引用的个数 每增加一个引用, 这个对象的引用计数会自动+1 每减少一个引用, 这个对象的引用计数会自动-1
引用计数+1场景
1、对象被创建
p1 = Person()
2、对象被引用
p2 = p1
3、对象被作为参数,传入到一个函数中
log(p1)
这里注意会+2, 因为内部有两个属性引用着这个参数
4、对象作为一个元素,存储在容器中
l = [p1]引用计数-1场景
1、对象的别名被显式销毁
del p1
2、对象的别名被赋予新的对象
p1 = 123
3、一个对象离开它的作用域
一个函数执行完毕时
内部的局部变量关联的对象, 它的引用计数就会-1
4、对象所在的容器被销毁,或从容器中删除对象查看引用计数
import sys
class Person:
pass
p1 = Person() # 1
print(sys.getrefcount(p1)) # 2
p2 = p1 # 2
print(sys.getrefcount(p1)) # 3
del p2 # 1
print(sys.getrefcount(p1)) # 2
del p1
# print(sys.getrefcount(p1)) #error,因为上一行代码执行类p1对象已经销毁
>>>> 打印结果
2
3
2关于对象间互相引用,导致对象不能通过引用计数器进行销毁手动触发垃圾回收,挥手循环引用问题
import objgraph
import gc
class Person:
pass
class Dog:
pass
p = Person()
d = Dog()
p.pet = d
d.master = p
del p
del d
gc.collect() #手动触发垃圾回收
print(objgraph.count("Person"))
print(objgraph.count("Dog"))
>>>> 打印结果
0
05.请谈谈web框架Django和Flask的区别
类似这种开放性问题,可以根据自己的认知简要回答:
1.Django走的是大而全的方向,开发效率高。它的MTV框架,自带的ORM,admin后台管理,自带的sqlite数据库和开发测试用的服务器 给开发者提高了超高的开发效率
2.Flask是轻量级的框架,自由,灵活,可扩展性很强,核心基于Werkzeug WSGI工具和jinja2模板引擎
但是这样的回答还远远不够,需要一个生动形象的例子来彰显理解的深度,可以说Flask就像是小轿车,可以自由驰骋,不受限制,也可以随时更换轮胎,进行改装这就和可扩展性强对应了起来。
而Django则更像是一列火车,火车虽然只能依托铁轨而前行,行进路线相对死板,但是火车内有各种自带服务,比如卫生间、餐饮、卧铺等等,这就对应了orm,admin等内置模块,不需要自己造轮子,但是必须按照框架规定的方式来进行,多多少少失去了自由性。
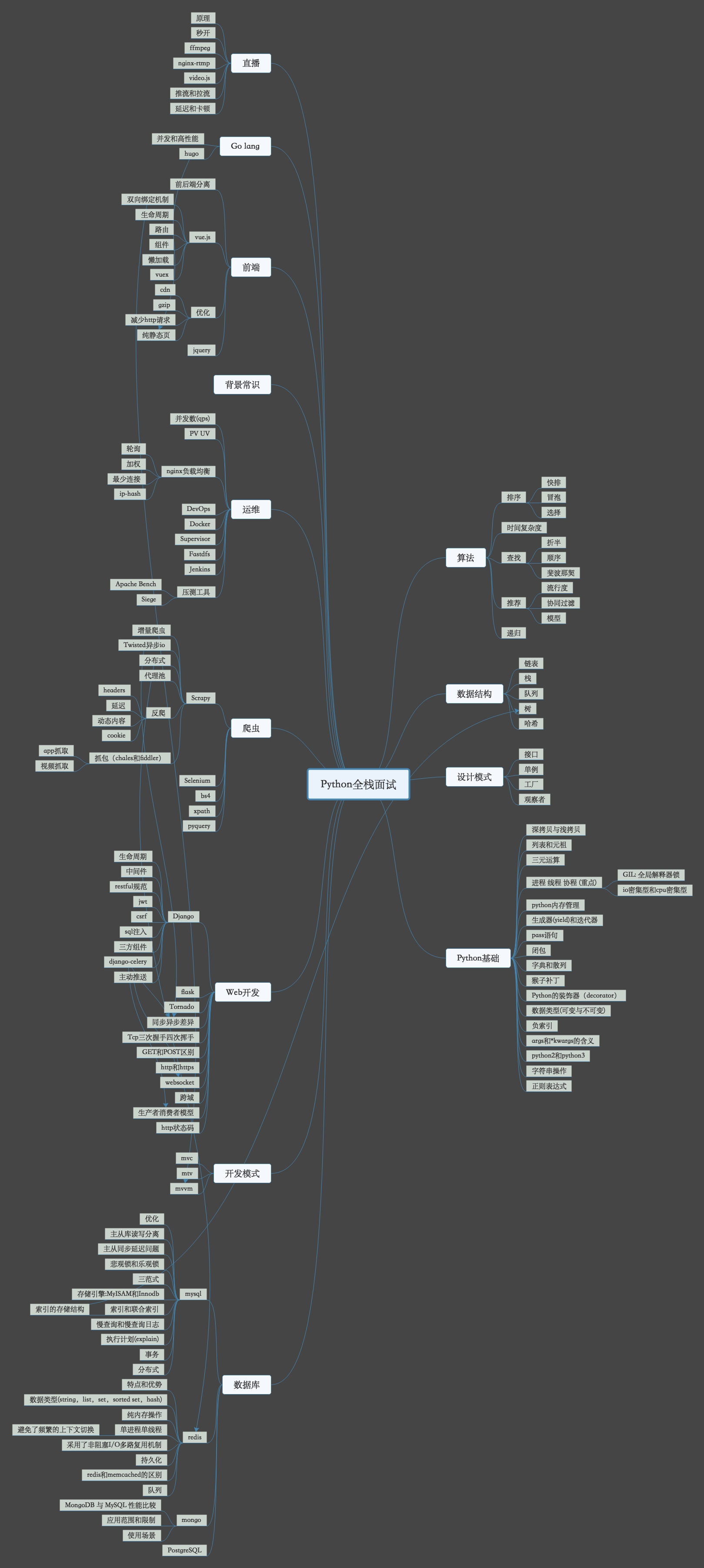
总体来看,文思海辉的面试相对还是偏基础,并没有算法结合场景的复杂问题,同时也没有市面上很火的leetcode原题,所以拿offer的几率肯定要比一线大厂要高,但是话说回来,如果拿到了外包公司的offer也不要只着眼于眼前,还是要继续努力和精进,争取一个去大厂的机会,最后附上一个Python全栈的知识体系结构图
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK