

Vuepress全文搜索终极版-algolia的开源实现meilisearch全接入指南
source link: https://wiki.eryajf.net/pages/dfc792/#%E6%9C%80%E5%90%8E
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Vuepress全文搜索终极版-algolia的开源实现meilisearch全接入指南
# 前言
一个好的搜索,能够更快速地把我们博客的内容呈现给读者。这也是我为什么五次三番地写文章介绍 Vuepress 配置全文搜索的原因。
我已经介绍过只需要安装插件即可实现全文搜索的两种方案:
然而在 Vuepress全文搜索插件vuepress-plugin-flexsearch-pro (opens new window) 文章末尾,我也介绍过为什么最终没有采用如上两种方案,这里就不再赘述。
在市面上,除了利用自身实现全文搜索之外,还有一种比较流行的就是接入外置的搜索引擎,在这种方案之中,大多数推荐的,文章介绍的,都是针对 algolia 的对接,algolia 非常优秀,提供了免费的额度供普通博客进行接入,但据一些反馈来看,这个资格的审核一般需要三天。另外最重要的是,当博客内容足够多之后,免费额度不够用,就得付费购买服务,且 algolia 是闭源的,没有自建搜索的可能。
于是,我尝试找寻能解决如上所有痛点的最佳实现,直到我遇到了:meilisearch (opens new window)。
meilisearch 也是一个搜索引擎,主程序完全开源,除了使用官方提供的美丽云服务进行对接之外,还可以通过自建搜索引擎来实现完全独立的搜索服务,这正是我所需要的。
两个产品提供的免费额度对比:
| 名字 | 免费额度 |
|---|---|
| meilisearch | 包含 100K 个文档,包括 10K 次搜索/月 |
| algolia | 10k 次搜索 + 10k 次推荐请求/月和 10k 条记录/月 |
至于收费方式就不再过多介绍了,因为我们最终会选择基于 meilisearch 开源版自建的方式来实现搜索功能。
接下来我们首先来介绍一下美丽云的接入方式,这种方式简单方便适合博客文档内容不算多,又不想折腾自建的同学,然后再介绍如何折腾自建。
# 接入云产品
meilisearch 这个项目处处蕴藏着优雅,官方文档也把产品使用的各种场景介绍的非常详细,因此很多内容你都可以在官方文档中找到答案。
官方文档的地址: https://docs.meilisearch.com/ (opens new window)
如果你的博客平台与使用场景是这样的:
- 文档数量不超过 100k,这是官方提供的免费额度上限。
- 对服务端响应有一定容忍度,因为云产品的部署节点(再创建项目的时候选择)为:旧金山,纽约,伦敦,法兰克福,新加坡。
- 没有自己的服务器,无法进行在线服务部署,于是只能选择云产品。
那么推荐你直接往下读,参考接入云产品的流程进行配置。如果有一项不能满足,那么建议你直接跳转到本文的自建折腾步骤进行参阅。
# 创建账号
meilisearch 提供了云版本供我们使用,我们通过如下链接进入到产品页面: https://www.meilisearch.com/pricing (opens new window)。
选择第一个免费版,点击开始,会让我们注册账号,注册账号之后即可投入使用,不需要等待审核。
# 创建项目
进入首页之后,我们先创建一个项目:

我这里用 howtoStartOpenSource (opens new window) 项目的接入历程进行举例。
创建完毕之后,我们点击进入到这个项目中,可以看到如下信息:
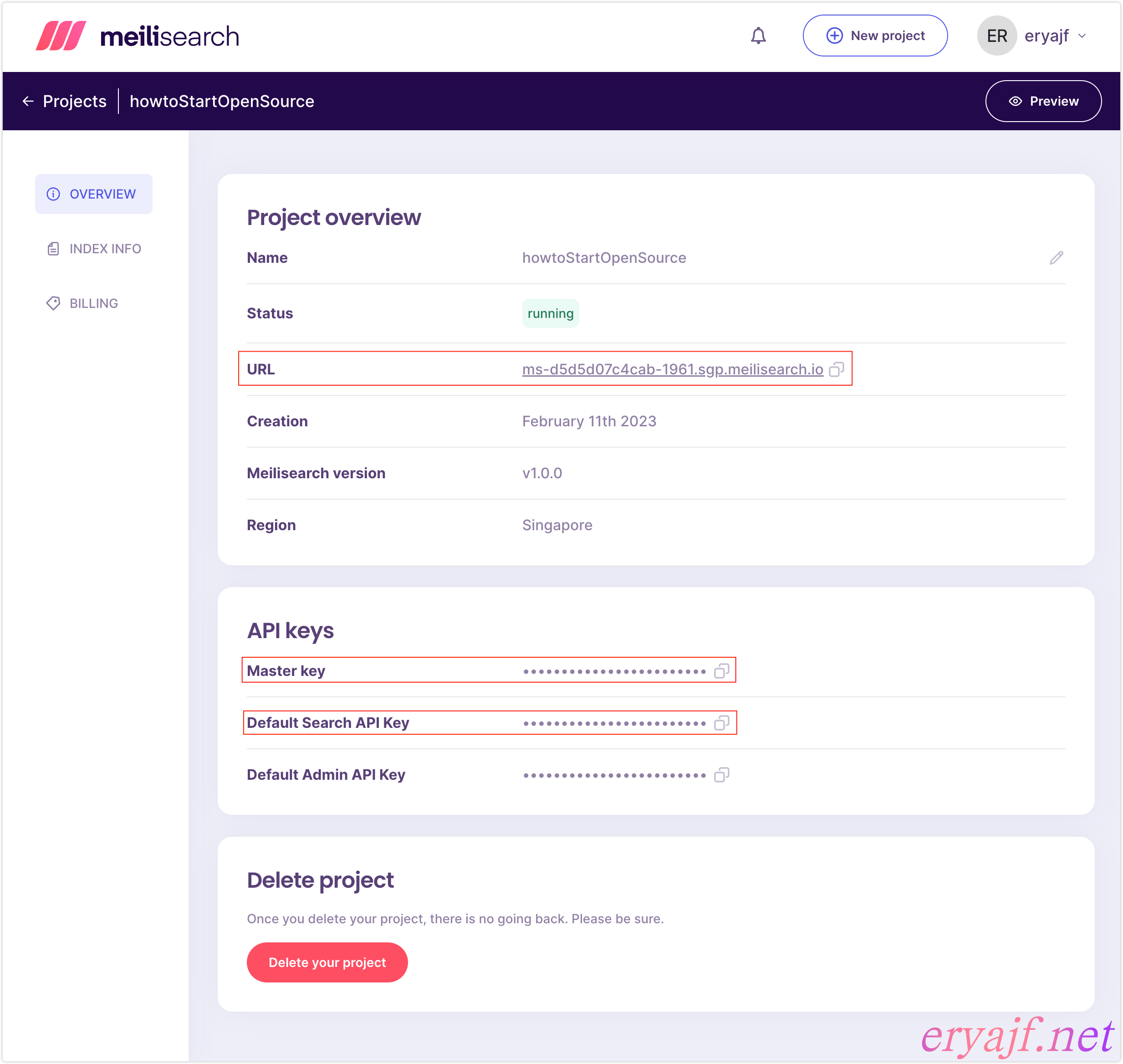
我们需要的是框住的三个内容:
- URL:是我们的搜索引擎服务端地址。
- Master key:我们在将博客数据通过爬虫建立索引的时候使用,这是个具有完整权限的 key。
- Default Search Api Key:一个仅有搜索权限的 key,供我们在博客配置插件时认证使用。
注:关于 key 的详细介绍,参见:官方文档 (opens new window)
接下来的工作分两步,第一:通过爬虫将博客数据创建成索引,第二:安装插件,配置搜索功能。
# 建立索引
官方提供了爬虫工具,我们只需要进行简单的配置,即可将数据索引建立起来。
关于这段配置流程,官方文档同样给了详细的说明:抓取你的内容 (opens new window)。
官方提供了一个 Vuepress 的抓取配置如下:
{
"index_uid": "docs",
"sitemap_urls": ["https://docs.meilisearch.com/sitemap.xml"],
"start_urls": ["https://docs.meilisearch.com"],
"selectors": {
"lvl0": {
"selector": ".sidebar-heading.open",
"global": true,
"default_value": "Documentation"
},
"lvl1": ".theme-default-content h1",
"lvl2": ".theme-default-content h2",
"lvl3": ".theme-default-content h3",
"lvl4": ".theme-default-content h4",
"lvl5": ".theme-default-content h5",
"text": ".theme-default-content p, .theme-default-content li, .theme-default-content td"
},
"strip_chars": " .,;:#",
"scrap_start_urls": true,
"custom_settings": {
"synonyms": {
"relevancy": ["relevant", "relevance"],
"relevant": ["relevancy", "relevance"],
"relevance": ["relevancy", "relevant"]
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
注意如上的配置内容很重要,如果你的博客不是常规默认的,那么需要根据自己的情况对元素进行辨别,详细配置项说明,参考更多可选字段 (opens new window)。
我的 howtoStartOpenSource 项目用的是 vdoing 主题,可以看到一些元素名字与内容不一样,需要一些调整。所以我用的配置如下:
{
"index_uid": "howtoStartOpenSource",
"sitemap_urls": ["https://eryajf.github.io/HowToStartOpenSource/sitemap.xml"],
"start_urls": ["https://eryajf.github.io/HowToStartOpenSource/"],
"stop_urls": [
"https://eryajf.github.io/HowToStartOpenSource/archives/",
"https://eryajf.github.io/HowToStartOpenSource/basic/",
"https://eryajf.github.io/HowToStartOpenSource/github-actions/",
"https://eryajf.github.io/HowToStartOpenSource/github-tips/"
],
"selectors": {
"lvl0": {
"selector": "h1",
"global": true,
"default_value": "Documentation"
},
"lvl1": ".theme-vdoing-content h2",
"lvl2": ".theme-vdoing-content h3",
"lvl3": ".theme-vdoing-content h4",
"lvl4": ".theme-vdoing-content h5",
"lvl5": ".theme-vdoing-content h6",
"text": ".theme-vdoing-content p, .theme-vdoing-content li"
},
"strip_chars": " .,;:#",
"scrap_start_urls": true,
"selectors_exclude": ["iframe", ".katex-block", ".md-flowchart", ".md-mermaid", ".md-presentation.reveal.reveal-viewport", ".line-numbers-mode", ".code-group", ".footnotes", "footer.page-meta", ".page-nav", ".comments-wrapper"]
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
index_uid :为索引名称,如果服务端没有,则会自动创建。
将配置文件放到/tmp/scraper目录下,然后通过如下命令运行爬虫对内容进行抓取:
docker run -t --rm \
--network=host \
-e MEILISEARCH_HOST_URL='刚刚创建的项目的URL' \
-e MEILISEARCH_API_KEY='刚刚创建的项目的Master Key' \
-v /tmp/scraper/config.json:/docs-scraper/config.json \
getmeili/docs-scraper:v0.12.7 pipenv run ./docs_scraper config.json
2
3
4
5
6
执行过程中可以看到每个页面都进行了抓取:
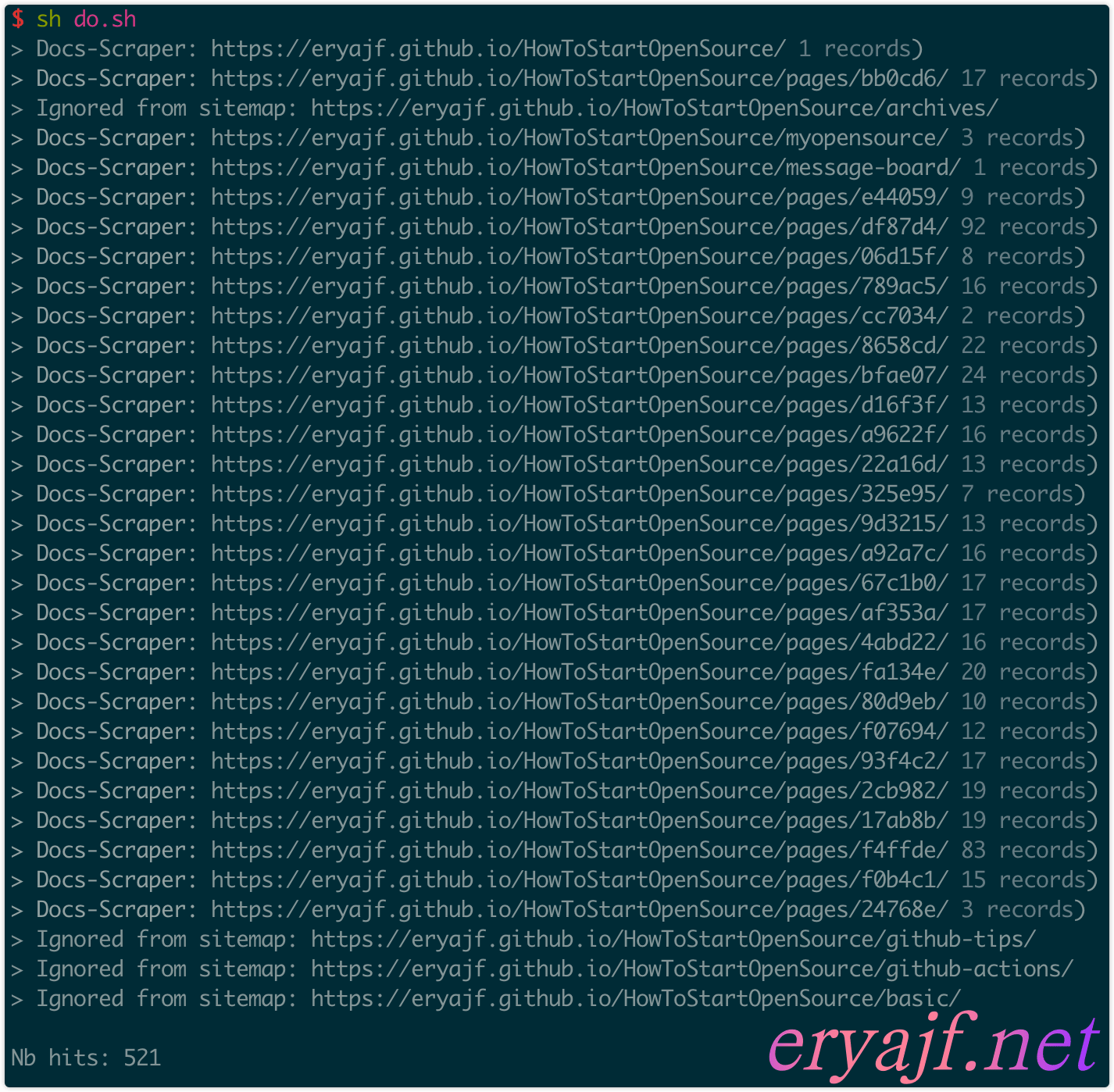
如果脚本跑完发现最后匹配到了 0 条,那说明是上边 config.json 中元素选择的问题,可以到自己博客中,点击检查来查看元素的正确名称。
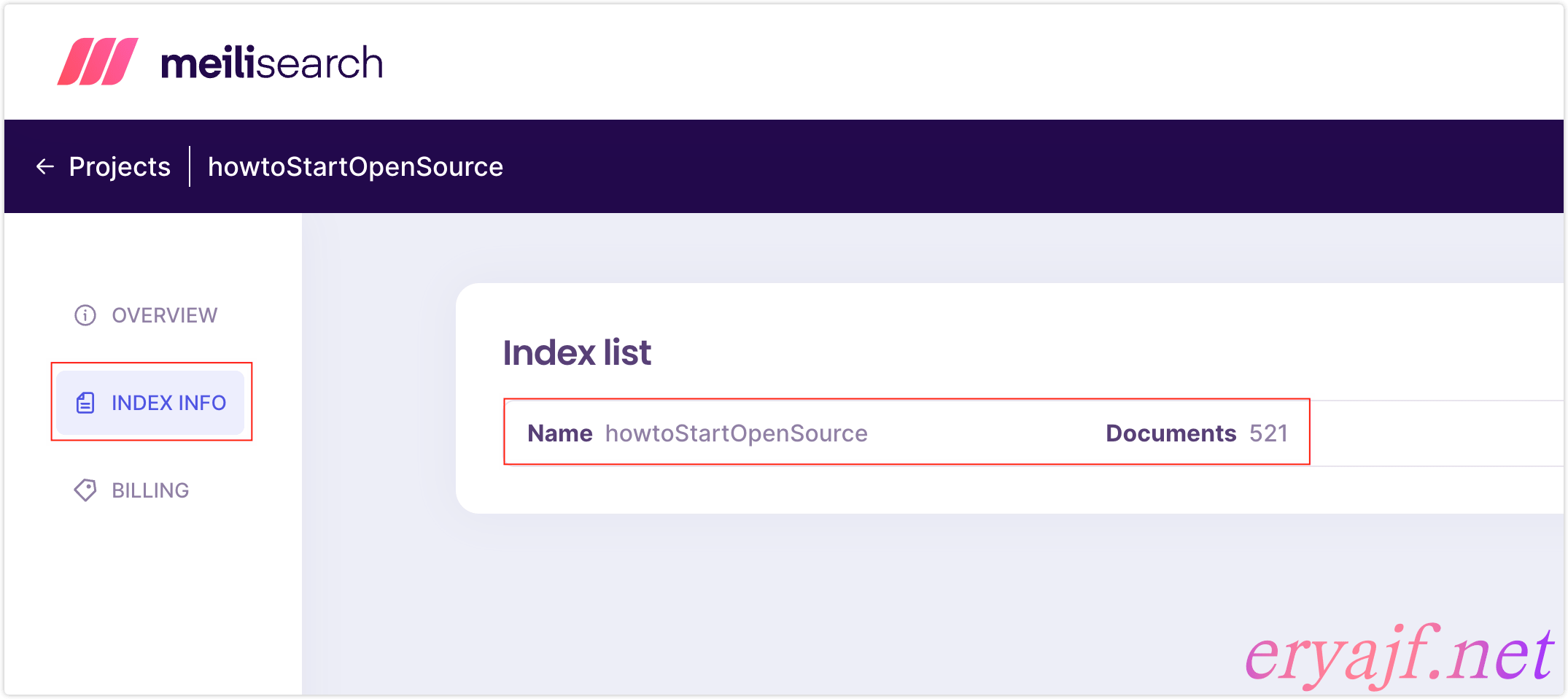
可以看到一共抓取到了 521 条记录,哎,爱,❤️,就是这么巧,嘿嘿。
这个时候来到美丽云这里,也可以看到有了 521 条记录:
点击右上角的预览,能够进入到 meilisearch 提供的一个 web 页面(需要填写 Master key):
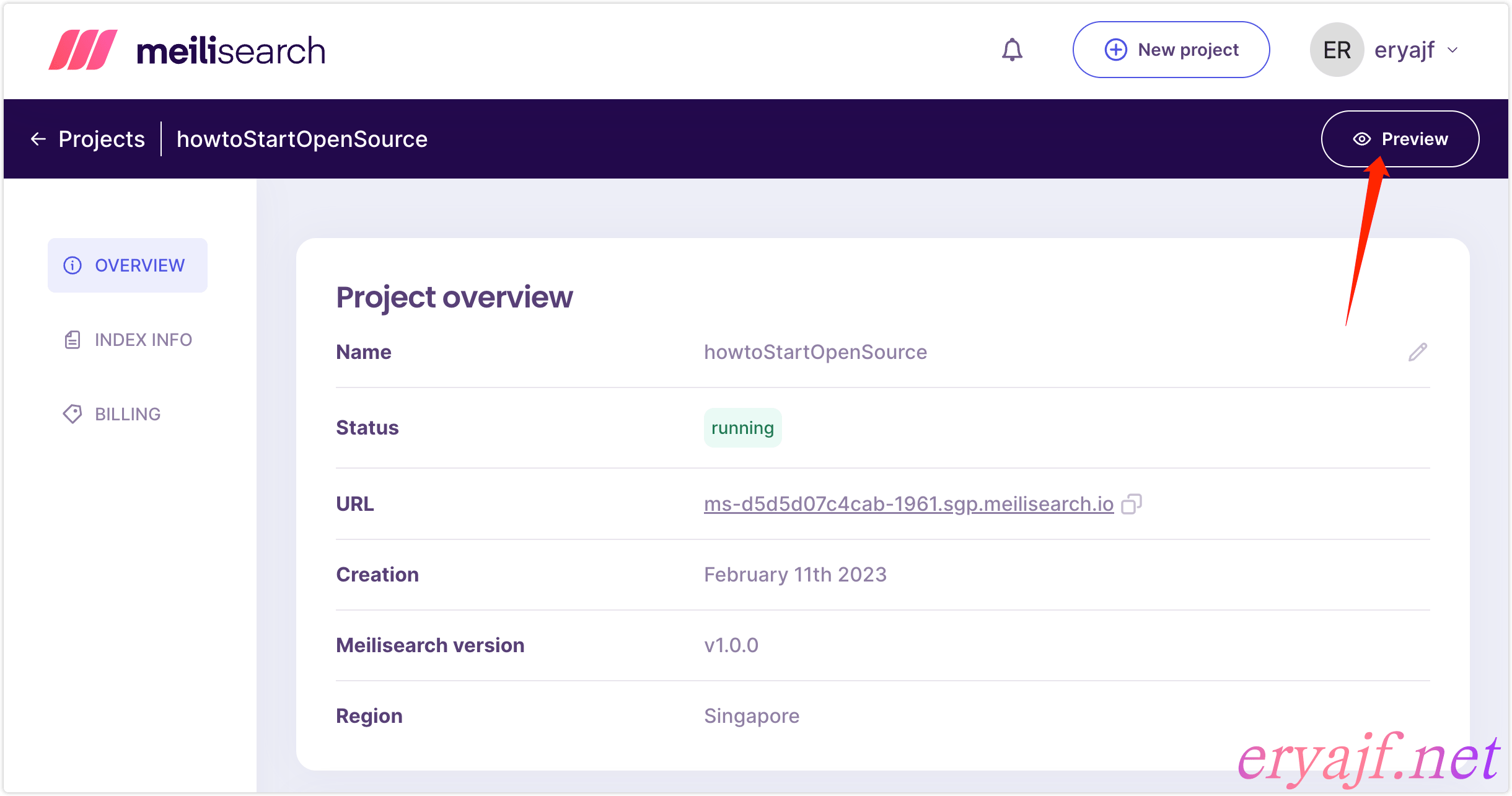
然后再 web 端简单验证一下搜索:
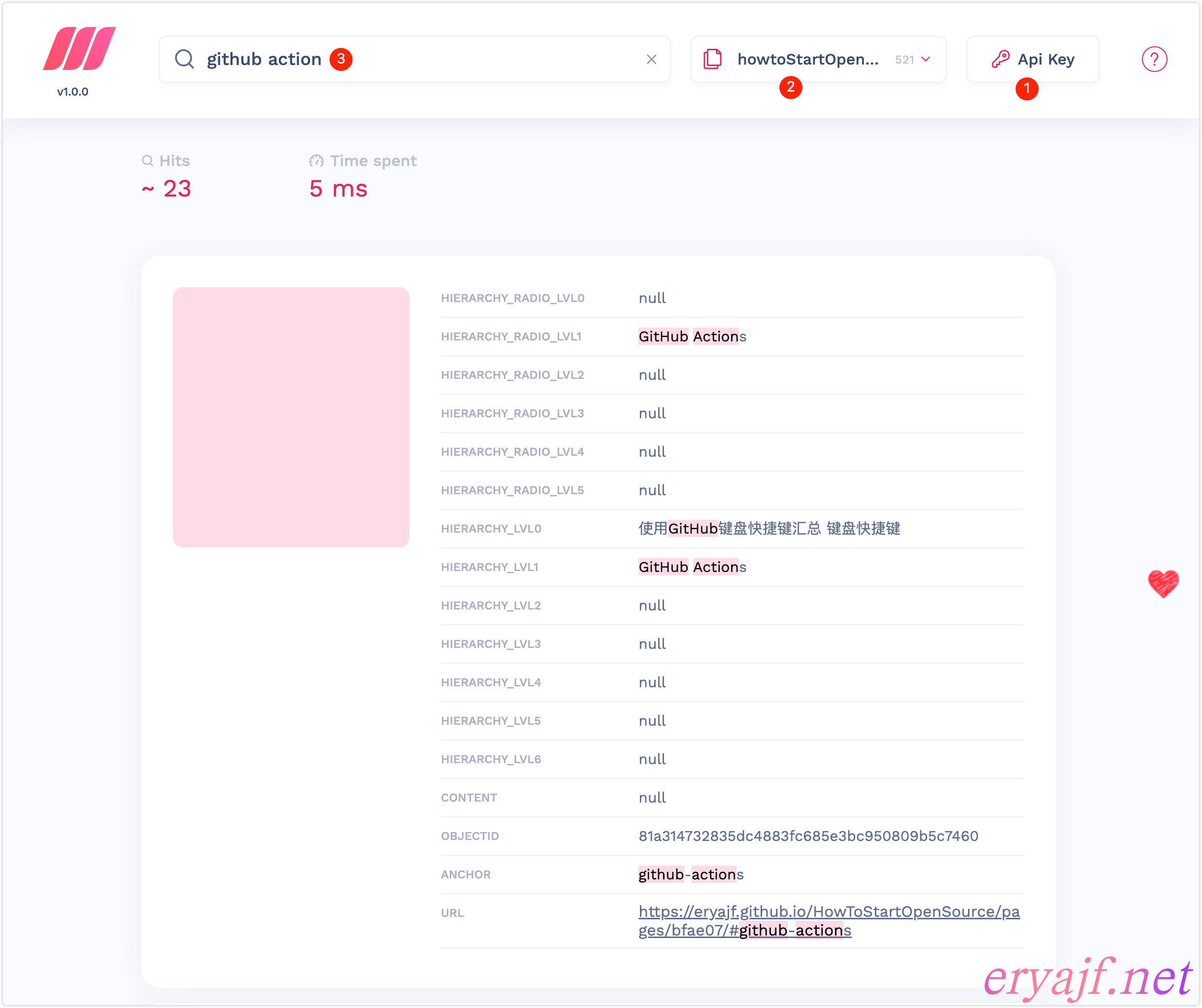
- ❶: 填写 key,否则无法进行交互。
- ❷:点击这里切换索引。
- ❸:在搜索框进行搜索验证。
如果上边的验证没有问题,就说明我们的采集工作就完成了,换句话说搜索引擎的服务端就准备妥当了。
# 配置客户端
客户端的配置就相对简单了,因为 meilisearch 的官方文档用的也是 Vuepress,因此官方也维护了一个 Vuepress 的插件,基本上就是开箱即用,下边安装配置直接进行,不多废话。
# 安装插件
yarn add vuepress-plugin-meilisearch
# or
npm install vuepress-plugin-meilisearch
# 配置插件
在插件的配置文件当中添加如下配置内容:
// 全文搜索插件 meilisearch
[
'vuepress-plugin-meilisearch',
{
hostUrl: 'https://ms-d5d5d07c4cab-1961.sgp.meilisearch.io', // meilisearch 服务端域名
apiKey: "575b81b52d62c70a11367b8c4bdc1cb2532270d89381d2da7fb0ebd6b7c7f675", // 只有搜索权限的 key
indexUid: 'howtoStartOpenSource',
// placeholder: 'Search as you type...', // 在搜索栏中显示的占位符
maxSuggestions: 9, // 最多显示几个搜索结果
cropLength: 30, // 每个搜索结果最多显示多少个字符
},
],
2
3
4
5
6
7
8
9
10
11
12
然后运行发布,查看效果:
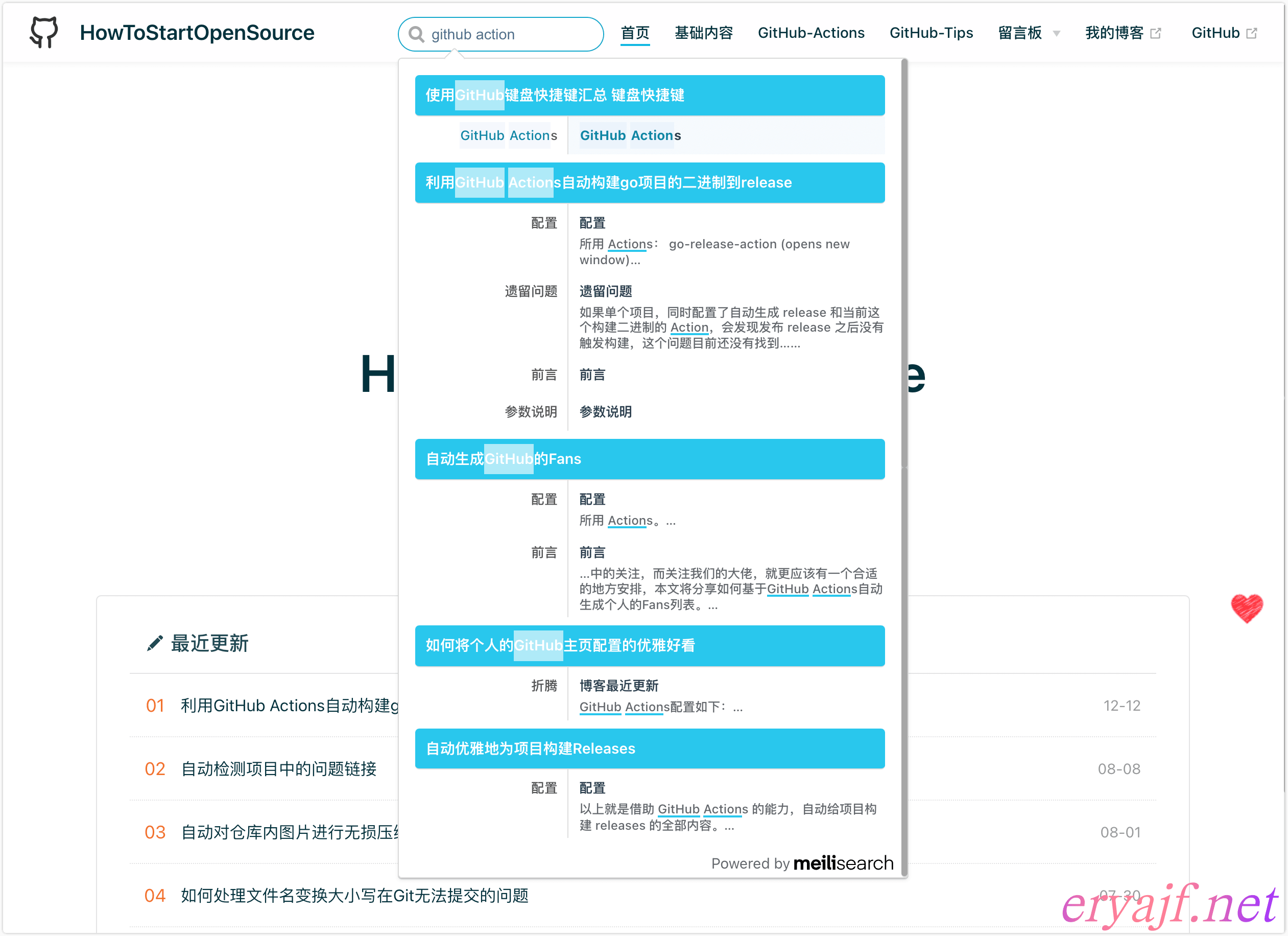
如此,便就完成了 Vuepress 博客对 meilisearch 搜索的接入。
# 索引自动化
当我们有新的文章发布时,应该重新运行抓取文章建立索引的命令,如果你的博客是通过 Github Action 进行发布的,那么官方还提供了通过 Action 自动抓取的方案。
这里做一个简单介绍。
在部署的 Action 下边添加如下内容:
scrape-docs:
needs: test_website
runs-on: ubuntu-20.04
steps:
- uses: actions/checkout@v2
- uses: actions/setup-node@v2
with:
node-version: 14
registry-url: https://registry.npmjs.org/
- name: Run docs-scraper
env:
API_KEY: ${{ secrets.MEILISEARCH_API_KEY }}
CONFIG_FILE_PATH: ${{ github.workspace }}/docs/.vuepress/public/data/docs-scraper-config.json
run: |
docker run -t --rm \
-e MEILISEARCH_HOST_URL="https://ms-d5d5d07c4cab-1961.sgp.meilisearch.io" \
-e MEILISEARCH_API_KEY=$API_KEY \
-v $CONFIG_FILE_PATH:/docs-scraper/config.json \
getmeili/docs-scraper:v0.12.7 pipenv run ./docs_scraper config.json
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
如果你拿不准应该怎样配置,可以参考我的这个完整配置 (opens new window)。
如上内容需要依赖三个配置信息:
- API_KEY:注意就是那个 Master key,这个 key 我们通过 github 的环境变量进行传递。如果你不知道怎么配置这个环境变量,参考这里 (opens new window)。
- CONFIG_FILE_PATH:抓取时的配置文件,你可以选择放在你项目源码的某个指定目录。
- MEILISEARCH_HOST_URL:务必注意将此 URL 换成你自己的,否则会运行失败。
如上内容准备完毕之后,当我们提交了新的代码,部署上去之后,就会自动运行抓取动作了,我这边执行的情况如下:
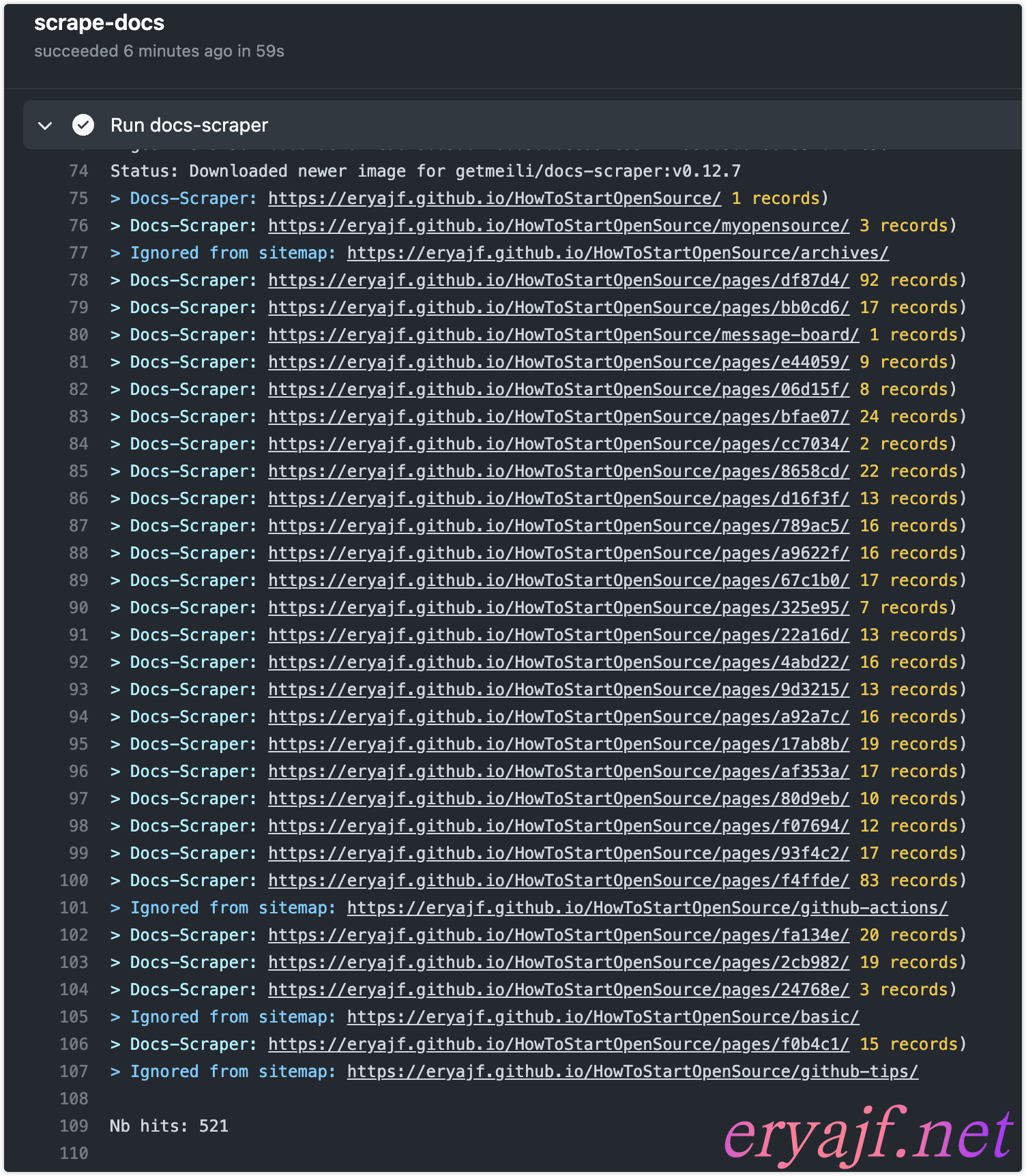
注意:我还没有找到具体的文档说明爬虫每次建立索引的机制是什么,至少目前看来,应该是增量的一个情况,不会重复创建。
# 自建折腾
事实上自建折腾的步骤,与上边接入云产品的流程基本上是一样的,不同的就是云产品会负责把服务端给我们部署好,而自建的时候,需要自己来完成服务端的部署。
那么接下来就长话短说,讲讲自建 meilisearch 的最佳实践。
# 部署
官方对于部署的介绍非常详细,各种方案都提供了,我这里选择使用 docker 来进行部署。
添加服务启动脚本:
$ cat start.sh
docker run -itd --name meilisearch -p 7700:7700 \
-e MEILI_ENV="production" -e MEILI_NO_ANALYTICS=true \
-e MEILI_MASTER_KEY="自定义一个不少于16字节的秘钥" \
-v $(pwd)/meili_data:/meili_data \
getmeili/meilisearch:v1.0
2
3
4
5
6
自建的时候,需要将环境变量声明为生产,并且必须指定 master-key,否则将会提示无法使用。
然后运行该脚本,服务启动,通过监听日志,查看服务状态是否正常。
也可以请求服务的健康接口进行验证:
$ curl -s localhost:7700/health | jq
{
"status": "available"
}
注意,生产模式下,只有这一个接口是不需要秘钥认证即可访问的,其他接口访问的时候都需要带上秘钥。
# 创建搜索的key
上边有了一个 master-key 用于爬虫抓取使用,还需要创建一个只有搜索权限的 key,可通过如下命令进行创建:
curl \
-X POST 'http://localhost:7700/keys' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer 你自定义的秘钥' \
--data-binary '{
"description": "eryajf-wiki key",
"actions": ["search"],
"indexes": ["wiki"],
"expiresAt": "2099-01-01T00:00:00Z"
}'
2
3
4
5
6
7
8
9
10
创建完成之后,能看到返回内容中有一个 key 的字段,就是这个只有搜索权限的 key 了。
# 添加域名
这个根据自己的实际情况,我这里给 Nginx 添加配置文件,配置域名:
server {
listen 80;
listen 443 ssl;
server_name search.eryajf.net;
ssl_certificate /etc/nginx/ssl/search.eryajf.net.pem;
ssl_certificate_key /etc/nginx/ssl/search.eryajf.net.key;
ssl_ciphers ECDHE-RSA-AES128-GCM-SHA256:ECDHE:ECDH:AES:HIGH:!NULL:!aNULL:!MD5:!ADH:!RC4;
ssl_protocols TLSv1 TLSv1.1 TLSv1.2;
ssl_prefer_server_ciphers on;
location / {
proxy_set_header Host $host;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_set_header X-Real-IP $remote_addr;
proxy_pass http://127.0.0.1:7700;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
这样就完成了与美丽云一样的服务端配置信息:
- 服务端 URL
- master key
- search key
接下来的步骤参考上边接入云产品的步骤即可,从建立索引往后看。
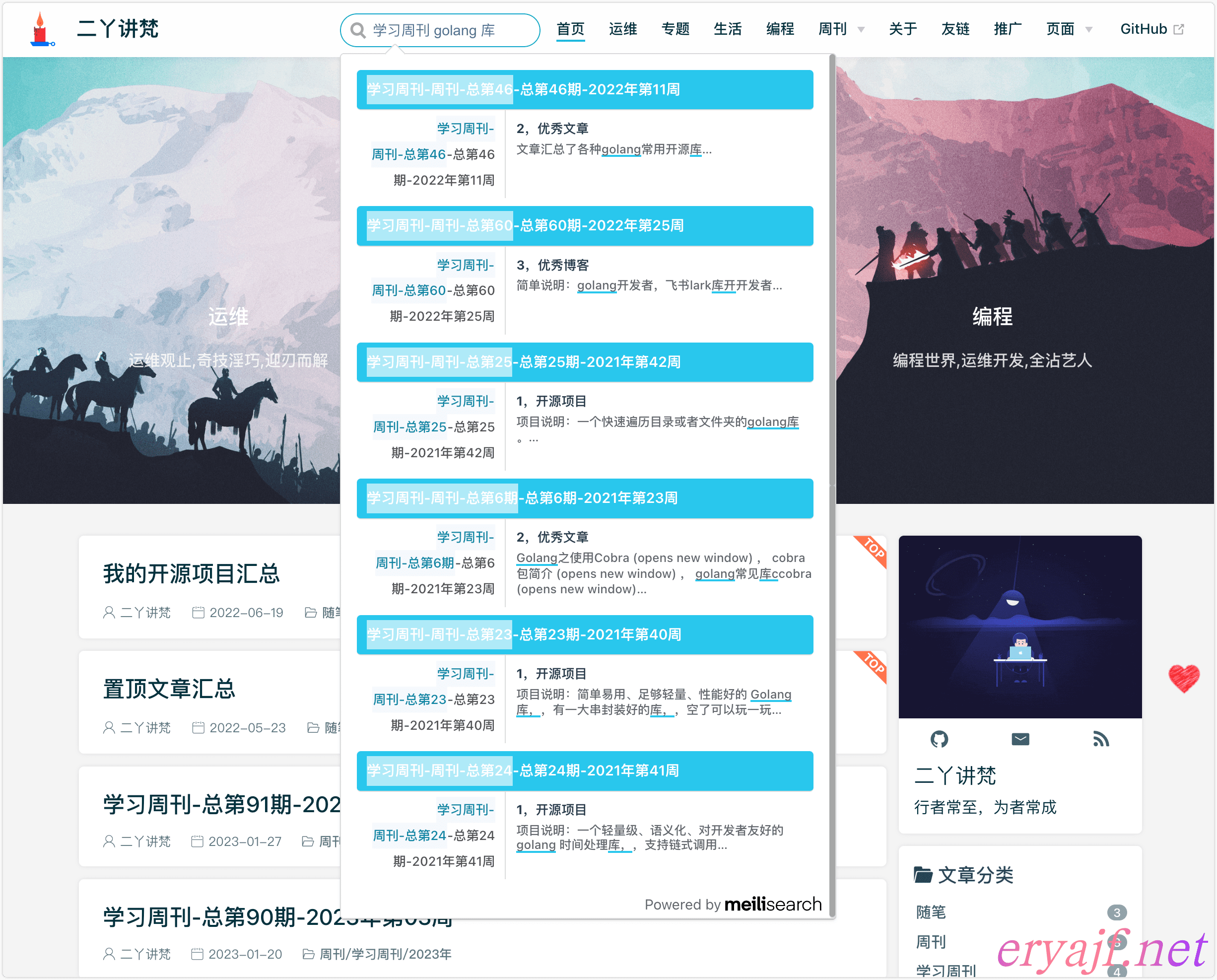
# 效果展示
最后来看下我的主博客接入自建搜索之后的效果:
# 附录
# 关于 key 的问题
有人可能会担心 key 配置在项目中,会不会有什么风险,其实不会有任何风险。
首先来说,我们的数据是什么:是爬虫运行之后建立的索引,就算是整个索引都被删了,那么爬虫再跑一次,就又部署起来了。
其次,其他人首先没有盗用的价值,因为别人的博客内容与你的不一样,就算配置成你的服务端与 key,其实也没有太大意义,所以这个担心没有必要。
# 关于建立索引的最佳实践
上边接入云产品的文档最后,我介绍了如何使用 GitHub Action 自动建立索引,这是因为那个项目本身就是依托于 github 而创建的,因此这么跑没啥问题。
而当我们的博客是部署在自己的服务器,并且接入了 CDN 的情况下,那么这波爬虫的请求,其实是可以通过服务器自身运行来规避掉的。
比如我要给博客 wiki.eryajf.net 建立索引,那么就在服务器绑定 hosts 为本机:
$ cat /etc/hosts | grep wiki
127.0.0.1 wiki.eryajf.net
然后在服务器添加一个运行爬虫的脚本,每次发布完新内容之后,调用这个脚本就可以实现自动更新了。
# 关于优化搜索匹配
官方给搜索匹配加了一张说明图:
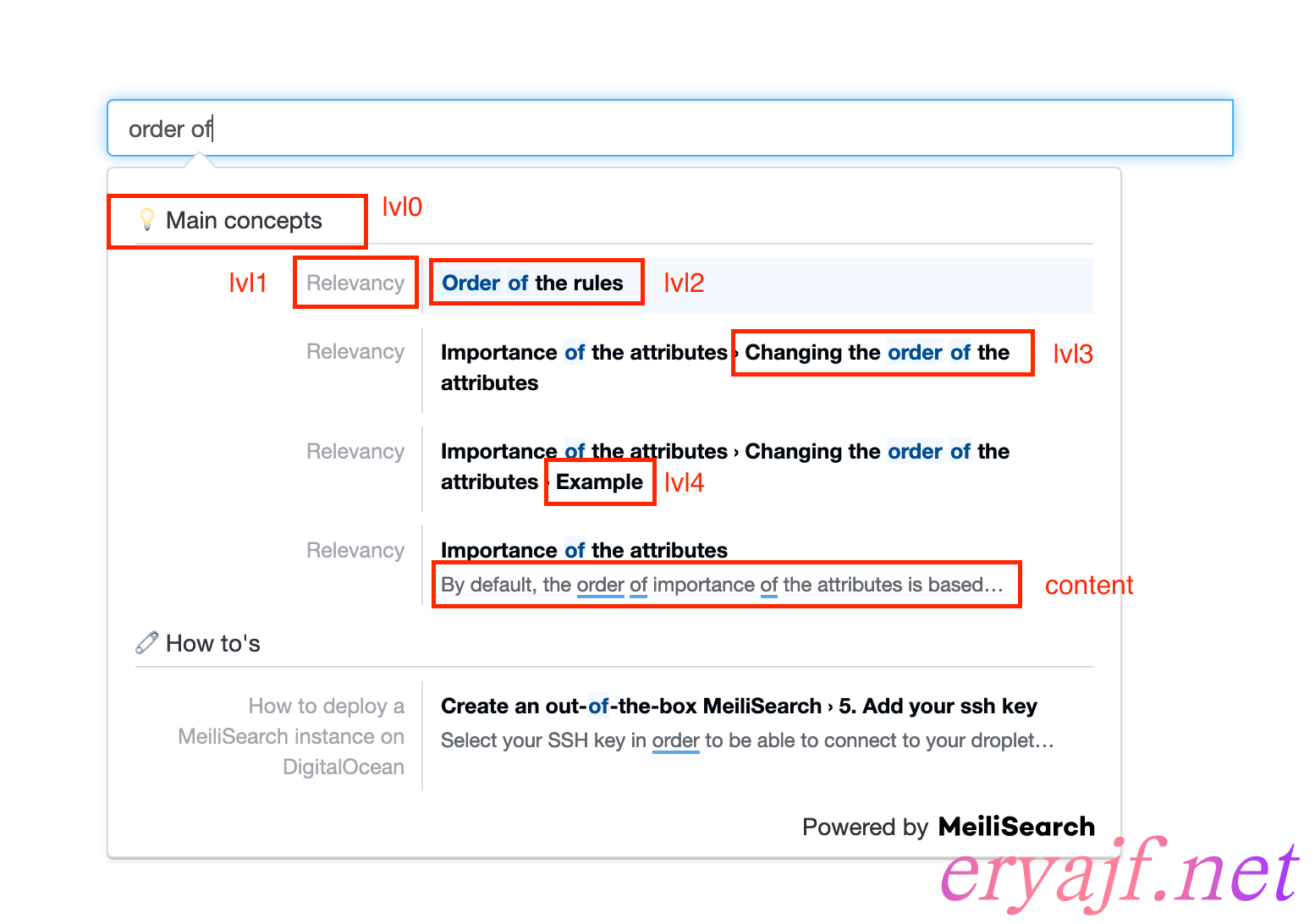
如上内容的匹配优先级也是不一样的,我们尽可能让每个内容都找到正确的元素,这个时候就能获取到正确的索引数据,那么最后呈现的搜索效果就越准确。
# 关于镜像版本
我以为始终使用 latest 的 tag 能够总是用到最后一个版本的镜像,但是官方并不推荐这么做,而是推荐使用指定的 tag 版本,事实上,我在使用爬虫抓取数据时,一开始使用的 latest 跑的,就出现了报错,而指定为最后一个版本之后,报错消失。
# 最后
终于,花了一天的时间,我从折腾 meilisearch 到此篇文档落地,总算是把博客的搜索给落地了,心中的一块儿石头也算是落地了。
正如她的名字,meilisearch,当我们在网页点击翻译的时候,也会被翻译成美丽搜索,因此这篇文档中也有不少地方我直接称呼为美丽,她的确太美丽了,我忍不住歌颂开发者们的伟大付出。尽管后来我也知道了,这是个美丽的误会(详见:meilisearch 为什么命令为meili (opens new window)),但我仍旧抹不去内心将 meilisearch 与美丽搜索挂钩的印象,世间很多事儿就是如此美妙,正如我的 HowToStartOpenSource 项目抓取之后文档数刚好是 521 条那样的美妙。
昨晚我折腾到深夜,并通读了 meilisearch 的官方文档,更加深刻地体会到 meilisearch 团队的用心与伟大,我推荐所有人都了解,并使用 meilisearch。
如果你的博客并不是 Vuepress,那也不必灰心,官方提供了各种语言的 SDK,你可以在任何地方进行集成。
欢迎你接入 meilisearch,如果接入过程中有任何问题,都可以在下方评论区进行交流。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK