

谷歌大模型团队并入DeepMind,誓要赶上ChatGPT进度
source link: https://www.36kr.com/p/2148449546340872
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

为应对ChatGPT,谷歌在大模型方面的动作还在继续。
最新消息,其旗下专注语言大模型领域的“蓝移团队”(Blueshift Team)宣布,正式加入DeepMind,旨在共同提升LLM能力!

DeepMind科学家们在推特下面“列队欢迎”,好不热闹~
蓝移团队隶属于谷歌研究,和谷歌大脑实验室同等级。
之前谷歌耗时2年发布的大模型新基准BIG-Bench,就有该团队的重要贡献。
还有谷歌5400亿大模型PaLM,背后也有蓝移团队成员提供建议。
综合此前消息,DeepMind表示要在今年发布聊天机器人麻雀(Sparrow)内测版本。
如今又有擅长大模型研究的团队加入,强强联手,或许会加快谷歌应对ChatGPT的脚步?
这下有好戏看了。
蓝移团队是谁?
据官网介绍,蓝移团队主要关注的研究点是如何理解和改进大语言模型的能力。
他们专注于了解Transformer的局限性,并挑战将其能力扩展到解决数学、科学、编程、算法和规划等领域。
具体可分为如下几方面分支。
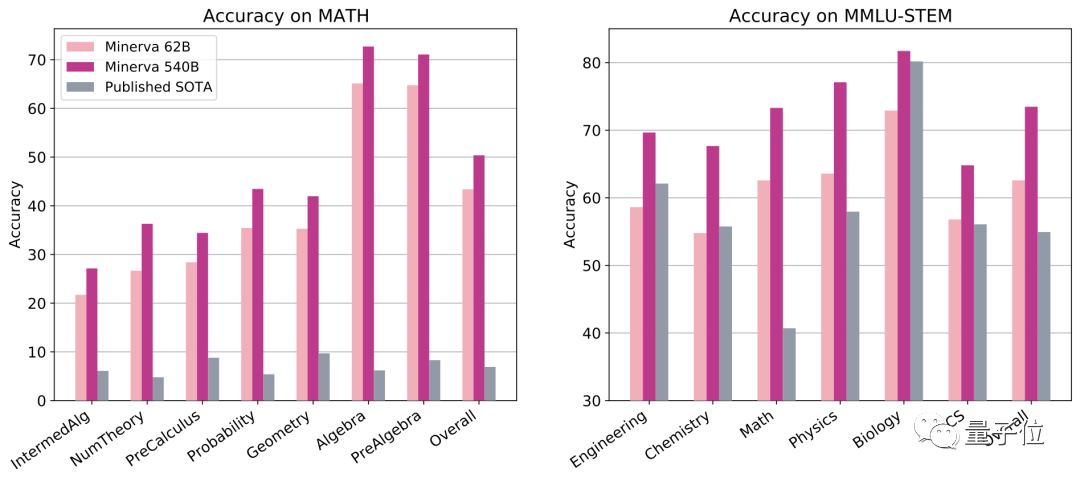
团队的代表性工作有数学做题模型Minerva。
它曾参加数学竞赛考试MATH,得分超过计算机博士水平。
综合了数理化生、电子工程和计算机科学的综合考试MMLU-STEM,它的分数比以往AI高了20分左右。
并且它的做题方法也是理科式的,基于谷歌5400亿参数大模型PaLM,Minerva狂读论文和LaTeX公式后,可可以按照理解自然语言的方式理解数学符号。
作者透露,让该模型参加波兰的数学高考,成绩都超过了全国平均分数。

还有蓝移团队曾和MIT的科学家一起,通过训练大模型学会程序员debug时“打断点”的方式,就能让模型读代码的能力大幅提升。

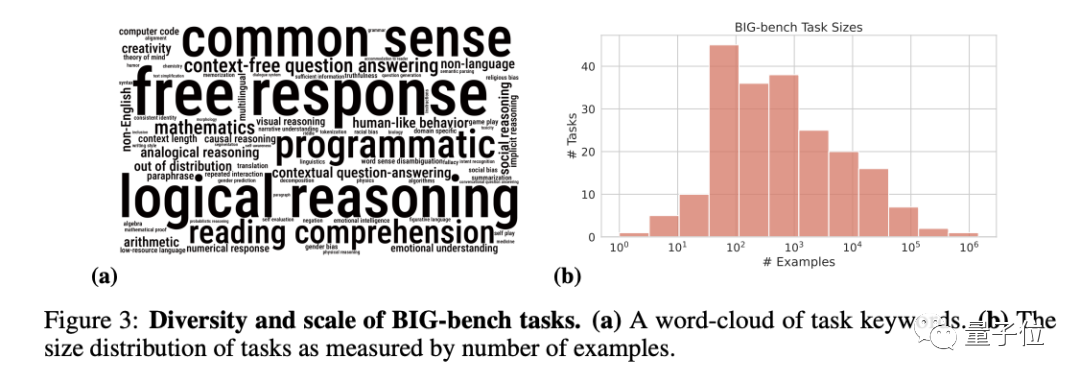
还有谷歌耗时2年发布的大模型新基准BIG-Bench,蓝移团队全部成员均参与了这项工作。
BIG-bench由204个任务组成,内容涵盖语言学、儿童发展、数学、常识推理、生物学、物理学、社会偏见、软件开发等方面的问题。
以及如上提到的谷歌大模型PaLM,蓝移团队成员Ethan S Dyer也贡献了建议。
官网显示,蓝移团队目前有4位主要成员。
Behnam Neyshabur现在是DeepMind的高级研究员。他在丰田工业大学(芝加哥)攻读了计算机博士学位,后来在纽约大学进行博士后工作,同时是普林斯顿大学高等研究理论机器学习项目组的成员。

研究领域是大语言模型的推理和算法能力、深度学习和泛化等。
Vinay Ramasesh在加州大学伯克利分校获得物理学博士学位,曾致力于研究基于超导量子比特的量子处理器,硕士毕业于麻省理工学院。

最近他主要在研究语言模型,职位是研究科学家。
Ethan Dyer博士毕业于麻省理工学院,2018年加入谷歌工作至今。

Anders Johan Andreassen同样是物理专业出身,博士毕业于哈佛大学。在哈佛大学、加州大学伯克利分校都做过博士后,2019年起加入谷歌。

谷歌还有多少后手?
这次蓝移团队的调动,也不免让外界猜测是否是谷歌为应对ChatGPT的最新举措。
ChatGPT引爆大模型趋势后,谷歌几乎是最先打响“阻击战”的大厂。
尽管加急发布的Bard效果确实有失水准,但这并不意味着谷歌会就此丧失竞争力。
诚如OpenAI之于微软,谷歌也有DeepMind。
DeepMind还是上一轮AI浪潮的引爆者。
消息显示,DeepMind手里也有聊天机器人。
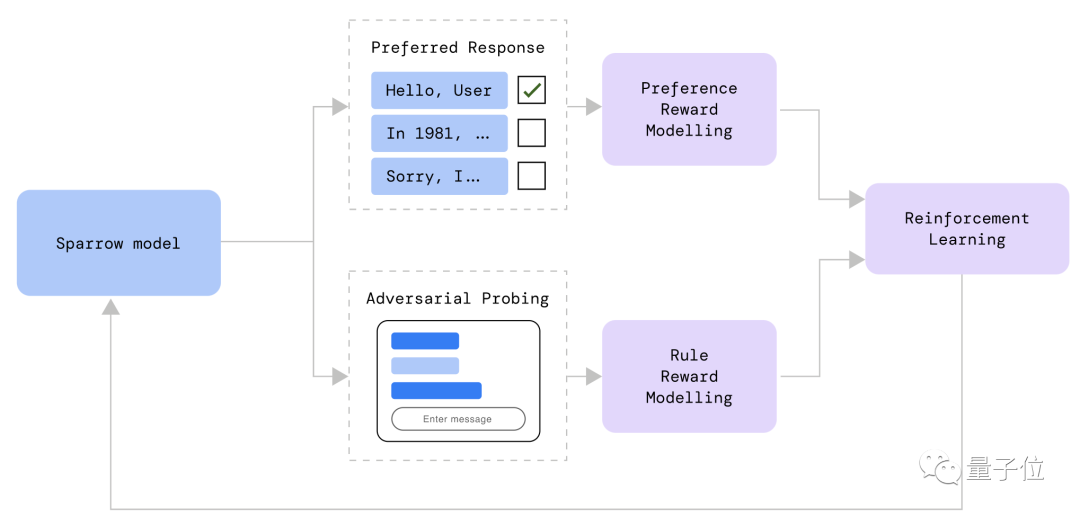
去年9月,他们介绍了一个对话AI麻雀(Sparrow),它的原理同样是基于人类反馈的强化学习,能够依据人类偏好训练模型。
DeepMind创始人兼CEO哈萨比在今年早些时候说,麻雀的内测版本将在2023年发布。
他表示,他们将会“谨慎地”发布模型,以实现模型可以开发强化学习功能,比如引用资料等——这是ChatGPT不具备的功能。
但具体的发布时间还没有透露。
蓝移团队的加入公告中提到,他们是为了加速提升DeepMind乃至谷歌的LLM能力,不知这一动向是否会加速该对话模型的发布。
与此同时,谷歌也没有把目光完全局限在自家开发能力上。
本月初,劈柴哥重磅宣布,斥资3亿美元,紧急投资ChatGPT竞品公司Anthropic——由GPT-3核心成员出走创办。
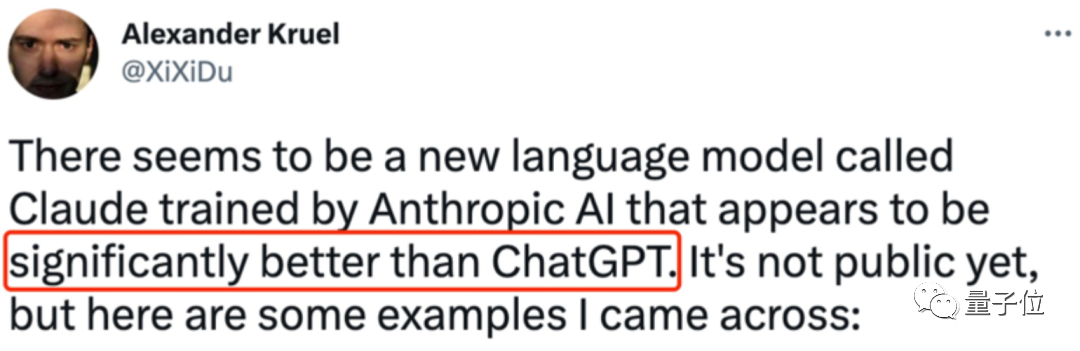
1月底,该公司内测聊天机器人Claude,
这是一个超过520亿参数的大模型,自称基于前沿NLP和AI安全技术打造。
它同ChatGPT一样,靠强化学习(RL)来训练偏好模型,并进行后续微调。
但又与ChatGPT采用的人类反馈强化学习(RLHF)不同,Claude训练时,采用了基于偏好模型而非人工反馈的原发人工智能方法(Constitutional AI),这种方法又被称为AI反馈强化学习(RLAIF)。
如今,Claude尚未作为商业产品正式发布,但已有人(如全网第一个提示工程师Riley Goodside)拿到了内测资格。有人说效果比ChatGPT要好。
目前,这家公司的最新估值已经达到50亿美元。
总而言之,谷歌虽然在Bard上栽了跟头,但也没把鸡蛋放在一个篮子里。接下来它在大模型上还有哪些新动作?还很有看头。
参考链接:[1]https://twitter.com/bneyshabur/status/1629150056715816962[2]https://research.google/teams/blueshift/[3]https://www.deepmind.com/blog/building-safer-dialogue-agents
— 完 —
本文来自微信公众号“量子位”(ID:QbitAI),作者:关注前沿科技,36氪经授权发布。
该文观点仅代表作者本人,36氪平台仅提供信息存储空间服务。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK