

[聊聊算法]拓扑排序原理及实战
source link: https://www.luozhiyun.com/archives/748
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

[聊聊算法]拓扑排序原理及实战
这档专栏打算整理一些比较容易归纳总结的模板题,让这些知识点不仅仅是我的笔记,希望也能帮助到大家
拓扑排序(topological sorting)并不是一个纯粹的排序算法,它只是针对有向无环图,找到一个可以执行的线性顺序。这类型的题有了一定的方法,其实很容易写出来。
Directed acyclic graph (DAG),有向无环图是指:
- 这个图是有方向的;
- 这个图内没有环;
DAG 既然是有向,并且是没有环的,那就可以用它来表示一种依赖关系,就像洗衣机洗衣服一样,先倒洗衣液,再加水洗衣服。在软件领域,我们也会不知不觉地碰到DAG,例如程序模块之间的依赖关系、makefile脚本、区块链、git分支等。
那么这一组先后的依赖的关系可以用数组来表示,比如 n=6 表示有6个节点,一个依赖关系可以用一个数组表示,例如:[2, 1]表示做2之前先要完成1;那么一组依赖关系就可以用一个二维数组表示:[[2,1],[4,1],[4,2],[3,2],[5,4],[5,3]],通过对数组的表述可以构成一张图:
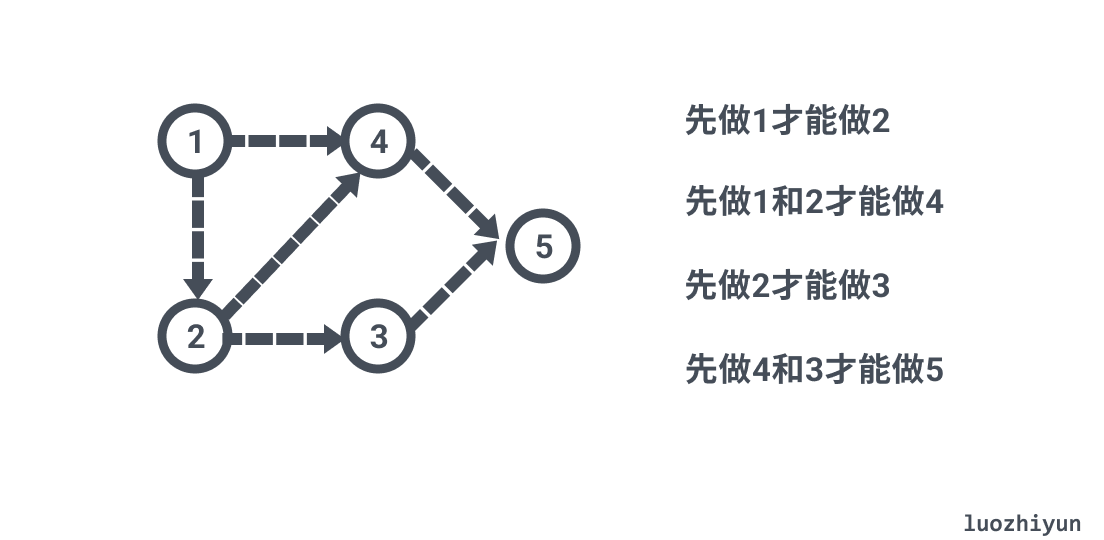
由这种有向无环图转成线性的排序就叫拓扑排序,在上图中 1->2->4->3->5就是一个正确的序列,而1->4->2->3->5就不是,因为做4之前要先做1和2。
拓扑排序的实现算法有两种:入度表(广度优先遍历)、DFS(深度优先遍历),其时间复杂度均为O(N+M),N 和 M 分别为节点数量和边数量。
入度表(广度优先遍历)
先来看看入度表(广度优先遍历),对于有向图来说有 入度 和 出度 的概念:
- 入度:有多少条边直接指向该节点;
- 出度:由该节点指出边的有多少条。
因此,对于有向图的拓扑排序可以先建图,生成 入度表 indegrees;然后借助一个队列 queue,将所有入度为 0 的节点入队;当 queue 非空时,依次将队首节点出队,并减少相关元素入度;如果入度表中有新的元素入度变成 0 了,那么再入队,依次循环直到没有入度为 0 的元素为止。
其中还需要一个 邻接表 来辅助我们遍历出最终结果,这张表是一个 map 存放的与该节点的依赖关系。
这么说有点抽象,我们可以看一道题 《207. 课程表 https://leetcode.cn/problems/course-schedule/ 》,这道题主要就是说一共有 n 门课要上,编号为 0~ n-1;给一个条件 [1, 0],表示必须先上课 0,才能上课 1,然后让你判断是否能完成所有课程。
那么对于这道题,我们需要:
- 创建一个数组 indegrees ,用来记录每个课程的入度;
- 用一个 map 记录每个课程的依赖关系,这个 map 就是邻接表,key 是课号,value 是依赖这门课的后续课,value可能存在多个,所以是个数组;
- 队列 queue 用来记录所有入度为 0 的元素;
- 当 queue 非空时,依次将队首节点出队,用一个 count 变量记录入度为 0 的课程个数;
- 然后从 map 里面将依赖这门课的后续课找出来,然后将这些课程的入度减一;
- 如果有课程的入度为 0 那么再加入队列 queue 中;
比如上面这个例子:[[2,1],[4,1],[4,2],[3,2],[5,4],[5,3]]

// 没有课程0所以入度为0;1课程入度为0;先做2之前要先做1,所以2课程入度为1;依次往下
indegrees = {0,0,1,1,2,2}
//第一轮
queue = {1}
count = 0
//第二轮
queue = {2}
count = 1
//第三轮
queue = {3,4}
count = 2
//第三轮
queue = {4}
count = 3
//第四轮
queue = {5}
count = 4
//第五轮
queue = {}
count = 5那代码其实就是:
func canFinish(numCourses int, prerequisites [][]int) bool {
ingress := make([]int,numCourses) //入度表
graph := make(map[int][]int,numCourses) //邻接表
for _,v:=range prerequisites {
ingress[v[0]]++ //入度加1
if _,ok := graph[v[1]];!ok{
graph[v[1]] = []int{}
}
// 建立关联关系,存储和v[1]课关联课程集
graph[v[1]] = append(graph[v[1]], v[0])
}
qu := []int{}
for i,v:=range ingress{
if v == 0 {//找出所有入度为0的课程
qu = append(qu,i)
}
}
count := 0
for len(qu)>0 {
//依次将队首节点出队
first := qu[0]
qu = qu[1:]
count++ // 记录入度为 0 的课程个数,表示这个课程已经可以修炼了
for _, v:=range graph[first] { //找出与这个课程关联的所有课程
ingress[v]-- //因为它的前提课程可以修炼了,所以这个课程的入度减一
if ingress[v] == 0 { //如果入度都为0了,那么代表这个课程可以修炼了,入队
qu = append(qu, v)
}
}
}
return count == numCourses //如果可以修炼的课程和课程总数相等,那么表示可以完成所有课程的修炼
}DFS(深度优先遍历)
DFS 实际上就是判断图中有没有环。
我们用一个 flags 用于判断每个元素的状态:
- 未被访问的为 0;
- 已被本轮搜索访问的为 1;
- 已被不是本轮搜索访问的为 -1;
然后和上面一样建立一个图,用一个 map 记录每个课程的依赖关系,key 是课号,value 是依赖这门课的后续课,value可能存在多个,所以是个数组;
终止条件就是:
- 当判断
flags[i] == 1,说明已被本轮搜索访问过,那么表示有环,直接返回 false; - 当判断
flags[i] == -1,说明已被其他轮搜索访问过,无需重复搜索,这是个优化项;
func canFinish(numCourses int, prerequisites [][]int) bool {
graph := make(map[int][]int,numCourses)
for _,v:=range prerequisites { // 建图
if _,ok := graph[v[1]];!ok{
graph[v[1]] = []int{}
}
// 建立关联关系,存储和v[1]课关联课程集
graph[v[1]] = append(graph[v[1]], v[0])
}
flags := make([]int, numCourses) //用来做标记用
for i:=0;i<numCourses;i++{
ret := dfs(graph, flags, i)
if !ret {
return false
}
}
return true
}
func dfs(graph map[int][]int, flags []int, index int) bool {
if flags[index] == -1 { //已被其他轮搜索过,停止搜索
return true
}
if flags[index] == 1 { // 已被本轮搜索过,表明有环
return false
}
flags[index] = 1 //标记本轮搜索过
for _, v := range graph[index] { // 遍历所有与该节点关联的节点
ret := dfs(graph,flags , v)
if !ret {
return false
}
}
flags[index] = -1 //本轮搜索完之后,设置为-1,因为要开启下一轮搜索了
return true
}外星文字典
这虽然是一道 hard 难度的题目,但是还是那个套路,这道题主要是难在如何将这个字母关系转换成为使用拓扑排序解决。
这题实际上就是对字符串 s1 和字符串 s2 进行排序时,从两者的首字母开始逐位对比,先出现较小的字母的单词排序在前。假设有这样数组 words = ["ac","ab","bc","zc","zb"] 为例,由于 "ac" < "ab" 所以 'c' < 'b',由于 "ab" < "bc" 所以 'a' < 'b',依次可得 'b' < 'z' 、'c' < 'b'。
首先我们可以把每个字母看作图的节点,若已知两个字母之间的大小关系,那么图中就存在一条从较小的字母指向较大字母的边。
那么对于这道题,我们需要:
- 和其他拓扑排序一样,创建一个 inGress 入度表;
- 创建一个 map 作为邻接表,记录各个字母的依赖关系,key 是字母 byte,value 是与 key 相邻的字母;
- 我们这里还多了一步建图,因为需要将所有的字母添加到入度表中;
下面是代码实现:
func alienOrder(words []string) string {
inGress := make(map[byte]int)
graph := make(map[byte][]byte)
// 建图
for _, v := range words {
for k := range v {
c := v[k]
inGress[c] = 0
if _, ok := graph[c]; !ok {
graph[c] = []byte{}
}
}
}
// 计算邻接表和入度
for i:=1;i<len(words);i++{
w1 := words[i-1]
w2 := words[i]
minLen := min(len(w1),len(w2))
j:=0
for ;j<minLen;j++{
c1 := w1[j]
c2 := w2[j]
if c1 != c2 {
graph[c1] = append(graph[c1], c2)
inGress[c2]++
// 这里要终止掉,因为只会第一个不同的字母
// 比如 abc 和 acd, 第二字母不同可以建立顺序关系,但是第三不同就不行了
break;
}
}
// 若两者的前缀相同,但前者的单词长度长于后者,如 "abc" 和 "ab"。这是不符合排序规则的
if j == minLen && len(w1) > minLen {
return ""
}
}
res := []byte{}
qu := []byte{}
// 入度为 0 的点
for k,v := range inGress{
if v == 0 {
qu = append(qu, k)
}
}
for len(qu) > 0 {
cu := qu[0]
qu = qu[1:]
res = append(res, cu)
for _, v := range graph[cu] {
inGress[v]--
if inGress[v] == 0 {
qu = append(qu, v)
}
}
}
if len(res) != len(inGress) {
return ""
}
return string(res)
}
func min ( a,b int) int {
if a< b{
return a
}
return b
}其实这题也是套路化的,需要注意的一点是由于题目中已经说明了seq[i]是 nums 的子序列,所以我们只需要判断该拓扑排序是否有唯一解就行了。
那么对于这道题,我们需要:
- 首先用 seq 建图,但是
seq[i]里面可能存在多个元素,这一点和以往的建图方式不太一样,需要用循环遍历; - 队列 queue 用来记录所有入度为 0 的元素,在遍历队列出队的时候需要判断一下队列里面的元素是不是大于1,大于1说明同时有两个元素的入度是0,表示可以有多种解法;
func sequenceReconstruction(nums []int, sequences [][]int) bool {
graph := make(map[int][]int)
inGress := make([]int,len(nums)+1)
for i:=0;i<len(sequences);i++{
cur := sequences[i]
//注意这里是一个子序列,有多个元素,不是两个
for j:=1;j<len(cur);j++ {
s1 := cur[j-1]
s2 := cur[j]
graph[s1] = append(graph[s1],s2)
inGress[s2]++
}
}
qu := []int{}
for i:=1;i<= len(nums);i++{
//入度为0的点入队
if inGress[i] == 0 {
qu = append(qu,i)
}
}
for len(qu)>0{
//存在多个入度为0的点 会有多个超序列 直接返回false
if len(qu)>1 {
return false
}
cur := qu[0]
qu = qu[1:]
for _, v := range graph[cur] {
//和此点连通的点入度减一
inGress[v]--
if inGress[v] == 0 {
qu = append(qu, v)
}
}
}
return true
} 要解决拓扑排序问题,通过上面的讲解我们可以知道主要分为这么几步:首先建图和建立入度表;然后找出所有入度为0的元素加入队列中;将队列中的元素循环出队,遍历与之关联的节点,并将入度减1。很多题目主要难在建图和入度表,这需要观察题目中给出的元素之间的依赖关系。
Reference
https://en.wikipedia.org/wiki/Topological_sorting
https://zhuanlan.zhihu.com/p/135094687
https://zhuanlan.zhihu.com/p/93647900

Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK