

迁移学习(DANN)《Domain-Adversarial Training of Neural Networks》 - 加微信X4665...
source link: https://www.cnblogs.com/BlairGrowing/p/17020391.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

论文标题:Domain-Adversarial Training of Neural Networks
论文作者:Yaroslav Ganin, Evgeniya Ustinova, Hana Ajakan, Pascal Germain, Hugo Larochelle....
论文来源: JMLR 2016
论文地址:download
论文代码:download
引用次数:5292
1 Domain Adaptation
We consider classification tasks where XX is the input space and Y={0,1,…,L−1}Y={0,1,…,L−1} is the set of LL possible labels. Moreover, we have two different distributions over X×YX×Y , called the source domain DSDS and the target domain DTDT . An unsupervised domain adaptation learning algorithm is then provided with a labeled source sample SS drawn i.i.d. from DSDS , and an unlabeled target sample TT drawn i.i.d. from DXTDTX , where DXTDTX is the marginal distribution of DTDT over XX .
S={(xi,yi)}ni=1∼(DS)nS={(xi,yi)}i=1n∼(DS)n
T={xi}Ni=n+1∼(DXT)n′T={xi}i=n+1N∼(DTX)n′
with N=n+n′N=n+n′ being the total number of samples. The goal of the learning algorithm is to build a classifier η:X→Yη:X→Y with a low target risk
RDT(η)=Pr(x,y)∼DT(η(x)≠y),RDT(η)=Pr(x,y)∼DT(η(x)≠y),
while having no information about the labels of DTDT .
2 Domain Divergence
dH(DXS,DXT)=2supη∈H∣∣Prx∼DXS[η(x)=1]−Prx∼DXT[η(x)=1]∣∣dH(DSX,DTX)=2supη∈H|Prx∼DSX[η(x)=1]−Prx∼DTX[η(x)=1]|
该散度的意思是,在一个假设空间 HH 中,找到一个函数 hh,使得 Prx∼D[h(x)=1]Prx∼D[h(x)=1] 的概率尽可能大,而 Prx∼D′[h(x)=1]Prx∼D′[h(x)=1] 的概率尽可能小。【如果数据来自源域,域标签为 11,如果数据来自目标域,域标签为 00】也就是说,用最大距离来衡量 D,D′D,D′ 之间的距离。同时这个 hh 也可以理解为是用来尽可能区分 DD,D′D′ 这两个分布的函数。
可以通过计算来计算两个样本 S∼(DXS)nS∼(DSX)n 和 T∼(DXT)n′T∼(DTX)n′ 之间的经验 H-divergence H-divergence :
d^H(S,T)=2(1−minη∈H[1n∑i=1nI[η(xi)=0]+1n′∑i=n+1NI[η(xi)=1]])(1)d^H(S,T)=2(1−minη∈H[1n∑i=1nI[η(xi)=0]+1n′∑i=n+1NI[η(xi)=1]])(1)
其中,I[a]I[a] 是指示函数,当 aa 为真时,I[a]=1I[a]=1,否则 I[a]=0I[a]=0。
3 Proxy Distance
由于经验 HH-divergence 难以精确计算,可以使用判别源样本与目标样本的学习算法完成近似。
构造新的数据集 UU :
U={(xi,0)}ni=1∪{(xi,1)}Ni=n+1(2)U={(xi,0)}i=1n∪{(xi,1)}i=n+1N(2)
使用 HH-divergence 的近似表示 Proxy A-distance(PAD),其中 ϵϵ 为 源域和目标域样本的分类泛化误差:
d^A=2(1−2ϵ)(3)d^A=2(1−2ϵ)(3)
4 Method
为学习一个可以很好地从一个域推广到另一个域的模型,本文确保神经网络的内部表示不包含关于输入源(源或目标域)来源的区别信息,同时在源(标记)样本上保持低风险。
首先考虑一个标准的神经网络(NN)结构与一个单一的隐藏层。为简单起见,假设输入空间由 mm 维向量 X=RmX=Rm 构成。隐层 GfGf 学习一个函数 Gf:X→RDGf:X→RD ,该函数将一个示例映射为一个 dd 维表示,并由矩阵-向量对 (W,b)∈RD×m×RD(W,b)∈RD×m×RD 参数化:
Gf(x;W,b)=sigm(Wx+b) with sigm(a)=[11+exp(−ai)]|a|i=1Gf(x;W,b)=sigm(Wx+b) with sigm(a)=[11+exp(−ai)]i=1|a|
类似地,预测层 GyGy 学习一个函数 Gy:RD→[0,1]LGy:RD→[0,1]L,该函数由一对 (V,c)∈RL×D×RL(V,c)∈RL×D×RL:
Gy(Gf(x);V,c)=softmax(VGf(x)+c) with softmax(a)=[exp(ai)∑|a|j=1exp(aj)]|a|i=1Gy(Gf(x);V,c)=softmax(VGf(x)+c) with softmax(a)=[exp(ai)∑j=1|a|exp(aj)]i=1|a|
其中 L=|Y|L=|Y|。通过使用 softmax 函数,向量 Gy(Gf(x))Gy(Gf(x)) 的每个分量表示神经网络将 xx 分配给该分量在 YY 中表示的类的条件概率。给定一个源样本 (xi,yi)(xi,yi),使用正确标签的负对数概率:
Ly(Gy(Gf(xi)),yi)=log1Gy(Gf(x))yiLy(Gy(Gf(xi)),yi)=log1Gy(Gf(x))yi
对神经网络的训练会导致源域上的以下优化问题:
minW,b,V,c[1n∑ni=1Liy(W,b,V,c)+λ⋅R(W,b)]minW,b,V,c[1n∑i=1nLyi(W,b,V,c)+λ⋅R(W,b)]
其中,Liy(W,b,V,c)=Ly(Gy(Gf(xi;W,b);V,c),yi)Lyi(W,b,V,c)=Ly(Gy(Gf(xi;W,b);V,c),yi),R(W,b)R(W,b) 是一个正则化项。
我们的方法的核心是设计一个直接从 Definition 1 的 HH-divergence 推导出的域正则化器。为此,我们将隐层 Gf(⋅)Gf(⋅)(Eq.4Eq.4)的输出视为神经网络的内部表示。因此,我们将源样本表示法表示为
S(Gf)={Gf(x)∣x∈S}S(Gf)={Gf(x)∣x∈S}
类似地,给定一个来自目标域的未标记样本,我们表示相应的表示形式
T(Gf)={Gf(x)∣x∈T}T(Gf)={Gf(x)∣x∈T}
在 Eq.1Eq.1 的基础上,给出了样本 S(Gf)S(Gf) 和 T(Gf)T(Gf) 之间的经验 H-divergenceH-divergence:
d^H(S(Gf),T(Gf))=2(1−minη∈H[1n∑i=1nI[η(Gf(xi))=0]+1n′∑i=n+1NI[η(Gf(xi))=1]])(6)d^H(S(Gf),T(Gf))=2(1−minη∈H[1n∑i=1nI[η(Gf(xi))=0]+1n′∑i=n+1NI[η(Gf(xi))=1]])(6)
域分类层 GdGd 学习了一个逻辑回归变量 Gd:RD→[0,1]Gd:RD→[0,1] ,其参数为 向量-常量对 (u,z)∈RD×R(u,z)∈RD×R,它模拟了给定输入来自源域 DXSDSX 或目标域 DXTDTX 的概率:
Gd(Gf(x);u,z)=sigm(u⊤Gf(x)+z)(7)Gd(Gf(x);u,z)=sigm(u⊤Gf(x)+z)(7)
因此,函数 Gd(⋅)Gd(⋅) 是一个域回归器。我们定义它的损失是:
Ld(Gd(Gf(xi)),di)=dilog1Gd(Gf(xi))+(1−di)log11−Gd(Gf(xi))Ld(Gd(Gf(xi)),di)=dilog1Gd(Gf(xi))+(1−di)log11−Gd(Gf(xi))
其中,didi 表示第 ii 个样本的二进制域标签,如果 di=0di=0 表示样本 xixi 是来自源分布 xi∼DXSxi∼DSX),如果 di=1di=1 表示样本来自目标分布 xi∼DXTxi∼DTX。
回想一下,对于来自源分布(di=0di=0)的例子,相应的标签 yi∈Yyi∈Y 在训练时是已知的。对于来自目标域的例子,我们不知道在训练时的标签,而我们想在测试时预测这些标签。这使得我们能够在 Eq.5Eq.5 的目标中添加一个域自适应项,并给出以下正则化器:
R(W,b)=maxu,z[−1n∑i=1nLid(W,b,u,z)−1n′∑i=n+1NLid(W,b,u,z)](8)R(W,b)=maxu,z[−1n∑i=1nLdi(W,b,u,z)−1n′∑i=n+1NLdi(W,b,u,z)](8)
其中,Lid(W,b,u,z)=Ld(Gd(Gf(xi;W,b);u,z),di)Ldi(W,b,u,z)=Ld(Gd(Gf(xi;W,b);u,z),di) 。这个正则化器试图近似 Eq.6Eq.6 的 H-divergenceH-divergence,因为 2(1−R(W,b))2(1−R(W,b)) 是 d^H(S(Gf),T(Gf))d^H(S(Gf),T(Gf)) 的一个替代品。
为了学习,可以将 Eq.5Eq.5 的完整优化目标重写如下:
E(W,V,b,c,u,z)=1n∑i=1nLiy(W,b,V,c)−λ(1n∑i=1nLid(W,b,u,z)+1n′∑Ni=n+1Lid(W,b,u,z))(9)E(W,V,b,c,u,z)=1n∑i=1nLyi(W,b,V,c)−λ(1n∑i=1nLdi(W,b,u,z)+1n′∑i=n+1NLdi(W,b,u,z))(9)
对应的参数优化 W^W^, V^V^, b^b^, c^c^, u^u^, z^z^:
(W^,V^,b^,c^)(u^,z^)==arg minW,V,b,cE(W,V,b,c,u^,z^)arg maxu,zE(W^,V^,b^,c^,u,z)(W^,V^,b^,c^)=arg minW,V,b,cE(W,V,b,c,u^,z^)(u^,z^)=arg maxu,zE(W^,V^,b^,c^,u,z)

Generalization to Arbitrary Architectures
分类损失和域分类损失:
Liy(θf,θy)Lid(θf,θd)=Ly(Gy(Gf(xi;θf);θy),yi)=Ld(Gd(Gf(xi;θf);θd),di)Lyi(θf,θy)=Ly(Gy(Gf(xi;θf);θy),yi)Ldi(θf,θd)=Ld(Gd(Gf(xi;θf);θd),di)
优化目标:
E(θf,θy,θd)=1n∑i=1nLiy(θf,θy)−λ(1n∑i=1nLid(θf,θd)+1n′∑i=n+1NLid(θf,θd))(10)E(θf,θy,θd)=1n∑i=1nLyi(θf,θy)−λ(1n∑i=1nLdi(θf,θd)+1n′∑i=n+1NLdi(θf,θd))(10)
对应的参数优化 θ^fθ^f, θ^yθ^y, θ^dθ^d:
(θ^f,θ^y)θ^d==argminθf,θyE(θf,θy,θ^d)(11)argmaxθdE(θ^f,θ^y,θd)(12)(θ^f,θ^y)=argminθf,θyE(θf,θy,θ^d)(11)θ^d=argmaxθdE(θ^f,θ^y,θd)(12)
如前所述,由 Eq.11-Eq.12Eq.11-Eq.12 定义的鞍点可以作为以下梯度更新的平稳点找到:
θf⟵θf−μ(∂Liy∂θf−λ∂Lid∂θf)(13)θy⟵θy−μ∂Liy∂θy(14)θd⟵θd−μλ∂Lid∂θd(15)θf⟵θf−μ(∂Lyi∂θf−λ∂Ldi∂θf)(13)θy⟵θy−μ∂Lyi∂θy(14)θd⟵θd−μλ∂Ldi∂θd(15)
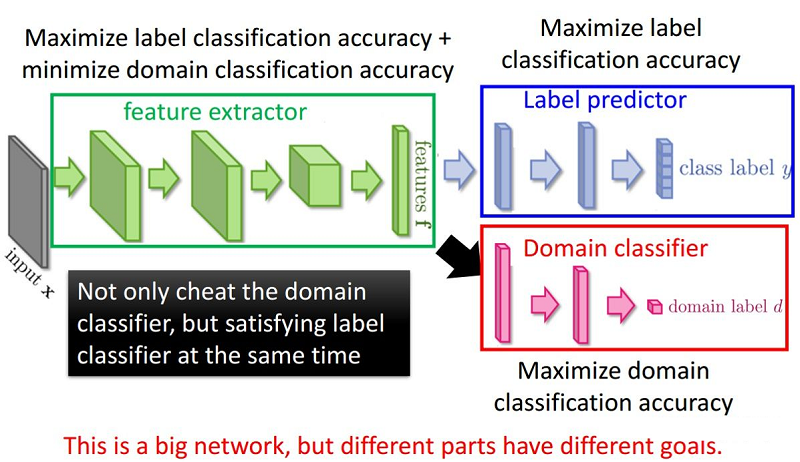
整体框架:

组件:
-
- 特征提取器(feature extractor)Gf(⋅;θf)Gf(⋅;θf) :将源域样本和目标域样本进行映射和混合,使域判别器无法区分数据来自哪个域;提取后续网络完成任务所需要的特征,使标签预测器能够分辨出来自源域数据的类别;
- 标签预测器(label predictor)Gy(⋅;θy)Gy(⋅;θy):对 Source Domain 进行训练,实现数据的分类任务,本文就是让 Source Domain 的图片分类越正确越好;
- 域分类器(domain classifier)Gd(⋅;θd)Gd(⋅;θd):二分类器,要让 Domain 的分类越正确越好,分类出是 Source 还是 Target ;
为什么要加梯度反转层:GRL?
域分类器和特征提取器中间有一个梯度反转层(Gradient reversal layer)。梯度反转层顾名思义将梯度乘一个负数,然后进行反向传播。加入GRL的目的是为了让域判别器和特征提取器之间形成一种对抗。
最大化 loss LdLd ,这样就可以尽可能的让两个 domain 分不开, feature 自己就渐渐趋于域自适应了。这是使用 GRL 来实现的,loss LdLd 在 domain classifier 中是很小的,但通过 GRL 后,就实现在 feature extractor 中不能正确的判断出信息来自哪一个域。
__EOF__
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK