

Transcribing recorded audio and video to text using Whisper AI on a Mac
source link: https://www.jeffgeerling.com/blog/2023/transcribing-recorded-audio-and-video-text-using-whisper-ai-on-mac
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Transcribing recorded audio and video to text using Whisper AI on a Mac
February 15, 2023
Late last year, OpenAI announced Whisper, a new speech-to-text language model that is extremely accurate in translating many spoken languages into text. The whisper repository contains instructions for installation and use.
tl;dr:
# Install whisper and its dependencies.
pip3 install git+https://github.com/openai/whisper.git
# (When needed) Update whisper.
pip3 install --upgrade --no-deps --force-reinstall git+https://github.com/openai/whisper.git
# Make sure ffmpeg is installed.
brew install ffmpeg
# Translate speech into text.
whisper my_audio_file.mp3 --language English
One thing I do quite regularly for my YouTube channel is extract the audio track, convert it to text using an online tool (I used to use Welder until they were bought out by Veed), and then hand-edit the file to fix references to product names, people, etc.
Then I upload either an edited .txt or .srt file alongside my video on YouTube, and people are able to use Closed Captions. YouTube shows whether a video has manually-curated captions with this handy little 'CC' icon:
But as Veed's free tier only allows up to 10 minutes of audio to be transcribed at a time, it was time to look elsewhere. And on my earlier blog post about using macOS's built-in Dictation feature for transcription, rasmi commented that a new tool was available, Whisper.
So I took it for a spin!
I installed it and ran it on one of my video's audio tracks using the commands at the top of this post, and I was pleasantly surprised:
- Experimenting with the different models,
base.enwas very fast for English, but I found thatsmallormediumwere much better at identifying product names, obscure technical terms, etc. Honestly it blew me away that it picked up words like 'PlinkUSA', 'Sliger', and 'Raspberry Pi'—something other transcription tools would trip on. - You can even translate text files (using
--translate), which is a neat trick. It will automatically identify the source language, or you can specify it with--language). - It's not quite perfect yet—I still need to touch up probably one word every 10 sentences. But it's a thousand times easier than trying to transcribe things manually! And it even does punctuation and outputs an .srt natively.
I've been scanning through discussions and there are already some great ones about features like diarization (being able to identify multiple speakers in a conversation) and performance benchmarking.
On my Mac Studio's CPU, the conversion process is only a little slower than real-time. I haven't yet tested it on my PC with a beefier GPU, but I plan on testing that soon.
Being fairly new, specific UIs for Whisper aren't mature yet... but I did find things like whisper-ui, and there's even a Hugging Face webapp Whisper Webui you can use for up to 10 minutes of audio transcription to get a feel for it.
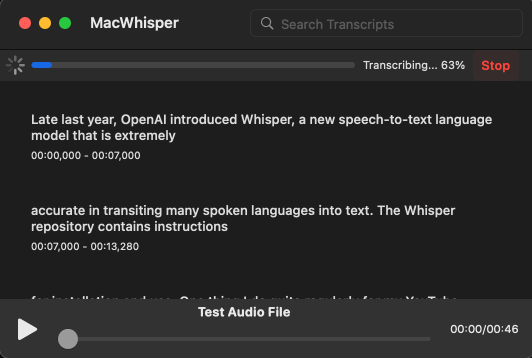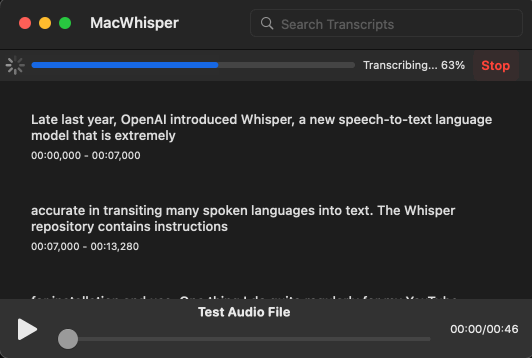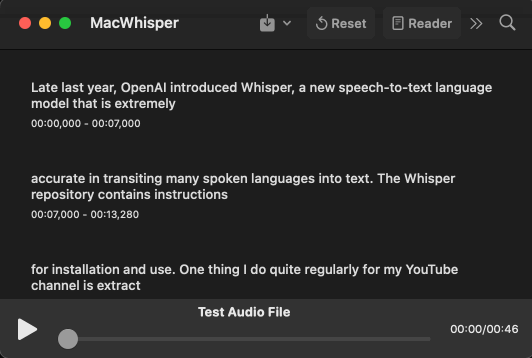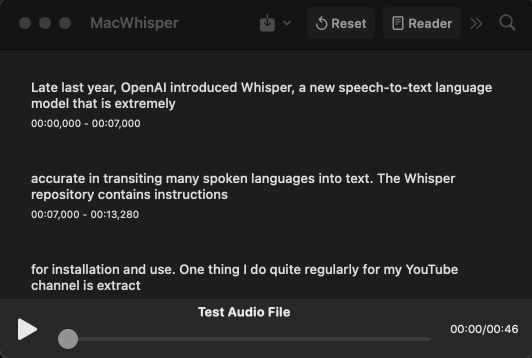
And on macOS, if the command line isn't your thing, Jordi Bruin created an app MacWhisper, which is free for the standard version and includes a UI for editing the transcription live:
Hopefully more UIs are developed, especially something I could toss on one of my PCs here, so I could quickly throw an audio file at it from any device.
I'm generally a bit conservative when it comes at throwing AI at a problem, but speech to text (and vice-versa) is probably one of the most cut-and-dry uses that makes sense and doesn't carry a number of footguns.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK