

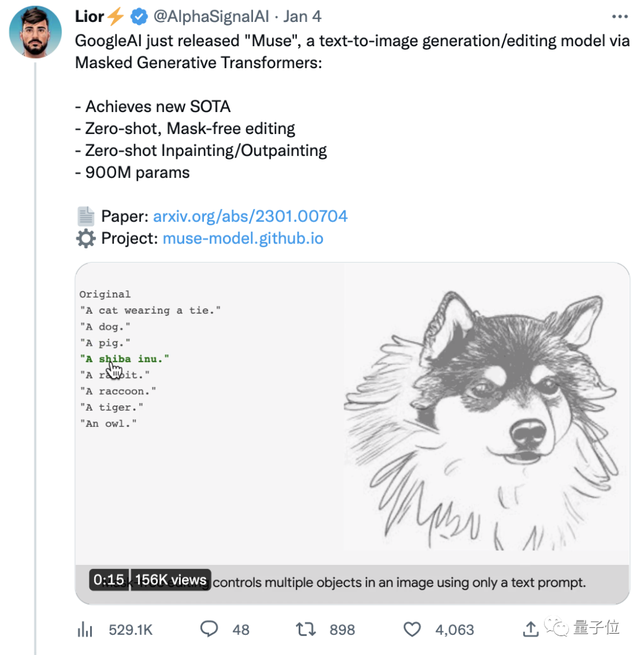
效率碾压DALL·E 2和Imagen,谷歌新模型达成新SOTA,还能一句话搞定PS
source link: https://www.qbitai.com/2023/01/41073.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

效率碾压DALL·E 2和Imagen,谷歌新模型达成新SOTA,还能一句话搞定PS

P图技术还挺溜
Alex 羿阁 发自 凹非寺
量子位 | 公众号 QbitAI
新年伊始,谷歌AI又开始发力文字-图像生成模型了。
这次,他们的新模型Muse(缪斯)在CC3M数据集上达成了新SOTA(目前最佳水平)。
而且其效率远超火爆全球的DALL·E 2和Imagen (这俩都属于扩散模型),以及Parti (属于自回归模型)。
——单张512×512分辨率图像的生成时间被压缩到仅1.3秒。

在图像编辑方面,只需一句文字指令,就可以对原始图像进行编辑。
(貌似不用再为学ps头秃了~)

如果想要效果更精准,还能选定遮罩位置,编辑特定区域。比如,把背景的建筑换成热气球。

Muse一经官宣,很快吸引了大波关注,目前原贴已收获4000+点赞。
看到谷歌的又一力作,有人甚至已经开始预言:
现在AI开发者的竞争非常激烈,看来2023将是非常精彩的一年。
比DALL·E 2和Imagen更高效
说回谷歌刚刚公开的Muse。
首先,就生成图片的质量来说,Muse的作品大都画质清晰、效果自然。
来看看更多例子感受一下~
比如戴着毛线帽的树懒宝宝正在操作电脑;再比如酒杯中的一只羊:

平时八竿子打不着的各种主体,在一张图里和谐共存,没啥违和感。
要是你觉得这些还只能算AIGC的基操,那不妨再看看Muse的编辑功能。
比如一键换装(还能换性别):

这既不需要加什么遮罩,还能一句话搞定。
而如果用上遮罩的话,就能实现更6的操作,包括一键切换背景,从原地切换到纽约、巴黎、再到旧金山。

还能从海边到伦敦、到花海,甚至飞到太空中的土星环上,玩一把刺激的滑板海豚跳。

(好家伙,不仅能轻松云旅游,还能一键上天……)
效果着实挺出色。那Muse背后都有哪些技术支持?为什么效率比DALL·E 2和Imagen更高?
一个重要的原因是,DALL·E 2和Imagen在训练过程中,需要将所有学到的知识都存储在模型参数中。
于是,它们不得不需要越来越大的模型、越来越多的训练数据来获取更多知识——将Better和Bigger绑在了一起。
代价就是参数量巨大,效率也受到了影响。
而据谷歌AI团队介绍,他们采用的主要方法名曰:掩码图像建模 (Masked image modeling)。
这是一种新兴的自监督预训练方法,其基本思想简单来说就是:
输入图像的一部分被随机屏蔽掉,然后通过预训练文本任务进行重建。
Muse模型在离散标记的空间掩码上训练,并结合从预训练语言大模型中提取的文本,预测随机遮蔽的图像标记。
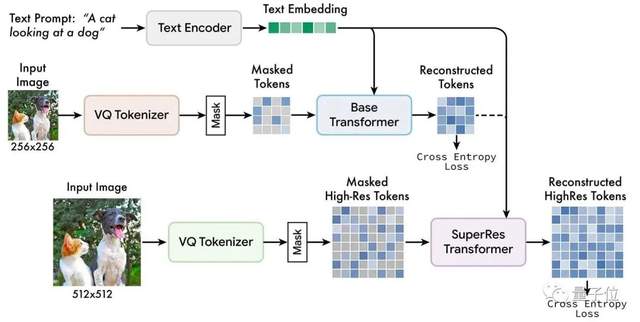
从上到下依次为:预训练的文本编码器、基础模型、超分辨率模型
谷歌团队发现,使用预先训练好的大语言模型,可以让AI对语言的理解更加细致透彻。
就输出而言,由于AI对物体的空间关系、姿态等要素把握得很不错,所以生成的图像可以做到高保真。
与DALL·E 2、Imagen等像素空间的扩散模型相比,Muse用的是离散的token,并且采样迭代较少。
另外,和Parti等自回归模型相比,Muse使用了并行解码,效率也更高。
FID上获SOTA得分
前文提到,Muse不仅在效率上取得了提升,在生成图像质量上也非常优秀。
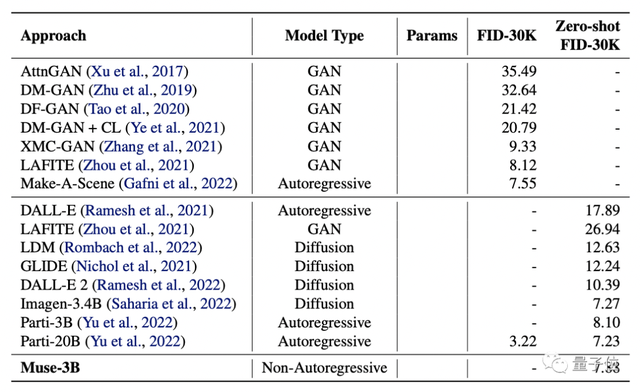
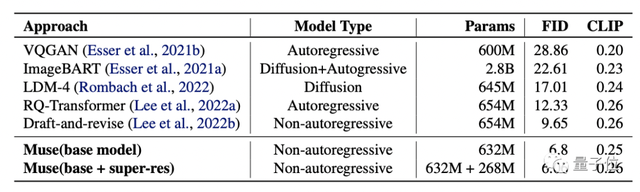
研究者把它与DALL·E、LAFITE、LDM、GLIDE、DALL·E 2,以及谷歌自家的Imagen和Parti进行PK,测试了它们的FID和CLIP分数。
(FID分数用于评估生成图像的质量,分数越低质量越高;CLIP分数则代表文本与图像的契合程度,分数越高越好。)
结果显示,Muse-3B模型在COCO验证集中的zero-shot FID-30K得分为7.88,仅次于参数更大的Imagen-3.4B和Parti-20B模型。
更优秀的是,Muse-900M模型在CC3M数据集上实现了新的SOTA,FID得分为6.06,这也意味着它与文字的匹配度是最高的。
同时,该模型的CLIP分数为0.26,也达到了同期最高水平。
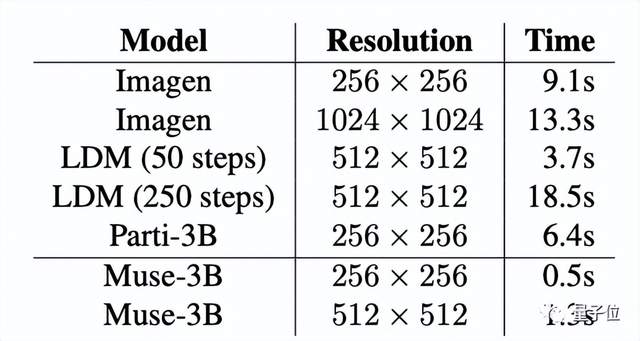
除此之外,为了进一步证实Muse的出图效率,研究者还对比了Muse与其他模型的单张图像生成时间:
在256×256、512×512的分辨率上Muse均达到了最快速度:0.5s和1.3s。
Muse的研究团队来自谷歌,两位共同一作分别是Huiwen Chang和Han Zhang。

Huiwen Chang,现为谷歌高级研究员。
她本科就读于清华大学,博士毕业于普林斯顿大学,有过在Adobe、Facebook等的实习经历。

Han Zhang,本科毕业于中国农业大学,硕士就读于北京邮电大学,后在罗格斯大学取得了计算机科学博士学位。
其研究方向是计算机视觉,深度学习和医学图像分析等。

不过值得一提的是,目前Muse还没有正式发布。

有网友调侃,虽然它应该很香,但以谷歌的“尿性”,Muse离正式发布可能还有很长时间——毕竟他们还有18年的AI都没发呢。
话说回来,你觉得Muse的效果怎么样?
对于其正式发布之事,有木有一点期待?
传送门:https://muse-model.github.io/
参考链接:https://twitter.com/AlphaSignalAI/status/161040458996618036012
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK