

The Transparent data encryption in PostgreSQL
source link: https://www.highgo.ca/2019/09/30/the-transparent-data-encryption-in-postgresql/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

The Transparent data encryption in PostgreSQL

I have been working with the PostgreSQL community recently to develop TDE (Transparent Data Encryption). During this time, I studied some cryptography-related knowledge and used it to combine with the database. I will introduce the TDE in PostgreSQL by the following three dimensions.
- The current threat model of the database
- Encryption policy description and current design status of the current PostgreSQL community
- Future data security
What is TDE?
Transparent Data Encryption (often abbreviated to TDE) is a technology employed by Microsoft, IBM and Oracle to encrypt database files. TDE offers encryption at file level. TDE solves the problem of protecting data at rest, encrypting databases both on the hard drive and consequently on backup media.
–Transparent_Data_Encryption
When it comes to cryptography-related topics, we must first understand what security threats are facing.
Security Threat Modes
- Inappropriate permissions
Many applications or software are often used to give unnecessary privileges to users because of the convenience of use. Secondly, if users are not cleaned up in time (for example, resigned employees), information leakage will also occur.
Most applications don’t impose too many restrictions on DBAs and developers, which also carries the risk of data loss.
Authority-giving strategies, separation of powers, or database auditing are all important ways to prevent such threats. - SQL injection attack
SQL injection attacks have always been one of the major risks facing databases. With the development of B/S mode application development, more and more programmers use this mode to write applications. However, due to the level of programmers and experience, a considerable number of programmers do not judge the legitimacy of user input data when writing code, which makes the application security risk. The user can submit a database query code and obtain some data he wants to know based on the results returned by the program.
Reasonable software architecture design and legal SQL auditing are effective ways to prevent such threats. - Attack on purpose
An attacker can affect the database through network eavesdropping, Trojan attack, etc., resulting in data loss risks. Many vendors often fail to enable network transmission encryption due to performance or resources, which causes data eavesdropping risks.
Secondly, a malicious attacker can infect a legitimate user device through measures such as a Trojan virus, thereby stealing data and causing data loss.
Improve security measures, such as turning on the firewall, enabling network transmission encryption, etc. Secondly, strengthening database auditing can be used to combat such threats. - Weak audit trail
Due to resource consumption and performance degradation, many vendors turn off or turn on less-functional audit trails, which can lead to malicious administrators hacking data.
Secondly, because the restricted operation after auditing is more difficult to implement, for example, it is difficult to distinguish between operation of DBAs and trespassing, which makes it difficult to defend against attacks after auditing.
Network equipment auditing is currently the most effective auditing program. - Unsafe storage medium
The storage medium stores the risk of stealing, and secondly, the backup storage security setting is lower, which causes data loss.
Enhance the protection of physical media, encrypt user data, and enforce security settings for all data stores to protect against such threats. - Unsafe third party
With the advent of the cloud era and 5G, more vendors are storing data in the cloud. This actually has third-party trust issues. If a third party has a malicious administrator, illegally stealing or reading sensitive data, or providing a server with a security risk, this will result in data loss.
By selecting a trusted third party and encrypting user data, you can avoid unsafe third-party threats. - Database vulnerability or incorrect configuration
With the increase of the functions of modern database software, complex programs are likely to have security vulnerabilities, and many manufacturers are reluctant to upgrade the version in order to ensure the stability of the system. The same data faces a large risk of leakage.
Second, there are also high risks associated with inadequate security settings. The security configuration here does not only refer to the database level but also needs to strengthen the security configuration at the operating system level.
Regularly fix database vulnerabilities and enhance security configuration. - Limited security expertise and education
According to statistics, about 30% of data breaches are caused by human error, so safety education needs to be strengthened.
Regular safety knowledge lectures to raise awareness of safety precautions.
In summary, the current data encryption can deal with threats with insecure storage media, insecure third parties.
And we know that the database not only needs security considerations, but also needs to balance performance, stability, and ease of use.
So how do you design data encryption?
Encryption Level
First, let’s review the overall architecture of PostgreSQL:

Through the overall architecture, we can divide the encryption into 6 levels.
As can be seen from the above figure, the client and the server interact, and the user data is received by the server from the client, written to the server cache, and then flushed into the disk.
The physical structure of PostgreSQL storage is: cluster –> table space –> database –> relationship object.
From this we can divide the database into six levels for encryption, client-side encryption, server-side encryption, cluster-level encryption, table-space-level encryption, database-level encryption, and table-level or object-level encryption.
The following six levels are explained separately:
- Client -level encryption, which generates a key by the user and encrypts the segment;
- Advantages: It can defend DBA and developers to a certain extent; the encryption granularity is small, and the amount of encrypted data is controllable. The existing encryption plug-in pgcrypto can be used for client data encryption.
- Disadvantages: The use cost is high, the existing application system needs to be adjusted, and the data insertion statement is modified; secondly, since the encryption is started from the data generation, it is equal to the cache level encryption, the performance is poor, and the index cannot be used.
- The server encrypts, establishes an encryption type, and encrypts the segment;
- Advantages: The use cost is relative to the encrypted copy of the client, only need to adjust the database, no need to modify the application, the encryption granularity is small, and the amount of encrypted data is controllable.
- Disadvantages, the same is cache-level encryption, poor performance, the index can not be used.
- Cluster-level encryption, encrypting the entire cluster, and determining whether the cluster is encrypted during initialization;
- Advantages: simple architecture, low cost of use, operating system cache level encryption (data cache brushing, encryption, and decryption when reading disk), performance is relatively better;
- Disadvantages, the encryption is fine-grained, and all cluster internal objects are encrypted, which will cause performance degradation.
- Tablespace-level encryption, setting encryption attributes for a certain table space, all encrypted inside the encrypted tablespace;
- Advantages: simple architecture, low cost of use, operating system cache level encryption, relatively better performance, reduced fine-grained encryption, better control of the amount of encrypted data, and favorable data encryption efficiency;
- Disadvantages: The concept of the tablespace in PostgreSQL is not clear enough, users are easily misunderstood, and secondly, the cost of use in backup management is higher.
- Database-level encryption, specifying a library as an encryption library, and all objects in the encryption library are replaced with encryption;
- Advantages: simple architecture, low cost of use, operating system cache level encryption, reduced fine-grained encryption, high data encryption efficiency;
- Disadvantages: The encryption fine-grained is relatively broken.
- Table-level encryption or file-level encryption, specifying an object to be encrypted;
- Advantages: simple architecture, low cost of use, operating system cache level encryption, lower and lower encryption granularity, and high data encryption efficiency;
- Disadvantages: The key management cost is reduced and the development complexity is higher. Secondly, when the object to be encrypted is vertical, the use cost is high.
The following explains why the cache level encryption cannot be indexed:
The purpose of indexing is to improve the efficiency of data construction, and the reason for encryption is to protect sensitive data.
- Then if we encrypt at the cache level, if we build an index, we need to divide it into two cases, based on plain text indexing or indexing based on the ciphertext.
- Based on the plaintext index, the plaintext needs to be decrypted, the index is built, and the index is encrypted. However, if the number of encryption and decryption is too high, the performance will be degraded, and the order of the index itself will cause certain information leakage.
- Based on the ciphertext document index, the index cannot effectively sort the data, and it is difficult to continuously decelerate continuously.
- If you do not encrypt the index, it will gradually affect the data security.
- Of course, if you do not use the index after encryption, it will have no effect.
The above-mentioned cache level and file system level encryption are next seen from the storage architecture:

As can be seen from the above figure, we can be divided into three levels, database cache level, operating system cache level, and file system level:
Database cache level encryption: Levels 1 and 2 above are encrypted when data is written to the cache, cache level encryption, and decryption during data retrieval, with the worst performance;
Operating system cache level: Levels 3, 4, 5, and 6 are all encrypted in PostgreSQL data flashing, decrypted when data is loaded, and performance is relatively good; File system level: The database itself cannot be implemented, and file system encryption is required.
File system level: The database itself cannot be implemented, and file system encryption is required.
So how to choose for the database?
Although encryption is a good means of data security protection, how to join the database requires a holistic consideration.
When we strengthen the database, we need to consider
- Development costs;
- safety;
- performance;
- Ease of use.
After many discussions in the community, cluster-level encryption has been chosen as the first solution for TDE.
We all know that commonly used encryption currently has three types: streaming encryption, packet encryption, and public-key encryption.
When using encryption algorithms, you should pay attention to:
- The encryption method consists of two parts, a key, and an encryption algorithm. Usually, we recommend the use of internationally public, certified encryption algorithms.
- The protection of the key is equivalent to the protection of the plaintext.
So how to encrypt it will be divided into two parts: the choice of an encryption algorithm and the management of the key.
Encryption algorithm selection
First, analyze the three encryption methods:
- The feature of streaming-encryption is that the key length is consistent with the length of the plaintext data, which is difficult to implement in the database, so it is not considered here.
- The biggest advantage of public-key encryption is that it is divided into public and private keys. The public key can be publicized, which reduces the problem of key management, but its encryption performance is too poor. The packet encryption algorithm is hundreds of public-key encryption. Double, so I don’t think about it here.
- Block cipher is the current mainstream encryption algorithm with the best performance and the widest application.
The current internationally recognized block cipher algorithm is AES.
Let’s briefly introduce AES.
The packet encryption algorithm first needs to be grouped. The AES encryption length is 128 bits, which is 16 bytes.
Has 3 key lengths, 128, 192 and 256.
AES has 5 encryption modes:
ECB mode: electronic codebook mode
CBC mode: cipher block link mode
CFB mode: password feedback mode
OFB mode: output feedback mode
CTR mode: counter mode
If you want to get the detail of this five-mode you can see: The difference in five modes in the AES encryption algorithm and The performance test on the AES modes.
After discussion, we chose the CTR mode as the TDE encryption algorithm mode.
Key Management
Key management consists of four parts: key generation, key preservation, key exchange, and key rotation.
If you want to get the detail of Key management you can see: Key Management.
I recommend to the community that password-based key generation, using KEK storage keys, Diffie-Hellman key exchange scheme.
After several rounds of discussions in the current community, there are currently two schemes of Layer 2 key management and Layer 3 key management.
2 tier Key Management
2 tier key management uses a combination of password-based key generation, KEK storage key, and key distribution center. The architecture is as follows:
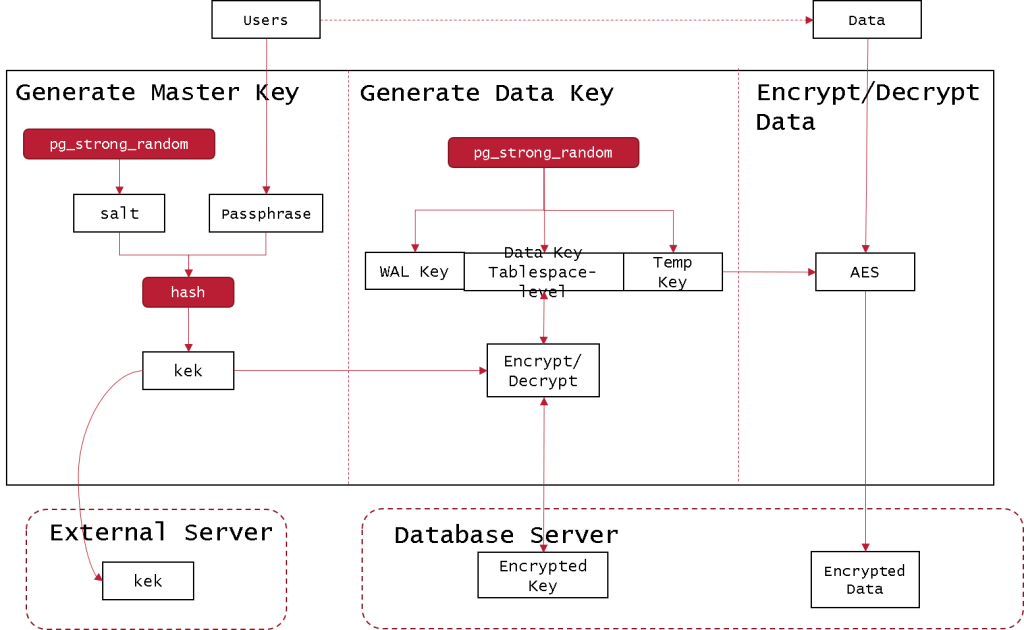
- A user enters a password;
- The system generates a random number, performs a hash calculation with the user password, and obtains a key encryption key;
- Store the key encryption key to a secure location;
- The system generates a random number as a data encryption key;
- The key encryption key encrypts the data key and the encrypted data key is also stored in a database server;
- Use data encryption keys to encrypt and decrypt data.
3 tier key management
3 tier key management uses a combination of the password-based key generation, HKDF, the use of KEK storage key and the use of the key distribution center 4, the architecture is as follows:
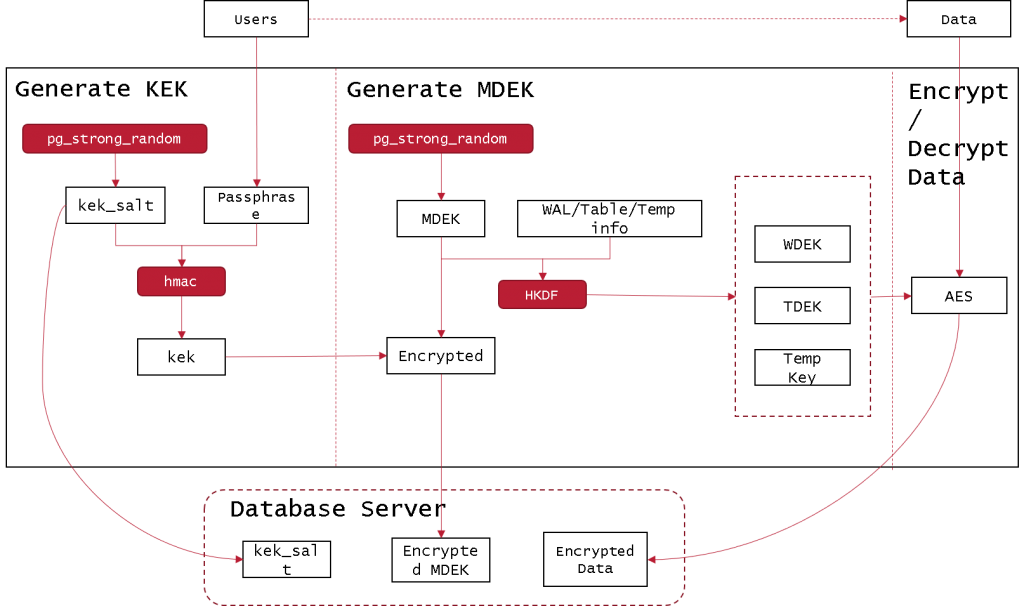
- The user enters a password;
- The system generates a random number, performs a hash calculation with the user password, and obtains a key encryption key;
- Store the random number to a safe place;
- The system generates a random number as MDEK (master data encryption key) and stores it in a secure place;
- Use MDEK and encrypted file information to get the data encryption key;
- Encrypt and decrypt the data using a data encryption key.
At present, there is still some controversy about key management. I personally agree with the second method to prepare for the finer granularity of later encryption.
Future data security
Now with the advent of 5G, the advent of the cloud era, I think the future of IT architecture, more are cloud-based design. More data is stored in the cloud, so if cloud vendors steal and analyze user data, it will seriously violate our privacy.
The malicious DBAs and developers who were also mentioned in the threat model often have higher database permissions. Even if they don’t have permission, if they have the method of reading the cache, the data will also be leaked.
So how do we protect our data?
Homomorphic encryption
Homomorphic encryption is a form of encryption that allows computations to be carried out on ciphertext, thus generating an encrypted result which, when decrypted, matches the result of operations performed on the plaintext.
— Homomorphic_encryption
Homomorphic Encryption is an Open Problem that was proposed by the cryptography community a long time ago. As early as 1978, Ron Rivest, Leonard Adleman, and Michael L. Dertouzos proposed this concept in the context of banking.
The general encryption scheme focuses on data storage security. That is, I have to send someone an encrypted thing, or to save something on a computer or other server, I have to encrypt the data and then send or store it. A user without a key cannot obtain any information about the original data from the encrypted result. Only the user who owns the key can decrypt it correctly and get the original content. We have noticed that in this process, the user cannot perform any operations on the encryption result, and can only store and transmit. Any action on the result of the encryption will result in incorrect decryption and even decryption. The most interesting aspect of the homomorphic encryption scheme is that it focuses on data processing security. Homomorphic encryption provides a means of processing encrypted data. That is, others can process the encrypted data, but the process does not reveal any original content. At the same time, after the user who owns the key decrypts the processed data, it is exactly the result of the processing.
If you don’t understand its concept very well, then we can look at the following picture:

DBAs and developers or malicious cloud administrators are like operators (attackers) who must handle the gold in a locked box (encryption algorithm) with no gloves. They don’t the key(data key) can’t open the box, so they can’t steal gold (data).
How-to-use Homomorphic Encryption?

Alice’s processing data with Homomorphic Encryption (hereafter referred to as HE) using Cloud is roughly like this:
- Alice encrypts the data. And send the encrypted data to the Cloud;
- Alice submits data processing methods to Cloud, which is represented by function f;
- Cloud processes the data under function f and sends the processed result to Alice;
- Alice decrypts the data and gets the result.
So why are there no large-scale applications yet? According to the IBM team’s research, until 2016, the technology still has performance bottlenecks, and the huge performance overhead is extremely helpless.
The inventor of homomorphic encryption, Craig Gentry, led a team of IBM researchers to conduct a series of homomorphic encryption attempts. In the beginning, the data processing speed of plaintext operation was “100 trillion times faster” than the homomorphic encryption. Later, it was executed on a 16-core server, and the speed was increased by 2 million times, but it was still much slower than the plaintext operation. As a result, IBM continues to improve HElib, and its latest release on GitHub re-implements a homomorphic linear transformation with dramatic performance improvements that are 15-75 times faster. In a paper by the International Cryptography Research Association, Shai Halevi of the IBM Cryptographic Research Team and Victor Shoup, a professor at the Coulometric Institute of Mathematics at New York University, also worked on IBM Zurich research experiments. Room describes the method of speed improvement.
Therefore, the performance of current homomorphic encryption cannot meet normal needs. If it is commercialized to the database level, I think it needs further research by cryptographers. Please look forward to it.
In the End
All of the above methods are software-scale operations. Currently, there are many hardware solutions for data encryption, like FPGA card encryption/decryption to improve its performance; and Intel’s Trusted Execution Environment Technology (TEE, Trusted Execution Environment) Trusted computing and so on.
Encryption is only a small part of database security. More content requires everyone’s joint efforts and hopes to see more people in the database security field in the future.
Reference
Shawn Wang is a developer of PostgreSQL Database Core. He has been working in HighGo Software for about eight years.
He did some work for Full Database encryption, Oracle Compatible function, Monitor tool for PostgreSQL, Just in time for PostgreSQL and so on.
Now he has joined the HighGo community team and hopes to make more contributions to the community in the future.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK