

「Go语言进阶」并发编程详解
source link: https://www.51cto.com/article/746176.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

并发 VS 并行
在讲解并发概念时,总会涉及另外一个概念并行。下面让我们来聊聊并发和并行之间的区别。
- 并发(concurrency):把任务在不同的时间点交给处理器进行处理。在同一时间点,任务并不会同时运行。
- 并行(parallelism):把每一个任务分配给每一个处理器独立完成。在同一时间点,任务一定是同时运行。
并发不是并行。并行是让不同的代码片段同时在不同的物理处理器上执行。并行的关键是同时做很多事情,而并发是指同时管理很多事情,这些事情可能只做了一半就被暂停去做别的事情了。
在很多情况下,并发的效果比并行好,因为操作系统和硬件的总资源一般很少,但能支持系统同时做很多事情。这种“使用较少的资源做更多的事情”的哲学,也是指导 Go语言设计的哲学。
如果希望让 goroutine 并行,必须使用多于一个逻辑处理器。当有多个逻辑处理器(CPU)时,调度器会将 goroutine 平等分配到每个逻辑处理器上。这会让 goroutine 在不同的线程上运行。不过要想真的实现并行的效果,用户需要让自己的程序运行在有多个物理处理器的机器上。否则,哪怕 Go语言运行时使用多个线程,goroutine 依然会在同一个物理处理器上并发运行,达不到并行的效果。
下图展示了在一个逻辑处理器上并发运行 goroutine 和在两个逻辑处理器上并行运行两个并发的 goroutine 之间的区别。 调度器包含一些聪明的算法,这些算法会随着Go语言的发布被更新和改进,所以不推荐盲目修改语言运行时对逻辑处理器的默认设置。如果真的认为修改逻辑处理器的数量可以改进性能,也可以对语言运行时的参数进行细微调整。
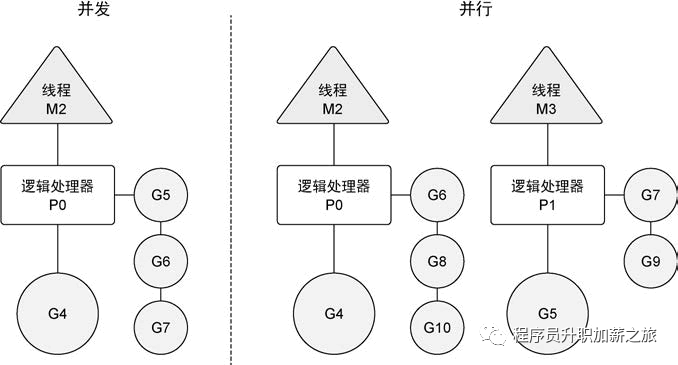
并发与并行的区别
Go 可以充分发挥多核优势,高效运行。 Go语言在 GOMAXPROCS 数量与任务数量相等时,可以做到并行执行,但一般情况下都是并发执行。
- 1.1 Goroutine
- 1.2 CSP
- 1.3 Channel
- 1.4 Lock
- 1.5 WaitGroup
1.1 Goroutine
由谁创建?
- 线程是操作系统分配给应用程序的独立执行单元,它们可以在多核处理器中并行执行。线程的调度是由操作系统内核负责的,并且线程之间有独立的地址空间。
- 协程是由程序员编写的,它是一种轻量级的线程,并由Go语言运行时管理。协程之间没有独立的地址空间,而是共享一个地址空间。协程的调度是由Go语言运行时负责的,并且可以在单个线程中并行执行。
线程的创建和销毁的开销比较大,而协程的创建和销毁开销很小,因此在需要高并发的场景中,使用协程更加高效。
大小比较?
线程栈是由操作系统分配的,它通常有一个固定的大小,并且在线程创建时分配。它存储着线程的状态信息和调用栈。线程栈的大小取决于操作系统的限制,一般在几百KB到几MB之间。
而协程的栈是由Go语言运行时管理的,它通常有一个较小的默认大小,并在协程创建时分配。它也存储着协程的状态信息和调用栈。协程栈的大小可以通过Golang的runtime包中的函数来调整,一般在几KB到几MB之间。
由于协程的栈比线程栈小,所以协程能够创建的数量比线程多得多。但是由于协程栈比线程栈小,所以在调用深度较深的程序中,协程可能会爆栈。
1.2 CSP
CSP:Communicating Sequential Processes
Go语言提倡:通过通信共享内存,而不是通过共享内存而实现通信。
有缓冲通道
缓冲通道中的数字表示该通道可以在没有接收者阻塞的情况下缓存多少个元素。
加入容量为1,所以只能缓存一个元素。如果一个新的元素试图被发送到已经满了的通道中,发送者将会阻塞直到接收者从通道中读取一个元素。
阻塞并不一定意味着数据丢失,这取决于阻塞的原因和应用程序的设计:
在 Go 语言中,通道是一种同步机制,发送者和接收者之间可以通过通道来进行通信。 如果发送者试图向一个满的缓冲通道发送数据,那么发送者将会阻塞直到缓冲区有空间可用。同样,如果接收者试图从一个空的通道接收数据,那么接收者将会阻塞直到通道中有数据可用。这种情况下,数据不会丢失,而是在缓冲区中等待被取出。
无缓冲通道
但是,如果通道是无缓冲的,那么发送者和接收者之间将是同步的。如果发送者在接收者准备好之前发送了数据,那么发送者将会阻塞直到接收者准备好。
如果接收者在数据可用之前就开始接收,那么接收者将会阻塞直到数据可用。在这种情况下,如果发送者和接收者之间的时间差较大,那么可能会导致数据丢失。
所以阻塞并不一定意味着数据丢失,而是取决于程序是否设计了阻塞的处理方式,以及阻塞的类型。
下面是一个示例代码,其中两个 goroutine 通过缓冲通道共享内存:
package main
import (
"fmt"
)
func main() {
// 创建缓冲通道
ch := make(chan int, 1)
// 启动第一个goroutine
go func() {
for i := 0; i < 10; i++ {
ch <- i // 发送数据
}
close(ch) // 关闭通道
}()
// 启动第二个goroutine
go func() {
for i := range ch {
fmt.Println(i) // 接收数据并打印
}
}()
// 等待所有goroutine结束
fmt.Scanln()
}执行效果:
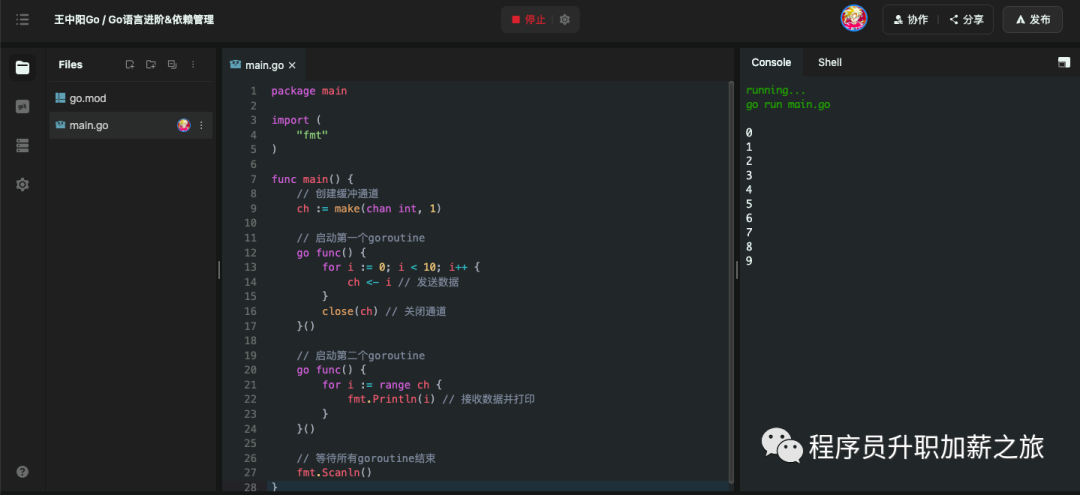
在这个示例中,第一个 goroutine 会循环发送 0 到 9 的整数,而第二个 goroutine 会接收这些整数并打印。这两个 goroutine 都会共享同一个通道来传递数据。
注意,在生产环境中,通常需要使用同步机制来等待 goroutine 结束,而不是使用 fmt.Scanln()。
1.3 Channel
make(chan 元素类型,[缓冲大小])
- 无缓冲通道 make(chan int) 同步
- 有缓冲通道 make(chan int,2) 不同步
无缓冲通道是在发送者和接收者之间同步地传递消息。 发送者会在接收者准备好接收消息之前阻塞,接收者会在接收到消息之前阻塞。这种方式可以保证消息的顺序和每个消息只被接收一次。
缓冲通道具有一个固定大小的缓冲区,发送者和接收者之间不再是同步的。 如果缓冲区已满,发送者会继续执行而不会阻塞;如果缓冲区为空,接收者会继续执行而不会阻塞。这种方式可以提高程序的性能,但是可能会导致消息的丢失或重复。
package main
import (
"fmt"
)
func main() {
// 创建通道
ch := make(chan int)
ch_squared := make(chan int)
// 启动A子协程
go func() {
for i := 0; i < 10; i++ {
ch <- i
}
close(ch)
}()
// 启动B子协程
go func() {
for i := range ch {
ch_squared <- i * i
}
close(ch_squared)
}()
//主协程输出结果
for i := range ch_squared {
fmt.Println(i)
}
}执行效果:
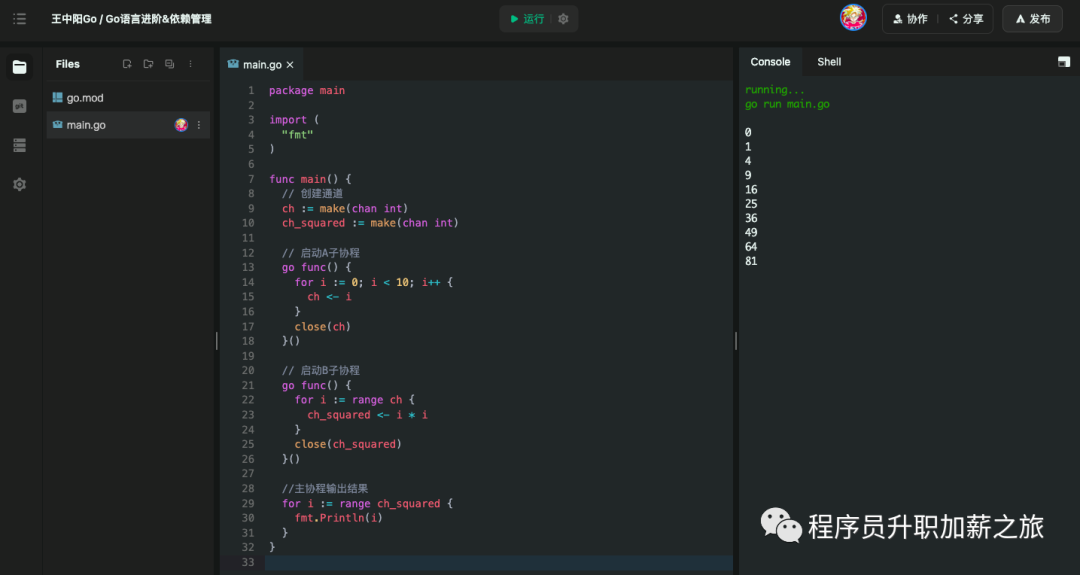
在这个程序中,A子协程循环发送0~9的数字,B子协程接收并计算数字的平方,最后主协程等待所有子协程完成后输出所有数字的平方。
- 在这个程序中我们使用了两个通道ch, ch_squared来传递数据,以避免数据丢失。
- 在最后输出结果时,主协程要等待所有子协程完成,因此我们使用了 for i := range ch_squared来等待子协程的完成
- 在生产环境中,通常需要使用同步机制来等待子协程结束,而不是使用 for i := range ch_squared。
- 可以把ch_squared改为带缓冲的channe,以解决生产比消费快的执行效率问题。
1.4 并发安全 Lock
在并发编程中,当多个 goroutine 同时访问共享资源时,可能会出现竞争条件,导致数据不一致或错误。为了避免这种情况,我们可以使用 Lock(锁)来保证并发安全。
Lock 是一种同步机制,可以防止多个 goroutine 同时访问共享资源。当一个 goroutine 获取锁时,其他 goroutine 将被阻塞,直到锁被释放。
Go语言标准库中提供了 sync.Mutex 来实现锁。
一个简单的例子:
package main
import (
"fmt"
"sync"
)
var (
count int
lock sync.Mutex
)
func main() {
wg := sync.WaitGroup{}
for i := 0; i < 10; i++ {
wg.Add(1)
go func() {
defer wg.Done()
lock.Lock()
defer lock.Unlock()
count++
fmt.Println(count)
}()
}
wg.Wait()
}执行效果:
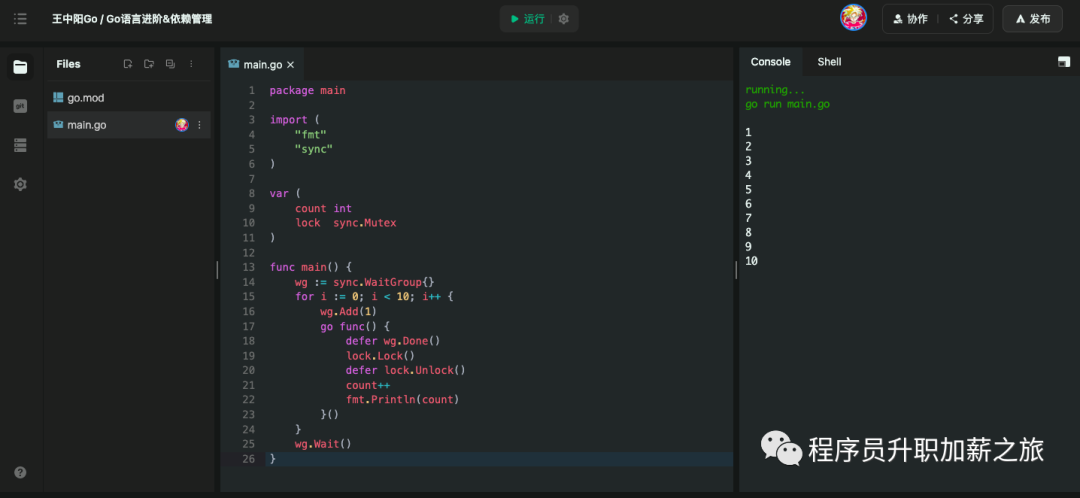
在上面的示例中,main函数中启动了10个goroutine,每个goroutine都会尝试去获取锁,并对共享变量count进行修改。在获取锁后才能进行修改,其他goroutine在等待锁时将被阻塞。
这样就能保证并发安全了,使得共享变量count在多个goroutine之间可以安全地访问。但是,使用锁也需要注意避免死锁的情况,需要在适当的时候释放锁。并发安全问题难以定位。
1.5 WaitGroup
Go语言标准库中提供了 sync.WaitGroup 来管理多个 goroutine 的执行。
- Add(delta int): 使用该方法来增加等待组中 goroutine 的数量。当我们需要等待一些 goroutine 执行完毕时,就可以使用该方法来增加等待组中 goroutine 的数量。
- Done(): 使用该方法来通知等待组,一个 goroutine 执行完毕。当一个 goroutine 执行完毕后,我们需要调用该方法来通知等待组。
- Wait(): 使用该方法来等待等待组中的所有 goroutine 执行完毕。当我们需要等待所有 goroutine 执行完毕时,就可以使用该方法。
下面是一个例子,演示了如何使用 sync.WaitGroup 来管理多个 goroutine 的执行:
package main
import (
"fmt"
"sync"
)
func main() {
var wg sync.WaitGroup
wg.Add(3) //增加3个goroutine
go func() {
defer wg.Done()
fmt.Println("Goroutine 1")
}()
go func() {
defer wg.Done()
fmt.Println("Goroutine 2")
}()
go func() {
defer wg.Done()
fmt.Println("Goroutine 3")
}()
wg.Wait()
fmt.Println("all goroutines have been finished")
}执行效果:
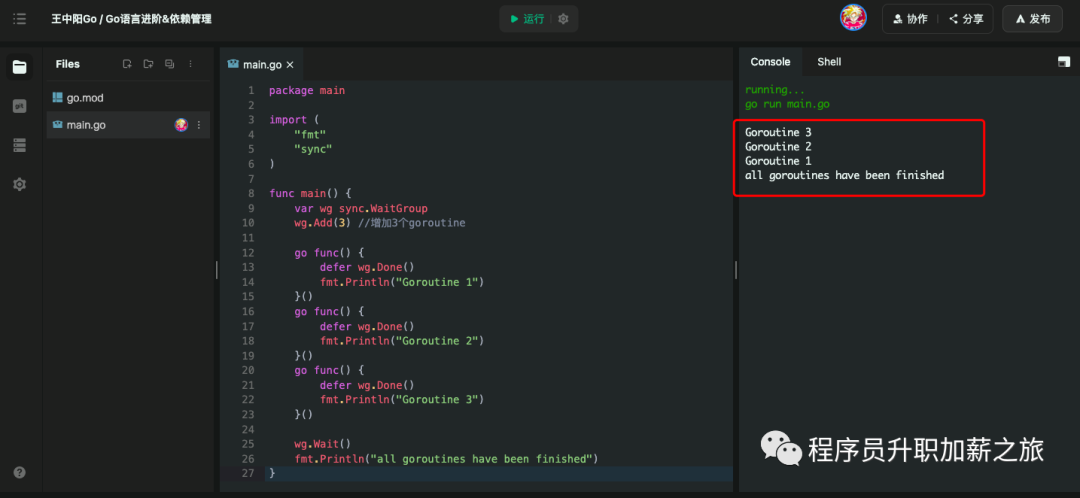
在上面的代码中,我们使用了 sync.WaitGroup 来管理三个 goroutine 的执行。我们先使用 wg.Add(3) 来增加等待组中 goroutine 的数量。然后在每个 goroutine 中调用 wg.Done() 来通知等待组,该 goroutine 执行完毕。最后使用 wg.Wait() 来等待所有 goroutine 执行完毕。
- 如果没有 wg.Wait(),主协程可能会在其他协程还没有执行完成的情况下结束,这样的话其他协程的执行结果就没有机会被获取。
- 如果Add的数量和done的数量不对应,wait永远不会返回,这也叫死锁。
上面分享的代码都支持,访问下方链接运行测试:https://1024code.com/codecubes/GB47x7u
本文转载自微信公众号「 程序员升级打怪之旅」,作者「王中阳Go」,可以通过以下二维码关注。

转载本文请联系「 程序员升级打怪之旅」公众号。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK