

Get Started With Trino and Alluxio in Five Minutes
source link: https://dzone.com/articles/get-started-with-trino-and-alluxio-in-five-minutes
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Get Started With Trino and Alluxio in Five Minutes
Get started with deploying Alluxio as the caching layer for Trino and learn how to use Alluxio caching with the Iceberg connector and MinIO file storage.
Trino is an open-source distributed SQL query engine designed to query large data sets distributed over one or more heterogeneous data sources. Trino was designed to handle data warehousing, ETL, and interactive analytics by large amounts of data and producing reports.
Alluxio is an open-source data orchestration platform for large-scale analytics and AI. Alluxio sits between compute frameworks such as Trino and Apache Spark and various storage systems like Amazon S3, Google Cloud Storage, HDFS, and MinIO.
This is a tutorial for deploying Alluxio as the caching layer for Trino using the Iceberg connector.
Why Do We Need Caching for Trino?
A small fraction of the petabytes of data you store is generating business value at any given time. Repeatedly scanning the same data and transferring it over the network consumes time, compute cycles, and resources. This issue is compounded when pulling data from disparate Trino clusters across regions or clouds. In these circumstances, caching solutions can significantly reduce the latency and cost of your queries.
Trino has a built-in caching engine, Rubix, in its Hive connector. While this system is convenient as it comes with Trino, it is limited to the Hive connector and has not been maintained since 2020. It also lacks security features and support for additional compute engines.
Trino on Alluxio
Alluxio connects Trino to various storage systems, providing APIs and a unified namespace for data-driven applications. Alluxio allows Trino to access data regardless of the data source and transparently cache frequently accessed data (e.g., tables commonly used) into Alluxio distributed storage.
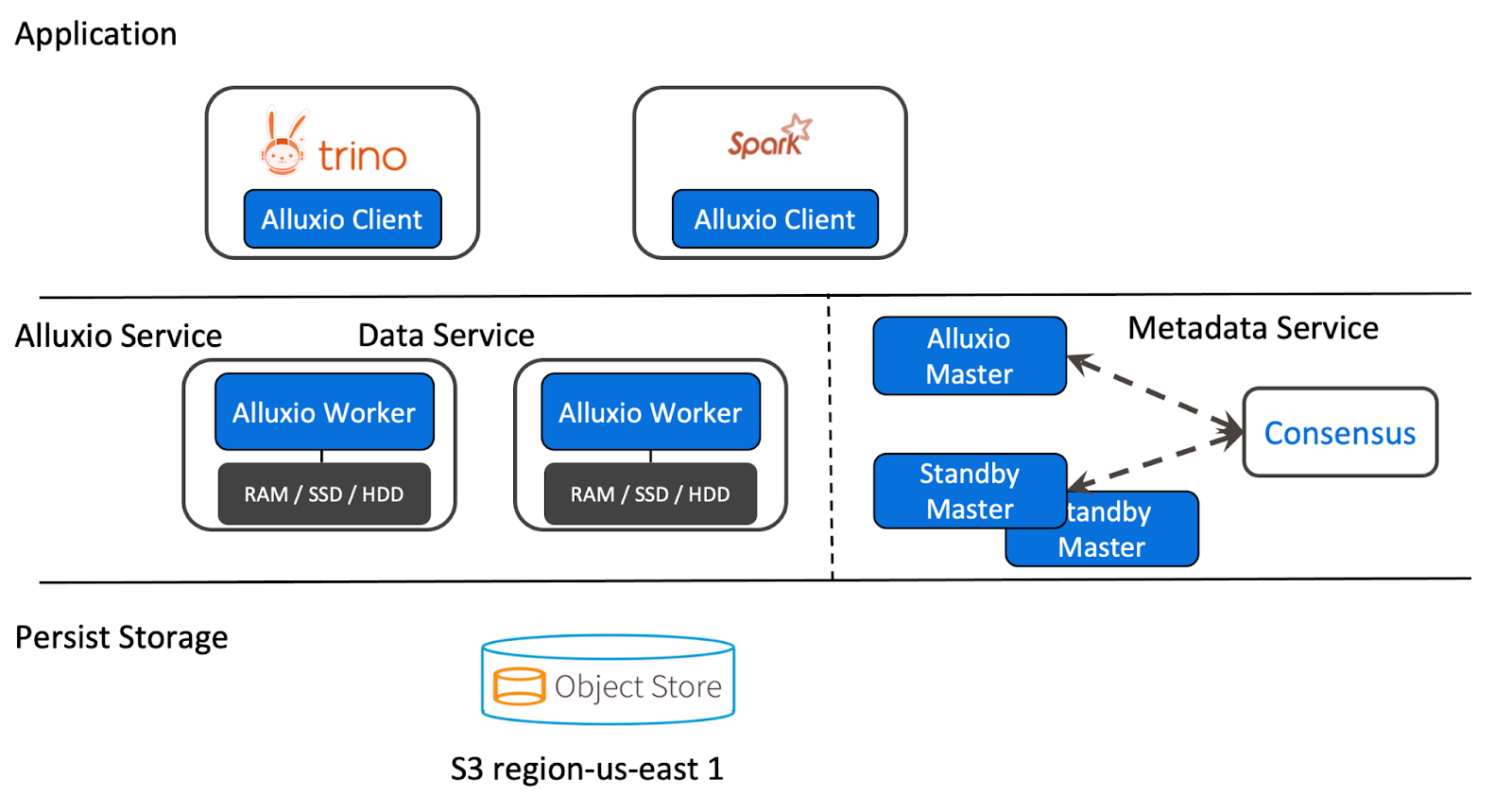
Using Alluxio Caching via the Iceberg Connector Over MinIO File Storage
We’ve created a demo that demonstrates how to configure Alluxio to use write-through caching with MinIO. This is achieved by using the Iceberg connector and making a single change to the location property on the table from the Trino perspective.
In this demo, Alluxio is run on separate servers; however, it’s recommended to run it on the same nodes as Trino. This means that all the configurations for Alluxio will be located on the servers where Alluxio runs, while Trino’s configuration remains unaffected. The advantage of running Alluxio externally is that it won’t compete for resources with Trino, but the disadvantage is that data will need to be transferred over the network when reading from Alluxio. It is crucial for performance that Trino and Alluxio are on the same network.
To follow this demo, copy the code located here.
Trino Configuration
Trino is configured identically to a standard Iceberg configuration. Since Alluxio is running external to Trino, the only configuration needed is at query time and not at startup.
Alluxio Configuration
The configuration for Alluxio can all be set using the alluxio-site.properties file. To keep all configurations colocated on the docker-compose.yml, we are setting them using Java properties via the ALLUXIO_JAVA_OPTS environment variable. This tutorial also refers to the master node as the leader and the workers as followers.
Master Configurations
alluxio.master.mount.table.root.ufs=s3://alluxio/The leader exposes ports 19998 and 19999, the latter being the port for the web UI.
Worker Configurations
alluxio.worker.ramdisk.size=1G
alluxio.worker.hostname=alluxio-followerThe follower exposes ports 29999 and 30000, and sets up a shared memory used by Alluxio to store data. This is set to 1G via the shm_size property and is referenced from the alluxio.worker.ramdisk.size property.
Shared Configurations Between Leader and Follower
alluxio.master.hostname=alluxio-leader
# Minio configs
alluxio.underfs.s3.endpoint=http://minio:9000
alluxio.underfs.s3.disable.dns.buckets=true
alluxio.underfs.s3.inherit.acl=false
aws.accessKeyId=minio
aws.secretKey=minio123
# Demo-only configs
alluxio.security.authorization.permission.enabled=falseThe alluxio.master.hostname needs to be on all nodes, leaders and followers. The majority of shared configs points Alluxio to the underfs, which is MinIO in this case.
alluxio.security.authorization.permission.enabled is set to “false” to keep the Docker setup simple.
Note: This is not recommended to do in a production or CI/CD environment.
Running Services
First, you want to start the services. Make sure you are in the trino-getting-started/iceberg/trino-alluxio-iceberg-minio directory. Now, run the following command:
docker-compose up -dYou should expect to see the following output. Docker may also have to download the Docker images before you see the “Created/Started” messages, so there could be extra output:
[+] Running 10/10
⠿ Network trino-alluxio-iceberg-minio_trino-network Created 0.0s
⠿ Volume "trino-alluxio-iceberg-minio_minio-data" Created 0.0s
⠿ Container trino-alluxio-iceberg-minio-mariadb-1 Started 0.6s
⠿ Container trino-alluxio-iceberg-minio-trino-coordinator-1 Started 0.7s
⠿ Container trino-alluxio-iceberg-minio-alluxio-leader-1 Started 0.9s
⠿ Container minio Started 0.8s
⠿ Container trino-alluxio-iceberg-minio-alluxio-follower-1 Started 1.5s
⠿ Container mc Started 1.4s
⠿ Container trino-alluxio-iceberg-minio-hive-metastore-1 StartedOpen Trino CLI
Once this is complete, you can log into the Trino coordinator node. We will do this by using the exec command and run the trino CLI executable as the command we run on that container. Notice the container id is trino-alluxio-iceberg-minio-trino-coordinator-1, so the command you will run is:
<<<<<<< HEAD
docker container exec -it trino-alluxio-iceberg-minio-trino-coordinator-1 trino
=======
docker container exec -it trino-minio_trino-coordinator_1 trino
>>>>>>> alluxioWhen you start this step, you should see the trino cursor once the startup is complete. It should look like this when it is done:
trino>To best understand how this configuration works, let’s create an Iceberg table using a CTAS (CREATE TABLE AS) query that pushes data from one of the TPC connectors into Iceberg that points to MinIO. The TPC connectors generate data on the fly so we can run simple tests like this.
First, run a command to show the catalogs to see the tpch and iceberg catalogs since these are what we will use in the CTAS query:
SHOW CATALOGS;You should see that the Iceberg catalog is registered.
MinIO Buckets and Trino Schemas
Upon startup, the following command is executed on an intiailization container that includes the mc CLI for MinIO. This creates a bucket in MinIO called /alluxio, which gives us a location to write our data to and we can tell Trino where to find it:
/bin/sh -c "
until (/usr/bin/mc config host add minio http://minio:9000 minio minio123) do echo '...waiting...' && sleep 1; done;
/usr/bin/mc rm -r --force minio/alluxio;
/usr/bin/mc mb minio/alluxio;
/usr/bin/mc policy set public minio/alluxio;
exit 0;
"Note: This bucket will act as the mount point for Alluxio, so the schema directory alluxio://lakehouse/ in Alluxio will map to s3://alluxio/lakehouse/.
Querying Trino
Let’s move to creating our SCHEMA that points us to the bucket in MinIO and then run our CTAS query. Back in the terminal, create the iceberg.lakehouse SCHEMA. This will be the first call to the metastore to save the location of the schema location in the Alluxio namespace. Notice, we will need to specify the hostname alluxio-leader and port 19998 since we did not set Alluxio as the default file system. Take this into consideration if you want Alluxio caching to be the default usage and transparent to users managing DDL statements:
CREATE SCHEMA iceberg.lakehouse
WITH (location = 'alluxio://alluxio-leader:19998/lakehouse/');Now that we have a SCHEMA that references the bucket where we store our tables in Alluxio, which syncs to MinIO, we can create our first table.
Optional: To view your queries run, log into the Trino UI and log in using any username (it doesn’t matter since no security is set up).
Move the customer data from the tiny generated TPCH data into MinIO using a CTAS query. Run the following query, and if you like, watch it running on the Trino UI:
CREATE TABLE iceberg.lakehouse.customer
WITH (
format = 'ORC',
location = 'alluxio://alluxio-leader:19998/lakehouse/customer/'
)
AS SELECT * FROM tpch.tiny.customer;Go to the Alluxio UI and the MinIO UI, and browse the Alluxio and MinIO files. You will now see a lakehouse directory that contains a customer directory that contains the data written by Trino to Alluxio and Alluxio writing it to MinIO.
Now, there is a table under Alluxio and MinIO, you can query this data by checking the following:
SELECT * FROM iceberg.lakehouse.customer LIMIT 10;How are we sure that Trino is actually reading from Alluxio and not MinIO? Let’s delete the data in MinIO and run the query again just to be sure. Once you delete this data, you should still see data return.
Stopping Services
Once you complete this tutorial, the resources used for this excercise can be released by runnning the following command:
docker-compose downConclusion
At this point, you should have a better understanding of Trino and Alluxio, how to get started with deploying Trino and Alluxio, and how to use Alluxio caching with an Iceberg connector and MinIO file storage. I hope you enjoyed this article. Be sure to like this article and comment if you have any questions!
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK