

SICP:符号求导、集合表示和Huffman树(Python实现) - orion-orion
source link: https://www.cnblogs.com/orion-orion/p/17026000.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

到目前为止,我们已经使用过的所有复合数据,最终都是从数值出发构造起来的(比如我们在上一篇博客《SICP 2.2: 层次性数据和闭包性质(Python实现)》所介绍的链表和树就基于数来进行层次化构造)。在这一节里,我们要扩充所用语言的表达能力,引进将任意符号作为数据的功能。
2.3.1 Scheme语言中的引号
在《SICP》原书采用的Scheme语言(Lisp的一种方言)中,要想表示诸如(a b c d)这种包含着符号的表非常简单,可以直接对数据对象加引号。例如在Scheme语言中,若我们定义变量
(define a 1)
(define b 2)
则我们对(list a b)、(list 'a 'b)、(list 'a b)分别进行求值的结果如下
(list a b)
(1 2)
(list 'a 'b)
(a b)
(list 'a b)
(a 2)
可见直接采用(list a b)构造出的是a和b的值的表,而不是这两个符号本身的表。若想要将符号作为数据对象看待,而不是作为应该求值的表达式,可以在被引对象的前面放一个引号,如'a和'b。
这里的引号非常有趣,因为在自然语言环境中这种情况也很常见,在那里的单词和句子可能看作语义实体,也可以看作是字符的序列(语法实体)。在自然语言中,我们常常用引号表明一个词或者句子作为文字看待,将它们直接作为字符的序列。例如我们对某人说“大声说你的名字”,此时希望听到的是那个人的名字。如果说“大声说‘你的名字’”,此时希望听到的就是词组“你的名字”。请注意,我们在这里不得不用嵌套的引号去描述别人应该说的东西。
然而,在Python语言中,却不能如此优雅地像数据一样操作符号/代码本身了,这也是Scheme/Lisp本身的魅力之所在,即所谓万物皆数据(参看知乎回答《Lisp 值得去学习吗?》)。
由于我们采用Python语言进行实现,故接下我们统一采用字符串的形式来表示符号。
2.3.2 实例:符号求导
为了阐释符号操作的情况,并进一步阐释数据抽象的思想,现在考虑设计一个执行代数表达式的符号求导的过程。我们希望该过程以一个代数表达式和一个变量作为参数,返回这个表达式相对于该变量的导数。例如,如果送给这个过程的参数是ax2+bx+cax2+bx+c和xx,它应该返回2ax+b2ax+b。符号求导对于Lisp有着特殊的历史意义,它正是推动人们去为符号操作开发计算机语言的重要实例之一。进一步说,它是人们为符号数学开发强有力系统的开端,今天已经有越来越多的应用数学家和物理学家们正在使用这类系统。
为了开发出一个符号计算程序,我们将按照2.1.1节开发有理数系统那样,采用同样的数据抽象策略。也就是说,首先定义一个求导算法,令它在一些抽象对象上操作,例如“和”、“乘积”和“变量”,并不考虑这些对象实际上如何表示,以后才去关心具体表示的问题。
对抽象数据的求导程序
为了使有关的讨论简单化,我们在这里考虑一个非常简单的符号求导程序,它处理的表达式都是由对于两个参数的加和乘运算构造起来的。对于这种表达式求导的工作可以通过下面几条规约规则完成:
可以看到,这里的最后两条规则具有递归的性质,也就是说,想要得到一个和式的导数,我们首先要找到其中各个项的导数,而后将它们相加。这里的每个项又可能是需要进一步分解的表达式。通过这种分解,最终将产生出常量和变量,它们的导数就是0或者1.
为了能在一个过程中体现这些规则,我么就像在前面设计有理数的实现时所做的那样,采用同样的数据抽象策略。给定一个代数表达式,我们可以判断出某个表达式是否为一个和式、乘式、常量或变量,也能够提取出表达式里的各个部分。对于一个和式,我们可能希望取得其被加项(第一个项)和加项(第二个项)。我们假定现在已经有了一些过程,它们实现了下述的构造函数、选择函数和谓词:
is_number(e) # e是数值吗?
is_variable(e) # e是变量吗?
is_same_variable(v1, v2) # v1和v2是同一个变量吗
is_sum(e) # e是和式吗?
addend(e) # 取e中的被加数
augend(e) # 取e中的加数
make_sum(a1, a2) # 构造起a1与a2的和式
is_product(e) # e是乘式吗?
multiplier(e) # 取e中的被乘数
multiplicand(e) # 取e中的乘数
make_product(m1, m2) # 构造起m1与m2的乘式
利用这些过程,我们就可以将各种求导规则用下面的过程表示出来了:
# 参数exp为表达式,var为欲求导的自变量
def deriv(exp, var):
if is_number(exp):
return "0"
elif is_variable(exp):
if is_same_variable(exp, var):
return "1"
else:
return "0"
elif is_sum(exp):
return make_sum(deriv(addend(exp), var), \
deriv(augend(exp), var))
elif is_product(exp):
return make_sum(\
make_product(multiplier(exp), \
deriv(multiplicand(exp), var)), \
make_product(deriv(multiplier(exp), var), \
multiplicand(exp))
)
else:
raise ValueError("unknown expression type")
过程deriv里包含了一个完整的求导算法。因为它是基于抽象数据表述的,因此,无论我们如何选择代数表达式exp的具体表示,只要正确地设计了我们前面列出的选择函数、谓词函数和构造函数,这个过程都可以工作。下面我们来看如何对这些函数进行设计。
函数设计
在对函数进行设计之前,我们需要先确定代数表达式的表示。我们固然可以用字符串来直接表达代数表达式,如将表达式ax+bax+b表示为字符串"a*x+b"。然而,这种表示方式体现不出表达式树的层次,不利于我们后面对表达式的操作。回想一下,我们在博客《Python:实现简单的递归下降Parser》中介绍了如何将表达式解析为表达式树,也即将ax+bax+b表示为("+", ("*", "a", "x"), "b"),这样我们就能够对上述的函数进行进一步设计了。注意,在Lisp中组合式本身就采用带括号的前缀形式来表示,因此若用Lisp语言实现则不需要事先写Parser(其实推广一步说,Lisp的整个程序都是一个由嵌套括号组成的表达式树,也就是说Lisp语言的的解释器也是不需要写Parser的)。
- 判断是否为数值:
def is_number(x):
return isinstance(x, str) and x.isnumeric()
- 判断是否为变量:
def is_variable(x):
return isinstance(x, str) and x.isalpha()
- 判断两个变量是否相同:
def is_same_variable(v1, v2):
return is_variable(v1) and is_variable(v2) and v1 == v2
- 和式与乘式都构造为表
# 构造起a1和a2的和式
def make_sum(a1, a2):
return ("+", a1, a2)
# 构造起m1和m2的乘式
def make_product(m1, m2):
return ("*", m1, m2)
- 和式就是第0个元素(下标从0开始)为符号为
+的元组
def is_sum(x):
return isinstance(x, tuple) and x[0] == "+"
- 被加数是表示和式的表里的第1个元素(下标从0开始):
def addend(s):
return s[1]
- 加数是表达和式元组里的第2个元素(下标从0开始):
def augend(s):
return s[2]
- 乘式就是第0个元素(下标从0开始)为符号为
*的元组
def is_product(x):
return isinstance(x, tuple) and x[0] == "*"
- 被乘数是表示乘式的元组里的第1个元素(下标从0开始)
def multiplier(p):
return p[1]
- 乘数是表示乘式的元组里的第2个元素(下标从0开始)
def multiplicand(p):
return p[2]
这样,为了得到一个能够工作的符号求导程序,我们只需要将这些过程与deriv装在一起,现在让我们看几个表现这一程序的行为的实例:
# 输入为元组,默认已经完成了表达式解析
print(deriv(("+", "x", "3"), "x"))
# ('+', '1', '0')
print(deriv(("*", "x", "y"), "x"))
# ('+', ('*', 'x', '0'), ('*', '1', 'y'))
print(deriv(("*", ("*", "x", "y"), ("+", "x", "3")), "x"))
# ('+', ('*', ('*', 'x', 'y'), ('+', '1', '0')), ('*', ('+', ('*', 'x', '0'), ('*', '1', 'y')), ('+', 'x', '3')))
程序产生出的这些结果是对的,但是它们没有经过化简。我们确实有:
当然,我们也可能希望这一程序能够知道x⋅0=0,1⋅y=yx⋅0=0,1⋅y=y以及0+y=y0+y=y。因此,第二个例子的结果就应该是简单的yy。正如上面的第三个例子所显示的,当表达式变得更加复杂时,这一情况也可能变成严重的问题。
现在所面临的困难很像我们在做有理数时所遇到的问题:希望将结果化简到最简单的形式。为了完成有理数的化简,我们只需要修改构造函数和选择函数的实现。这里也可以采取同样的策略。我们在这里也完全不必修改deriv,只需要修改make_sum,使得当两个求和对象都是数时,make_sum求出它们的和返回。此外,如果其中的一个求和对象是0,那么make_sum就直接返回另一个对象。
def make_sum(a1, a2):
if eq_number(a1, "0"):
return a2
elif eq_number(a2, "0"):
return a1
elif is_number(a1) and is_number(a2):
return str(int(a1) + int(a2))
else:
return ("+", a1, a2)
在这个实现里用到了过程eq_number,它检查某个表达式是否等于一个给点的数。
def eq_number(exp, num):
return is_number(exp) and exp == num
与此类似,我们也需要修改make-product,设法引进下面的规则:0与任何东西的乘积都是0,1与任何东西的乘积总是那个东西:
def make_product(m1, m2):
if eq_number(m1, "0") or eq_number(m2, "0"):
return "0"
elif eq_number(m1, "1"):
return m2
elif eq_number(m2, "1"):
return m1
elif is_number(m1) and is_number(m2):
return str(int(m1) * int(m2))
else:
return ("*", m1, m2)
下面是这一新过程版本对前面三个例子的结果:
print(deriv(("+", "x", "3"), "x")) # 1
print(deriv(("*", "x", "y"), "x")) # y
print(deriv(("*", ("*", "x", "y"), ("+", "x", "3")), "x"))
# ('+', ('*', 'x', 'y'), ('*', 'y', ('+', 'x', '3')))
# 即对(x * y) * (x + 3)求导后得到 (x * y) + y * ( x + 3)
显然情况已经大大改观。但是,第三个例子还是说明,想要做出一个程序,使它能将表达式做成我们都能同意的“最简单”形式,前面还有很长的路要走。代数化简是一个非常复杂的问题,除了其他各种因素之外,还有另外一个根本性问题:对于某种用途的最简形式,对于另一用途可能就不是最简形式。
2.3.3 实例:集合的表示
用元组来表示代数表达式是直截了当的,现在我们要转到集合的表示问题,此时表示方式的选择就不那么显然了。实际上,在这里存在几种选择,而且它们之间在几个方面存在明显的不同。
非形式化地说,一个集合就是一些不同对象的汇集。要给出精确定义,我们可以利用数据抽象的方法,也就是说,用一组可以作用于“集合”的操作来定义它们。这些操作是union_set,intersection_set,is_element_of_set,adjoin_set。is_element_of_set是一个谓词,用于确定某个给定元素是不是某个给定集合的成员。adjoin-set以一个对象和一个集合为参数,返回一个集合,其中包含了原集合的所有元素与新加入的元素。union-set为计算两个集合的并集,intersection-set为计算两个集合的交集。
集合作为未排序的表
集合的一种表示形式就是用其元素的表,其中任何元素的出现都不超过一次。这样,空集就用空表来表示。对于这种表示形式,is_element_of_set定义如下:
def is_element_of_set(x, set):
if not set:
return False
elif x == set[0]:
return True
else:
return is_element_of_set(x, set[1: ])
利用它就能写出adjoin-set。如果要加入的对象已经在相应集合里,那么就返回那个集合;否则就将这一对象加入表示集合的表里:
def adjoin_set(x, set):
if is_element_of_set(x, set):
return set
else:
return [x] + set
实现intersection_set时可以采用递归策略:如果我们已知如何做出set2与set1[1: ]的交集,那么就只需要确定是否将set1[0]包含到结果之中了,而这依赖于set1[0]是否也在set2中。下面是这样写出的过程:
def intersection_set(set1, set2):
if not set1 or not set2:
return []
elif is_element_of_set(set1[0], set2):
return [set1[0]] + intersection_set(set1[1: ], set2)
else:
return intersection_set(set1[1: ], set2)
在设计一种表示形式时,有一件必须关注的事情是效率问题。为考虑这一问题,就需要考虑上面定义的各集合操作所需要的工作步数。因为它们都使用了is_element_of_set,这一操作的速度对整个集合的实现效率将有重大影响。在上面这个实现里,如果集合有nn个元素,is_element_of_set就可能需要nn步才能完成。这样,这一操作所需的步数将以Θ(n)Θ(n)的速度增长。adjoin_set使用了这个操作,因此它所需的步数也已Θ(n)Θ(n)的速度增长。而对于intersection_set,它需要对set_1的每个元素做一次is_element_of_set检查,因此所需步数在两个集合大小都为nn时将以Θ(n2)Θ(n2)增长。union_set的情况也是如此。
集合作为排序的表
加速集合操作的一种方式是改变表示方式,使集合元素在表中按照上升序排列。为此,我们就需要有某种方式来比较两个元素,以便确定哪个元素更大。如按照字典序做符号的比较,或者同意采用某种方式为每个对象关联一个唯一的数,在比较元素的时候比较该数即可。为了简化讨论,我们仅考虑元素是数值的情况。下面将数的集合表示为元素按照升序排列的表。在前面第一种表示方式下,集合{1,3,6,10}{1,3,6,10}的元素在相应的表里可以任意排列,而在现在新的表示方式中,我们就只允许用表[1, 3, 6, 10]。
从操作is_element_of_set可以看到采用有序表的一个优势:为了检查一个项的存在性,现在就不必扫描整个表了。如果检查中遇到的某个元素大于当时要找的东西,那么就可以断定这个东西根本不在表里:
def is_element_of_set(x, set):
if not set:
return False
elif x == set[0]:
return True
elif x < set[0]:
return False
else:
return is_element_of_set(x, set[1: ])
这样能节约多少步数呢?在最坏情况下,我们要找的项目可能是集合中的最大元素,此时所需步数与采用未排序的表示时一样。不过在平均情况下,我们可以期望需要检查表中的一半元素,所需步数大约是n/2n/2,这仍然是Θ(n)Θ(n)的增长速度,但与前一实现相比,平均来说节约了大约一半的步数(注意,原书此处有误,前面说未排序表需要检查整个表,考虑的只是一种特殊情况:查找没有出现在表里的元素。如果查找的是表里存在的元素,即使采用未排序的表,平均查找长度也是表元素的一半)。
操作intersection_set的加速情况更使人印象深刻。在未排序的表示方式里,这一操作需要Θ(n)2Θ(n)2的步数,因为对set1中的每个元素,我们都需要对set2做一次完全的扫描。对于排序表示则可以有一种更聪明的方法。我们在开始时比较两个集合的起始元素,例如x1和x2。如果x1等于x2。那么这样就得到了交集的一个元素,而交集的其他元素就是这两个集合[1:]的交集。如果x1小于x2,由于x2是集合set2的最小元素,我们立即可以断定x1不会出现在集合set2的任何地方,因此它不应该在交集里。这样,两集合的交集就等于集合set2与set1[1:]的交集。与此类似,如果x2小于x1,两集合的交集就等于集合set1与set2[1:]的交集。下面是按这种方式写出的过程:
def intersection_set(set1, set2):
if not set1 or not set2:
return []
else:
x1, x2 = set1[0], set2[0]
if x1 == x2:
return [x1] + intersection_set(set1[1:], set2[1: ])
elif x1 < x2:
return intersection_set(set1[1: ], set2)
elif x2 < x1:
return intersection_set(set1, set2[1: ])
现估计这一过程所需的步数。注意,在每个步骤中,我们都将求交集问题归结到更小集合的交集计算问题——去掉了set1额set2之一或者是两者的第一个元素。这样,所需步数至多等于set1于set2的大小之和,而不像在未排序表示中它们的乘积。这也就是Θ(n)Θ(n)的增长速度,而不是Θ(n2)Θ(n2)——这一加速非常明显,即使对中等大小的集合也是如此。
集合作为二叉树
如果将集合元素安排成一棵树的形式,我们还可以得到比排序表表示更好的结果。树中每个节点保存集合中的一个元素,称为该节点的“数据项”,它还链接到另外的两个节点(可能为空)。其中“左边”的链接所指向的所有元素均小于本节点的元素,而“右边”链接到的元素都大于本节点里的元素。如下图所示是一棵表示集合的树(同一个集合表示为树可以有多种不同的方式)。
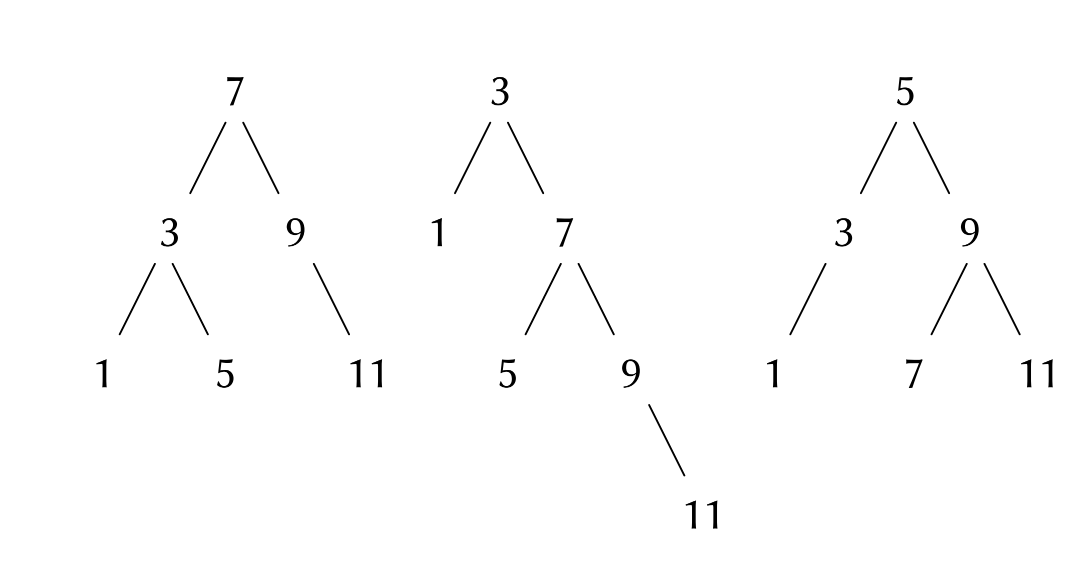
树方法的优点在于,对于检查某个数xx是否在集合里这个任务,我们可以用x与树顶点的数据项进行比较。如果x小于它,我么就知道只需要搜索左子树;如果x比较大,那么就只需要搜索右子树。在这样做时,如果该树是“平衡的”,也即每棵子树大约是整个树的一半大,那么经过这样一步我们就将搜索规模为nn的树的问题,归约为搜索规模为n/2n/2的树的问题。由于每次经过这个步骤能够使树的大小减小一半,我们可以期望搜索规模为nn的树的计算步数以Θ(logn)Θ(logn)速度增长。在集合很大时,相对于原来的表示,现在的操作速度将明显快很多。
我们可以用表来表示树,讲节点表示为三个元素的表:本节点中的数据项,其左子树和右子树。以空表作为左子树或者右子树,就表示没有子树连接在那里。我们可以用下面过程描述这种表示:
def entry(tree):
return tree[0]
def left_branch(tree):
return tree[1]
def right_branch(tree):
return tree[2]
def make_tree(entry, left, right):
return [entry, left, right]
现在,我们就可以采用上面描述的方式实现过程is_element_of_set了:
def is_element_of_set(x, set):
if not set:
return False
elif entry(set) == x:
return True
elif x < entry(set):
return is_element_of_set(x, left_branch(set))
elif x > entry(set):
return is_element_of_set(x, right_branch(set))
我们对is_element_of_set操作的测试结果如下:
set = [7, [3, [1, [], []], [5, [], []]], [9, [], [11, [], []]]]
print(is_element_of_set(5, set)) # True
print(is_element_of_set(99, set)) # False
像集合里插入一个项的实现方式与此类似,也需要Θ(logn)Θ(logn)的步数。为了加入元素x,我们需要将x与节点数据项比较,以便确定x应该加入右子树还是左子树中。下面是这个过程:
def adjoin_set(x, set):
if not set:
return make_tree(x, [], [])
elif x == entry(set):
return set
elif x < entry(set):
return make_tree(entry(set), \
adjoin_set(x, left_branch(set)), \
right_branch(set))
elif x > entry(set):
return make_tree(entry(set), \
left_branch(set), \
adjoin_set(x, right_branch(set)))
我们对adjoin_set操作的测试结果如下:
set = [7, [3, [1, [], []], [5, [], []]], [9, [], [11, [], []]]]
print(adjoin_set(6, set))
# [7, [3, [1, [], []], [5, [], [6, [], []]]], [9, [], [11, [], []]]]
注意,我们在上面断言,搜索树的操作在对数步数中完成,这实际上依赖于树“平衡”的假设。也就是说,每个树的左右子树中的节点大致上一样多,因此每棵子树中包含的节点大约就是其父的一半。但是我们怎样才能确保构造出的树是平衡的呢?即使是从一颗平衡的树开始工作,采用adjoin_set加入元素也可能产生出不平衡的的结果。因为新加入的元素的位置依赖于它与当时已经在树中的那些项比较的情况。我们可以期望,如果“随机地”将元素加入树中,平均而言将会使树趋于平衡。但在这里并没有任何保证。例如,如果我们从空集出发,顺序将数值1至7加入其中,我们就会得到如下图所示的高度不平衡的树。
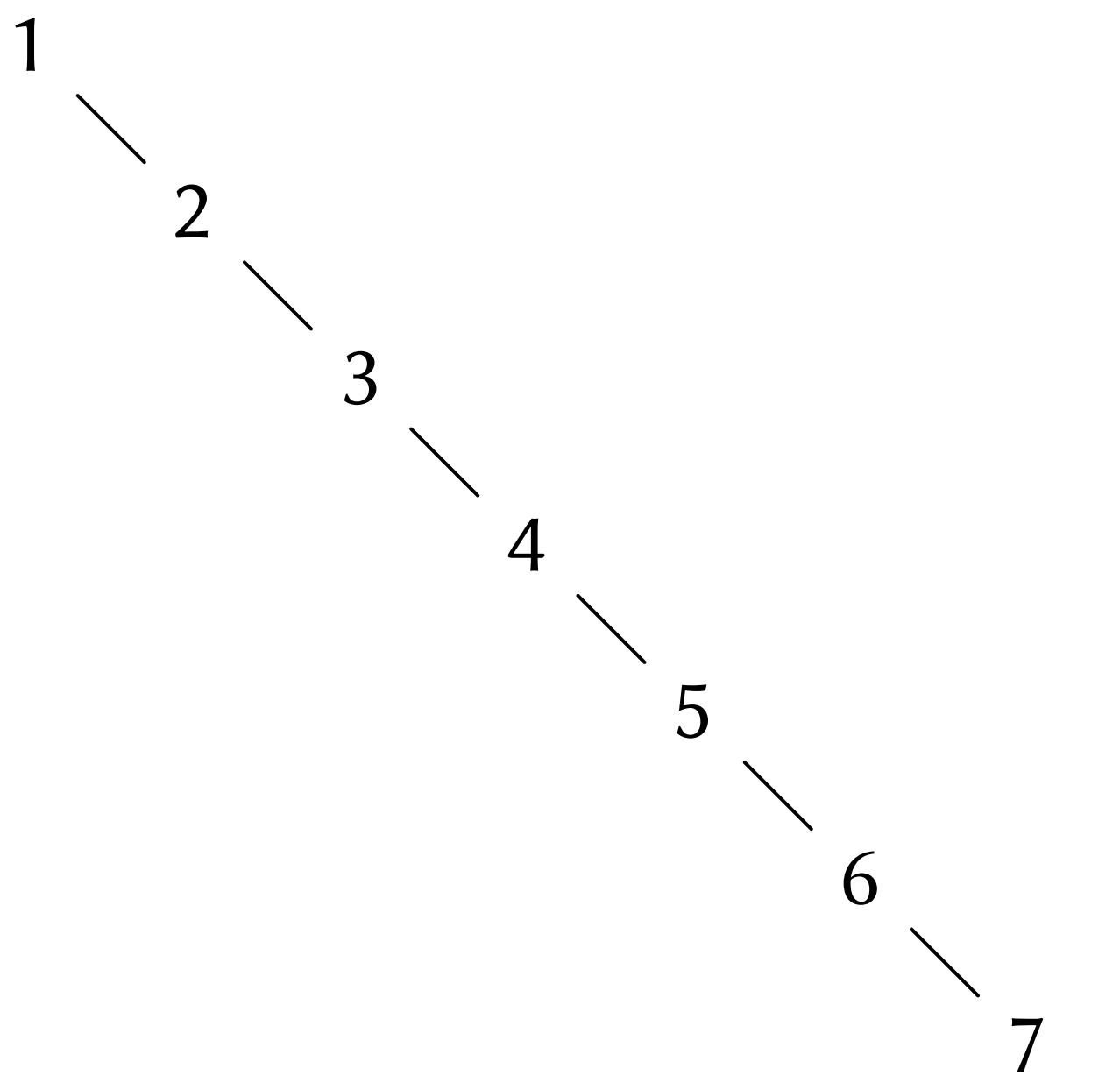
在这个树里,所有的左子树都为空,所以它与简单排序表相比一点优势也没有。解决这个问题的一种方式是定义一个操作,它可以将任意的树变换为一棵具有同样元素的平衡树。在每执行过几次adjoin_set操作之后,我们就可以通过执行它来保持树的平衡。当然,解决这一问题的方法还有很多,大部分这类方法都涉及到设计一种新的数据结构,设法使这种数据结构上的搜索和插入操作都在Θ(logn)Θ(logn)步数内完成(这种结构的例子如B树和红黑树,参见《算法导论》)。
集合与信息检索
我们考察了用表表示集合的各种选择,并看到了数据对象表示的选择可能如何深刻地影响到使用数据的程序的性能。关注集合的另一个原因是,这里所讨论的技术在设计信息检索的应用中将会一次又一次地出现。
现在考虑一个包含大量独立记录的数据库,我们可以将这个数据库表示为一个记录的集合,将每个记录中的一部分当做标识key(键值)。为了根据给定键值确定相关记录的位置,我们用一个过程lookup,它以一个键值和数据库为参数,返回具有这个键值的记录,或者在找不到相应记录时报告失败。lookup的实现方式几乎与is_element_of_set一模一样,如果记录的集合被表示为未排序的表,我们就可以用:
def lookup(given_key, set_of_records):
if not set_of_records:
return False
elif given_key == key(set_of_records[0]):
return set_of_records[0]
else:
return lookup(given_key, set_of_records[1: ])
不言而喻,还有比未排序的表更好的表示大集合的方法。常常需要“随机访问”其中记录的信息检索系统通常用某种基于树的方式实现,例如前面讨论过的二叉树。
2.3.4 实例:Huffman编码树
本节将给出一个实际使用表结构和数据抽象去操作集合与树的例子。这一应用是想确定一些用0和1(二进制位)的序列表示数据的方法。举例说,用于在计算机里表示文本的ASCII标准编码将每个字符表示为一个包含77个二进制位的序列,采用77个二进制位能够区分2727种不同的情况,即128128个可能不同的字符。一般而言,如果我们需要区分nn个不同字符,那么就需要为每个字符使用log2nlog2n个二进制位。假设我们的所有信息都是用A、B、C、D、E、F、G和H这样8个字符构成的,那么就可以选择为每个字符用3个二进制位,例如:
采用这种编码方式,消息
将编码为54个二进制位
像ASCII码和上面A到H这样的方式称为定长编码,因为它们采用同样数目的二进制位表示消息中的每一个字符。变长编码方式就是用不同数目的二进制位表示不同的字符,这种方式有时也可能有些优势。举例说,莫尔斯电报码对于字母表中各个字母就没有采用同样数目的点和划,特别是最常见的字母E只用一个点表示。一般而言,如果在我们的消息里,某些符号出现得频繁,而另一些却很少见,那么如果为这些频繁出现的字符指定较短的码字,我们就可能更有效地完成数据的编码(对于同样消息使用更少的二进制位)。请考虑下面对于字母A到H的另一种编码:
采用这种编码方式,上面的同样信息将编码为如下的串:
这个串种只包含42个二进制位,也就是说,与上面的定长编码相比,现在的这种方式节约了超过20%20%的空间。
采用变长编码有一个困难,那就是在读0/1序列的过程中确定何时到达了一个字符的结束。莫尔斯码解决这一问题的方式是在每个字母的电划序列之后用一个特殊的分隔符(它用的是一个间歇)。另一种解决方式是以某种方式设计编码,使得其中每个字符的完整编码都不是另一个字符编码的开始一段(或称前缀)。这样的编码称为前缀码。在上面的例子中,A编码为0而B编码为100,没有其他字符的编码由0或者100开始。
一般而言,如果能够通过变长前缀码去利用被编码消息中符号出现的相对频度,那么就能够明显地节约空间。完成这件事情的一种特定方式称为Huffman编码。一个Huffman编码可以表示为一颗二叉树,如下就是上面给出的A到H编码所对应的Huffman树:

可以看到,位于树叶的每一个符号被赋予一个相对权重(也就是它的相对频度),非叶节点所包含的权重是位于它之下的所有叶节点的权重之和。这种权重只在构造树的过程中使用,而在编码和解码的过程中并不使用。
给定了一颗Huffman树,要找出任一符号的编码,我们只需从树根开始往下,知道找到存有这一符号的树叶为止,每次向左给编码加一个0,向右加一个1。比如从上图中的树根开始,到达D的叶节点的方式是走右-左-右-右,因此其代码为1011。
对应地,解码时,我们也从树根开始,通过位序列中的0或1确定是移向左分支还是右分支。当我们到达一个叶节点时,就生成出了消息中的一个符号。比如如果给我们的是上面的树和序列10001010,则操作序列为右-左-左找到B,然后再此从根开始左找到A,然后再此从根开始右-左-右-左找到C。这样整个消息也就是ABC。
生成Huffman树
我们上面只说了编码和解码的过程,那么给定了符号的“字母表”和它们的相对频度,我们怎么才能构造出“最好的编码”,也即使消息编码的位数达到最少呢?Huffman给出了完成这件事的第一个算法, 并且证明了若根据符号所出现的相对频度来建树, 这样产出的编码确实是最好的变长编码。我们这里略过Huffman编码最优性质的证明,将直接展示如何构造Huffman树。
生成Huffman树的算法实际上十分简单,其想法就是设法安排这棵树,使得那些带有最低频度的符号出现在离树根最远的地方。这一过程从叶节点的集合开始,找出两个具有最低权重的叶进行归并,产生出一个以这两个节点为左右分支的节点,新节点的权重就是那两个点的圈子之和。然后从原集合里删除前面的两个叶节点,利用新节点替代它们。之后以此类推继续这一过程。当集合中只剩下一个节点时,这一过程终止,而这个节点就是树根。下面显示的是上图中的Huffman树的生成过程:

这一算法并不总能描述一棵唯一的树,因为选出的最小权重节点有可能不唯一。还有,在做归并时,两个节点的顺序也是任一的,也就是说随便哪个都可以作为左分支或者右分支。
Huffman树的表示
在下面的练习中,我们将要做出一个使用Huffman树完成消息编码和编码、并能根据上面给出的梗概生成Huffman树的系统。开始还是讨论这种树的表示。
将一棵树的树叶表示为包含符号leaf、叶中符号和权重的表:
def make_leaf(symbol, weight):
return ["leaf", symbol, weight]
def is_leaf(object):
return object[0] == "leaf"
def symbol_leaf(x):
return x[1]
def weight_leaf(x):
return x[2]
在归并两个节点做出一棵树时,树的权重也就是,树的权重也就是这两个节点的权重之和,其符号集就是两个节点的符号集的并集。这里符号集我们直接用Python的字符串来表示,直接相加即可:
def make_code_tree(left, right):
return [left, \
right, \
symbols(left) + symbols(right), \
weight(left) + weight(right)]
如果以这种方式构造,我们就需要采用下面的选择函数:
def left_branch(tree):
return tree[0]
def right_branch(tree):
return tree[1]
def symbols(tree):
if is_leaf(tree):
return symbol_leaf(tree)
else:
return tree[2]
def weight(tree):
if is_leaf(tree):
return weight_leaf(tree)
else:
return tree[3]
在对树叶或者一般树调用过程symbols和weight时,它们需要做的事情有一点不同。这些不过是通用型过程(可以处理多于一种数据的过程)的简单示例,有关这方面的情况我们在2.4节和2.4节将有更多讨论。
解码过程
下面的过程实现解码算法,它以一个0/1的Python字符串和一棵Huffman树为参数:
def decode(bits, tree):
def decode_1(bits, current_branch):
if not bits:
return ""
else:
next_branch = choose_branch(bits[0], current_branch)
if is_leaf(next_branch):
return symbol_leaf(next_branch) + decode_1(bits[1: ], tree)
else:
return decode_1(bits[1: ], next_branch)
return decode_1(bits, tree)
def choose_branch(bit, branch):
if bit == "0":
return left_branch(branch)
elif bit == "1":
return right_branch(branch)
else:
raise ValueError("error: bad bit -- CHOOSE-BRANCH %s" % bit)
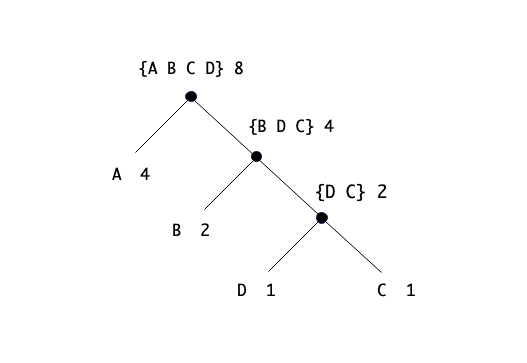
下面我们进行一下测试。定义一棵如下所示的编码树:
sample_tree = make_code_tree(make_leaf("A", 4),
make_code_tree(
make_leaf("B", 2),
make_code_tree(make_leaf("D", 1), make_leaf("C", 1))
))
print(sample_tree)
# [['leaf', 'A', 4], [['leaf', 'B', 2], [['leaf', 'D', 1], ['leaf', 'C', 1], 'DC', 2], 'BDC', 4], 'ABDC', 8]
这棵树实际上如下图所示:
再定义如下的样例消息:
sample_message = "0110010101110"
我们用decode完成该消息的解码,得到解码结果:
decoded_message = decode(sample_message, sample_tree)
print(decoded_message)
程序打印输出的编码结果为:
ADABBCA
编码过程
下面的过程实现编码算法,它以一个字母组成的Python字符串和一棵Huffman树为参数:
def encode(message, tree):
if not message:
return ""
else:
return encode_symbol(message[0], tree) + encode(message[1:], tree)
def encode_symbol(symbol, current_branch):
if is_leaf(current_branch):
return ""
else:
left, right = left_branch(current_branch), right_branch(current_branch)
if symbol in symbols(left):
return "0" + encode_symbol(symbol, left)
elif symbol in symbols(right):
return "1" + encode_symbol(symbol, right)
else:
raise ValueError("error: bad symbol -- CHOOSE-BRANCH %s" % symbol)
编码树仍采用我们上面解码部分所定义的sample_tree,然后定义如下的样例消息:
sample_message = "ADABBCA"
我们用encode完成该消息的解码,得到解码结果:
encoded_message = encode(sample_message, sample_tree)
print(encoded_message)
程序打印输出的编码结果为:
0110010101110
建树过程
下面的过程建树编码算法,它以一个符号-频度对偶表位参数(其中没有任何符号出现在多于一个对偶中),并根据Huffman算法生产出Huffman编码树:
def generate_huffman_tree(paris):
return successive_merge(make_leaf_set(paris))
def make_leaf_set(pairs):
if not pairs:
return []
else:
pair = pairs[0]
return adjoin_set(make_leaf(pair[0], pair[1]), \
make_leaf_set(pairs[1: ]))
def successive_merge(leaf_set):
if len(leaf_set) == 1:
return leaf_set
left, right = leaf_set[0], leaf_set[1]
return successive_merge(adjoin_set(make_code_tree(left, right), leaf_set[2: ]))
def adjoin_set(x, set):
if not set:
return [x]
if weight(x) < weight(set[0]):
return [x] + set
else:
return [set[0]] + adjoin_set(x, set[1: ])
注意这里的make_leaf_set过程将对偶表变换为叶的有序集,successive_merge使用make_code_tree反复归并集合中具有最小权重的元素,直至集合中只剩下一个元素为止。这个元素就是我们所需要的Huffman树(这一过程稍微有点技巧性,但并不复杂,因为我们利用了有序集合表示这一事实)。
然后定义如下的对偶表:
pairs = ([("A", 4), ("B", 2), ("D", 1), ("C", 1)])
我们用generate_huffman_tree完成由该对偶表到Huffman树的构建,得到Huffman树的构建结果:
tree = generate_huffman_tree(pairs)
print(tree)
程序打印输出的Huffman树构建结果为:
# [['leaf', 'A', 4], [['leaf', 'B', 2], [['leaf', 'C', 1], ['leaf', 'D', 1], 'CD', 2], 'BCD', 4], 'ABCD', 8]
这实质上和我们前面所画出来的Huffman树在功能上是等效的,但具体的某些左右子树可能有差异,因为Huffman树本身就不唯一。
- [1] Abelson H, Sussman G J. Structure and interpretation of computer programs[M]. The MIT Press, 1996.
- [2] Cormen T H, Leiserson C E, Rivest R L, et al. Introduction to algorithms[M]. MIT press, 2022.
__EOF__
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK