
8

基于APIView&ModelSerializer写接口 - 阿丽米热
source link: https://www.cnblogs.com/almira998/p/17109618.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

基于APIView&ModelSerializer写接口
引言,首先路由写法还是不变、视图层的视图类写法不变,在序列化类要改变写法、慢慢的靠近序列化器组件;而且需要创建关联表,因为现实生活当中不可能仅仅建单表,会使用大量的多表关联的表数据。好吧!咱们上干货把,首先准备一下路由吧,毕竟就两条代码而且配好就逻辑写完可以马上测试接口了。本篇文章重点介绍了序列化定制字段的多种方法,也演示了序列化重要字段DictField()、ListField()的用法和反序列化重要参数read_only=True和write_only=True
一、首先准备前提工作
1.模型代码
python
from django.db import models
class Book(models.Model):
name = models.CharField(verbose_name='书名', max_length=32)
price = models.CharField(verbose_name='价格', max_length=32)
# 外键 书跟出版社是一对多
publish = models.ForeignKey(to='Publish', on_delete=models.CASCADE)
# 外键 书跟作者是多对多
authors = models.ManyToManyField(to='Author')
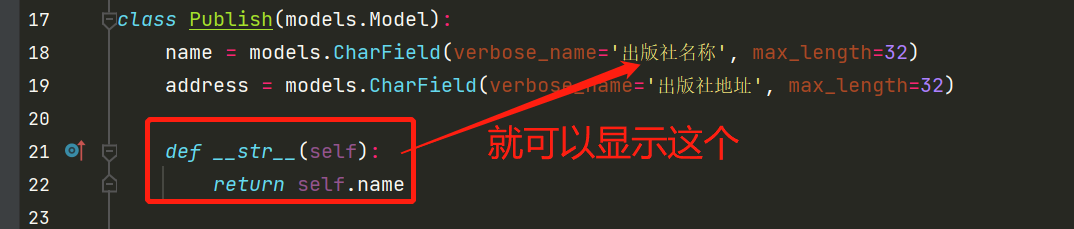
class Publish(models.Model):
name = models.CharField(verbose_name='出版社名称', max_length=32)
address = models.CharField(verbose_name='出版社地址', max_length=32)
class Author(models.Model):
name = models.CharField(verbose_name='作者姓名', max_length=32)
phone = models.CharField(verbose_name='电话号码', max_length=11)
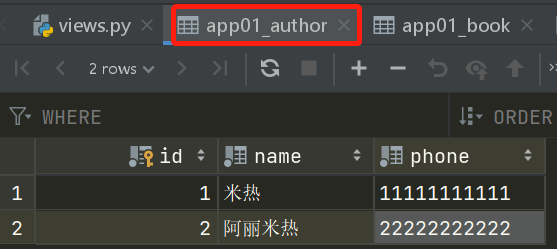
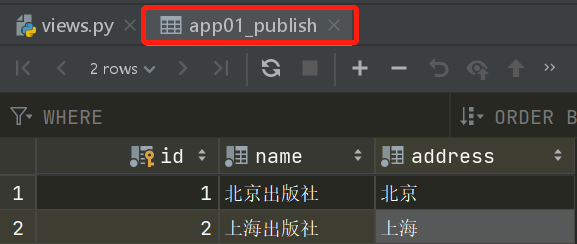
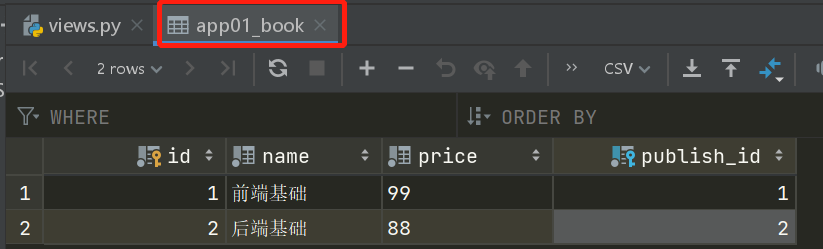
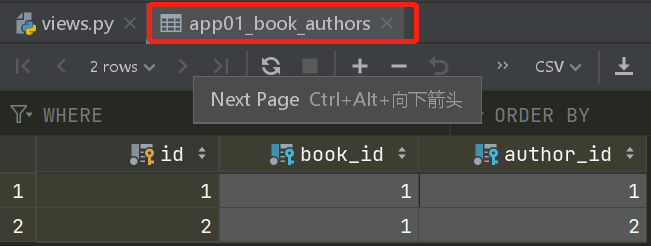
录入数据的顺序不能乱来,因为有外键关系、那么小编在这里详细的列出录入数据的过程
先在Author表录入两条
2.路由代码
python
from django.contrib import admin
from django.urls import path
from app01 import views
urlpatterns = [
path('admin/', admin.site.urls),
path('books/', views.BookView.as_view()),
path('books/<int:pk>/', views.BookDetailView.as_view()),
]
3.视图代码
python
from django.shortcuts import render
from rest_framework.views import APIView
from .models import Book
from .serializer import BookSerializer
from rest_framework.response import Response
class BookView(APIView):
def get(self, request): # 查询所有
# 查询所有数据
books = Book.objects.all()
# 序列化数据
ser = BookSerializer(instance=books, many=True)
return Response(ser.data)
def post(self, request):
ser = BookSerializer(data=request.data)
if ser.is_valid():
ser.save()
return Response({'code': 100, 'msg': '新增成功', 'result': ser.data})
else:
return Response({'code': 101, 'msg': ser.errors})
class BookDetailView(APIView):
def put(self, request, pk):
book = Book.objects.filter(pk=pk).first()
ser = BookSerializer(data=request.data, instance=book)
if ser.is_valid():
ser.save()
return Response({'code':100, 'msg':'修改成功'})
else:
return Response({'code':101, 'msg':ser.errors})
def get(self, request, pk):
book = Book.objects.filter(pk=pk)
ser = BookSerializer(instance=book)
return Response(ser.data)
def delete(self, request, pk):
Book.objects.filter(pk=pk).delete()
return Response('删除成功')
二、继承Serializer序列化定制字段的三种方法
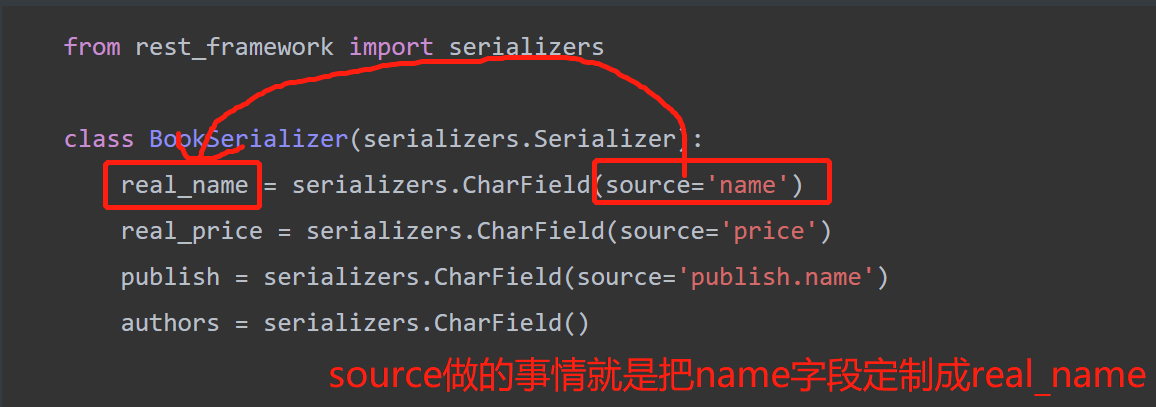
1.通过source关键词定制
python
# 用source关键字定制字段的代码
from rest_framework import serializers
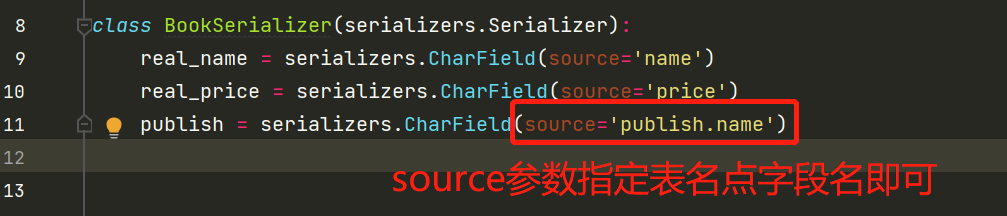
class BookSerializer(serializers.Serializer):
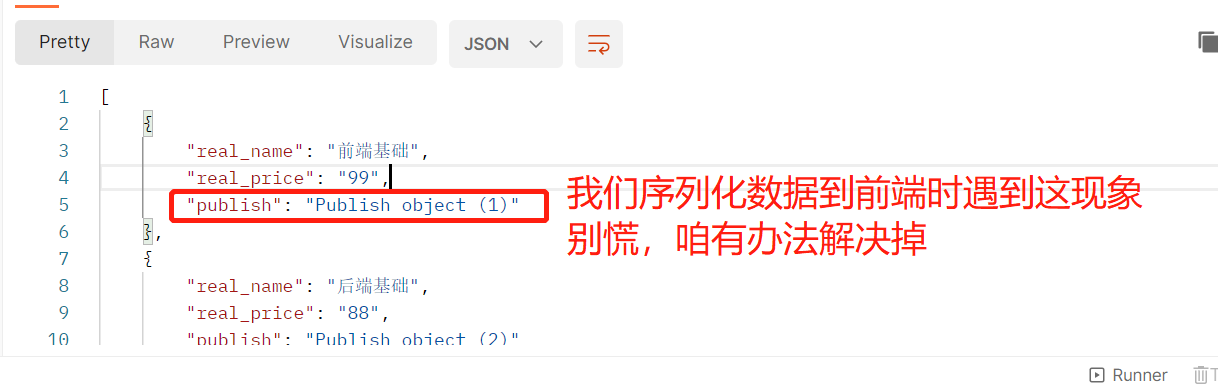
real_name = serializers.CharField(source='name')
real_price = serializers.CharField(source='price')
publish = serializers.CharField(source='publish.name')
authors = serializers.CharField()
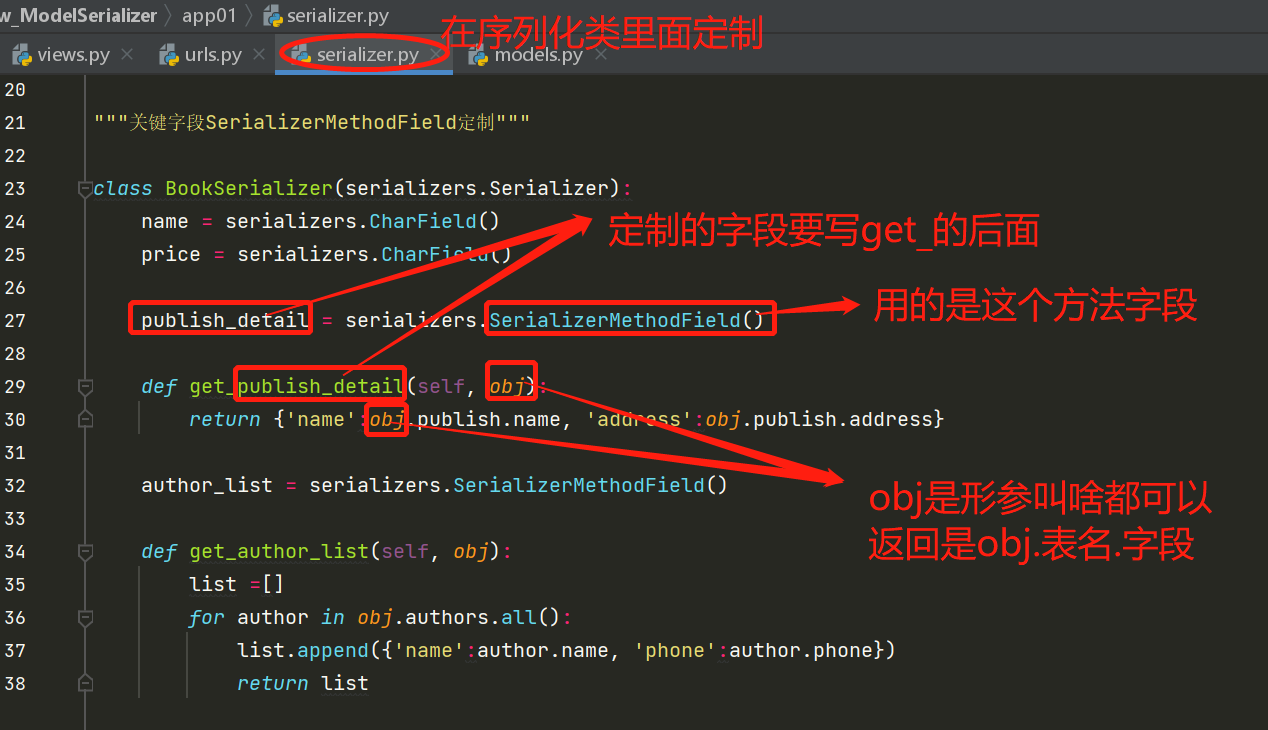
2.SerializerMethodField定制
该方法能够序列化定制所有的任何的字段先想好定制成什么样子,之后新字段名跟get_后面即可,记得定制一个就一定要配合一个get_方法,可以自定义返回格式,就说明个性化能力强。
python
"""关键字段SerializerMethodField定制"""
class BookSerializer(serializers.Serializer):
name = serializers.CharField()
price = serializers.CharField()
publish_detail = serializers.SerializerMethodField()
def get_publish_detail(self, obj):
return {'name':obj.publish.name, 'address':obj.publish.address}
author_list = serializers.SerializerMethodField()
def get_author_list(self, obj):
list =[]
for author in obj.authors.all():
list.append({'name':author.name, 'phone':author.phone})
return list
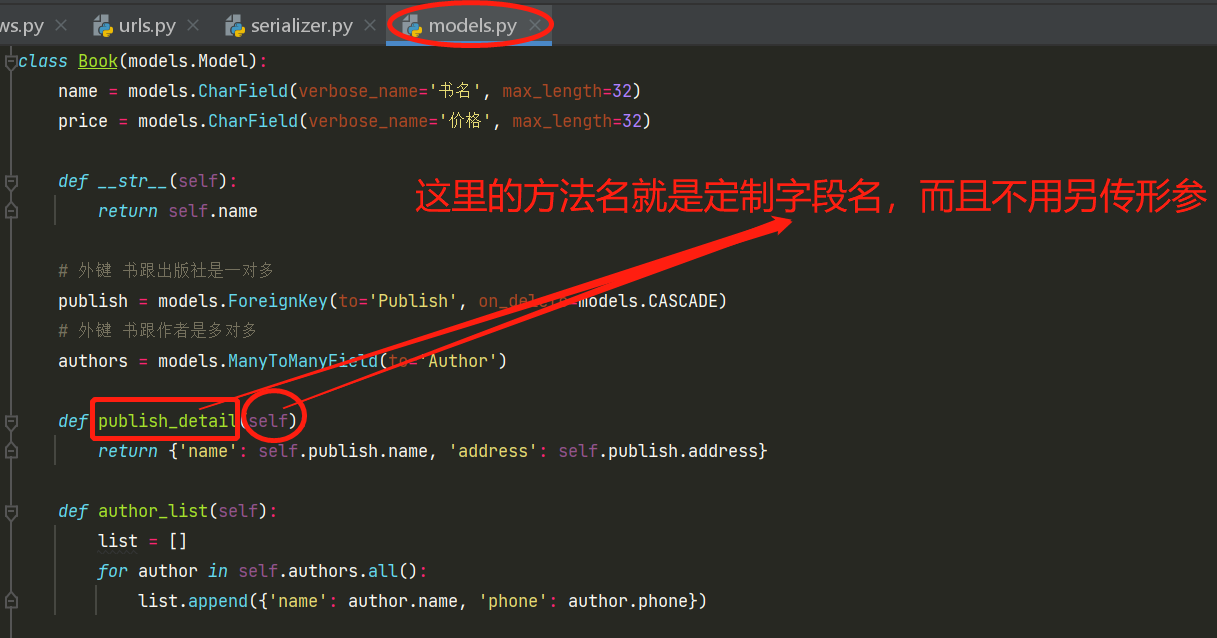
3.在模型表中写方法来定制
这个方法其实算不上方法,因为逻辑是一样的,只不过把方法写到模型表里面,而序列化类里面只需要写新定制字段,所以相当于做了所谓的解耦合吧,但是我感觉完全没这个必要,毕竟要序列化,那么属性和方法统一写到一个位置比较省心。当然这是我的个人想法,仅供参考。
python
# 序列化类代码
class BookSerializer(serializers.Serializer):
name = serializers.CharField()
price = serializers.CharField()
publish_detail = serializers.DictField()
author_list = serializers.ListField()
python
# 模型表写定制方法代码
def publish_detail(self):
return {'name': self.publish.name, 'address': self.publish.address}
def author_list(self):
list = []
for author in self.authors.all():
list.append({'name': author.name, 'phone': author.phone})
return list
三、继承Serializer反序列化
当然定制字段的方法也要写,不管在序列化类里写还是模型表里写,但凡涉及到定制字段就要写定制方法,因为涉及到反序列化所以要重写create方法和update方法,而且也要写数据校验,毕竟不能前端传什么就录入,一定要有校验机制的
python
class BookSerializer(serializers.Serializer):
# 如果一个字段既用来序列化又用来反序列化就不用写参数read_only或write_only
name = serializers.CharField(max_length=8, error_messages={'max_length':'太长了'})
price = serializers.CharField()
# 只用来序列化 写参数read_only=True
publish_detail = serializers.DictField(read_only=True)
author_list = serializers.ListField(read_only=True)
# 只用来反序列化 写参数write_only=True
publish = serializers.CharField(write_only=True)
author = serializers.ListField(write_only=True)
# 反序列化要重写create方法和update方法
def create(self, validated_data):
# 新增一本书
book = Book.objects.create(name=validated_data.get('name'),
price=validated_data.get('price'),
publish_id=validated_data.get('publish'))
# 关联作者
book.authors.add(*validated_data.get('author'))
# 返回book
return book
def update(self, instance, validated_data):
# 序列出数据
instance.name = validated_data.get('name')
instance.price = validated_data.get('price')
instance.publish_id = validated_data.get('publish')
# 先清空数据在add
authors = validated_data.get('author')
print(validated_data)
instance.authors.clear()
instance.authors.add(*authors)
# 修改完保存
instance.save()
# 返回数据
return instance
# 修改要重写update
def update(self, instance, validated_data):
# validated_data 校验过后的数据,{name:红楼梦,price:19,publish:1,authors:[1,2]}
instance.name = validated_data.get('name')
instance.price = validated_data.get('price')
instance.publish_id = validated_data.get('publish')
# 先清空,再add
authors = validated_data.get('authors')
instance.authors.clear()
instance.authors.add((*authors)
instance.save()
return instance
四、用ModelSerializer进行序列化与反序列化
python
"""ModelSerializer的用法"""
class BookSerializer(serializers.ModelSerializer):
class Meta:
# 跟book表关联
model = Book
# fields = ['写需要序列化的字段名',[]···]
# 如果fields = '__all__'这样写就表明序列化所有字段
fields = '__all__'
# extra_kwargs = {'字段名': {'约束条件': 约束参数},是反序列化字段
extra_kwargs = {'name': {'max_length': 8},
'publish_detail': {'read_only': True},
'authors_list': {'read_only': True},
'publish': {'write_only': True},
'authors': {'write_only': True}
}
def validate_name(self, name):
if name.startswith('sb'):
raise ValidationError('书名不能以sb开头')
else:
return name

__EOF__
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK