

Top 6 Amazon Redshift Interview Questions
source link: https://www.analyticsvidhya.com/blog/2023/02/top-6-amazon-redshift-interview-questions/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Introduction
Amazon Redshift is a fully managed, petabyte-scale data warehousing Amazon Web Services (AWS). It allows users to easily set up, operate, and scale a data warehouse in the cloud. Redshift uses columnar storage techniques to store data efficiently and supports data warehousing workloads intelligence, reporting, and analytics. It allows users to perform complex queries on large datasets in a matter of seconds, making for data warehousing and business intelligence applications. Redshift is integrated with other AWS services, EMR, and Kinesis, with its compliance features to ensure data is protected. Here, in this article, we will examine the top 6 frequently asked yet crucial Amazon Redshift Interview questions to help you bag that dream job.

Learning Objectives:
1. We will cover an overview of Amazon Redshift and its importance in data warehousing
2. Then, we will explain Redshift architecture, scalability, performance, pricing, and ease of use data loading and unloading in Redshift: COPY and UNLOAD command.
3. Further, you will get to know about the scaling of Redshift by adding or removing nodes.
4. Then, we will implement security and access control in Redshift: using AWS Identity and Access Management (IAM) and AWS Resource Access Manager (RAM).
5. Finally, we will compare Redshift with other data warehousing solutions like BigQuery, including their architecture, scalability, performance, pricing, and ease of use.
This article was published as a part of the Data Science Blogathon.
Table of Contents
- Introduction to Amazon Redshift Interview Questions
- Learning Objectives
- What is the Importance & Need of Amazon Redshift?
- How do you handle data replication and backups in Redshift?
- How do you implement security and access control in Redshift?
- How do you optimize query performance in Redshift?
- How do you handle data retention and data archiving in Redshift?
- Explain the differences between Redshift and other data warehousing solutions like BigQuery?
- Conclusion
Top 6 Amazon Redshift Interview Questions
Q1. What is the Importance and Need of Amazon Redshift?
Amazon Redshift is important for several reasons:
- Scalability: Redshift allows users to easily scale their data warehouse up or down to meet their business needs. This means the amount of data grows. Redshift can handle it without requiring time.
- Cost-effectiveness: Redshift is a fully managed service, which means that AWS handles all of the underlying infrastructure and maintenance. This can be more cost-effective than managing a data warehouse on-premises or using a cloud-based solution.
- Performance: Redshift uses columnar storage techniques to store data efficiently, which allows it to perform complex queries on large datasets in a matter of seconds. This makes for data warehousing and business intelligence applications where fast query performance is critical.
- Integration: Redshift can be easily integrated with other AWS services, EMR, and Kinesis, which allows users to easily access and analyze their data in the context of other data sources.
- Security: Redshift and compliance feature to ensure data is protected. This includes encryption at and compliance standards 2, PCI DSS, and HIPAA.
The need for Amazon Redshift comes from the growing amount of data generated by businesses. This data is often stored in various systems, making it difficult to access, analyze, and gain insights. Data warehousing services like Redshift provide a way to consolidate and organize large amounts of data in a single place, making it actionable. More companies are moving their data and workloads to the cloud. Redshift provides a way to leverage the scalability and cost-effectiveness of the cloud for data warehousing and business intelligence.
Q2. How do you Handle Data Replication and Backups in Redshift?
Handling data replication and backups in Amazon Redshift involves several steps:
Snapshots: Redshift provides a built-in data backup feature called snapshots. Snapshots are point-in-time backups that we can use to restore. You can schedule regular snapshots and retain them for days.
- Copy: You can use the “COPY” command to copy data from one table to another. This can be useful for creating backups of your data or for replicating data.
- Replication: Redshift supports multi-AZ deployments, providing automatic failover for high availability and data replication. This allows you to create a read replica of a different backup and disaster recovery.
- Encryption: Redshift supports the encryption of data at rest. This can be useful for protecting data during a data breach or other security incident.
It’s important to remember that data replication and backups are ongoing processes. Regularly schedule and test snapshots and replication to ensure that they are working properly and that you can restore your data failure or data loss.
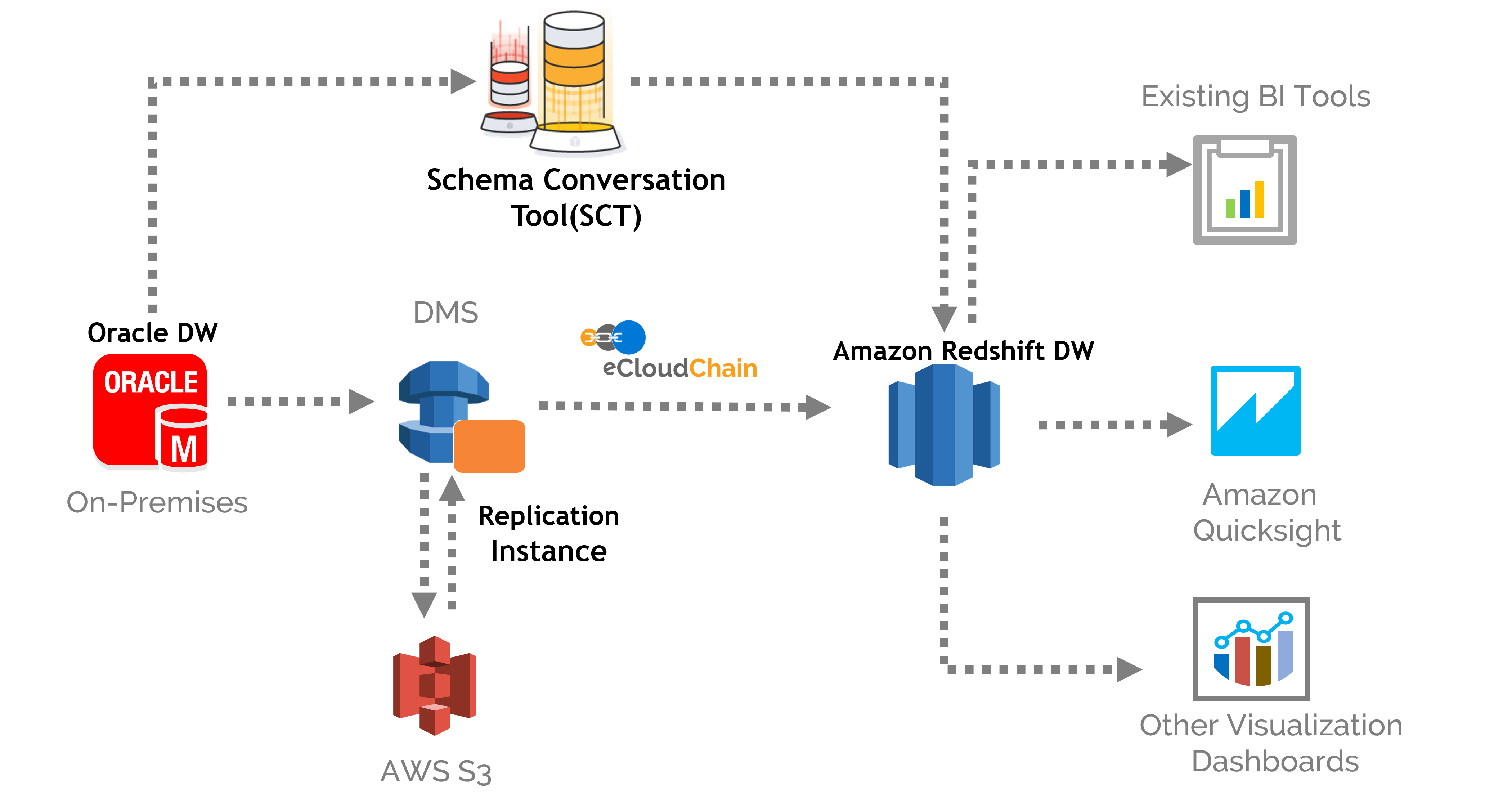
Q3. How do you Implement Security and Access Control in Redshift?

Q4. How do you Optimize Query Performance in Redshift?
Q5. How do you Handle Data Retention and Data Archiving in Redshift?
Q6. Explain the Differences between Redshift and other Data Warehousing Solutions like BigQuery?
Conclusion
In conclusion, Amazon Redshift is a powerful data warehousing service that allows businesses to store, analyze and retrieve large amounts of data cost-effectively. Redshift provides COPY and UNLOAD commands to handle data loading and unloading. To scale and use the “Resize” feature, which allows you to add or remove nodes. To optimize query performance in Redshift, we have to use distribution styles, compression, vacuum, analysis and indexing, and Redshift Query Optimizer. Finally, to handle data retention and archive in Redshift, you can use the UNLOAD command, partitioning, compaction, data governance, and data lifecycle management features. It’s important to remember that all these ongoing tasks must be reviewed and tested to ensure the best performance and security.
Key takeaways of this article:
1. Firstly, we discussed one of the most crucial topics asked in an Amazon Redshift Interview – what Amazon Redshift is and its need and importance.
2. After that, we discussed some common interview-centric questions that can be asked in an Amazon Redshift interview, like scaling the architecture, optimizing the queries, etc.
3. Finally, we discussed the comparison of Redshift with other architectures like BigQuery and then concluded that article. Some youtube links at last, which will help you to understand that topic better.
Video Resources to Reckon
Here are some video resources that you can use to learn about the topics we discussed:
These videos should provide a good starting point for learning about each topic we discussed. However, as with any video resource, it’s important to read relevant documentation and practice hands-on exercises to gain a deeper understanding of each topic.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Related
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK