

被OpenAI CEO取关后,Yann LeCun再次抨击:ChatGPT对现实的把握非常肤浅
source link: https://tech.sina.com.cn/csj/2023-02-02/doc-imyehtzq6651038.shtml
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

被OpenAI CEO取关后,Yann LeCun再次抨击:ChatGPT对现实的把握非常肤浅
2023-02-02 13:24:04 创事记 微博 作者: 机器之心 我有话说(0人参与)
机器之心报道
编辑:蛋酱、杜伟
尽管 Yann LeCun 或者一部分学者对 ChatGPT 的评价不高,但其商业化的成功仍是不可阻挡的。
大佬之间的关系,有时真是扑朔迷离。
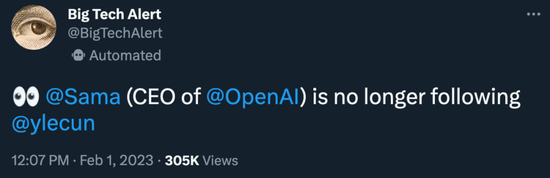
昨天,有人发现,OpenAI CEO Sam Altman 已经在推特上取关了 Meta 首席人工智能科学家 Yann LeCun。
我们很难确定这次取关发生的具体时间点,但基本能够确定事件原因 —— 几天前,Yann LeCun 在前段时间的一次小型媒体和高管在线聚会上发表了自己对 ChatGPT 的看法:
‘就底层技术而言,ChatGPT 并没有什么特别的创新,也不是什么革命性的东西。许多研究实验室正在使用同样的技术,开展同样的工作。’
在 ZDNet 的‘ChatGPT is ‘not particularly innovative,’ and ‘nothing revolutionary’, says Meta‘s chief AI scientist’报道中,LeCun 演讲的一些细节被披露出来。其中有一些很惊人的评价:
-
‘与其他实验室相比,OpenAI 并没有什么特别的进步。’
-
‘ChatGPT 使用的 Transformer 架构是以这种自监督的方式预训练的。自监督学习是我很长一段时间以来一直倡导的,甚至可以追溯到 OpenAI 出现之前。’
-
‘Transformer 是谷歌的发明,这类语言项目的工作可以追溯到几十年前。’
如此,Sam Altman 的取关行动也是情有可原。
在‘取关’被人发现的四个小时后,Yann LeCun 更新了动态,再次转发了一篇‘阴阳’ChatGPT 的文章:
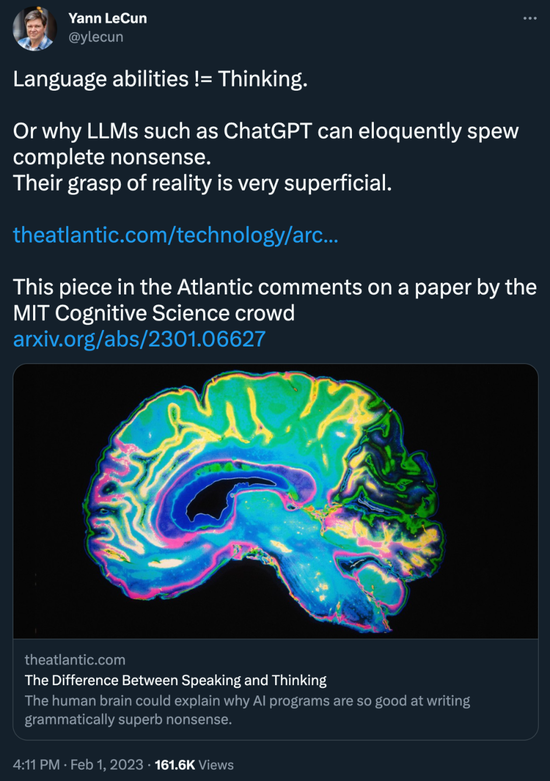
为什么像 ChatGPT 这样的大型语言模型可以滔滔不绝地胡说八道?它们对现实的把握是非常肤浅的
有人就不同意了:‘ChatGPT 是广泛知识和巨大创造力的源泉,已经在大量书籍和其他信息源上接受过训练。’
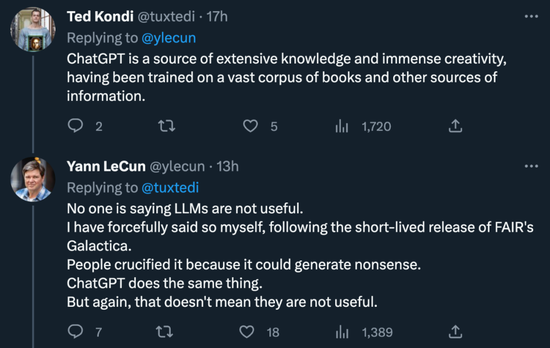
对此,LeCun 也表明了自己观点:‘没人说 LLM 没用。FAIR 的 Galactica 短暂发布期间,我自己也曾这么说过。人们把它钉在十字架上,因为它会产生胡说八道。ChatGPT 做了同样的事情。但同样,这并不意味着它们没有用。’
实际上,这篇《大西洋报》的文章是对麻省理工学院认知科学小组的一篇论文进行了评论。让我们看一下具体的研究内容。
这篇论文说了啥?
这篇论文的标题为《Dissociating Language and Thought in Large Language Models: a Cognitive Perspective》,作者分别来自得克萨斯大学奥斯汀分校、MIT 和 UCLA。

论文地址:https://arxiv.org/pdf/2301.06627.pdf
我们知道,如今的大型语言模型(LLM)通常能够生成连贯、合乎语法且看起来有意义的文本段落。这一成就引发了人们的猜测,即这些网络已经是或者很快将成为‘思维机器’,从而执行需要抽象知识和推理的任务。
在本文中,作者考虑了两个不同方面的语言使用表现来观察 LLM 的能力,分别如下:
-
形式语言能力,包括给定语言的规则和模式知识;
-
功能语言能力,现实世界中语言理解和使用所需的一系列感知能力。
借鉴认知神经科学的证据,作者表明人类的形式能力依赖特定的语言处理机制,而功能能力需要语言之外的多种能力,它们构成了形式推理、世界知识、情境建模和社会认知等思维能力。与人类的两种能力区别相似,LLM 在需要形式语言能力的任务上表现出色(尽管还不完美),但在很多需要功能能力的测试中却往往失败。
基于这一证据,作者认为,其一现代 LLM 应该被认真地作为具备形式语言技能的模型,其二玩转现实生活语言使用的模型需要合并或开发核心语言模块以及建模思维所需的多种非特定语言的认知能力。
总之,他们认为,形式语言能力和功能语言能力之间的区别有助于理清围绕 LLM 潜力的讨论,并为构建以类人方式理解和使用语言的模型提供了途径。LLM 在很多非语言任务上的失败并没有削弱它们作为语言处理的良好模型,如果以人类的思维和大脑作为类比,未来 AGI 的进步可能取决于将语言模型以及代表抽象知识和支持复杂推理的模型相结合。
ChatGPT 数学水平仍需要提升
LLM 在语言之外的功能能力(如推理等)方面有所欠缺,OpenAI 的 ChatGPT 正是一个例子。虽然此前官宣数学能力再升级,但被网友吐槽只能精通十以内的加减法。
近日在一篇论文《Mathematical Capabilities of ChatGPT》中,牛津大学、剑桥大学等机构的研究者在公开可用和手工制作的数据集上测试 ChatGPT 的数学能力,并衡量了它与在 Minerva 等数学语料库上训练的其他模型的性能。同时通过模拟数学家日常专业活动(问答、定理搜索)中出现的各种用例,来测试 ChatGPT 是否可以称为专业数学家的有用助手。

论文地址:https://arxiv.org/pdf/2301.13867.pdf
研究者引入并公开了一个全新数据集 —— GHOSTS,它是首个由数学研究人员制作和管理的自然语言数据集,涵盖了研究生水平的数学,并全面概述语言模型的数学能力。他们在 GHOSTS 上对 ChatGPT 进行了基准测试,并根据细粒度标准评估性能。
测试结果显示,ChatGPT 的数学能力明显低于普通数学研究生,它通常可以理解问题但无法给出正确答案。
每月 20 美元,ChatGPT Plus 大会员上线
不管怎么说,ChatGPT 在商业上的成功是有目共睹的。
刚刚,OpenAI 宣布了‘ChatGPT Plus’,一项每月 20 美元的新付费会员服务。
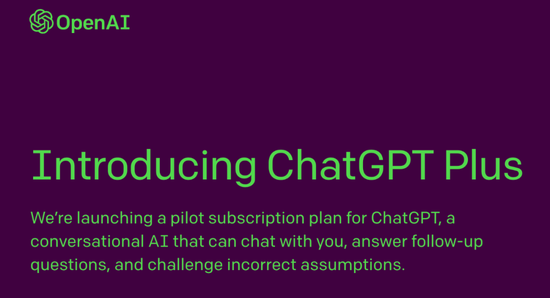
订阅者将获得一些好处:
-
可以普遍使用 ChatGPT,即使在高峰期也是如此;
-
更快的响应时间;
-
优先获得新功能和改进。
OpenAI 表示,它将在‘未来几周内’向在美国和在其候补名单上的人发出该服务的邀请,并表示会将该服务推广到其他国家和地区。
一个多星期前,有消息称 OpenAI 要以每月 42 美元的价格推出 ChatGPT 服务的 plus 版或 pro 版,但最终定下的每月 20 美元,显然让更广泛的人群有能力使用该服务,包括学生和企业。
某种程度上,这将为市场上任何想要推出的 AI 聊天机器人设定付费标准。鉴于 OpenAI 是该领域的先行者,如果其他公司试图发布每月付费超过 20 美元的机器人,都必须先解释明白一件事 —— 自己的聊天机器人凭什么比 ChatGPT Plus 更值钱?

(声明:本文仅代表作者观点,不代表新浪网立场。)
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK