

图解eBPF Socket level 重定向的内核实现细节
source link: https://www.51cto.com/article/745149.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.


上一篇《利用eBPF实现socket level重定向》,二哥从整体上介绍了 eBPF 的一个应用场景 socket level redirect:如果一台机器上有两个进程需要通过 loopback 设备相互收发数据,我们可以利用 ebpf 在发送进程端将需要发送的数据跳过本机的底层 TCP/IP 协议栈,直接交给目的进程的 socket,从而缩短数据在内核的处理路径和时间。
这个流程如图 1 所示。本篇我们来详细看下图 1 右侧在内核里的实现细节。
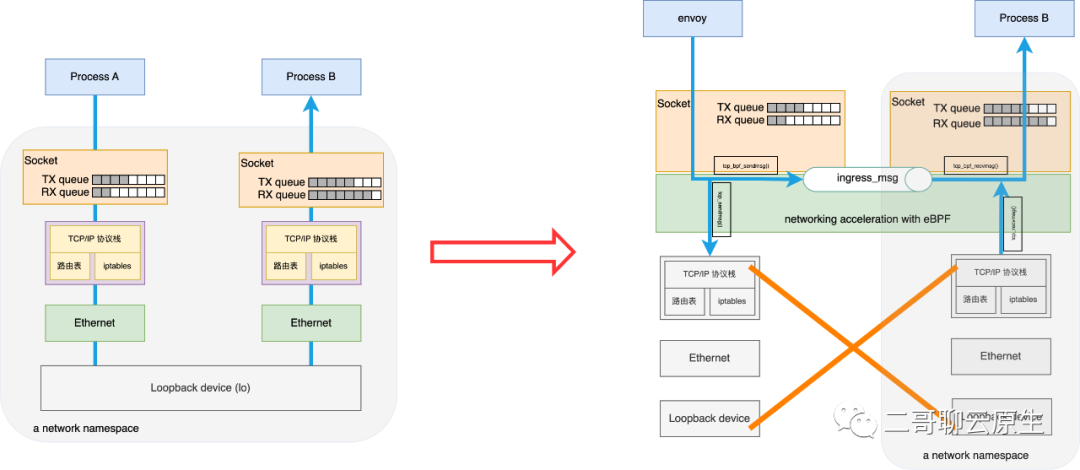
图 1:利用 ebpf 进行 socket level redirect,从而跳过 TCP/IP 协议栈和 lo 设备
先来一张全局图,我们再依次剖析这张图上面的关键知识点。
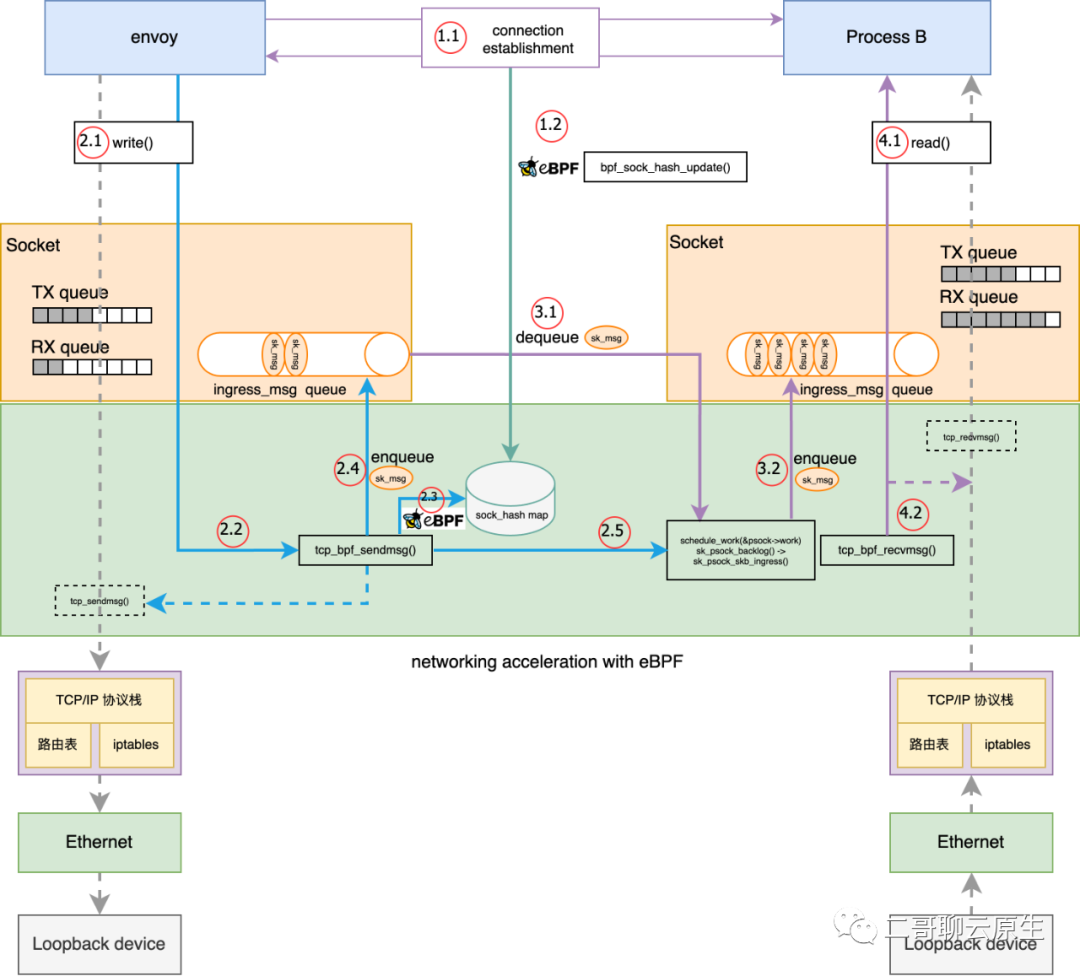
图 2:利用 ebpf 进行 socket level redirect 全局细节图
一、准备阶段
1、插入 bpf_sock_ops 到 sock_hash map
我们的故事从图 3 所示的插入 bpf_sock_ops 到 sock hash map 开始。这里给出一些代码片段,完整可编译、可执行的代码位于 https://github.com/LanceHBZhang/socket-acceleration-with-ebpf 。另外,完整的 ebpf 程序的安装过程还涉及到 cgroup,我就不展开来讲这个话题了。
下面代码中用到一种特殊的 map 类型:BPF_MAP_TYPE_HASH,也即本文提及的 sock_hash。在它里面存储的是 KV 类型数据,而 value 实际对应的是数据结构 struct bpf_sock_ops。除了存储 bpf_sock_ops,在这类 map 上还可以 attach 一个用户编写的 sk_msg 类型的 bpf 程序,以便来查找接收数据的 socket,attach 语句请参考 github 代码。
static inline
void bpf_sock_ops_ipv4(struct bpf_sock_ops *skops)
{
struct sock_key key = {};
int ret;
extract_key4_from_ops(skops, &key);
ret = sock_hash_update(skops, &sock_ops_map, &key, BPF_NOEXIST);
if (ret != 0) {
printk("sock_hash_update() failed, ret: %d\n", ret);
}
printk("sockmap: op %d, port %d --> %d\n",
skops->op, skops->local_port, bpf_ntohl(skops->remote_port));
}
__section("sockops")
int bpf_sockmap(struct bpf_sock_ops *skops)
{
switch (skops->op) {
case BPF_SOCK_OPS_PASSIVE_ESTABLISHED_CB:
case BPF_SOCK_OPS_ACTIVE_ESTABLISHED_CB:
if (skops->family == 2) { //AF_INET
bpf_sock_ops_ipv4(skops);
}
break;
default:
break;
}
return 0;
}当我们通过 attach 一种 sock_ops 类型的 bpf 函数,即下面代码中的 bpf_sockmap(),到 cgroupv2 的根路径后,当发生一些 socket 事件,如主动建立连接或者被动建立连接等,这个时候 bpf 函数 bpf_sockmap() 将会被调用。这个过程如图 3 执行点 1 所示,更具体地说 1发生的事情就是三次握手(SYN / SYNC-ACK / ACK),既然是三次握手,当然是与通信双方都有关系,所以 bpf_sockmap() 函数里 bpf_sock_ops_ipv4(skops) 会被调用两次 。
bpf_sockmap() 所做的事情非常简单:以 source ip / source port / dest ip / dest port / family 为 key ,将 struct bpf_sock_ops 对象放入到 sock_hash 中。这个过程如图 3 执行点 1.2 所示。为了表示 bpf_sockmap() 与 ebpf 有关,我特意在2 处画出了 ebpf 的 logo。
上述代码中 sock_hash_update() 函数调用看起来是在更新 sock_has map,其实它在内核中所做的事情更重要:精准动态替换 TCP 协议相关函数。
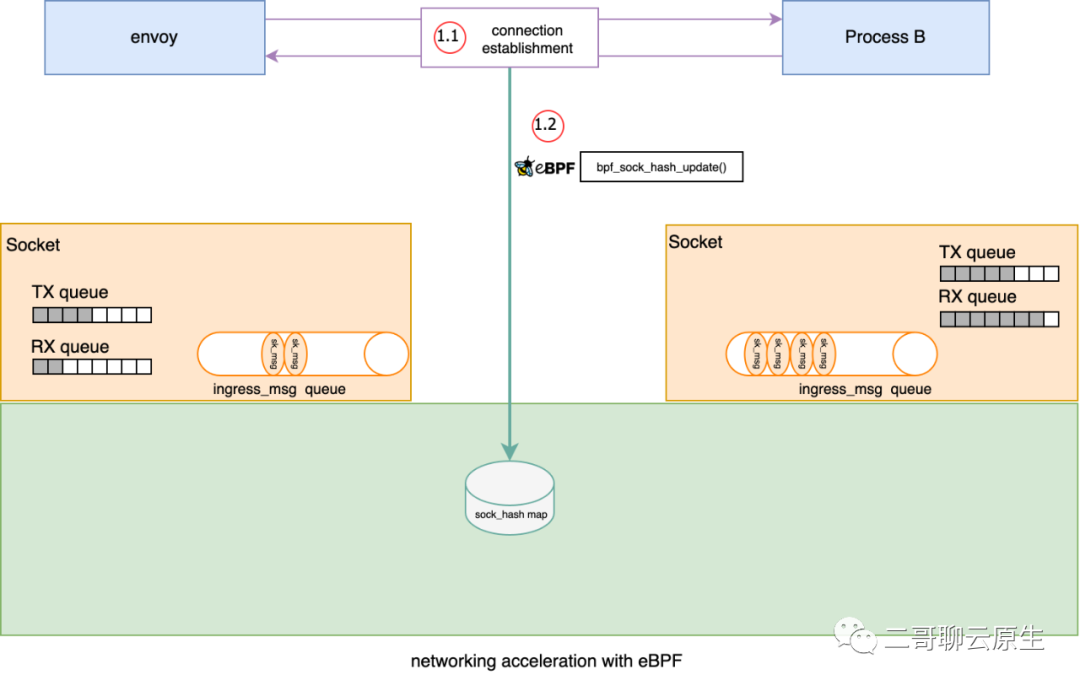
图 3:插入 sock 到 sock_hash map
2、精准动态替换 prot
如果大家关注过内核协议栈相关数据结构的话,一定会碰到如下图所示的几个关键角色:struct file / struct socket / struct sock / struct proto 。
其中 socket 如同设计模式里常用的转接器(adaptor),一方面它适配了面向应用层的 struct file ,另一方面又通过引用 struct sock 的方式串联起网络协议栈。
仔细看这张图,我们会发现 struct sock 才是灵魂,你从它所包含的内容就能窥得一二了。struct sock 里有一个非常关键地方:对 Networking protocol 的引用,也即你看到的 sk_prot 。为什么说它关键呢?因为 sk_prot 作为一个指针所指向的结构体 tcp_prot 包含了一系列对 TCP 协议至关重要的函数,包括本文需要重点关注的 recvmsg 和 sendmsg 。从它们的名字你也能看出来它们的使用场景:用于 TCP 层接收和发送数据。
当然除了 struct tcp_prot ,sk_prot 还可能指向 struct udp_prot / ping_prot / raw_prot 。
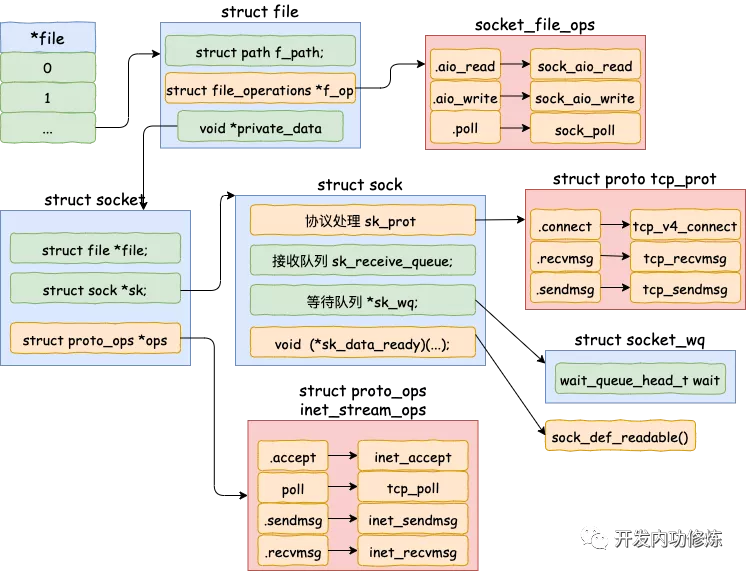
图 4:file / socket / sock / operations(图片来源:开发内功修炼公众号)
那 ebpf 在这里面干了啥事呢?非常的巧妙,它把 struct proto 里面的 recvmsg / sendmsg 等函数动态替换掉了。比如把 recvmsg 由原来的 tcp_recvmsg 替换成了 tcp_bpf_recvmsg ,而把 tcp_sendmsg 替换为 tcp_bpf_sendmsg 。
static void tcp_bpf_rebuild_protos(struct proto prot[TCP_BPF_NUM_CFGS], struct proto *base)
{
prot[TCP_BPF_BASE] = *base;
prot[TCP_BPF_BASE].close = sock_map_close;
prot[TCP_BPF_BASE].recvmsg = tcp_bpf_recvmsg;
prot[TCP_BPF_BASE].sock_is_readable = sk_msg_is_readable;
prot[TCP_BPF_TX] = prot[TCP_BPF_BASE];
prot[TCP_BPF_TX].sendmsg = tcp_bpf_sendmsg;
prot[TCP_BPF_TX].sendpage = tcp_bpf_sendpage;
prot[TCP_BPF_RX] = prot[TCP_BPF_BASE];
prot[TCP_BPF_RX].recvmsg = tcp_bpf_recvmsg_parser;
prot[TCP_BPF_TXRX] = prot[TCP_BPF_TX];
prot[TCP_BPF_TXRX].recvmsg = tcp_bpf_recvmsg_parser;
}
static int __init tcp_bpf_v4_build_proto(void)
{
tcp_bpf_rebuild_protos(tcp_bpf_prots[TCP_BPF_IPV4], &tcp_prot);
return 0;
}
late_initcall(tcp_bpf_v4_build_proto);
int tcp_bpf_update_proto(struct sock *sk, struct sk_psock *psock, bool restore)
{
// ...
/* Pairs with lockless read in sk_clone_lock() */
WRITE_ONCE(sk->sk_prot, &tcp_bpf_prots[family][config]);
return 0;
}单纯的替换其实谈不上巧妙,二哥说巧妙是因为这里的替换是“精准动态替换”。首先为啥叫精准替换呢?你想啊,不是每个服务都需要通过 loopback 来进行本机进程间通信的,另外即使进程间通信是通过这种方式,也不是每一种场景都需要使用到我们这里说的 socket level redirect ,所以替换操作不能广撒网,只能在需要的时候替换。所谓“动态替换”也即不是在编译内核的时候就直接替换掉了,而是在有需要的时候。
那这个“需要的时候”到底是什么时候呢?
答案是将 bpf_sock_ops 存储到 sock_hash 的时候,也即图 3 所涉及到过程。当系统函数 bpf_sock_hash_update 被调用时,内核会调用位于 net/core/sock_map.c 中的 sock_hash_update_common 函数,在它的调用链中完成了替换函数 tcp_bpf_update_proto() 的调用。实际的替换结果是 sk->sk_prot 保存了替换后的版本,也即 tcp_bpf_prots[family][config],而 tcp_bpf_prots 则在很早的时候就已经初始化好了。
强调一遍,这里的替换操作仅仅与确实需要用到 socket level redirect 的 sock 有关,不会影响到其它 sock,当然被替换的 sock 其实是一对,你一定猜到了,图 3 中 envoy 进程和 Process B 各有一个自己的 sock 参与了这次通信过程,故而它们自己的 recvmsg / sendmsg 都需要被替换掉。
二、sk_psock
在图 3 中,我们还能看到独立于 TX queue 和 RX queue 的新 queue:ingress_msg。通信双方的 socket 层都各有一个这样的 queue 。queue 里面暂存的数据用结构体 struct sk_msg 表示,sk_msg 包含了我们之前非常熟悉的 skb ,我们略过它的具体定义。在下文讲述数据发送和接收流程中我们会看到 ingress_msg queue 是如何发挥作用的。
这个 queue 位于结构体 struct sk_psock {} 里面。同样被包含在 sk_psock 里面的,还有它的小伙伴 sock / eval / cork 等。
内核代码里面我们会看到大量的 psock->eval 这样的语句,即为对 sk_psock 的读写。另外你看这个结构体里面还有函数指针 psock_update_sk_prot ,它所指向的即为上一节所说的函数 tcp_bpf_update_proto() 。
struct sk_psock {
struct sock *sk;
struct sock *sk_redir;
u32 apply_bytes;
u32 cork_bytes;
u32 eval;
struct sk_msg *cork;
struct sk_psock_progs progs;
#if IS_ENABLED(CONFIG_BPF_STREAM_PARSER)
struct strparser strp;
#endif
struct sk_buff_head ingress_skb;
struct list_head ingress_msg;
spinlock_t ingress_lock;
unsigned long state;
struct list_head link;
spinlock_t link_lock;
refcount_t refcnt;
void (*saved_unhash)(struct sock *sk);
void (*saved_close)(struct sock *sk, long timeout);
void (*saved_write_space)(struct sock *sk);
void (*saved_data_ready)(struct sock *sk);
int (*psock_update_sk_prot)(struct sock *sk, struct sk_psock *psock, bool restore);
struct proto *sk_proto;
struct mutex work_mutex;
struct sk_psock_work_state work_state;
struct work_struct work;
struct rcu_work rwork;
}三、发送数据
在和 Process B 成功建立起 TCP 连接后,进程 envoy 开始写数据了,如图 5 中 2.1 所示。
正常情况下, write() 系统调用所传递的数据最终会由 tcp_sendmsg() 来进行 TCP 层的处理。不过还记得在“精准动态替换 prot” 一节我们提到 tcp_sendmsg() 已经被替换成 tcp_bpf_sendmsg() 了吗?所以这里的主角其实是 tcp_bpf_sendmsg() 。
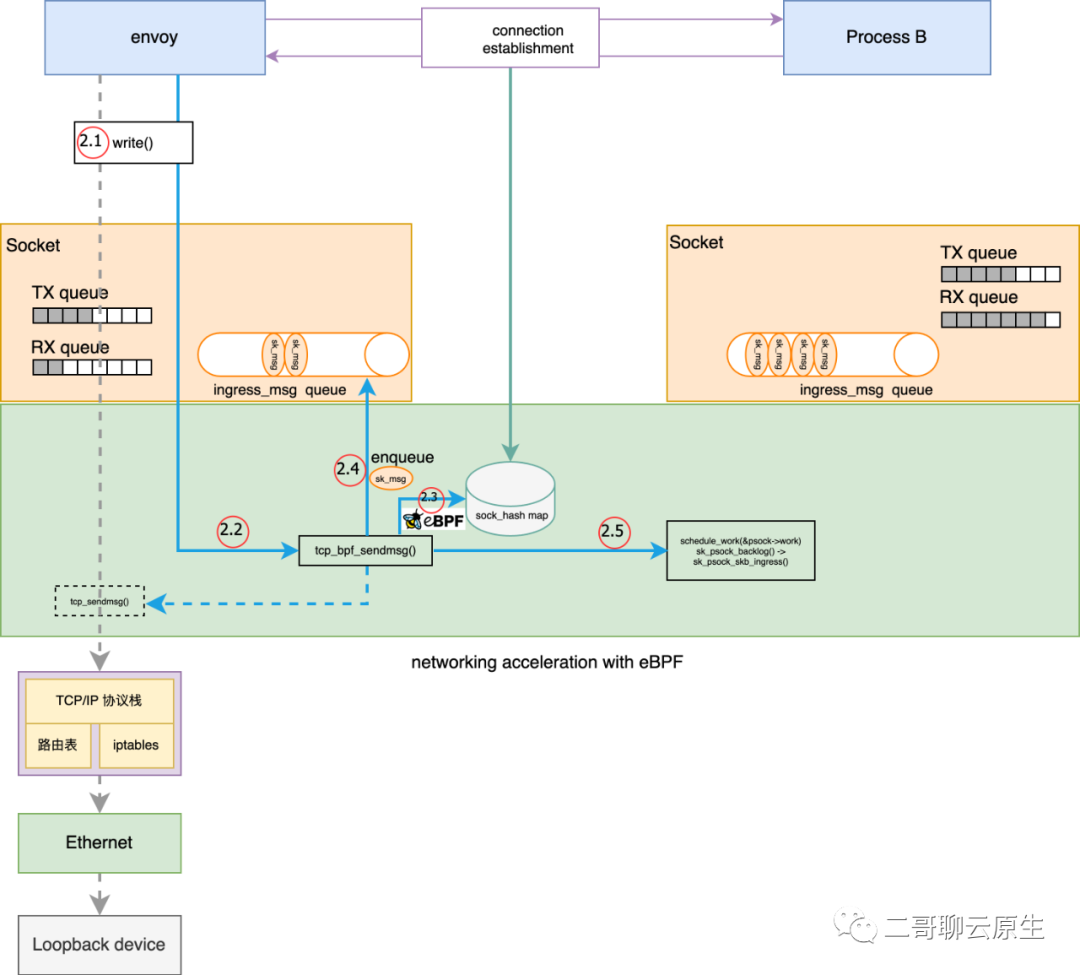
图 5:发送数据流程
我在图 5 中画出了 tcp_bpf_sendmsg() 所干的几件重要的事情:
1、执行点2.3:执行 ebp 程序
ebpf 程序其实需要老早就需要准备好,并 attach 到 sock_hash 上(再一次,这个过程请参考前文所附 github 代码)。程序的入口非常简单:bpf_redir()。它同样从 struct sk_msg_md 里面提取出 source ip / source port / dest ip / dest port / family ,并以其为 key 到 sock_hash 里面找到需要重定向的目标,也即通信对端的 struct sock,并将其存放于 psock->sk_redir 处。
static inline
void extract_key4_from_msg(struct sk_msg_md *msg, struct sock_key *key)
{
key->sip4 = msg->remote_ip4;
key->dip4 = msg->local_ip4;
key->family = 1;
key->dport = (bpf_htonl(msg->local_port) >> 16);
key->sport = FORCE_READ(msg->remote_port) >> 16;
}
__section("sk_msg")
int bpf_redir(struct sk_msg_md *msg)
{
struct sock_key key = {};
extract_key4_from_msg(msg, &key);
msg_redirect_hash(msg, &sock_ops_map, &key, BPF_F_INGRESS);
return SK_PASS;
}代码中 msg_redirect_hash() 这个名字有点误导人。乍一看还以为是在这里就完成了重定向过程。其实它只干了 map 查找和确认是否允许重定向这两个操作,真正的好戏还在后头。它的代码不长,我直接全部贴在这里了。
BPF_CALL_4(bpf_msg_redirect_hash, struct sk_msg *, msg, struct bpf_map *, map, void *, key, u64, flags)
{
struct sock *sk;
if (unlikely(flags & ~(BPF_F_INGRESS)))
return SK_DROP;
sk = __sock_hash_lookup_elem(map, key);
if (unlikely(!sk || !sock_map_redirect_allowed(sk)))
return SK_DROP;
msg->flags = flags;
msg->sk_redir = sk;
return SK_PASS;
}2、 执行点2.4:enqueue sk_msg
在这里,我们第一次看到 ingress_msg queue 的使用场景。
struct sk_psock {} 里面有一个成员叫 eval ,从这个关键词大概就能猜到它与评估结果有关,那评估的对象是谁呢?就是 2.3 处所需要执行的 ebpf 程序。2.3 处的执行结果会放到 psock->eval 里面供后面使用。
执行结果有三种:__SK_PASS / __SK_REDIRECT / __SK_DROP 。当 psock->eval 等于我们重点关注的 __SK_REDIRECT 时,就开始了执行点 2.4 的过程:将 sk_msg 放到 psock->ingress_msg 这个 queue 里面。
需要注意的是,这个地方的 psock 还是位于发送端,也即它是属于 envoy 进程的,那自然这个 ingress_msg queue 也是属于 envoy 进程的。
3、执行点2.5:拉起新的 task
在执行点 2.4 把 sk_msg 放到 psock->ingress_msg 之后,内核没有继续往下调用其它函数,而是选择通过 schedule_work(&psock->work) 拉起了一个异步 task,并结束了发送数据的流程。
这样的选择搭配 queue 非常的合理:一是为了效率,不能让发送端(envoy)一直等待;二是为了解耦,通过 queue 来解开发送端和接收端的耦合;三是为了匹配接收端(Process B)的处理速度,进程 B 可能这个时候正好在处理其它事项来不及消费 skb。
四、接收数据
上一节执行点 2.5 我们说到,发送数据流程最终启动了一个异步 task 。到这里为止结束了发送数据流程,而从这里也开始了接收数据的流程。整个流程涉及到的关键步骤我画在图 6 里面了:执行点 3.1 / 3.2 / 4.1 / 4.2 。
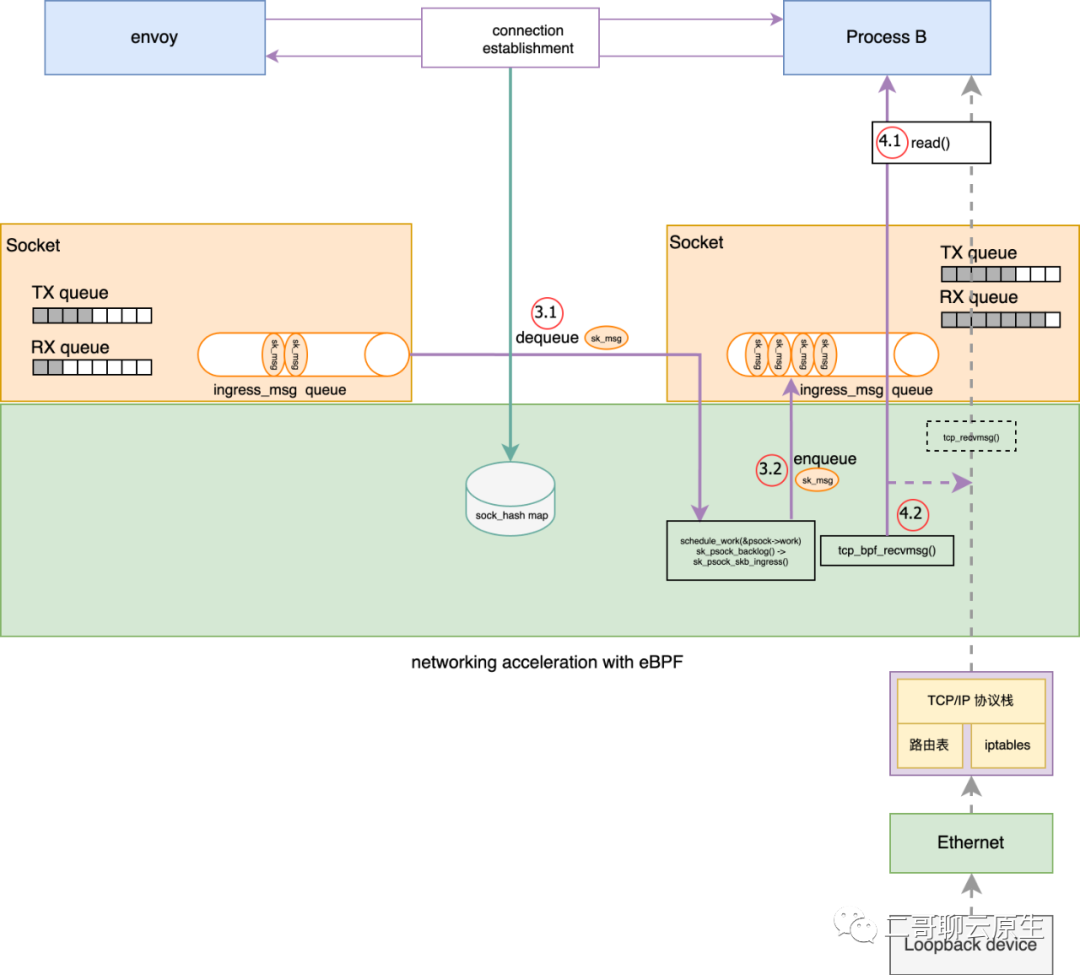
图 6:接收数据流程
1、 执行点3.1: dequeue sk_mskg
异步 task 的切入口是函数 sk_psock_backlog() ,而它首先做的事情是拿到 envoy 所使用的 psock 指针,进而不断地从 psock->ingress_skb 里面取出 sk_msg 进行消费。
下面代码中 struct sk_psock *psock = container_of(work, struct sk_psock, work) 即为通过 work 拿到 psock 的逻辑,一个简单又不失优雅的过程。
static void sk_psock_backlog(struct work_struct *work)
{
struct sk_psock *psock = container_of(work, struct sk_psock, work);
struct sk_psock_work_state *state = &psock->work_state;
struct sk_buff *skb = NULL;
//...
//...
while ((skb = skb_dequeue(&psock->ingress_skb))) {
//...
start:
ingress = skb_bpf_ingress(skb);
skb_bpf_redirect_clear(skb);
do {
ret = -EIO;
if (!sock_flag(psock->sk, SOCK_DEAD))
ret = sk_psock_handle_skb(psock, skb, off,
len, ingress);
//...
} while (len);
if (!ingress)
kfree_skb(skb);
}
end:
mutex_unlock(&psock->work_mutex);
}2、 执行点3.2: 再次enqueue sk_msg
我们看上面代码里面 skb_dequeue(&psock->ingress_skb) 这一行。它其实消费的是发送端 psock 里面的数据,也即 sk_msg,那消费的结果是什么呢?其实非常简单,在执行点 3.2 把 sk_msg 塞到了接收端的 psock->ingress_msg queue 里面了。
其实你也看出来了,这一步结束后,这个新拉起的 task 也就完成了它的使命。
3、执行点4.1和4.2: 处理 skb
好了,如果你耐心地看到这个地方,大概也能猜到接下来发生什么了。执行点 4.1 处所调用的 read() 操作其实对应到 TCP 协议里面的 recvmsg 函数。recvmsg 只是一个指向函数的指针,真正的函数实现是 tcp_bpf_recvmsg() 。在文首“精准动态替换”那节,二哥已经铺垫过啦。
你再回头看下图 2 ,会发现二哥在图中从 tcp_bpf_sendmsg() 以及 tcp_bpf_recvmsg() 分别拉了一条虚线到 tcp_sendmsg() 和 tcp_recvmsg()。我管 tcp_sendmsg() 和 tcp_recvmsg() 叫备胎。因为 tcp_bpf_sendmsg() 以及 tcp_bpf_recvmsg() 在处理一些异常情况时就直接走老路了。
static int tcp_bpf_recvmsg(struct sock *sk, struct msghdr *msg, size_t len,
int nonblock, int flags, int *addr_len)
{
// ...
psock = sk_psock_get(sk);
if (unlikely(!psock))
return tcp_recvmsg(sk, msg, len, nonblock, flags, addr_len);
}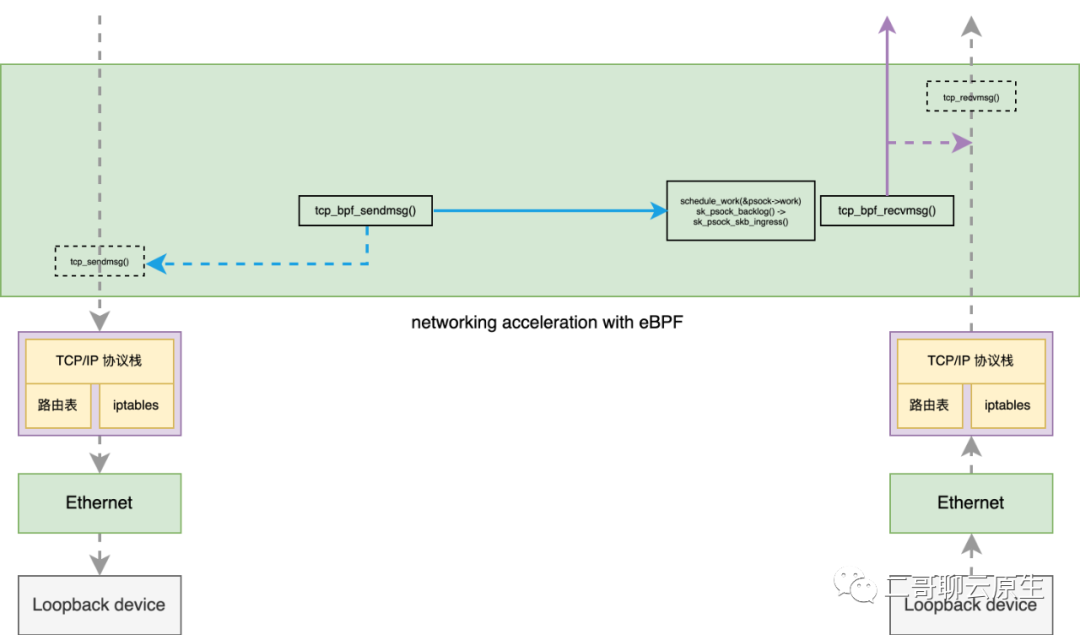
图 7:备胎 tcp_sendmsg() 和 tcp_recvmsg()
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK