

面向长代码序列的 Transformer 模型优化方法,提升长代码场景性能
source link: https://www.51cto.com/article/743793.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

面向长代码序列的 Transformer 模型优化方法,提升长代码场景性能
阿里云机器学习平台PAI与华东师范大学高明教授团队合作在SIGIR2022上发表了结构感知的稀疏注意力Transformer模型SASA,这是面向长代码序列的Transformer模型优化方法,致力于提升长代码场景下的效果和性能。由于self-attention模块的复杂度随序列长度呈次方增长,多数编程预训练语言模型(Programming-based Pretrained Language Models, PPLM)采用序列截断的方式处理代码序列。SASA方法将self-attention的计算稀疏化,同时结合了代码的结构特性,从而提升了长序列任务的性能,也降低了内存和计算复杂度。
论文:Tingting Liu, Chengyu Wang, Cen Chen, Ming Gao, and Aoying Zhou. Understanding Long Programming Languages with Structure-Aware Sparse Attention. SIGIR 2022
下图展示了SASA的整体框架:
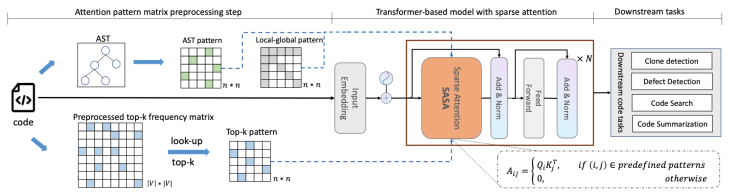
其中,SASA主要包含两个阶段:预处理阶段和Sparse Transformer训练阶段。在预处理阶段得到两个token之间的交互矩阵,一个是top-k frequency矩阵,一个是AST pattern矩阵。Top-k frequency矩阵是利用代码预训练语言模型在CodeSearchNet语料上学习token之间的attention交互频率,AST pattern矩阵是解析代码的抽象语法树(Abstract Syntax Tree,AST ),根据语法树的连接关系得到token之间的交互信息。Sparse Transformer训练阶段以Transformer Encoder作为基础框架,将full self-attention替换为structure-aware sparse self-attention,在符合特定模式的token pair之间进行attention计算,从而降低计算复杂度。
SASA稀疏注意力一共包括如下四个模块:
- Sliding window attention:仅在滑动窗口内的token之间计算self-attention,保留局部上下文的特征,计算复杂度为,为序列长度,是滑动窗口大小。
- Global attention:设置一定的global token,这些token将与序列中所有token进行attention计算,从而获取序列的全局信息,计算复杂度为,为global token个数。
- Top-k sparse attention:Transformer模型中的attention交互是稀疏且长尾的,对于每个token,仅与其attention交互最高的top-k个token计算attention,复杂度为。
- AST-aware structure attention:代码不同于自然语言序列,有更强的结构特性,通过将代码解析成抽象语法树(AST),然后根据语法树中的连接关系确定attention计算的范围。
为了适应现代硬件的并行计算特性,我们将序列划分为若干block,而非以token为单位进行计算,每个query block与
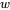
个滑动窗口blocks和
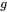
个global blocks以及
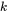
个top-k和AST blocks计算attention,总体的计算复杂度为
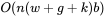
b为block size。
每个sparse attention pattern 对应一个attention矩阵,以sliding window attention为例,其attention矩阵的计算为:
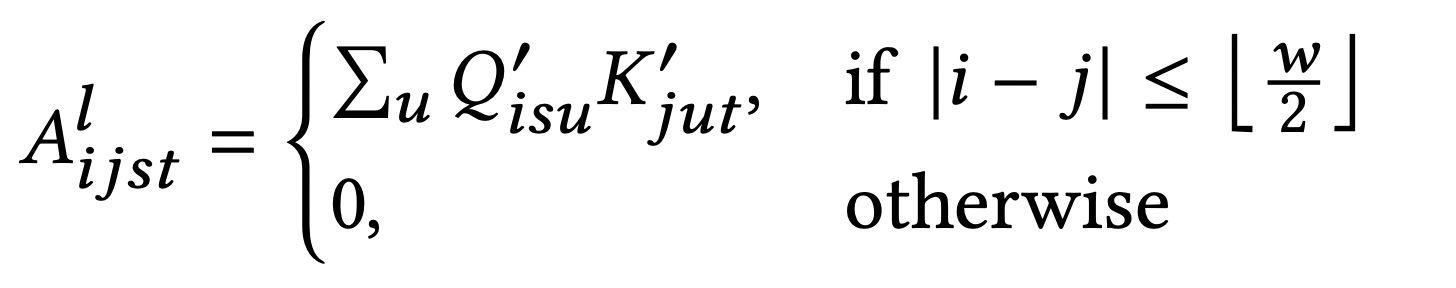
ASA伪代码:

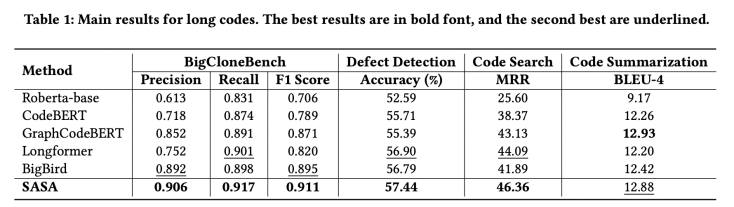
我们采用CodeXGLUE[1]提供的四个任务数据集进行评测,分别为code clone detection,defect detection,code search,code summarization。我们提取其中的序列长度大于512的数据组成长序列数据集,实验结果如下:
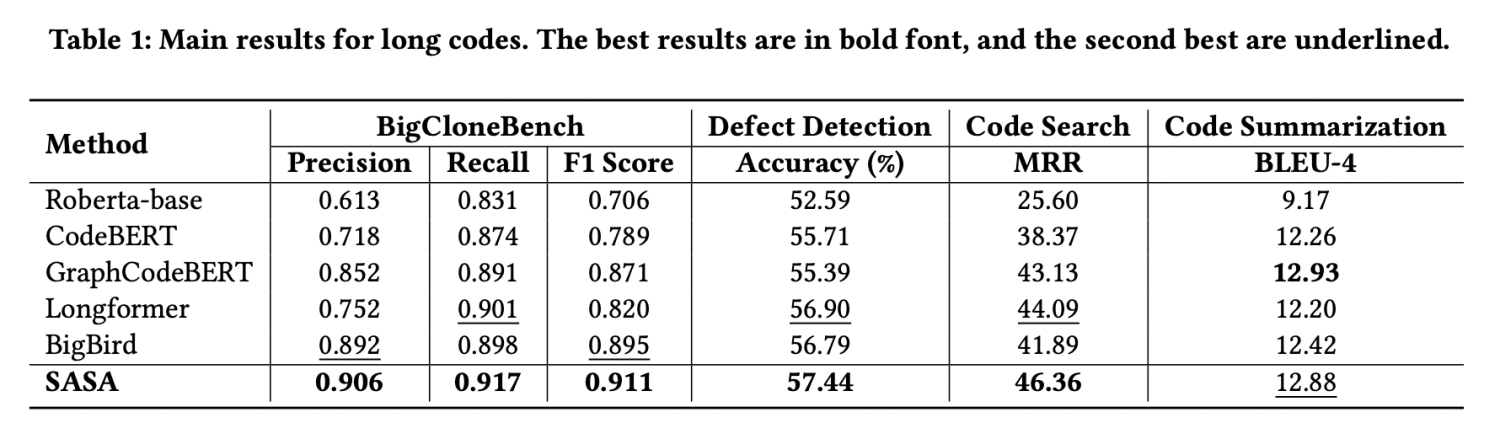
从实验结果可以看出,SASA在三个数据集上的性能明显超过所有Baseline。其中Roberta-base[2],CodeBERT[3],GraphCodeBERT[4]是采用截断的方式处理长序列,这将损失一部分的上下文信息。Longformer[5]和BigBird[6]是在自然语言处理中用于处理长序列的方法,但未考虑代码的结构特性,直接迁移到代码任务上效果不佳。
为了验证top-k sparse attention和AST-aware sparse attention模块的效果,我们在BigCloneBench和Defect Detection数据集上做了消融实验,结果如下:
sparse attention模块不仅对于长代码的任务性能有提升,还可以大幅减少显存使用,在同样的设备下,SASA可以设置更大的batch size,而full self-attention的模型则面临out of memory的问题,具体显存使用情况如下图:
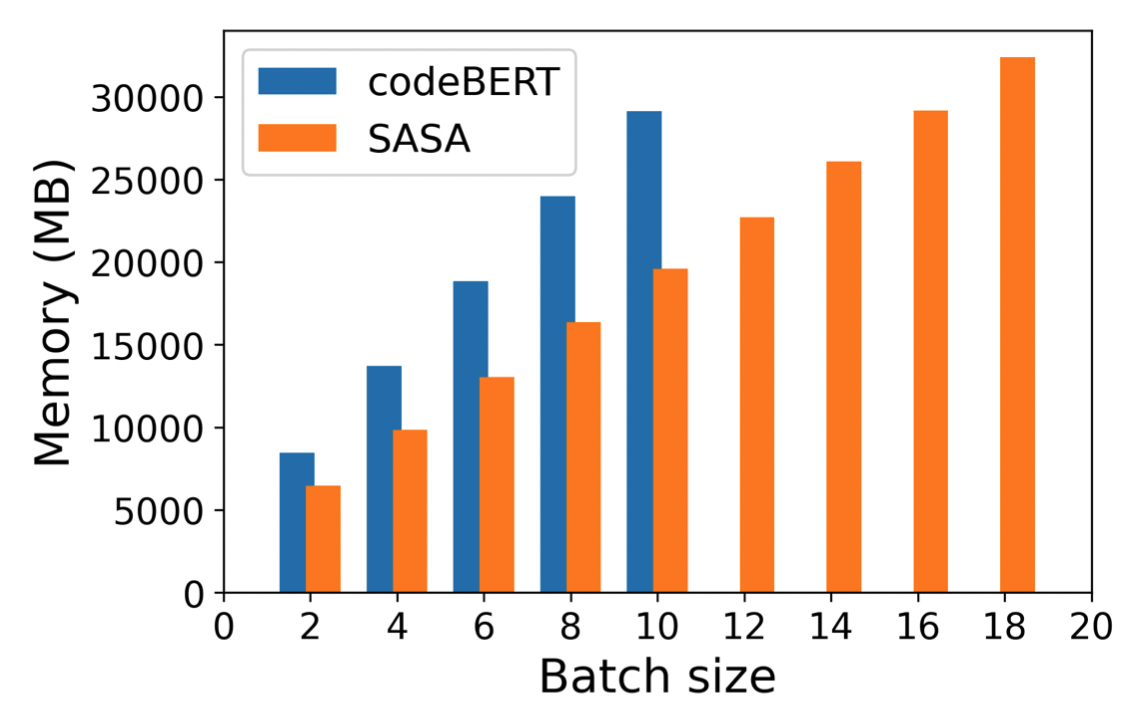
SASA作为一个sparse attention的模块,可以迁移到基于Transformer的其他预训练模型上,用于处理长序列的自然语言处理任务,后续将集成到开源框架EasyNLP(https://github.com/alibaba/EasyNLP)中,贡献给开源社区。
论文链接:
https://arxiv.org/abs/2205.13730
Recommend
-
27
对于目前基于神经网络的序列模型,很重要的一个任务就是从序列模型中采样。 比如解码时我们希望能产生多个不一样的结果,而传统的解码算法只能产生相似的结果。 又比如训练时使用基于强化学习或者最小风...
-
28
主课的最后一讲,我们来看看非常出名的 Seq2Seq 模型和注意力机制,这些都是 RNN 得以在机器翻译、语音识别、自然语言处理领域大放异彩的重要原因。 更新历史 2019.10.25: 完成初稿 Seq2Seq 结构...
-
22
作者 | Miracle8070 研究 | 时空序列预测与数据挖掘 出品 | AI蜗牛车 ...
-
6
论文题目:Attention Is All You Need论文链接:https://arxiv.org/pdf/1706.03762.pdf 本文的代码主要参考wmathor的
-
7
怪盗基德的滑翔翼 题目链接:怪盗基德的滑翔翼 分析:这道题还是比较简单的,我们只需要求一遍最长上升子序列(倒着看就是怪盗基德从最后的一个点滑翔到最前面的一个点),再求一遍...
-
4
序列标注之NER、CWS经典模型HMM实现序列标注之NER经典模型HMM实现 在文章NLP任务:序列标注提及很多解决NER和中文分词任务的方案,唯独经典的HMM没有详细展开。 三类常见的词法...
-
6
WWW 2022 弯道超车:基于纯MLP架构的序列推荐模型 AINLP...
-
2
作者 | 郑智献行为序列模型相对于传统机器学习的主要优势在于不依赖行为画像特征,无需强专家经验挖掘高效特征来提升模型性能,缩短了特征工程的周期,能快速响应黑产攻击。黑产通过刷接口、群控、真人众包等作弊手段在关注、点赞、评论等核心场景进行攻击。...
-
1
行为序列模型相对于传统机器学习的主要优势在于不依赖行为画像特征,无需强专家经验挖掘高效特征来提升模型性能,缩短了特征工程的周期,能快速响应黑产攻击。 黑产通过刷接口、群控、真人众包等作弊手段在关注、点赞、评论等核心场景进行攻击。不同作弊方式...
-
6
基于序列标注模型的主动学习实践 2022年12月07日 02:15 · 阅读 158 ...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK