

分布式机器学习:异步SGD和Hogwild!算法(Pytorch) - orion-orion
source link: https://www.cnblogs.com/orion-orion/p/17118029.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

我们在博客《分布式机器学习:同步并行SGD算法的实现与复杂度分析(PySpark)》和博客《分布式机器学习:模型平均MA与弹性平均EASGD(PySpark) 》中介绍的都是同步算法。同步算法的共性是所有的节点会以一定的频率进行全局同步。然而,当工作节点的计算性能存在差异,或者某些工作节点无法正常工作(比如死机)的时候,分布式系统的整体运行效率不好,甚至无法完成训练任务。为了解决此问题,人们提出了异步的并行算法。在异步的通信模式下,各个工作节点不需要互相等待,而是以一个或多个全局服务器做为中介,实现对全局模型的更新和读取。这样可以显著减少通信时间,从而获得更好的多机扩展性。
2 异步SGD
2.1 算法描述与实现
异步SGD[9]是最基础的异步算法,其流畅如下图所示。粗略地讲,ASGD的参数更新发生在工作节点,而模型的更新发生在服务器端。当参数服务器接收到来自某个工作节点的参数梯度时,就直接将其加到全局模型上,而无需等待其它工作节点的梯度信息。

下面我们用Pytorch实现的训练代码(采用RPC进行进程间通信)。首先,我们设置初始化多个进程,其中0号进程做为参数服务器,其余进程做为worker来对模型进行训练,则总的通信域(world_size)大小为workers的数量+1。这里我们设置参数服务器IP地址为localhost,端口号29500。
def run(rank, world_size):
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '29500'
options=rpc.TensorPipeRpcBackendOptions(
num_worker_threads=16,
rpc_timeout=0 # infinite timeout
)
if rank == 0:
rpc.init_rpc(
"ps",
rank=rank,
world_size=world_size,
rpc_backend_options=options
)
run_ps([f"trainer{r}" for r in range(1, world_size)])
else:
rpc.init_rpc(
f"trainer{rank}",
rank=rank,
world_size=world_size,
rpc_backend_options=options
)
# trainer passively waiting for ps to kick off training iterations
# block until all rpcs finish
rpc.shutdown()
if __name__=="__main__":
world_size = n_workers + 1
mp.spawn(run, args=(world_size, ), nprocs=world_size, join=True)
下面我们定义参数服务器的所要完成工作流程,包括将训练数据划分到各个worker,异步调用所有worker的训练流程,最后训练完毕后在参数服务器完成对模型的评估。
def run_trainer(ps_rref, train_dataset):
trainer = Trainer(ps_rref)
trainer.train(train_dataset)
def run_ps(trainers):
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
train_dataset = datasets.MNIST('./data', train=True, download=True,
transform=transform)
local_train_datasets = dataset_split(train_dataset, n_workers)
print(f"{datetime.now().strftime('%H:%M:%S')} Start training")
ps = ParameterServer()
ps_rref = rpc.RRef(ps)
futs = []
for idx, trainer in enumerate(trainers):
futs.append(
rpc.rpc_async(trainer, run_trainer, args=(ps_rref, local_train_datasets[idx]))
)
torch.futures.wait_all(futs)
print(f"{datetime.now().strftime('%H:%M:%S')} Finish training")
ps.evaluation()
这里数据集的划分代码采用我们在《Pytorch:单卡多进程并行训练》中所述的数据划分方式:
class CustomSubset(Subset):
'''A custom subset class with customizable data transformation'''
def __init__(self, dataset, indices, subset_transform=None):
super().__init__(dataset, indices)
self.subset_transform = subset_transform
def __getitem__(self, idx):
x, y = self.dataset[self.indices[idx]]
if self.subset_transform:
x = self.subset_transform(x)
return x, y
def __len__(self):
return len(self.indices)
def dataset_split(dataset, n_workers):
n_samples = len(dataset)
n_sample_per_workers = n_samples // n_workers
local_datasets = []
for w_id in range(n_workers):
if w_id < n_workers - 1:
local_datasets.append(CustomSubset(dataset, range(w_id * n_sample_per_workers, (w_id + 1) * n_sample_per_workers)))
else:
local_datasets.append(CustomSubset(dataset, range(w_id * n_sample_per_workers, n_samples)))
return local_datasets
以下是参数服务器类ParameterServer的定义:
class ParameterServer(object):
def __init__(self, n_workers=n_workers):
self.model = Net().to(device)
self.lock = threading.Lock()
self.future_model = torch.futures.Future()
self.n_workers = n_workers
self.curr_update_size = 0
self.optimizer = optim.SGD(self.model.parameters(), lr=0.001, momentum=0.9)
for p in self.model.parameters():
p.grad = torch.zeros_like(p)
self.test_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=False,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=32, shuffle=True)
def get_model(self):
# TensorPipe RPC backend only supports CPU tensors,
# so we move your tensors to CPU before sending them over RPC
return self.model.to("cpu")
@staticmethod
@rpc.functions.async_execution
def update_and_fetch_model(ps_rref, grads):
self = ps_rref.local_value()
for p, g in zip(self.model.parameters(), grads):
p.grad += g
with self.lock:
self.curr_update_size += 1
fut = self.future_model
if self.curr_update_size >= self.n_workers:
for p in self.model.parameters():
p.grad /= self.n_workers
self.curr_update_size = 0
self.optimizer.step()
self.optimizer.zero_grad()
fut.set_result(self.model)
self.future_model = torch.futures.Future()
return fut
def evaluation(self):
self.model.eval()
self.model = self.model.to(device)
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in self.test_loader:
output = self.model(data.to(device))
test_loss += F.nll_loss(output, target.to(device), reduction='sum').item() # sum up batch loss
pred = output.max(1)[1] # get the index of the max log-probability
correct += pred.eq(target.to(device)).sum().item()
test_loss /= len(self.test_loader.dataset)
print('\nTest result - Accuracy: {}/{} ({:.0f}%)\n'.format(
correct, len(self.test_loader.dataset), 100. * correct / len(self.test_loader.dataset)))
以下是Trainer类的定义:
class Trainer(object):
def __init__(self, ps_rref):
self.ps_rref = ps_rref
self.model = Net().to(device)
def train(self, train_dataset):
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
model = self.ps_rref.rpc_sync().get_model().cuda()
pid = os.getpid()
for epoch in range(epochs):
for batch_idx, (data, target) in enumerate(train_loader):
output = model(data.to(device))
loss = F.nll_loss(output, target.to(device))
loss.backward()
model = rpc.rpc_sync(
self.ps_rref.owner(),
ParameterServer.update_and_fetch_model,
args=(self.ps_rref, [p.grad for p in model.cpu().parameters()]),
).cuda()
if batch_idx % log_interval == 0:
print('{}\tTrain Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
pid, epoch + 1, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
完整代码我已经上传到了GitHub仓库 [Distributed-Algorithm-PySpark],感兴趣的童鞋可以前往查看。
运行该代码得到的评估结果为:
Test result - Accuracy: 9696/10000 (97%)
可见该训练算法是收敛的,但在10个epoch下在测试集上只能达到97%的精度,不如我们下面提到的在10个epoch就能在测试集上达到99%精度的Hogwild!算法。注意,ASGD和Hogwild都是异步算法,但ASGD是分布式算法(当然我们这里是单机多进程模拟),进程间采用RPC通信,不会出现同步错误的问题,根本不需要考虑加不加锁。而Hogwild!算法是单机算法,进程/线程间采用共享内存通信,需要考虑加不加锁的问题,不过Hogwild!算法为了提高训练过程中的数据吞吐量,直接采用了无锁的全局内存访问。
2.2 收敛性分析
ASGD避开了同步开销,但会给模型更新增加一些延迟。我们下面将ASGD的工作流程用下图加以剖析来解释这一点。用worker(k)worker(k)来代表第kk个工作节点,用wtwt来代表第tt轮迭代时服务端的全局模型。按照时间顺序,首先worker(k)worker(k)先从参数服务器获取全局模型wtwt,再根据本地数据计算模型梯度g(wt)g(wt)并将其发往参数服务器。一段时间后,worker(k′)worker(k′)也从参数服务器取回当时的全局模型wt+1wt+1,并同样依据它的本地数据计算模型的梯度f(wt+1)f(wt+1)。注意,在worker(k′)worker(k′)取回参数并进行计算的过程中,其它工作节点(比如worker(k)worker(k))可能已经将它的梯度提交给服务器并进行更新了。所以当worker(k′)worker(k′)将其梯度g(wt+1)g(wt+1)发给服务器时,全局模型已经不再是wt+1wt+1,而已经是被更新过的版本。
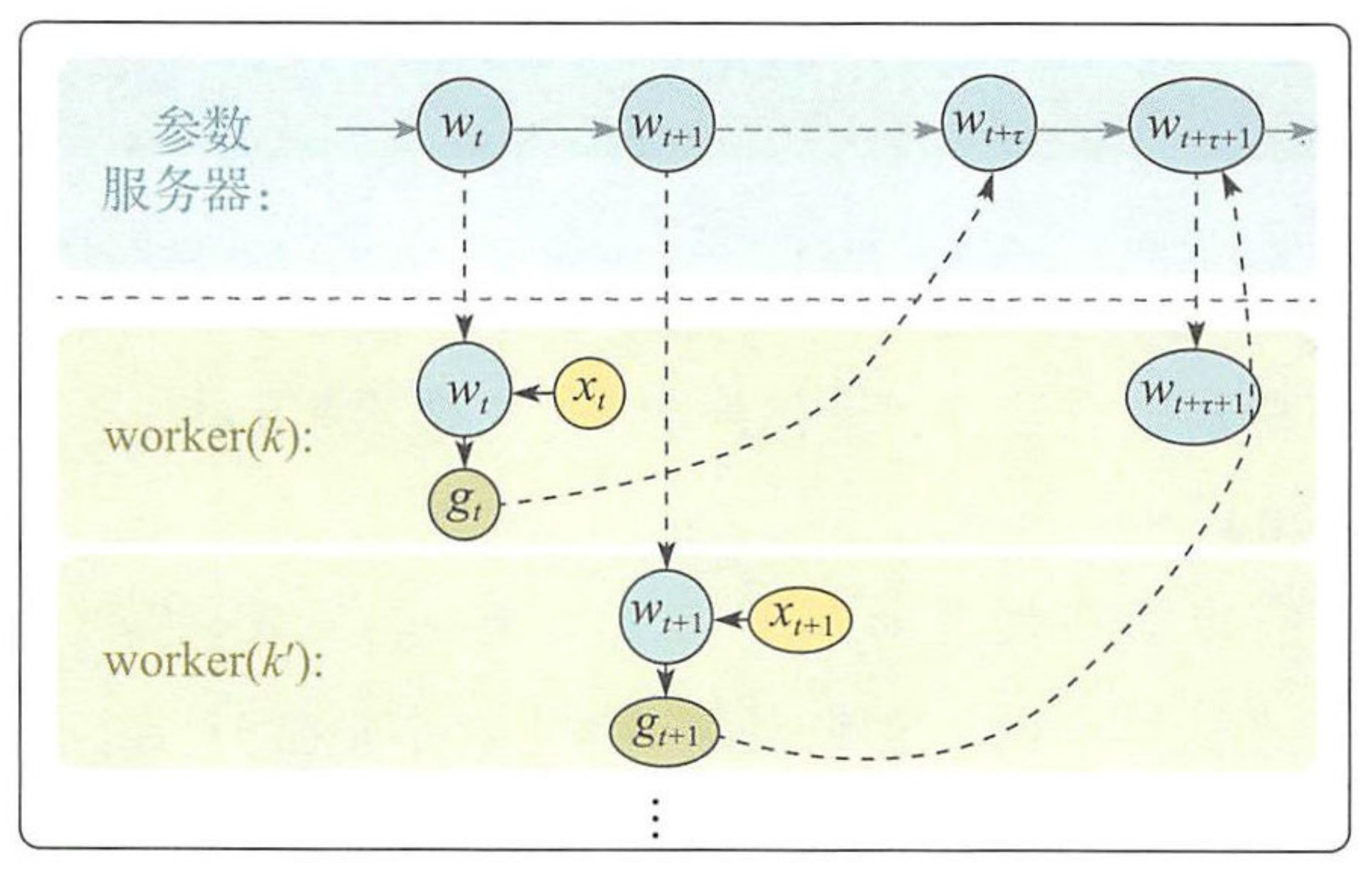
我们将上面这种现象称为梯度和模型的失配,也即我们用一个比较旧的参数计算了梯度,而将这个“延迟”的梯度更新到了模型参数上。这种延迟使得ASGD和SGD之间在参数更新规则上存在偏差,可能导致模型在某些特定的更新点上出现严重抖动,设置优化过程出错,无法收敛。后面我们会介绍克服延迟问题的手段。
3 Hogwild!算法
3.1 算法描述与实现
异步并行算法既可以在多机集群上开展,也可以在多核系统下通过多线程开展。当我们把ASGD算法应用在多线程环境中时,因为不再有参数服务器这一角色,算法的细节会发生一些变化。特别地,因为全局模型存储在共享内存中,所以当异步的模型更新发生时,我们需要讨论是否将内存加锁,以保证模型写入的一致性。
Hogwild!算法[2]为了提高训练过程中的数据吞吐量,选择了无锁的全局模型访问,其工作逻辑如下所示:

这里使用我们在《Pytorch:单卡多进程并行训练》所提到的torch.multiprocessing来进行多进程并行训练。多进程原本内存空间是独立的,这里我们显式调用model.share_memory()来讲模型设置在共享内存中以进行进程间通信。不过注意,如果我们采用GPU训练,则GPU直接就做为了多进程的共享内存,此时model.share_memory()实际上为空操作(no-op)。
我们用Pytorch实现的训练代码如下:
from __future__ import print_function
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.multiprocessing as mp
from torchvision import datasets, transforms
import os
import torch
import torch.optim as optim
import torch.nn.functional as F
batch_size = 64 # input batch size for training
test_batch_size = 1000 # input batch size for testing
epochs = 10 # number of global epochs to train
lr = 0.01 # learning rate
momentum = 0.5 # SGD momentum
seed = 1 # random seed
log_interval = 10 # how many batches to wait before logging training status
n_workers = 4 # how many training processes to use
cuda = True # enables CUDA training
mps = False # enables macOS GPU training
dry_run = False # quickly check a single pass
def train(rank, model, device, dataset, dataloader_kwargs):
torch.manual_seed(seed + rank)
train_loader = torch.utils.data.DataLoader(dataset, **dataloader_kwargs)
optimizer = optim.SGD(model.parameters(), lr=lr, momentum=momentum)
for epoch in range(1, epochs + 1):
model.train()
pid = os.getpid()
for batch_idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad()
output = model(data.to(device))
loss = F.nll_loss(output, target.to(device))
loss.backward()
optimizer.step()
if batch_idx % log_interval == 0:
print('{}\tTrain Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
pid, epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
if dry_run:
break
def test(model, device, dataset, dataloader_kwargs):
torch.manual_seed(seed)
test_loader = torch.utils.data.DataLoader(dataset, **dataloader_kwargs)
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
output = model(data.to(device))
test_loss += F.nll_loss(output, target.to(device), reduction='sum').item() # sum up batch loss
pred = output.max(1)[1] # get the index of the max log-probability
correct += pred.eq(target.to(device)).sum().item()
test_loss /= len(test_loader.dataset)
print('\nTest set: Global loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
return F.log_softmax(x, dim=1)
if __name__ == '__main__':
use_cuda = cuda and torch.cuda.is_available()
use_mps = mps and torch.backends.mps.is_available()
if use_cuda:
device = torch.device("cuda")
elif use_mps:
device = torch.device("mps")
else:
device = torch.device("cpu")
print(device)
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
train_dataset = datasets.MNIST('../data', train=True, download=True,
transform=transform)
test_dataset = datasets.MNIST('../data', train=False,
transform=transform)
kwargs = {'batch_size': batch_size,
'shuffle': True}
if use_cuda:
kwargs.update({'num_workers': 1,
'pin_memory': True,
})
torch.manual_seed(seed)
mp.set_start_method('spawn', force=True)
model = Net().to(device)
model.share_memory() # gradients are allocated lazily, so they are not shared here
processes = []
for rank in range(n_workers):
p = mp.Process(target=train, args=(rank, model, device,
train_dataset, kwargs))
# We first train the model across `n_workers` processes
p.start()
processes.append(p)
for p in processes:
p.join()
# Once training is complete, we can test the model
test(model, device, test_dataset, kwargs)
运行得到的评估结果为:
Test set: Global loss: 0.0325, Accuracy: 9898/10000 (99%)
可见该训练算法是收敛的。
3.2 收敛性分析
当采用不带锁的多线程的写入(即在更新wjwj的时候不用先获取对wjwj的访问权限),而这可能会导致导致同步错误[10]的问题。比如在线程11加载全局参数wtjwjt之后,线程22还没等线程11存储全局参数更新后的值,就也对全局参数wtjwjt进行加载,这样导致每个线程都会存储值为wtj−ηtg(wtj)wjt−ηtg(wjt)的更新后的全局参数值,这样就导致其中一个线程的更新实际上在做“无用功”。直观的感觉是这应该会对学习的过程产生负面影响。不过,当我们对模型访问的稀疏性(sparity)做一定的限定后,这种访问冲突实际上是非常有限的。这正是Hogwild!算法收敛性存在的理论依据。
假设我们要最小化的损失函数为l:W→Rl:W→R,对于特定的训练样本集合,损失函数ll是由一系列稀疏子函数组合而来的:
也就是说,实际的学习过程中,每个训练样本涉及的参数组合ee只是全体参数集合中的一个很小的子集。我们可以用一个超图G=(V,E)G=(V,E)来表述这个学习过程中参数和参数之间的关系,其中节点vv表示参数,而超边ee表示训练样本涉及的参数组合。那么,稀疏性可以用下面几个统计量加以表示:
其中,ΩΩ表达了最大超边的大小,也就是单个样本最多涉及的参数个数;ΔΔ反映的是一个参数最多可以涉及多少个不同的超边;而ρρ则反映了给定任意一个超边,与其共享参数的超边个数。这三个值的取值越小,则优化问题越稀疏。在ΩΩ、ΔΔ、ρρ都比较小的条件下,Hogwild!算法的收敛性保证还需要假设损失函数是凸函数,并且是Lipschitz连续的,详细的理论证明和定量关系请参考文献[2]。
-
[1] Agarwal A, Duchi J C. Distributed delayed stochastic optimization[J]. Advances in neural information processing systems, 2011, 24.
-
[2] Recht B, Re C, Wright S, et al. Hogwild!: A lock-free approach to parallelizing stochastic gradient descent[J]. Advances in neural information processing systems, 2011, 24.
-
[3] 刘浩洋,户将等. 最优化:建模、算法与理论[M]. 高教出版社, 2020.
-
[4] 刘铁岩,陈薇等. 分布式机器学习:算法、理论与实践[M]. 机械工业出版社, 2018.
-
[5] Stanford CME 323: Distributed Algorithms and Optimization (Lecture 7)
-
[6] Bryant R E等.《深入理解计算机系统》[M]. 机械工业出版社, 2015.
__EOF__
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK