

k-means聚类 - 归去_来兮
source link: https://www.cnblogs.com/flyup/p/17076998.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

当前人工智能技术实现的一种主要手段是机器学习,而机器学习能够解决的问题主要有三种:分类、聚类、回归,有监督的是分类,无监督的是聚类。所谓聚类,就是以一定的方法将一堆样本依它们本身的数据特性划分成不同的簇类,以达成不同的技术目的,k-means就是这样一种基础聚类算法。
二、算法原理
对给定的样本集,k-means基于迭代的思想,由聚集中心点划定簇集,簇集反过来确定新的聚集中心点,周而复始,最终获得最佳划分的簇集。k-means中的k即想要划定的簇数,它是一个超参数,需由人工事先指定。样本的簇集划归由它与各个聚集中心点的距离来确定,划归到距离最近的那一个,其中距离的计算一般采用欧氏距离;新划定的簇集则进一步计算质心作为新的聚集中心,质心即样本向量的均值 c=(x(1)¯,x(2)¯,...,x(n)¯)c=(x(1)¯,x(2)¯,...,x(n)¯)
算法描述
输入:样本集 T={x1,x2,...,xN}T={x1,x2,...,xN},簇数k.
输出:质心集合 C={c1,c2,...,ck}C={c1,c2,...,ck},划分样本集D={D1,D2,...,Dk}D={D1,D2,...,Dk}.
(1) 任意选定k个样本作为初始聚集中心.
(2) 划分簇类
1)对T中数据,计算与各个聚集中心的距离.样本x与聚集中心c的距离为
2)将样本划归到离得最近的聚集中心,形成簇类。
(3)计算质心作为聚集中心
对簇S,质心
c(i)=1M∑Ms=1x(i)sc(i)=1M∑s=1Mxs(i),M=|S|M=|S|.
(4)重复(2)-(3)步,直至质心不发生偏移或达到指定的迭代次数.
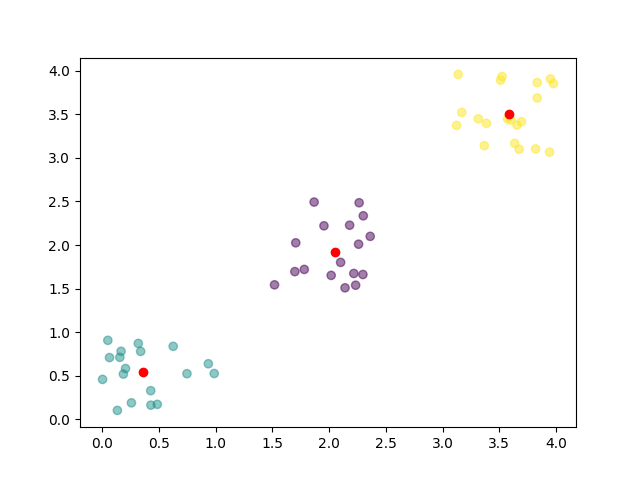
三、python实现
'''
由sklearn实现kmeans聚类。
'''
import numpy as np
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
#初始化数据集
d1 = np.random.rand(18,2)
d2 = 1.5 + np.random.rand(17,2)
d3 = 3 + np.random.rand(20,2)
data = np.concatenate((d1,d2,d3),axis=0)
#定义kmeans模型,n_clusters为指定的簇数k
kmr = KMeans(n_clusters=3)
#数据计算
fit_kmr = kmr.fit(data)
#获取标签结果
rs_labels = fit_kmr.labels_
#获取每个簇类的中心点
rs_center_ids = fit_kmr.cluster_centers_
#绘图
#绘制数据点
plt.scatter(data[:,0],data[:,1],c=rs_labels,alpha=0.5)
#绘制质心
plt.scatter(rs_center_ids[:,0],rs_center_ids[:,1],c='red')
plt.show()
运行结果:
End.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK