

用户行为分析模型实践(三)——H5通用分析模型 - vivo互联网技术
source link: https://www.cnblogs.com/vivotech/p/17090093.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

用户行为分析模型实践(三)——H5通用分析模型
作者:vivo 互联网大数据团队- Zhao Wei、Tian Fengbiao、Li Xiong
本文从提升用户行为分析效率角度出发,详细介绍了H5埋点方案规划,埋点数据采集流程,提供可借鉴的用户行为数据采集方案;且完整呈现了针对页面分析,留存分析的数仓模型规划方案,在数仓模型设计过程中遇见的痛点难点问题也相应的给出了解决思路及案例代码;在数据展示模块,提供了分析指标数据展示的逻辑流程及UI案例,旨在帮助有需要的同学全方位的了解用户行为数据全链路分析流程。
针对用户行为数据进行采集有个专业术语叫埋点,在h5页面上做的埋点统称为H5埋点。H5页面因其灵活性,便捷的交互和丰富的功能,以及在移动设备上支持多媒体等特点目前被广泛应用于网页app开发。
现阶段H5埋点的自由度较高,行业数据产品在同类高频的业务场景上设计的时间花费较多,埋点开发、埋点测试等事项耗时,且需重复劳动;同样的埋点数据分析层面-基础分析指标,留存指标,页面分析等需求需多次开发模型,浪费宝贵的人力资源。
H5通用分析模型旨在通过规范化埋点设计方案,开发设计一套通用度高,扩展方便,需求响应迅速的模型,减少行业数据产品和开发在类似需求上的人力投入,提升数据分析效率。
二、分析模型概述
2.1 术语解释

2.2 模型概述
针对业务发展的不同阶段,会有相应的数据分析需求。如图(1),在业务初期,用户的访问,留存情况等是阶段性分析重点,业务产品运营可以根据分析数据适时的调整页面布局,运营策略等;应用发展中后期可能会更多的关注订单、转化、路径等相关分析指标。如果能在应用上线之初,快速的拿到核心分析指标数据,对产品的推广,迭代无疑是收益良多。所以,本次模型构建从应用初期分析最广泛的核心指标出发,落地应用概况、页面访问、用户留存等维度全方位核心分析指标体系。
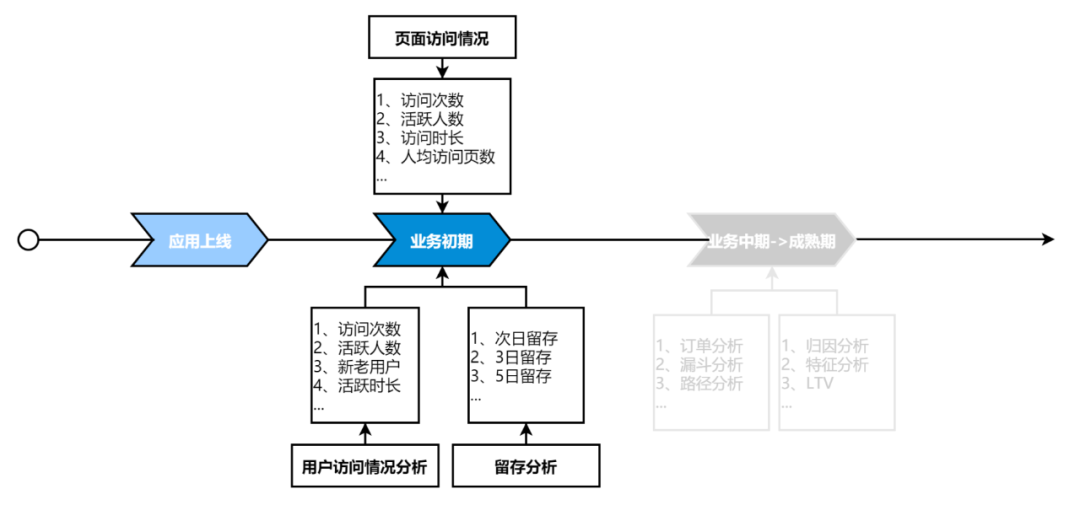
2.2.1 分析模型主题
本次通用分析模型围绕以下分析主题构建。
-
【基础分析】:从用户浏览次数,人均访问页面数,人均使用时长,新老用户等基础指标展示用户访问大盘数据。
-
【页面分析】:面向具体页面,分析用户访问pv,uv,访问时长等核心指标,有针对性的发现页面访量薄弱环节,为合理化页面管理提供数据支撑,协助产品经理通过信息重组,提升页面访问量。
-
【留存分析】:通过用户的留存,了解目前的产品现状(用户的哪些行为导致留存率的不同); 判断产品的改进有无效果(用户行为是否发生了改变导致留存率的提升);留存分析反映了用户由初期的不稳定用户转化为活跃用户,稳定用户,忠诚用户的过程。
2.2.2 分析指标定义
(以下示例中数据均为参考数据,非真实数据)
1、基础分析:访问pv,uv等指标(全维度)

2、页面分析:页面访问相关pv,uv,时长等指标

注:用户对访问页面进行命名,分析平台提供配置入口,方便用户对页面进行命名。
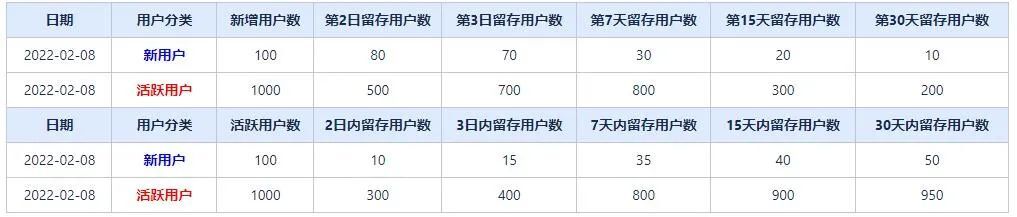
3、留存分析:新用户留存,活跃用户留存 包括:N日内留存 和 第N日留存。
通常意义上的留存分析指的是:用户在APP产生行为后,在固定的第N日继续访问或使用APP的用户;包括活跃用户留存和新用户留存
为满足不同业务的分析需求。此次留存模型包含 n日内留存分析,即用户在APP产生行为后,在固定的第N日内继续访问或使用APP的用户(日期范围留存)。
三、埋点方案
3.1 业务目标
-
采集用户的pv,uv数据,帮助产品同学了解目前的产品现状,并不断改进产品;
-
自动采集,对pv,uv等这类埋点,业务无需再开发,打开开关即可采集这类数据。
3.2 自动采集
3.2.1 什么是自动采集
自动采集是相对于前端开发者而言,目的是为了帮助前端开发者提升数据采集效率。通过自动采集开关配置,无需在手动实现上报逻辑。使用时前端开发者通过引入h5sdk.js(也称jssdk.js),打开自动采集开关,我们就会在适当的时机,以适当的规则采集数据,并进行上报。开发者无需在关注采集代码内部逻辑,以此来减轻同类数据采集的开发工作量。
3.2.2 如何自动采集
按照给定的规则进行页面事件EventListener,当用户活动触发对应的事件时,我们会组装好数据,然后将组装好的数据通过https传入到后台。
3.2.3 自动采集的三大规则场景
我们的网站是一个SPA应用。SPA应用通过改变前端路由的变化,实现页面内组件的切换。组件的切换,对于一个非前端开发者来说,可以泛指页面的切换。所以我们第一场景是要覆盖url变化的这类事件。在实践中,我们发现,当我们需要采集页面的用户停留时长时,往往会不准确。为什么不准确?用户可以缩小化浏览器,也可以切换tab到其他网站,这个时候计算的用户时长是不准确的。因为用户虽然打开了我们网页,但是并没有聚焦到我们的网页。这种不应该算作用户停留时长,因此对于这些行为,我们又加上了失去焦点,得到焦点,以及切换浏览器tab事件的EventListener,这两种场景。
综上三大场景总结如下:
-
页面切换时,进行采集,即url变化时触发的事件;
-
页面失去焦点,得到焦点时,进行采集。即focus,blur事件;
-
页面通过浏览器tab切换离开,切换回来时,进行采集,即visibilitychange事件;
3.2.3.1 三大规则场景的界定
上文我们已经在实践中总结出了自动采集的三大场景,在实际应用针对三大场景的使用我们也总结出了一套界定方案。
(1)规则一界定——怎么判断页面切换?
a、现在的网站要么是MPA,要么是SPA模式,或者两种模式混合,MPA主要是后台路由,SPA主要是前端路由(hash模式和history模式)。但无论是SPA还是MPA,当页面需要切换时,url一定会变化,基于此点,我们判断当url变化时,用户一定切换了页面。此时触发规则一的事件,产生数据上报。
这里需要注意2个问题:
-
第1个问题:url变化 = window.location.origin + window.location.pathname + window.location.hash 这三部分的任一部分变化,即为url变化,并不包括window.location.search这部分的变化;
-
第2个问题:在SPA中,如果一个页面内有多个tab,当切换tab时,开发者也改变他的url的window.location.pathname,此时也会认为是页面切换,也会产生上报数据,如下这种情况。
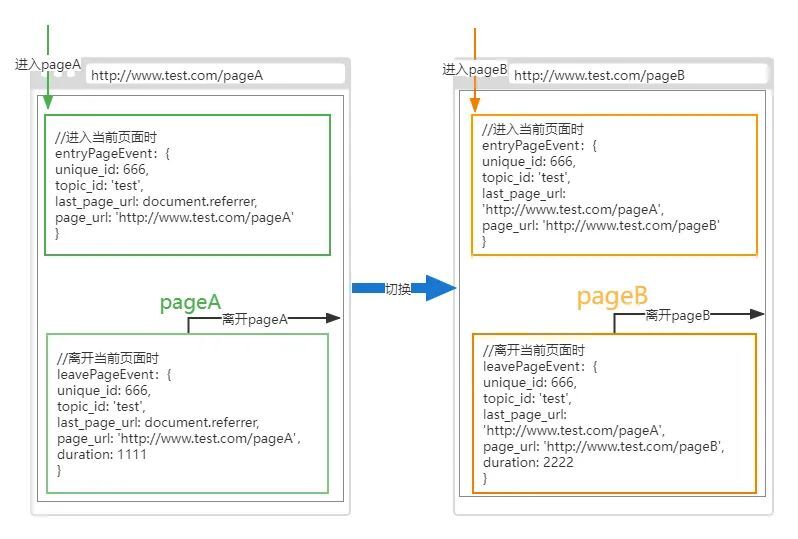
b、完整页面切换上报流程,由页面A切换到页面B时,一共上报4个埋点;
c、关于路由的EventListener
现在的大多网站,大多是SPA应用,SPA的前端路由有hash模式和history模式这两种模式,当通过前端路由来页面切换时,肯定会触发hash模式或history相关的api。
因此,我们只需要把所有触发事件的场景给全部进行EventListener即可。有如下2种路由的EventListener:window.hashchange事件——触发hash模式时、window.popstate事件、pushstate,replacestate自定义事件——触发history模式时。
这里有2个问题需要关注:一是当某个SPA应用的路由事件,触发了history模式时,我们应该移除hash模式的EventListener。二是pushstate,replacestate自定义事件,因为BOM并没有提供相关的api支持EventListener,需要自行封装使用,如下code。
引入JSSDK
/*** 拼接通用化上报参数* @param {string} 重写路由事件类型*/function resetHistoryFun(type){// 将原先的方法复制出来let originMethod = window.history[type]// 当window.history[type]函数被执行时,这个return出来的函数就会被执行return function(){// 执行原先的方法let rs = originMethod.apply(this, arguments)// 然后自定义事件let e = new Event(type.toLocaleLowerCase())// 将原先函数的参数绑定到自定义的事件上去,原先的是没有的e.arguments = arguments// 然后用window.dispatchEvent()主动触发window.dispatchEvent(e)return rs;}}window.history.pushState = resetHistoryFun('pushState') // 覆盖原来的pushState方法window.history.replaceState = resetHistoryFun('replaceState') // 覆盖原来的replaceState方法window.addEventListener('pushstate', reportBothEvent) window.addEventListener('replacestate', reportBothEvent) |
(2)规则二界定——怎么判断页面失去焦点,得到焦点?
失去焦点,得到焦点。我们主要进行如下这两个事件的EventListener:
引入JSSDK
window.addEventListener('focus', ()=>{console.log('页面得到焦点')});window.addEventListener('blur', ()=>{console.log('页面失去焦点')}) |
(3)规则三界定——怎么判断浏览器tab切换离开,切换回来?
tab切换离开,切换回来。我们主要进行如下这一个事件的EventListener:
引入JSSDK
document.addEventListener('visibilitychange', () => {if(document.hidden) {console.log('页面离开')} else {console.log('页面进入')}}) |
注意:如果一个行为同时满足2个及2个以上的规则时,只会取一个规则上报数据。避免不重复上报数据。
3.3 埋点设计
3.3.1 埋点个数
为了得到pv和uv的相关数据,我们设计了2个埋点,1个为页面进入时上报的埋点,另外1个为页面离开时的埋点,上报的数据都是一对的,离开-进入页面为一对,失去焦点-得到焦点为一对,切换tab离开当前页面-返回当前页面也为一对;
为什么要设计2个埋点?设计2个埋点,能覆盖全面上述我们所说的3种规则场景;其次,方面计算页面停留时长;最后就是方便逻辑判断,避免重复上报;
3.3.2 参数的设计
按照不同的需求,参数的设计分为如下4类:
-
pv,uv需要参数,开发者传入参数:unique_id——标识用户唯一标识、topic_id——当前网站唯一标识、current_env——当前网站环境,默认为prod,可用户传入;
-
pv,uv需要参数,sdk内部获取参数:duration——页面停留时长、last_page_url——上个页面url、page_url——当前页面url;
-
SDK需要的参数,帮助判断事件触发类型,SDK内部获取参数:eventType
-
用户其他需要补充的参数:自定义参数
3.4 数据上报
数据上报方式是XMLHttpRequest、window.navigator.sendBeacon,基于h5sdk上报逻辑架构。
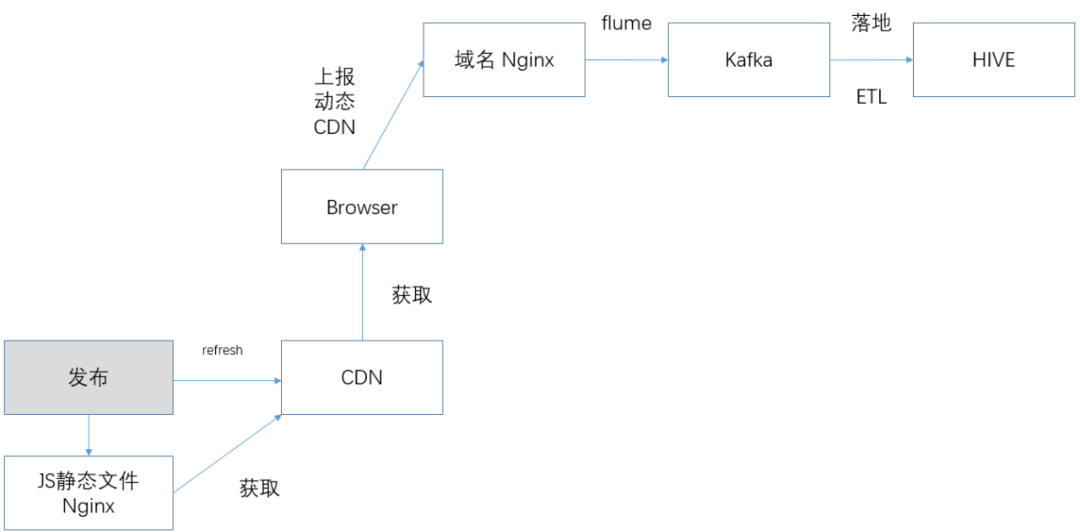
3.5 兼容性和容错性
关于兼容性,依赖于window对象、不兼容IE6、IE7,IE8;
关于容错性,对通用化内部逻辑做了try catch的容错兼容,保证出错时不影响业务主逻辑运行,同时上报一个出错的事件类型,知道出错的原因,以便提前做好对应的优化方案。
3.6 个人数据保护合规
为了保护好用户的个人数据及其隐私并满足法律法规要求,在埋点的设计、采集、使用等环节需要进行充分的隐私保护设计。例如,在埋点设计阶段,需要确定标识符的选择、埋点参数的最小必要、采集频率的最小必要等;在埋点的采集、使用阶段,需要确保相关处理行为的透明、可控,包括对用户进行告知,获取用户的有效同意,提供撤回同意的渠道等等。
四、数仓方案
埋点方案已经具备,接下来的工作就是设计一套接入高效,拓展便捷的数仓分析模型;为实现以上既定的分析目标,模型设计过程中需要解决以下核心问题。
4.1 核心问题列表

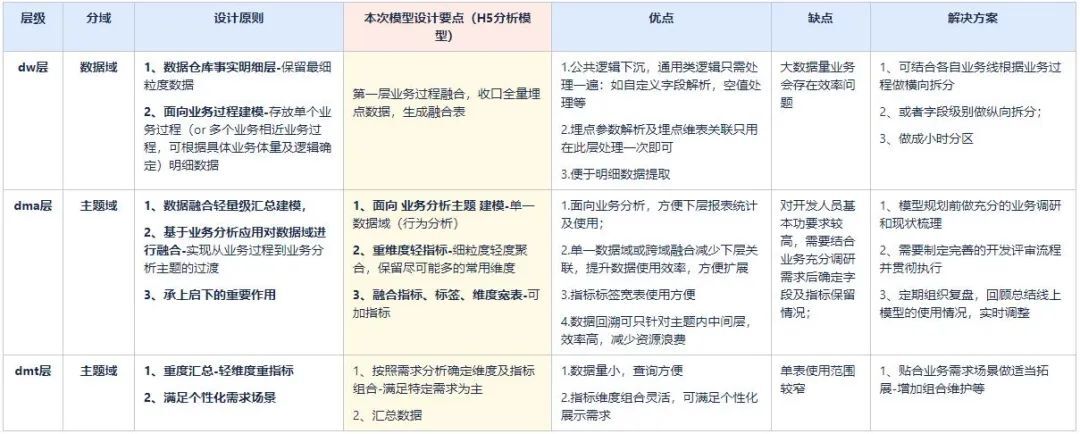
4.2 模型分层标准
介绍模型设计前,先说下vivo 数仓模型分层基本原则,及本次模型分层思路,各层模型设计原则参照《vivo中台数仓建设方法论》,层级设计摘要如下:
4.3 模型层级架构
通过核心问题拆解发现,为实现通用分析模型方案,需要从数据接入层收口,在数据接入时统一参数解析,统一字段命名,并设置相应的应用id字段,区分各个业务数据源;接着需要生成活跃数据明细表,可统计相应的基础分析,页面分析指标;同时为满足留存分析的需要,我们需要构建相应的活跃全量表,留存分析主题表基于活跃增量表和活跃全量表生成,用户活跃信息通过打标签的方式标记。至此涉及三个主题分析的模型规划完毕。层级划分原则及规划逻辑模型明细,如:图(5)
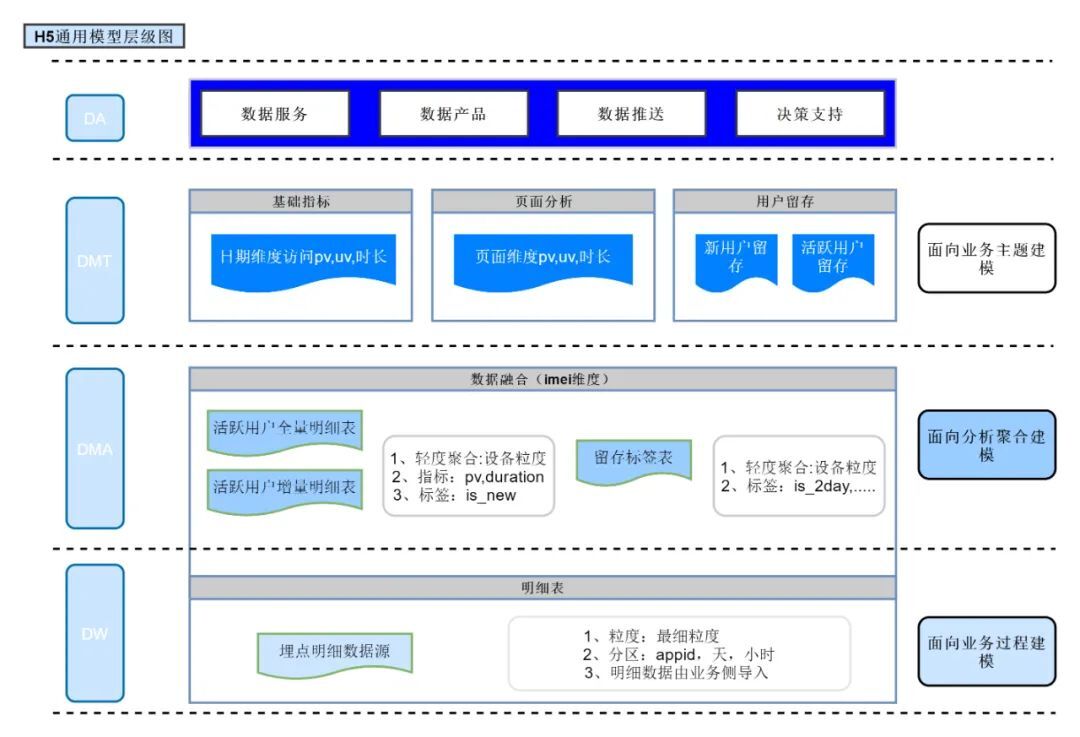
从分层架构图可看出H5通用分析模型分为明细层(dw)、轻度汇总层(dma)、分析主题表 (dmt) 和指标层(da); 其中轻度汇总层可作为中间数据提供行业分析师及数据开发、业务产品等查询分析使用;汇总层作为分析平台通用分析模型报表数据源,导入mysql存储,前端基于mysql表实现数据展示,各个模型设计细则如下:
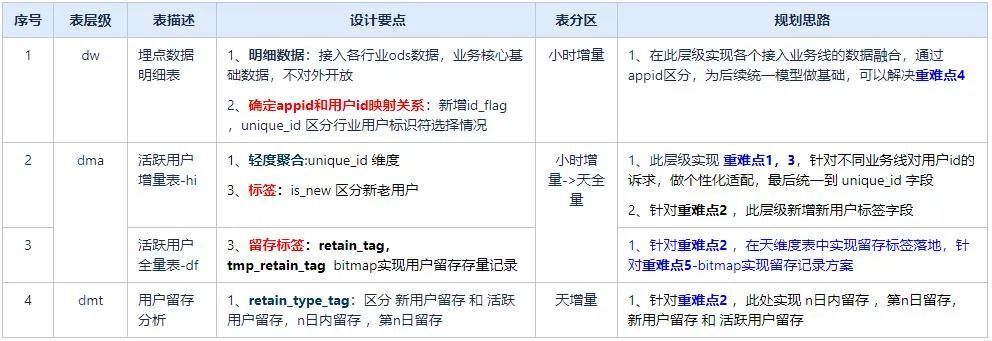
数据模型规划及设计的核心在于三点:确定appid和用户id映射关系,留存方案实现及留存记录入库bitmap方式读写。
1、确定appid和用户id映射关系-unique_id 关联设计
多业务id统一
## 明细层收口数据,统一id字段SELECT xx,xx1,CASE WHEN appid IN(1) THEN 1 WHEN appid IN(2) THEN 2 WHEN appid IN(3) THEN 3 WHEN appid IN(4,5,6,...) THEN 4 ELSE 0 END AS id_flag ,CASE WHEN appid IN(1) THEN id1WHEN appid IN(2) THEN id2WHEN appid IN(3) THEN id3 WHEN appid IN(4,5,6,...) THEN IF(NVL(params['id1'],'')='',NVL(params['id2'],'NA'),params['id1']) ELSE 'NA' END AS unique_id ,appid FROM ods_table_name_XXX a -- 各个接入业务线数据源 odsWHERE day='${today}'AND hour = '${etl_hour}'-- APPID 和 事件id 要匹配新增AND appid in (1,2,3 ...)AND 事件id in (XXX|167,XXX|168,...);## id字段后续关联使用方式## 增量关联全量,确定是否新用户SELECT if(b.unique_id is null,1,0) AS is_newFROM(SELECT *FROM table_XXX_hiWHERE day= '${today}'AND hour = '${etl_hour}'GROUP BY XX) a-- 取全量表唯一 unique_id 作为关联条件,判断新老用户-- 新用户是相对于历史全量的LEFT JOIN ( SELECT unique_id,appidFROM ( SELECT unique_id,appid,row_number() over(partition by unique_id,appid order by 活跃日期 asc) as rn_0FROM table_XXX_dfWHERE day='${etl_date}') aWHERE rn_0 = 1) bON a.unique_id = b.unique_id AND a.appid = b.appid; |
2、留存方案实现及留存记录入库bitmap方式读写
## 利用bitmap思想,留存标签满8位转化为16进制组合到retain_tag之前,这样可以利用很少的位数记录较长的活跃情况## 示例代码如下SELECT user_unique_id,if(length(tmp_retain_tag) = 8,is_active,concat(is_active,tmp_retain_tag)) as tmp_retain_tag-- 如果tmp_retain_tag长度为8的时候,将数据转化为十六进制添加到retain_tag前,并将本字段清空,从头开始计数,if(length(tmp_retain_tag) = 8,concat(con_tmp_retain_tag,retain_tag),retain_tag) as retain_tag,is_activeFROM(SELECT unique_id-- 前一天的临时存储,与con_tmp_retain_tag保持一致,tmp_retain_tag -- 如果转换为十六进制后的长度不为2,则在左边添加0 ,if(length(conv(tmp_retain_tag,2,16)) = 2,conv(tmp_retain_tag,2,16),concat('0',conv(tmp_retain_tag,2,16))) as con_tmp_retain_tag -- 历史轨迹,retain_tag ,first_value(is_active) over(partition by unique_id,appid,topic_id order by first_active_day desc) as is_activeFROM( SELECT unique_id,topic_id,appid ,first_active_day,last_active_day-- 留存标签,'0' as is_active,tmp_retain_tag -- 形如 11101010,retain_tag -- 形如 A0E3FROM table_active_XX_df -- 活跃全量表WHERE day= '${last_etl_date}'UNION ALLSELECT unique_id,topic_id,appid ,day as first_active_day,day as last_active_day-- 留存标签 ,'1' as is_active,'' as tmp_retain_tag,'' as retain_tagFROM table_active_XX_hi -- 活跃明细表WHERE day= '${etl_date}') a) bWHERE rn =1;## 留存指标统计:## 以3日内及第3日留存为例WITH tmp_table AS (SELECT DAY,unique_id,appid,首次活跃日期,CONCAT(tmp_retain_tag,retain_tag) AS login_trace FROM (SELECT DAY,unique_id,tmp_retain_tag,appid,首次活跃日期,IF(nvl(retain_tag,'') <> '',CONV(SUBSTR(retain_tag,1,8),16,2),'') AS retain_tag-- 如果retain_tag为空时,直接取空值。如果长度超过8位数,取最后八位数;如果长度不超过8位数,取全部。如果是30日内新用户,长度不超过8位FROM table_active_XX_df WHERE DAY = 统计日) x1)## 以3日内及第3日留存为例:SELECT -- 第N日留存指标:第N日来访,SUM(IF(SUBSTR(login_trace,3,1) = '1',1,null)) AS retain_cnt_3th-- N日内留存指标:N日内访问过1次或N次,SUM(IF(instr(SUBSTR(login_trace,2,2) ,'1')= 0,null,1)) AS retain_cnt_between_3thFROM (SELECT '统计日-2天' AS dt,unique_id,REVERSE(SUBSTR(login_trace,1,3)) AS login_trace,appidFROM tmp_table WHERE SUBSTR(login_trace,3,1) = '1' AND 首次活跃日期 = 统计日-2天) X GROUP BY dt,appid; |
4.4 模型数据流图
至此,模型的设计落地全部完成,模型包含埋点数据表2张,dw明细层模型1张,维表1张,dma轻度汇总主题层2张,dmt主题表2张,任务层深4层,模型层2层,模型数据接入0.5人日可完成。
数据流图如下:
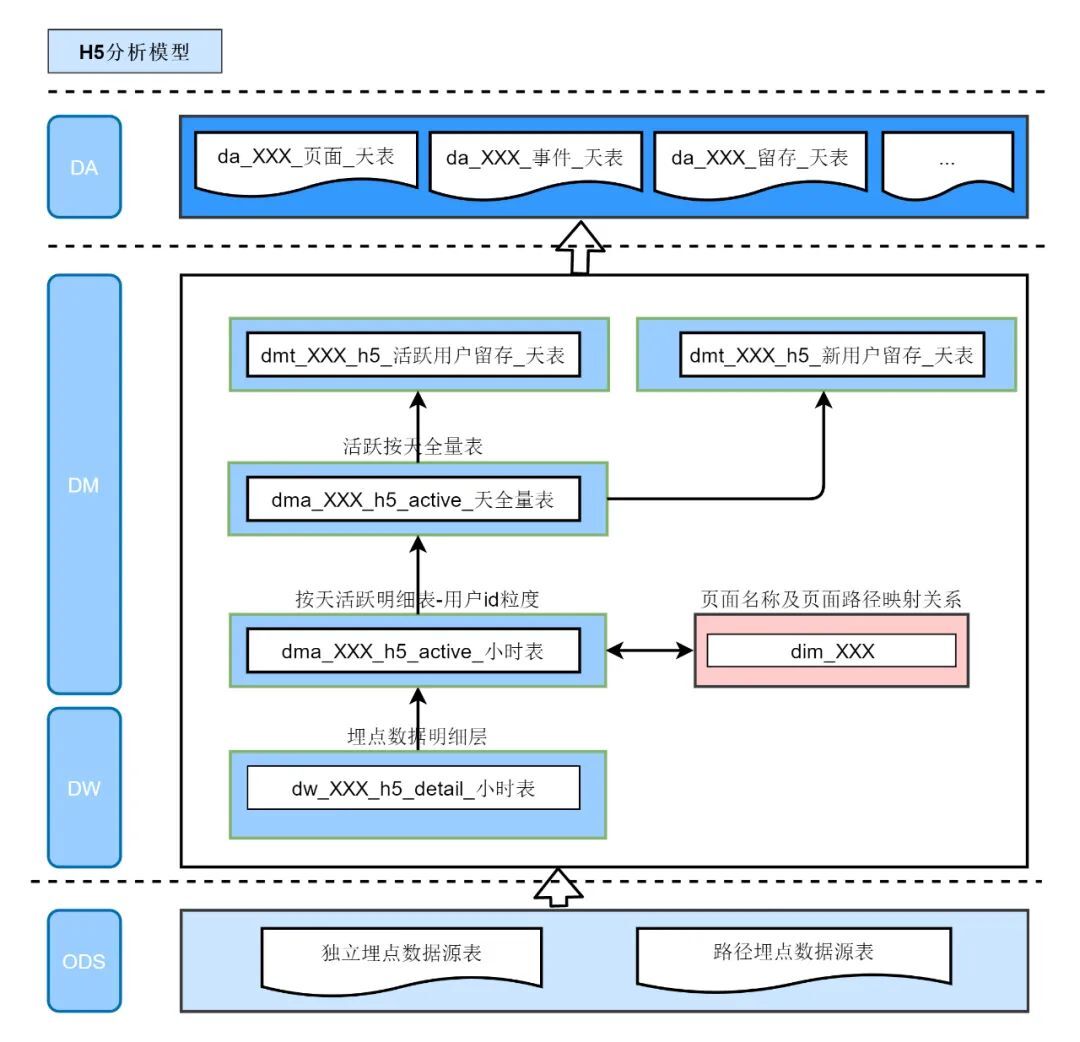
五、数据展示
模型数据展示可基于用户行为分析平台,数据指标存储使用 MySQL 数据库,数据展示逻辑实现如下:
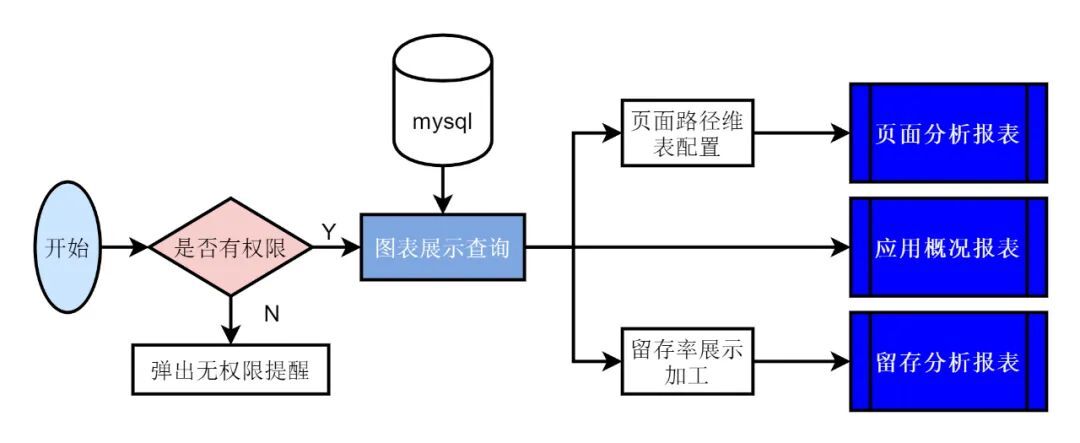
5.1 报表展示
报表配置完成后,各个分析模块的前台展示示例如下:
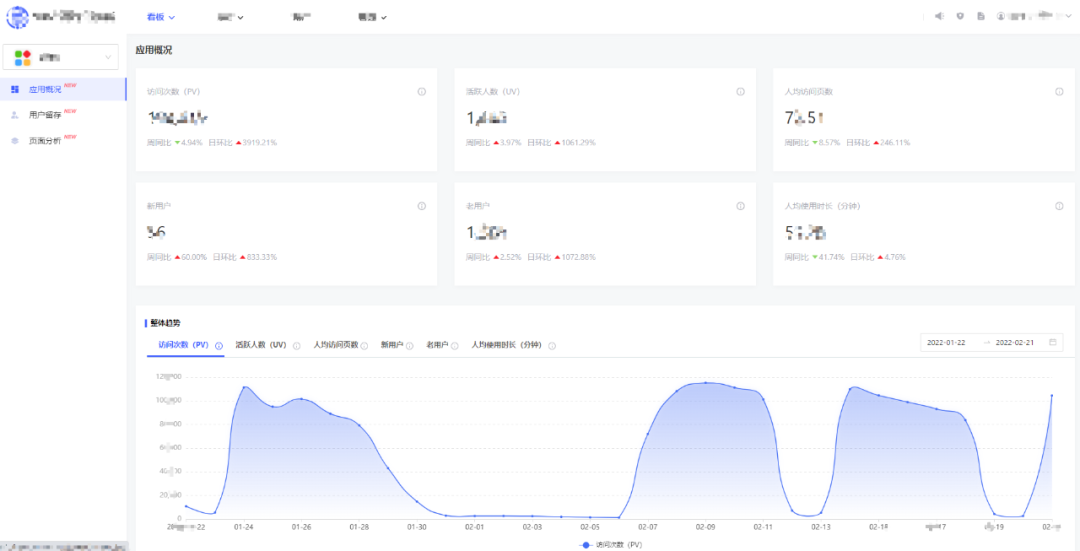
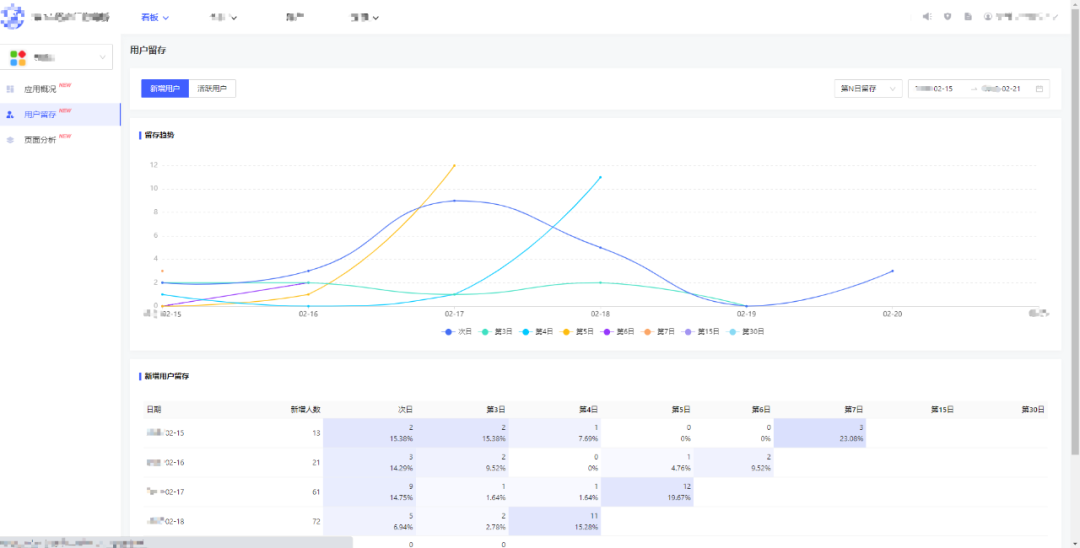
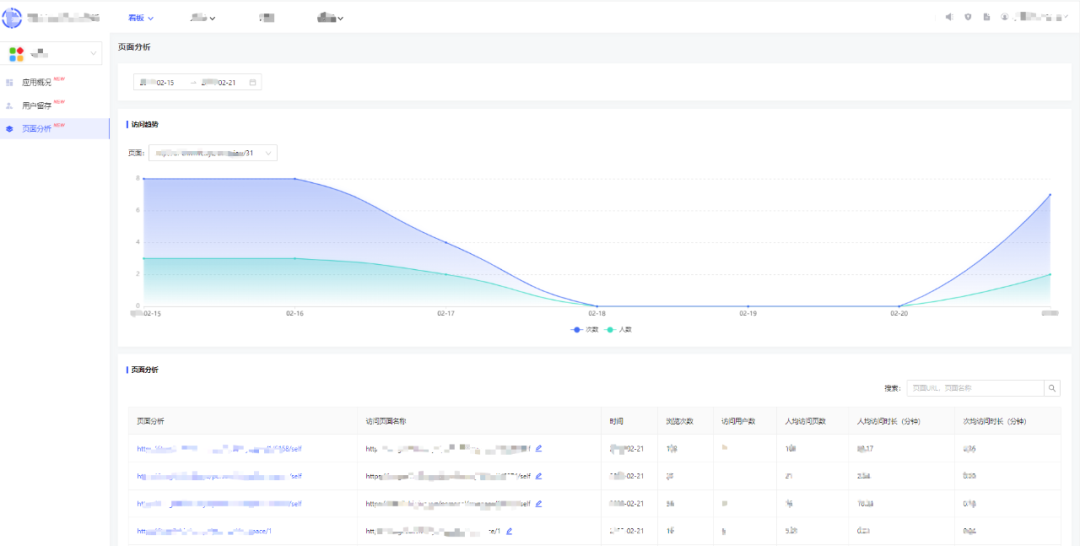
六、未来展望
至此,H5通用分模型落地流程已介绍完毕。本文主要是基于业务初期诉求,快速落地通用的、统一的数据解决方案,满足业务分析人员在产品初期最迫切的分析需求。随着业务的不断发展迭代,运营产品的分析方向也会不断的扩展和深入,同时不同的业务关注点不同,针对分析模型的诉求也不尽相同。例如在业务中后期,简单的访问留存分析已经支撑不了更进一步的决策制定,此时针对页面访问的路径分析模型;针对营销分析的订单转化模型、归因分析模型;针对页面跳转分析的用户漏斗模型等需求会相应变多。
所以,为更好的支撑业务目标达成,H5通用分析模型系列在后期会根据业务诉求落地相应的分析模型,持续为产品运营提供高效稳定的数据解决方案。
相关文章:
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK