

Extracting, converting, and querying data in local files using clickhouse-local
source link: https://clickhouse.com/blog/extracting-converting-querying-local-files-with-sql-clickhouse-local
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Extracting, converting, and querying data in local files using clickhouse-local
What is clickhouse-local?
Sometimes we have to work with files, like CSV or Parquet, resident locally on our computers, readily accessible in S3, or easily exportable from MySQL or Postgres databases. Wouldn’t it be nice to have a tool to analyze and transform the data in those files using the power of SQL, and all of the ClickHouse functions, but without having to deploy a whole database server or write custom Python code?
Fortunately, this is precisely why clickhouse-local was created! The name “local” indicates that it is designed and optimized for data analysis using the local compute resources on your laptop or workstation. In this blog post, we’ll give you an overview of the capabilities of clickhouse-local and how it can increase the productivity of data scientists and engineers working with data in these scenarios.
Installation
Now we can use the tool:
Quick example
Suppose we have a simple CSV file we want to query:
This will print the first two rows from the given sample.csv file:
The file() function, which is used to load data, takes a file path as the first argument and file format as an optional second argument.
Working with CSV files
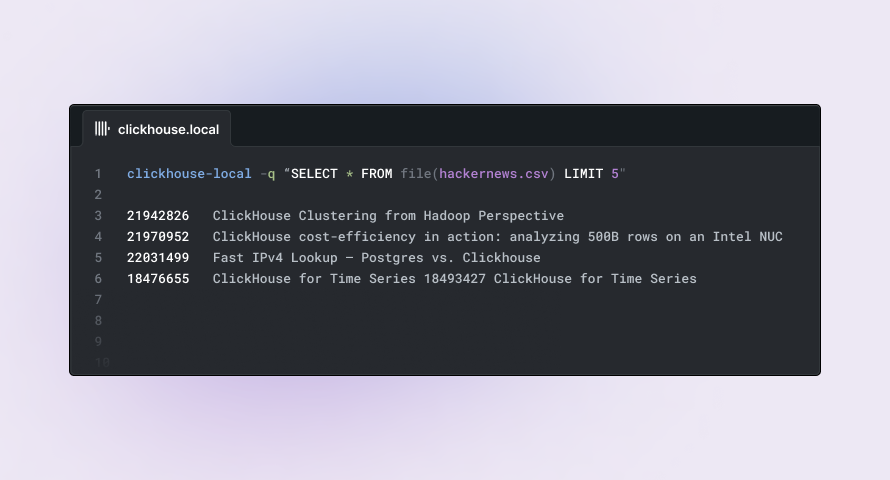
Lets now introduce a more realistic dataset. A sample of the Hackernews dataset containing only posts concerning ClickHouse is available here for download. This CSV has a header row. In such cases, we can additionally pass the CSVWithNames format as a second argument to the file function:
Note how we can now refer to columns by their names in this case:
In cases where we are dealing with CSVs without a header row, we can simply use CSV format (or even omit, since Clickhouse can automatically detect formats):
In these cases, we can refer to specific columns using c and a column index (c1 for the first column, c2 for the second one, and so on). The column types are still automatically inferred from the data. To select the first and third columns:
Using SQL to query data from files
We can use any SQL query to fetch and transform data from files. Let’s query for the most popular linked domain in Hacker News posts:
Note how we can now refer to columns by their names in this case:
Or we can build the hourly distribution of posts to understand the most and least popular hours for posting:
4pm seems to be the least popular hour to post:
In order to understand file structure, we can use the DESCRIBE query:
Which will print the columns with their types:
Output formatting
By default, clickhouse-client will output everything in TSV format, but we can use any of many available output formats for this:
This will output results in a standard SQL format, which can then be used to feed data to SQL databases, like MySQL or Postgres:
Saving output to file
We can save the output to file by using the ‘INTO OUTFILE’ clause:
This will create a hn.tsvfile (TSV format):
clickhouse@clickhouse-mac ~% head urls.tsv
18346787 2018-10-31 15:56:39.000000000 18355652 2018-11-01 16:29:16.000000000 18362819 2018-11-02 13:26:59.000000000 21938521 2020-01-02 19:01:23.000000000 21942826 http://blog.madhukaraphatak.com/clickouse-clustering-spark-developer/ 2020-01-03 03:25:46.000000000 21953967 2020-01-04 09:56:48.000000000 21966741 2020-01-06 05:31:48.000000000 18404015 2018-11-08 02:44:50.000000000 18404089 2018-11-08 03:05:27.000000000 18404090 2018-11-08 03:06:14.000000000
Deleting data from CSV and other files
We can delete data from local files by combining query filtering and saving results to files. Let’s delete rows from the file hackernews.csv that have an empty url. To do this, we just need to filter the rows we want to keep and save the result to a new file:
The new clean.csv file will not have empty url rows, and we can delete the original file once it’s not needed.
Converting between formats
As ClickHouse supports several dozen input and output formats (including CSV, TSV, Parquet, JSON, BSON, Mysql dump files, and many others), we can easily convert between formats. Let’s convert our hackernews.csv to Parquet format:
And we can see this creates a new hackernews.parquet file:
Note how Parquet format takes much less space than CSV. We can omit the FORMAT clause during conversions and Clickhouse will autodetect the format based on the file extensions. Let’s convert Parquet back to CSV:
Which will automatically generate a hn.csv CSV file:
Working with multiple files
We often have to work with multiple files, potentially with the same or different structures.
Merging files of the same structure
Suppose we have several files of the same structure, and we want to load data from all of them to operate as a single table:
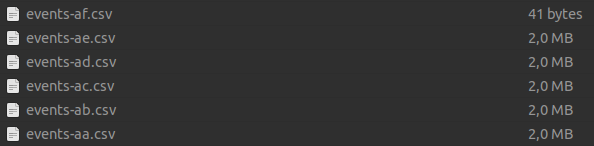
We can use a * to refer to all of the required files by a glob pattern:
This query will quickly count the number of rows across all matching CSV files. We can also specify multiple file names to load data:
This will count all rows from the first.csv and other.csv files.
Merging files of a different structure and format
We can also load data from files of different formats and structures, using a UNION clause:
This query will quickly count the number of rows across all matching CSV files. We can also specify multiple file names to load data:
We use c6 and c3 to reference the required columns in a first.csv file without headers. We then union this result with the data loaded from third.parquet.
Virtual _file and _path columns
When working with multiple files, we can access virtual _file and _path columns representing the relevant file name and full path, respectively. This can be useful, e.g., to calculate the number of rows in all referenced CSV files. This will print out the number of rows for each file:
Joining data from multiple files
Sometimes, we have to join columns from one file on columns from another file, exactly like joining tables. We can easily do this with clickhouse-local.
Suppose we have a users.tsv (TSV format) file with full names in it:
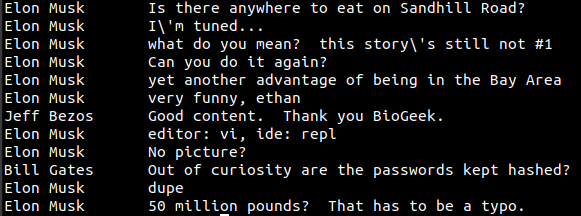
We have a username column in users.tsv which we want to join on with an by column in hackernews.csv:
This will print short messages with their authors' full names (data isn’t real):
Piping data into clickhouse-local
We can pipe data to clickhouse-local as well. In this case, we refer to the virtual table table that will have piped data stored in it:
In case we want to specify the data structure explicitly, so we use the --structure and --format arguments to select the columns and format to use respectively. In this case, Clickhouse will use the CSVWithNames input format and the provided structure:
./clickhouse local -q "SELECT * FROM table LIMIT 3" --input-format CSVWithNames --structure "id UInt32, type String" < unknown.file
"id", "type" 1, "story" 2, "story" 3, "story"
We can also pipe any stream to clickhouse-local, e.g. directly from curl:
This will filter the piped stream on the fly and output results:
Working with files over HTTP and S3
clickhouse-local can work over HTTP using the url() function:
We can also easily read files from S3 and pass credentials:
The s3() function also allows writing data, so we can transform local file data and put results right into an S3 bucket:
This will create a hackernews.parquet file in our S3 bucket:

Working with MySQL and Postgres tables
clickhouse-local inherits ClickHouse's ability to easily communicate with MySQL, Postgres, MongoDB, and many other external data sources via functions or table engines. While these databases have their own tools for exporting data, they cannot transform and convert to the same formats. For example, exporting data from MySQL directly to Parquet format using clickhouse-local is as simple as
Working with large files
One common routine is to take a source file and prepare it for later steps in the data flow. This usually involves cleansing procedures which can be challenging when dealing with large files. clickhouse-local benefits from all of the same performance optimizations as ClickHouse, and our obsession with making things as fast as possible, so it is a perfect fit when working with large files.
In many cases, large text files come in a compressed form. clickhouse-local is capable of working with a number of compression formats. In most cases, clickhouse-local will detect compression automatically based on a given file extension:
You can download the file used in the examples below from here. This represents a larger subset of HackerNews post of around 4.6GB.
We can also specify compression type explicitly in cases file extension is unclear:
With this support, we can easily extract and transform data from large compressed files and save the output into a required format. We can also generate compressed files based on an extension e.g. below we use gz:
./clickhouse local -q "SELECT * FROM file(hackernews.csv.gz, CSVWithNames) WHERE by = 'pg' INTO OUTFILE 'filtered.csv.gz'"
ls -lh filtered.csv.gz -rw-r--r-- 1 clickhouse clickhouse 1.3M 4 Jan 17:32 filtered.csv.gz
This will generate a compressed filtered.csv.gz file with the filtered data from hackernews.csv.gz.
Performance on large files
Let’s take our [hackernews.csv.gz](https://datasets-documentation.s3.eu-west-3.amazonaws.com/hackernews/hacknernews.csv.gz) file from the previous section. Let’s execute some tests (done on a modest laptop with 8G RAM, SSD, and 4 cores):
| Query | Time |
|
./clickhouse local -q "SELECT count(*) FROM file(hn.csv.gz, CSVWithNames) WHERE by = 'pg'" |
37 seconds |
|
./clickhouse local -q "SELECT * FROM file(hn.csv.gz, CSVWithNames) WHERE by = 'pg' AND text LIKE '%elon%' AND text NOT LIKE '%tesla%' ORDER BY time DESC LIMIT 10" |
33 seconds |
|
./clickhouse local -q "SELECT by, AVG(score) s FROM file(hn.csv.gz, CSVWithNames) WHERE text LIKE '%clickhouse%' GROUP BY by ORDER BY s DESC LIMIT 10"
|
34 seconds |
As we can see, results do not vary beyond 10%, and all queries take ~ 35 seconds to run. This is because most of the time is spent loading the data from the file, not executing the query. To understand the performance of each query, we should first load our large file into a temporary table and then query it. This can be done by using the interactive mode of clickhouse-local:
clickhouse@clickhouse-mac ~ % ./clickhouse local ClickHouse local version 22.13.1.160 (official build).
clickhouse-mac :)
This will open a console in which we can execute SQL queries. First, let’s load our file into MergeTree table:
CREATE TABLE tmp ENGINE = MergeTree ORDER BY tuple() AS SELECT * FROM file('hackernews.csv.gz', CSVWithNames)
0 rows in set. Elapsed: 68.233 sec. Processed 20.30 million rows, 12.05 GB (297.50 thousand rows/s., 176.66 MB/s.)
We’ve used the CREATE…SELECT feature to create a table with structure and data based on a given SELECT query. Once the data is loaded, we can execute the same queries to check performance:
| Query | Time |
|
SELECT count(*) FROM tmp WHERE by = 'pg'
|
0.184 seconds |
|
SELECT * FROM tmp WHERE by = 'pg' AND text LIKE '%elon%' AND text NOT LIKE '%tesla%' ORDER BY time DESC LIMIT 10
|
2.625 seconds |
|
SELECT by, AVG(score) s FROM tmp WHERE text LIKE '%clickhouse%' GROUP BY by ORDER BY s DESC LIMIT 10
|
5.844 seconds |
We could further improve the performance of queries by leveraging a relevant primary key. When we exit the clickhouse-local console (with exit; command) all created tables are automatically deleted:
Generating files with random data for tests
Another benefit of using clickhouse-local, is that it has support for the same powerful random functions as ClickHouse. These can be used to generate close-to-real-world data for tests. Let’s generate CSV with 1 million records and multiple columns of different types:
And in less than a second, we have a test.csv file that can be used for testing:
We can also use any available output formats to generate alternative file formats.
Loading data to a ClickHouse server
Using clickhouse-local we can prepare local files before ingesting them into production Clickhouse nodes. We can pipe the stream directly from clickhouse-local to clickhouse-client to ingest data into the table:
In this example, we first filter the local hn.csv.gz file and then pipe the resulting output directly to the hackernews table on ClickHouse Cloud node.
Summary
When dealing with data in local or remote files, clickhouse-local is the perfect tool to get the full power of SQL without the need to deploy a database server on your local computer. It supports a wide variety of input and output formats, including CSV, Parquet, SQL, JSON, and BSON. It also supports the ability to run federated queries on various systems, including Postgres, MySQL, and MongoDB, and export data to local files for analysis. Finally, complex SQL queries can be easily executed on local files with the best-in-class performance of ClickHouse.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK