

清华最新「持续学习」综述,32页详述持续学习理论、方法与应用综述
source link: https://www.51cto.com/article/745903.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

清华最新「持续学习」综述,32页详述持续学习理论、方法与应用综述
在一般意义上,持续学习明显受到灾难性遗忘的限制,学习新任务通常会导致旧任务的性能急剧下降。
除此之外,近年来出现了越来越多的进展,在很大程度上扩展了持续学习的理解和应用。
人们对这一方向日益增长和广泛的兴趣表明了它的现实意义和复杂性。

论文地址:https://arxiv.org/abs/2302.00487
本文对持续学习进行了全面的调研,试图在基本设置、理论基础、代表性方法和实际应用之间建立联系。
基于现有的理论和实证结果,将持续学习的一般目标总结为:在资源效率的背景下,确保适当的稳定性-可塑性权衡,以及充分的任务内/任务间泛化能力。
提供了最先进的和详细的分类法,广泛分析了有代表性的策略如何解决持续学习,以及它们如何适应各种应用中的特定挑战。
通过对持续学习当前趋势、跨方向前景和与神经科学的跨学科联系的深入讨论,相信这种整体的视角可以极大地促进该领域和其他领域的后续探索。
学习是智能系统适应环境的基础。为了应对外界的变化,进化使人类和其他生物具有很强的适应性,能够不断地获取、更新、积累和利用知识[148]、[227]、[322]。自然,我们期望人工智能(AI)系统以类似的方式适应。这激发了持续学习的研究,其中典型的设置是逐一学习一系列内容,并表现得就像同时观察到的一样(图1,a)。这些内容可以是新技能、旧技能的新示例、不同的环境、不同的背景等,并包含特定的现实挑战[322],[413]。由于内容是在一生中逐步提供的,因此在许多文献中,持续学习也被称为增量学习或终身学习,但没有严格的区分[70],[227]。
与传统的基于静态数据分布的机器学习模型不同,持续学习的特点是从动态数据分布中学习。一个主要的挑战被称为灾难性遗忘[291],[292],对新分布的适应通常会导致捕获旧分布的能力大大降低。这种困境是学习可塑性和记忆稳定性权衡的一个方面:前者过多会干扰后者,反之亦然。除了简单地平衡这两方面的「比例」外,持续学习的理想解决方案应该获得强大的泛化能力,以适应任务内部和任务之间的分布差异(图1,b)。作为一个朴素的基线,重新训练所有旧的训练样本(如果允许)可以轻松解决上述挑战,但会产生巨大的计算和存储开销(以及潜在的隐私问题)。事实上,持续学习的主要目的是确保模型更新的资源效率,最好接近只学习新的训练样本。
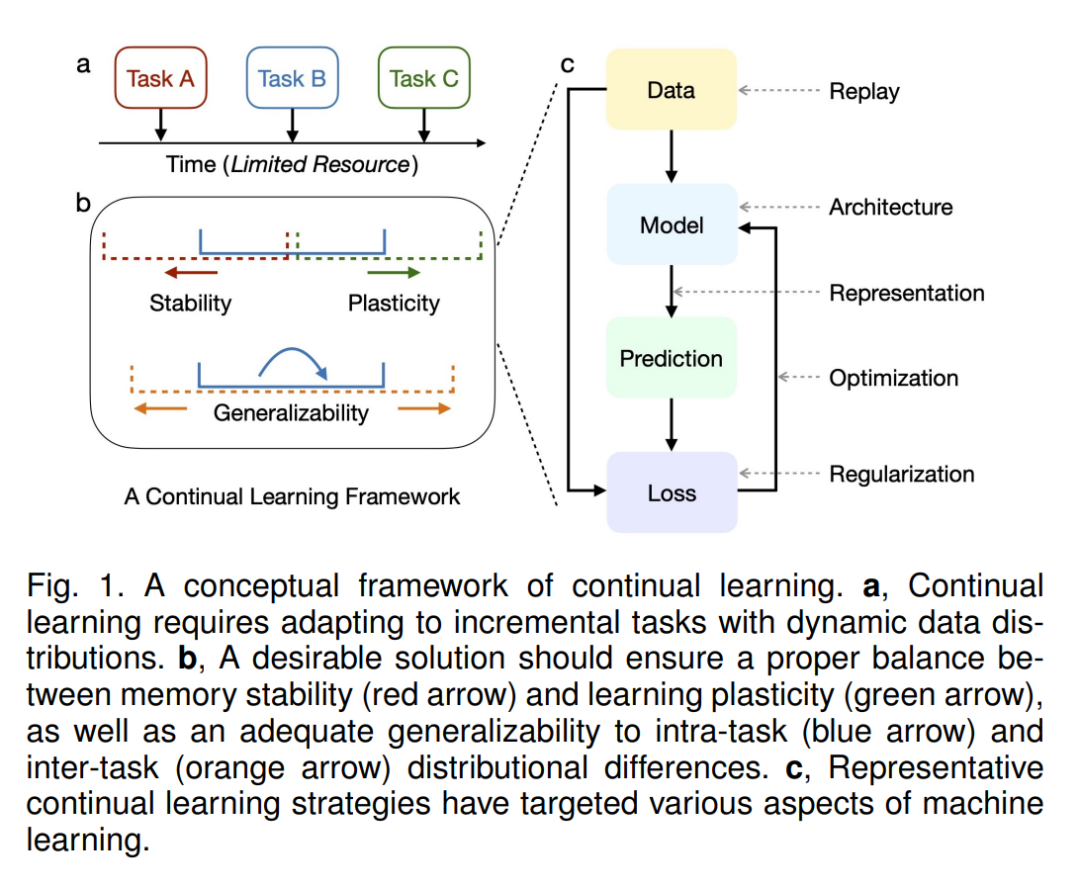
许多努力致力于解决上述挑战,可以在概念上分为五组(图1,c):参考旧模型添加正则化项(基于正则化的方法);逼近和恢复旧数据分布(基于回放的方法);显式操作优化程序(基于优化的方法);学习鲁棒和良好泛化的表示(基于表示的方法);以及使用正确设计的体系结构构建任务自适应参数(基于体系结构的方法)。该分类法扩展了常用分类法的最新进展,并为每个类别提供了细化的子方向。总结了这些方法是如何实现所提出的一般目标的,并对其理论基础和典型实现进行了广泛的分析。特别是,这些方法是紧密联系的,例如正则化和重放最终纠正优化中的梯度方向,并且具有高度的协同性,例如,重放的效果可以通过从旧模型中提取知识来提高。
现实应用对持续学习提出了特殊的挑战,可以分为场景复杂性和任务特异性。对于前者,例如,在训练和测试中可能缺少任务oracle(即执行哪个任务),训练样本可能是小批量甚至一次引入的。由于数据标记的成本和稀缺性,持续学习需要在少样本、半监督甚至无监督的场景中有效。对于后者,虽然目前的进展主要集中在视觉分类,但其他视觉领域(如目标检测、语义分割和图像生成)以及其他相关领域(如强化学习(RL)、自然语言处理(NLP)和伦理考虑)正在受到越来越多的关注,其机遇和挑战。
考虑到持续学习的兴趣显著增长,我们相信这项最新和全面的调研可以为后续的工作提供一个整体的视角。尽管有一些关于持续学习的早期调研,覆盖面相对较广[70],[322],但近年来的重要进展并未被纳入其中。相比之下,最新的调研通常只整理持续学习的局部方面,关于其生物学基础[148],[156],[186],[227],视觉分类的专门设置[85],[283],[289],[346],以及NLP[37],[206]或RL[214]中的扩展。据我们所知,这是第一个系统总结持续学习的最新进展的调研。基于这些优势,我们就当前趋势、跨方向前景(如扩散模型、大规模预训练、视觉转换器、具体AI、神经压缩等)以及与神经科学的跨学科联系,深入讨论了持续学习。
主要贡献包括:
(1) 对持续学习进行了最新而全面的综述,以连接理论、方法和应用的进步;
(2) 根据现有的理论和实证结果,总结了持续学习的一般目标,并对具有代表性的策略进行了详细的分类;
(3) 将现实应用的特殊挑战分为场景复杂性和任务特殊性,并广泛分析了持续学习策略如何适应这些挑战;
(4)深入探讨了当前研究趋势和发展方向,以期为相关领域后续工作提供参考。
本文的组织如下:在第2节中,我们介绍了持续学习的设置,包括其基本公式,典型场景和评估指标。在第3节中,我们总结了一些针对其一般目标的持续学习的理论努力。在第4节中,我们对具有代表性的策略进行了最新的和详细的分类,分析了它们的动机和典型的实现。在第5节和第6节中,我们描述了这些策略如何适应场景复杂性和任务特异性的现实挑战。在第7节中,我们提供了当前趋势的讨论,交叉方向的前景和神经科学的跨学科联系。
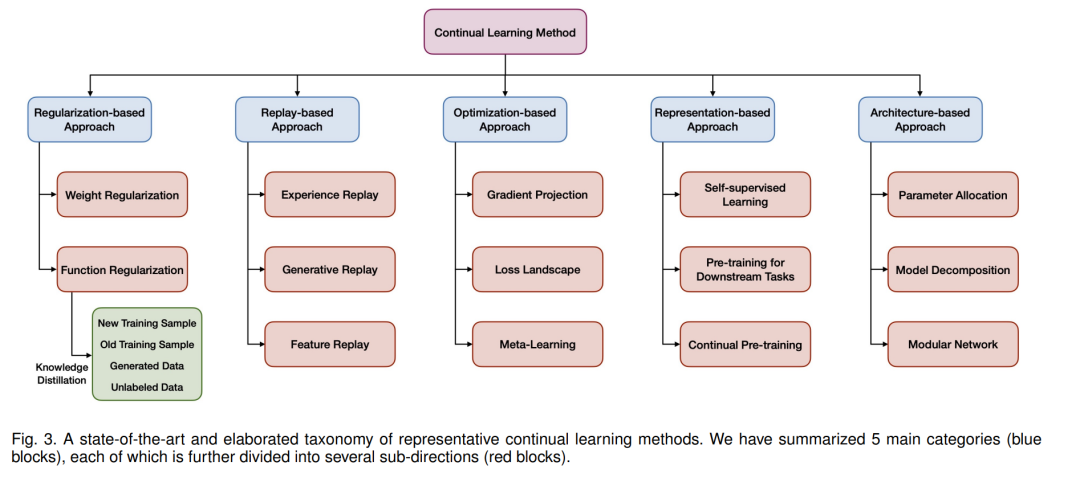
在本节中,我们详细介绍了代表性持续学习方法的分类(参见图3和图1,c),并广泛分析了它们的主要动机、典型实现和经验属性。
Regularization-based 方法
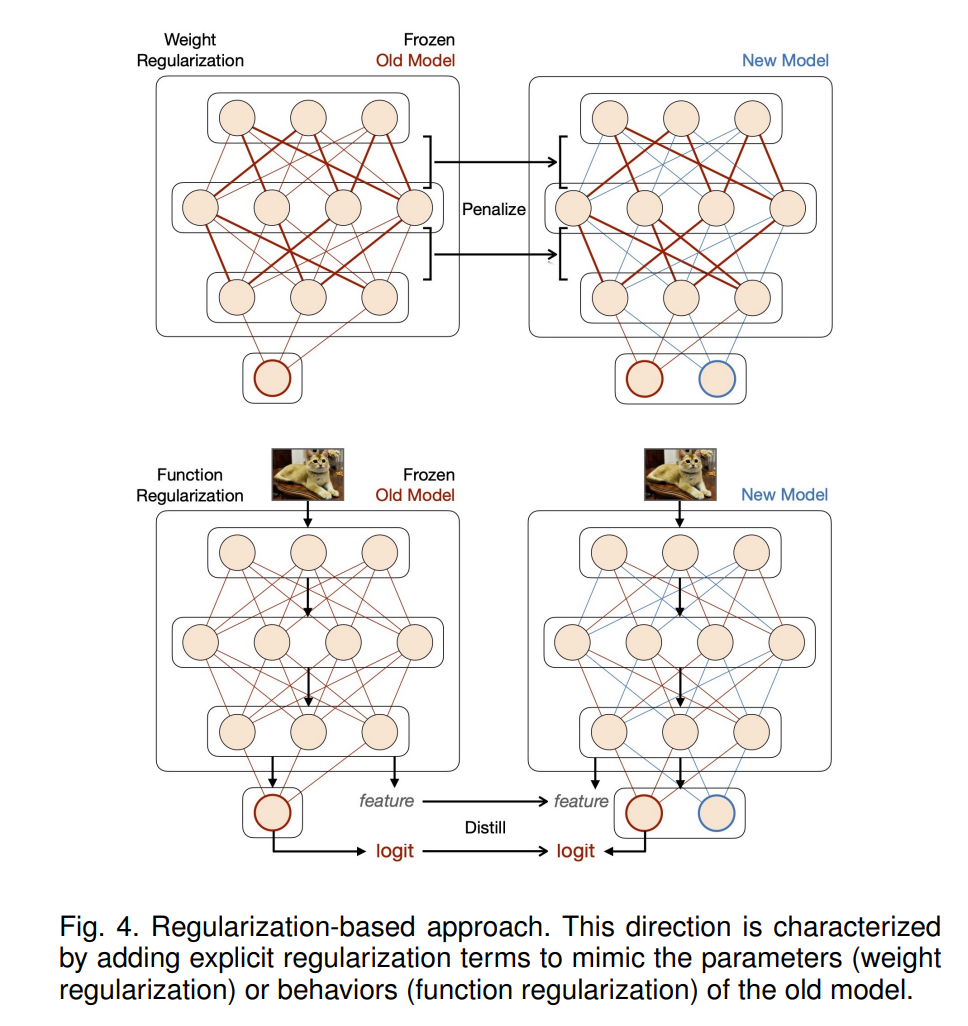
该方向的特点是添加显式正则项来平衡新旧任务,这通常需要存储旧模型的冻结副本以供参考(见图4)。根据正则化的目标,这类方法可以分为两类。
Replay-based 方法
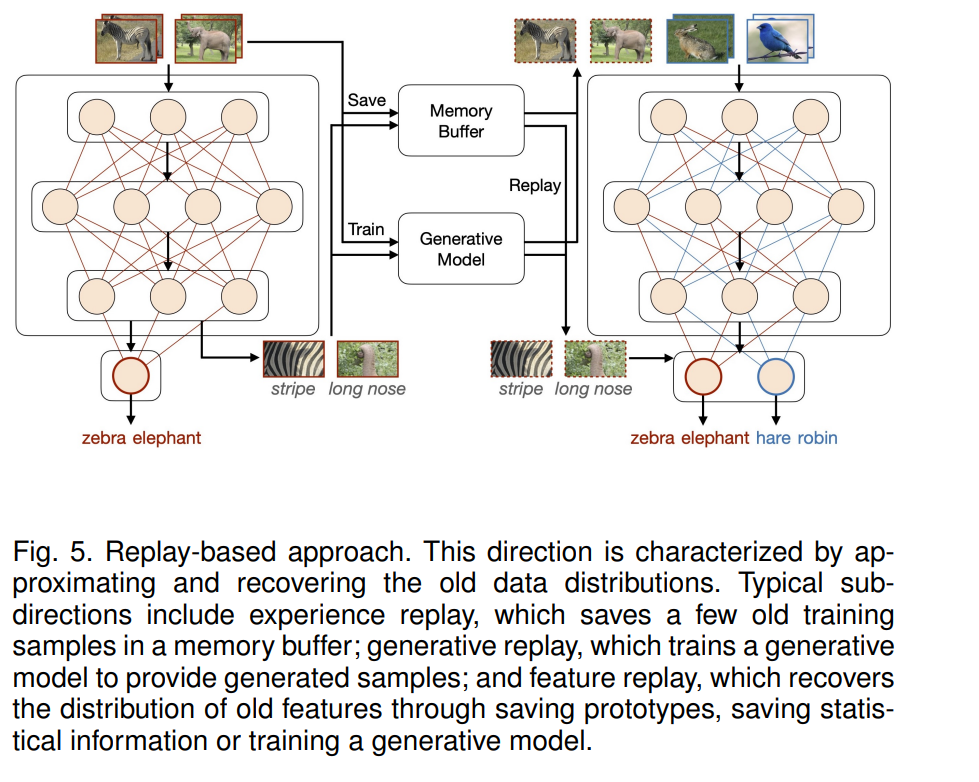
将近似和恢复旧数据分布的方法分组到这个方向(见图5)。根据回放的内容,这些方法可以进一步分为三个子方向,每个子方向都有自己的挑战。
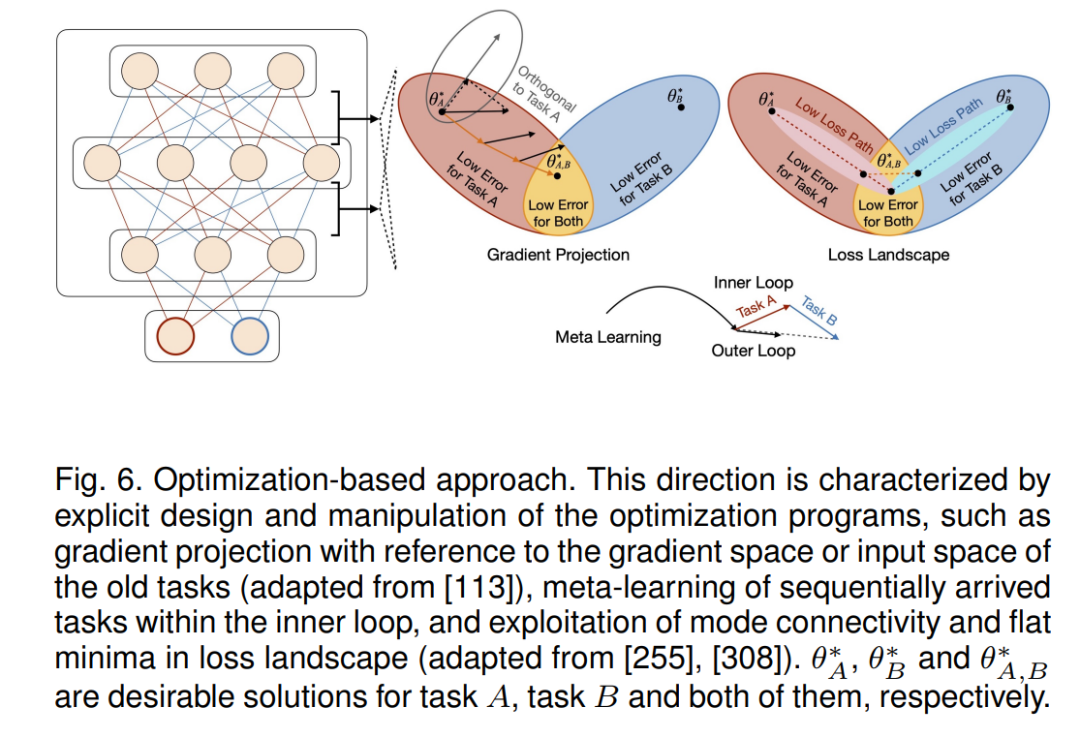
Optimization-based 方法
持续学习不仅可以通过向损失函数添加额外的项(例如正则化和重放)来实现,还可以通过显式地设计和操作优化程序来实现。
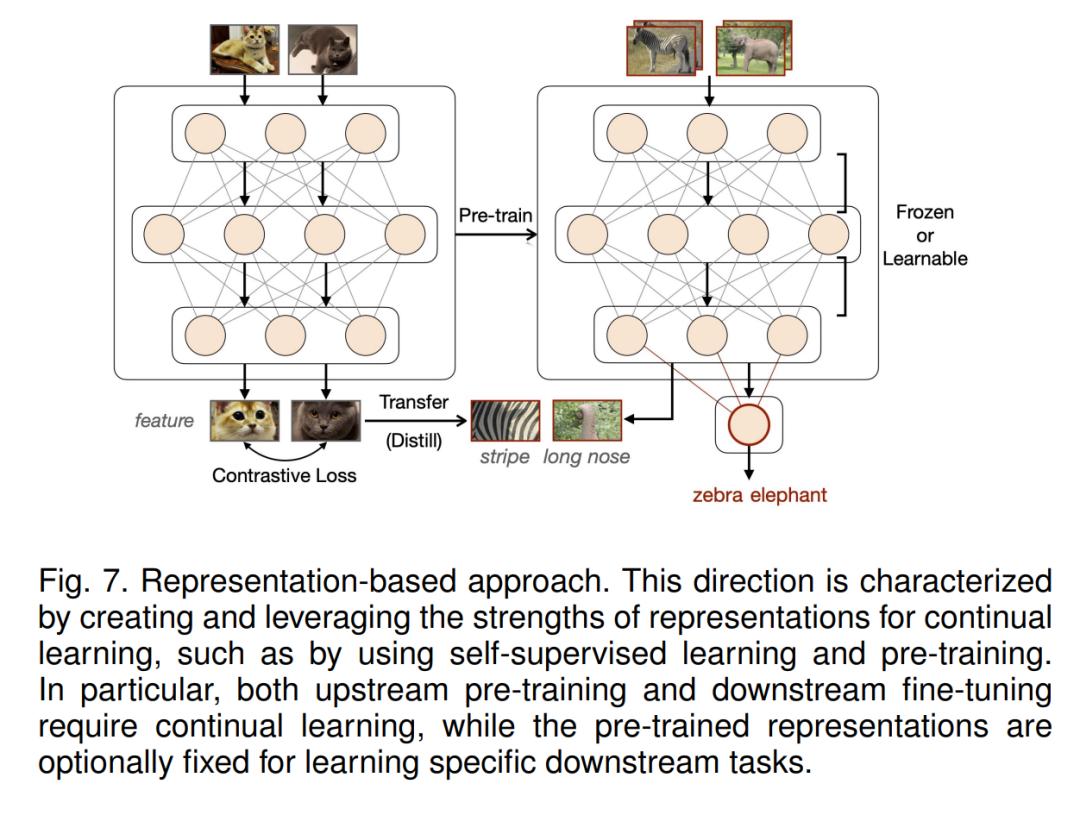
Representation-based 方法
将创建和利用持续学习表示优势的方法归为这一类。除了早期通过元训练[185]获得稀疏表示的工作外,最近的工作试图结合自监督学习(SSL)[125]、[281]、[335]和大规模预训练[295]、[380]、[456]的优势,以改进初始化和持续学习中的表示。请注意,这两种策略密切相关,因为预训练数据通常数量巨大且没有明确的标签,而SSL本身的性能主要通过对(一系列)下游任务进行微调来评估。下面,我们将讨论具有代表性的子方向。
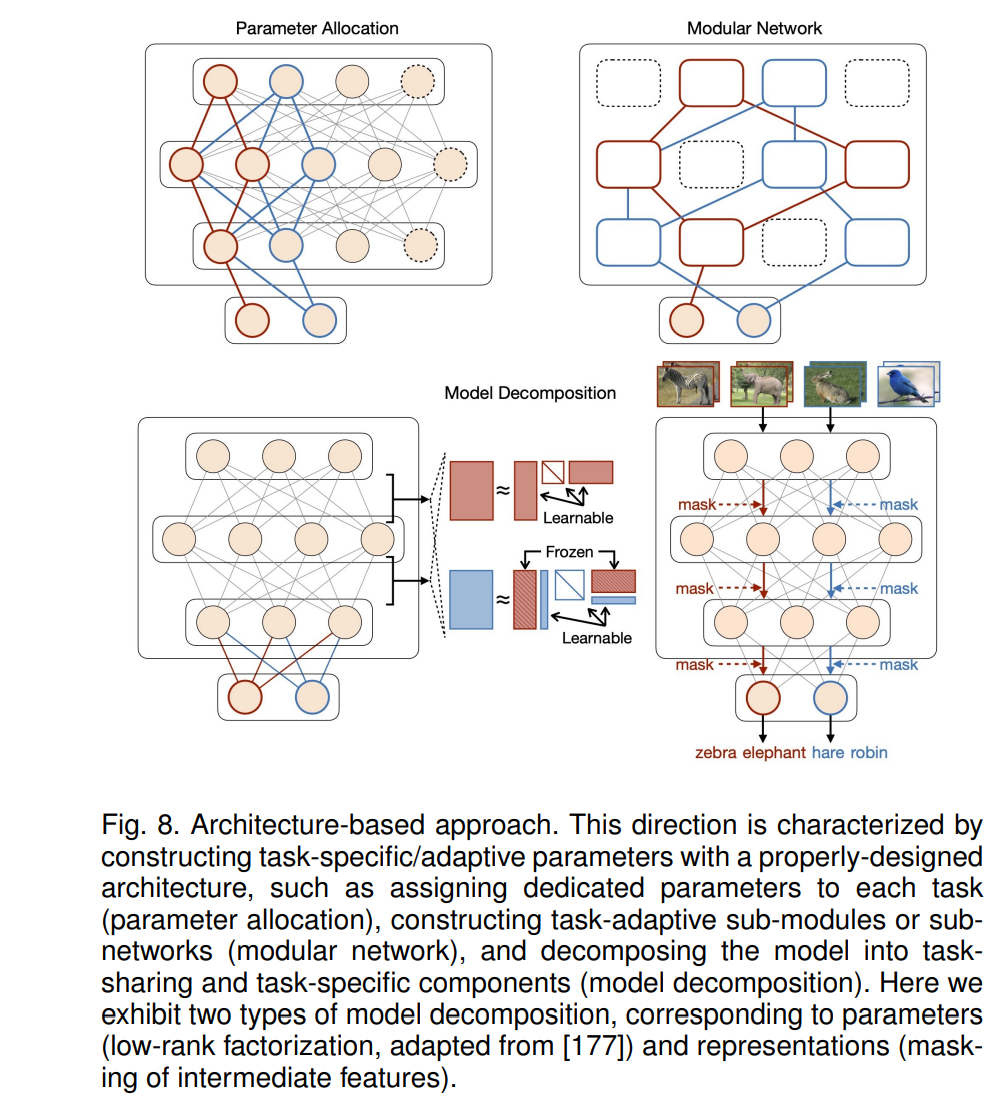
Architecture-based 方法
上述策略主要集中在学习所有具有共享参数集的增量任务(即单个模型和一个参数空间),这是导致任务间干扰的主要原因。相反,构造特定于任务的参数可以显式地解决这个问题。以往的工作通常根据网络体系结构是否固定,将该方向分为参数隔离和动态体系结构。本文专注于实现特定任务参数的方式,将上述概念扩展到参数分配、模型分解和模块化网络(图8)。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK