

基于 Next.js 建立文档站点
source link: https://oldj.net/article/2023/02/03/docs-site-based-on-nextjs/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

基于 Next.js 建立文档站点
复杂项目的运营中,文档站点通常不可或缺,比如我正在开发维护的 WonderPen 软件,虽然我一直努力让各个功能都尽可能简明易懂,但当软件的功能复杂到一定程度之后,用户对文档的需求仍然与日俱增,因为总有一些功能难以做到一看就明白,同时也总有一些功能的入口不会直接显示在主界面,如果没有说明,用户可能要花很长时间才能发现。
为了构建文档站点,我尝试过很多方案,最后选择了基于 Next.js 自建,本文记录了一些相关经历。
文档站点主要用于存放产品的使用和帮助说明,内容一般是纯静态的,可不必支持用户留言、评论等功能,从功能角度来讲比较简单。
对文档站点,我的需求主要有以下几点:
- 最好能使用 Markdown 写文档;
- 支持多语言(暂时只有中文、英文的需求);
- 能提前批量修改或新建文档,然后再在指定的时间统一发布更新。
其中第一、第二两点无需多说,关于第三点“批量修改、统一发布”,应该是软件或类似分版本发布的产品共同的需求。举个例子,比如软件现在最新的版本是 2.2 版,下一个版本将会是 2.3 版,2.3 版可能有很多变化,相应地,文档也需要做对应的变更,比如修改相关的功能说明(也许有几个至几十个页面),更新对应的界面截图等等,并且需要在 2.3 版发布时同步更新上线。
对这样的需求,使用语雀等在线知识库就不是很合适,虽然它们的功能很强大,但发布粒度是基于文档的,很难实现批量修改多个文档,并在指定时间统一发布。目前,要实现这个需求,基本上需要使用专门的文档站点方案,如 VuePress、Docusaurus 等,并用 Git 等工具来管理文档版本。当然,也有一些托管的方案,比如 GitBook、Read the Docs 等,但这些托管方案通常只对开源项目免费,同时在样式风格上也有很多限制。
一些之前的尝试
最早的时候,我使用 VuePress 来构建文档站点,因为这个方案对前端开发来说非常简单。后来,我发现 Docusaurus 支持更多功能,于是又将文档站点迁移到了 Docusaurus。几个月前注意到新发布的 VitePress 界面挺好看,也动过迁移到 VitePress 的念头,可惜 VitePress 对多语言的支持迟迟没有完全实现(注:VitePress 于 2023-01-17 发布的 1.0.0-alpha.37 版中已支持多语言),于是暂时放弃。
Docusaurus 等方案虽然很强大,也提供了很多自定义项,但使用了一段时间后,我发现仍然存在一些问题,主要如下:
- 站点的信息结构比较适合呈现技术文档,方便技术人员阅读,但对普通用户不是很友好;
- 虽然提供了很多自定义选项,但要让风格和自己的网站足够匹配仍然比较难。
在比较了各大流行的文档站点方案后,我发现要让文档站点真正合心,最好的选择应该还是花一点时间,基于某个基础框架自建。
自建文档站点
有了自建的想法之后,首先就是方案的选择。一开始,我考察了 Stripe 团队出的 Markdoc 方案,这个方案看起来很强大,内容以及样式都可以完全由自己控制,唯一的问题是,Markdoc 对 Markdown 的语法做了一些扩展,可以说是一种新的 Markdown 方言了,我比较担心如果用这种方案实现了文档站点,将来万一又想迁移到其他方案,迁移工作量恐怕会很大。
最后,经过综合考虑,我决定放弃 Markdoc 等方案,而是基于 Next.js 直接实现一个文档站点,在这个站点中,文档仍然是以 Markdown 格式编写和保存,用户在访问对应路径时看见的是渲染之后的 HTML 页面。
这样一个站点的原理其实非常简单,它就是一个普通的 Next.js 站点项目,目录结构如下所示:
site/
├─ docs/
│ ├─ wonderpen/
│ │ ├─ guides/
│ │ │ ├─ editor.zh.md
│ │ │ ├─ editor.en.md
├─ pages/
│ ├─ index.tsx
│ ├─ [...slug].tsx
├─ ...
省略的部分与常规 Next.js 站点一样,不同之处在于有一个 docs 目录,所有 Markdown 格式的文档都放在这个目录下,每个 .md 文件都将对应一个文档页面。同时,在 pages 目录下有一个 [...slug].tsx 文件,当收到请求时,如果 pages 下没有直接匹配的路径,Next.js 会将请求转给 [...slug].tsx 处理,而 [...slug].tsx 则会去 docs 目录下查找是否有匹配的 Markdown 文件,如果有,则将其渲染为 HTML 页面,否则返回 404 错误。
整个流程如下图所示:
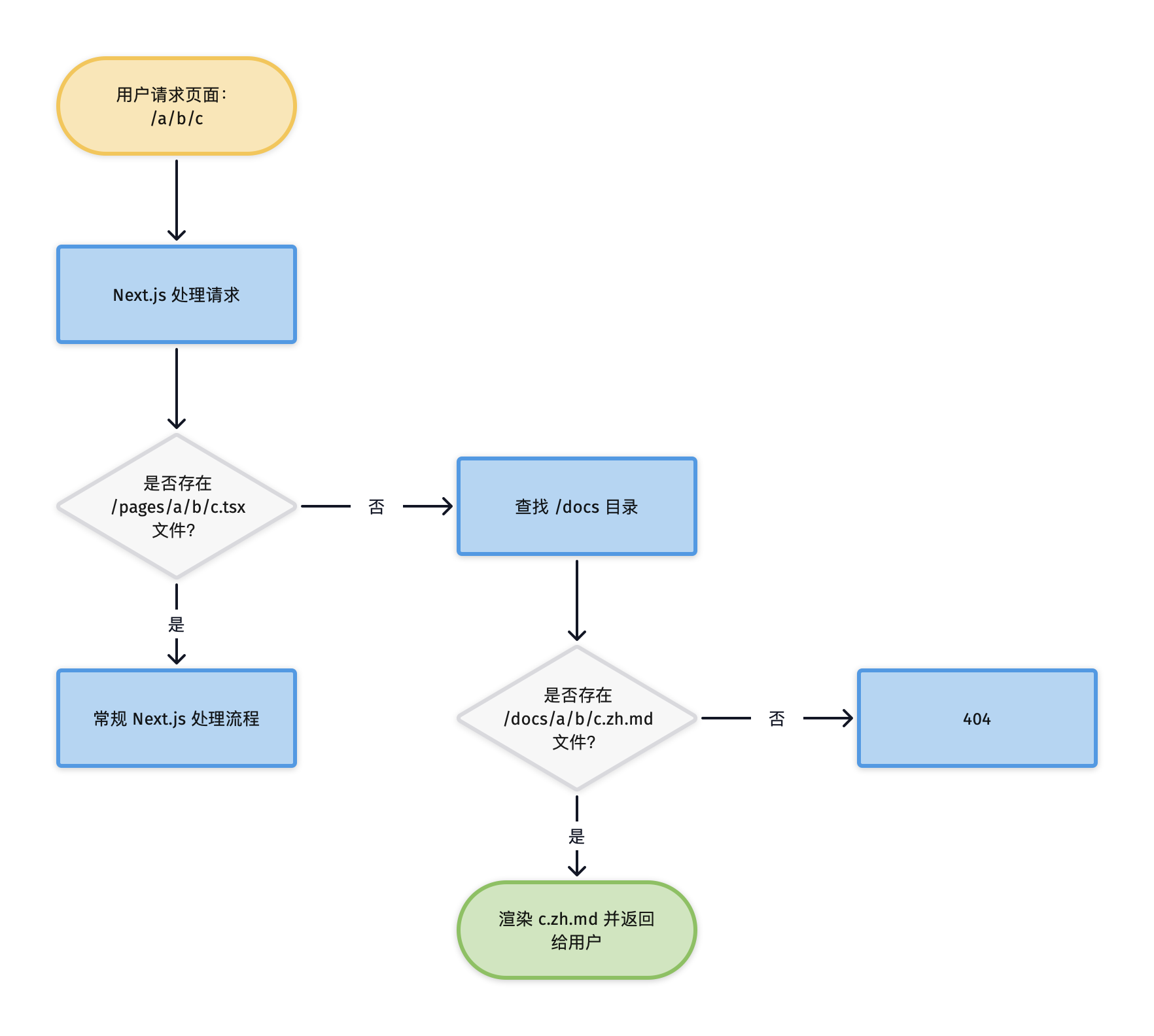
我将所有 Markdown 文件放在了根目录下的 docs 目录下,这不是必须的,你也可以放在其他你喜欢的目录,只要后续在 [...slug].tsx 中能根据请求路径读取到对应的文件即可。
同时,我将不同语言的 Markdown 放在了一起,只在文件名后缀中加以区分,比如 editor.zh.md 是中文文档,editor.en.md 是对应的英文文档。
在 Docusaurus 等方案中,不同语言的翻译文件需要放在专门的 i18n 目录下,比如:i18n/en/docusaurus-plugin-content-docs/current/guides/editor.mdx 。这种方式将多语言文件当作类似插件或游戏中的 MOD 来处理,每种语言的文件都在自己单独的文件夹中,方便管理和多人协作,每种语言的翻译者只要处理自己目录下的文件即可,但在实践中,这种组织方式有时也会带来不便。
其中一个不便是,多数情况下,各个语言的文档需要同步更新,当我修改了某个文档的中文版时,它对应的英文版常常也需要同时修改。在 Docusaurus 中,不同语言的文件位于不同的文件夹中,改完一个语言后,需要在复杂的目录树中寻找其他语言对应的文件,这个操作有点麻烦。所以,为什么不直接将它们放在同一个目录下,只是用不同的后缀来区分呢?
参考 Docusaurus 等方案,我在每个 Markdown 文件的头部以 YAML 的格式放置了一些元信息,如下所示:
---
title: 编辑器
---
Markdown 正文……
文件头部分还可以根据需要添加更多自定义信息,比如文档图标等等。解析文件时,先读取使用 --- 标记出的文件头,用 YAML 库解析,然后再读取后面的 Markdown 正文,使用 markdown-it 等库渲染为 HTML。
这个方案最关键的部分,是获取请求 URL 中的路径,读取对应的 Markdown 文件并渲染。
这部分的工作,可以在 [...slug].tsx 的 getServerSideProps 中处理。主要代码如下:
export async function getServerSideProps(
ctx: GetServerSidePropsContext,
): Promise<GetServerSidePropsResult<IProps>> {
const { query, locale } = ctx
let slug = query.slug
let key = Array.isArray(slug) ? path.join(...slug) : slug
if (!key) {
return { notFound: true }
}
// parseDocFile 负责读取 Markdown 文件并解析
let data = await parseDocFile(key, locale || 'en')
if (!data) {
return { notFound: true }
}
return {
props: {
title: data.metadata.title,
content: data.html,
},
}
}
其中 parseDocFile 的主要代码如下:
export default async function parseDocFile(
key: string,
locale: string = 'en',
): Promise<IDocFile | null> {
let fn = `${key}.${locale}.md`
if (fn.startsWith('/')) {
fn = fn.slice(1)
}
fn = path.join(base_dir, 'docs', fn)
let data = cached[fn] || ''
if (data) {
return data
}
if (!isFile(fn)) {
return null
}
try {
let source = await fs.promises.readFile(fn, 'utf-8')
let data = parseSource(source)
if (!is_dev) {
// 缓存数据,提升速度
cached[fn] = data
}
return data
} catch (e) {
console.error(e)
return null
}
}
一些关键点如下:
base_dir需要使用process.cwd()获取,而不能用__dirname等路径再计算相对路径;- 由于站点正式发布之后 Markdown 内容不会变化,因此可以将解析及渲染结果缓存起来,让每个路径只在首次访问时读取并渲染一次,以提升运行效率。
具体的解析和渲染工作是在 parseSource() 方法中实现,这部分就是简单地调用相关库(比如 markdown-it),此处就不再赘述了。
至此,构建一个支持 Markdown 的文档站点的关键部分就完成了,当然,要让这个站点更易用,还有不少细节工作需要完善,比如实现导航索引等功能。
这个方案原理很简单,不过对小型文档站点而言已经足够,能完全满足我的需求,由于站点页面完全由自己控制,因此页面样式可以根据需要深度定制,确保与主站的整体风格保持一致。
唯一的不足,是本地开发时,修改 Markdown 文件后页面不能自动刷新,不过这个小缺点对我而言影响不大。
在研究和使用了多种文档站点方案之后,我开始尝试基于 Next.js 自建文档站点方案。
自建方案的技术原理很简单,取得用户请求的路径,寻找对应的 Markdown 文件,解析并渲染为 HTML 。
最后,这个自建的文档站点已经上线,欢迎访问 WonderPen 帮助中心 查看效果。站点目前托管在 Vercel 上,运行成本基本为零。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK