

blog :: Brent -> [String]
source link: https://byorgey.wordpress.com/2023/01/01/competitive-programming-in-haskell-better-binary-search/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Competitive programming in Haskell: better binary search
Binary search is a workhorse of competitive programming. There are occasional easy problems where binary search is the solution in and of itself; more often, it’s used as a primitive building block of more complex algorithms. It is often presented as a way to find the index of something in a sorted array in 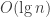
Arrays.binarySearch in Java, the bisect library in Python, or the binary_search function in C++). However, the idea of binary search is more general than searching in a sorted array; we’re doing binary search any time we repeatedly halve a search interval. For example, we can use it to find the smallest or largest number with a given property, or to find an optimal, “just right” measurement that is neither too small nor too big.
Generic binary search with first-class functions, take 1
A language with easy access to first-class functions provides a great opportunity to generalize binary search properly. For example, here’s a version of binary search that has lived in my competitive programming solution template for a long time:
-- Discrete binary search. Find the smallest integer in [lo,hi] such
-- that monotone predicate p holds.
binarySearchD :: Int -> Int -> (Int -> Bool) -> Int
binarySearchD lo hi p
| lo == hi = lo
| p mid = binarySearchD lo mid p
| otherwise = binarySearchD (mid+1) hi p
where
mid = (lo + hi) `div` 2The key generalization is that it takes a predicate of type Int -> Bool as an argument. Note that in order for binary search to work, the predicate p must be monotonic. This means, intuitively, that p starts out False, and once it switches to True it never goes back. (Formally, p being monotonic means that for all x and y, if x <= y then p x <= p y, where False <= True). This is how we can tell if we’re “too low” or “too high”: we’re “too low” when p is False and “too high” when it is True.
This is definitely an improvement over array-specific versions of binary search. We can still use it to search in an array by providing a predicate that does an array lookup, but we can use it for other things as well.
I should note at this point that there is a very nice binary-search package published on Hackage, which I definitely recommend if you need binary search in some kind of project. However, for the purposes of competitive programming, we can’t rely on that package being available, and we’d also like something a bit simpler, so we don’t have to read the documentation every time we want to use it.
…can we do better?
So my binarySearchD function works fine as far as it goes, and I have used it regularly, but there are still several things about it that always annoyed me:
-
What if we want a slight variation, such as the largest integer such that something holds? Or the last integer where the predicate doesn’t hold? etc.? It is possible to use
binarySearchDin these situations, but I find it tricky and error-prone to figure out how. And when I’m reaching for some function as a building block of a bigger algorithm I definitely don’t want to waste time and brainpower having to think carefully about small details like this. -
Getting the implementation right in the first place was kind of tricky. Should we use
mid+1?mid-1? Should we think in terms of a closed interval[lo,hi], or a half-open interval[lo,hi), or…? How can we convince ourselves our implementation is completely correct, and won’t get stuck in infinite recursion? -
What if we want to do binary search over a continuous domain, like
Double? We have to make a completely separate function, for example, like this:
-- Continuous binary search. Given a tolerance eps, an interval
-- [a,b], a continuous, monotonically increasing function f, and a
-- target value tgt, find c ∈ [a,b] such that f(c) = tgt.
binarySearch :: (Fractional t, Ord t, Ord a) => t -> t -> t -> (t -> a) -> a -> t
binarySearch eps a b f tgt = go a b
where
go lo hi
| hi-lo < eps = mid
| f mid < tgt = go mid hi
| otherwise = go lo mid
where
mid = (lo + hi)/2(Actually, I’m not sure why I wrote that version in terms of finding a “target” value. In practice I suppose continuous binary search often comes up that way, but looking at it now it seems less general. In any case, we’re going to throw this function away very shortly so it doesn’t really matter!)
A better binary search
Recently I came across a lovely article, Binary Search a Little Simpler & More Generic by Jules Jacobs. Jules explains a really elegant API for binary search that is so much better than anything I’d seen before, and solves all the above issues! I immediately went to implement it in Haskell, and I want to share it with you. As I’ve reflected on Jules’s presentation, I have identified three key ideas:
-
Rather than looking for some index with a certain property, we’re really looking for the place where
pswitches fromFalsetoTrue. That actually happens in between two indices… so let’s return the pair of indices bracketing the change, rather than just a single index! This means we get both the last index that does not have propertypand the first one that does, and we can use whichever one we want.This is a simple change, but in my experience, it helps a lot to reduce the cognitive load. Previously, if I wanted something like “the last index that does not have property
p” I’d have to think hard about what the index I get out of the search represents, and figure out that I needed to subtract one. Now I only have to think “OK, I want the thing right before the predicate changes fromFalsetoTrue, so I can project it out withfst”. -
The second important idea is that we’re going to insist that
pswitches fromFalsetoTrue, not at most once, but exactly once. (If necessary, we can add special “virtual”-∞and/or+∞indices such thatp (-∞) = Falseandp (+∞) = True.) Then as we narrow down our current search interval[l, r], we will maintain the invariant thatp l = Falseandp r = True.This invariant makes everything so much cleaner, and it also ties in with the first important idea of returning a pair instead of a single index. Previously I always thought of binary search in terms of searching for a specific index, but that makes the semantics of the interval tricky. For example, do we maintain the invariant that the index we’re looking for is somewhere in the closed interval
[l,r]? Somewhere in the half-open interval[l,r)? …? But I find it so much more elegant and natural to say “lalways stays in theFalsepart, andralways stays in theTruepart, and we just slide them closer until we find the exact dividing line betweenFalseandTrue.”I will note that there are a couple tradeoffs: first of all, our search function of course takes starting values for
landras inputs, and it will now have as a prerequisite thatp l = Falseandp r = True, so we have to think a little harder when calling it. We also have to work a little harder to figure out when e.g. a value we’re looking for was not found at all. Typically, if we use some sort of initial special+∞value forr, if the returnedrvalue is still+∞it means nothing at all was found that made the predicateTrue. -
The final important idea is to abstract out a function
midto compute a potential next index to look at, given the current interval. We’ll insist that whenmid l rreturns a value, it must be strictly in betweenlandr(there’s no point in returninglorrbecause we already knowp l = Falseandp r = True), and we’ll stop when it returnsNothing. This lets us cleanly separate out the logic of the recursion and keeping track of the current search interval from the details of the arithmetic needed for each step. In particular, it will allow us to unify binary search over both integral and floating-point domains.
Here’s the final form of our search function. Unlike, say, binarySearchD, it pretty much writes itself at this point:
search :: (a -> a -> Maybe a) -> (a -> Bool) -> a -> a -> (a,a)
search mid p = go
where
go l r = case mid l r of
Nothing -> (l,r)
Just m
| p m -> go l m
| otherwise -> go m rWe check our mid function to tell us what to look at next. If it returns Nothing, we stop and return the pair of the current (l,r). If it returns a “midpoint” m then we test the predicate on m and recurse. No tricky +1’s or -1’s to think about; given our invariant regarding l and r, it’s obvious which one we should replace with m depending on the outcome of the predicate, and we can’t get stuck in an infinite loop since m is always strictly between l and r.
(As an aside, I love that this is polymorphic in a with no class constraints! That’s another hint that this is really quite general. The class constraints will come with particular mid functions.)
So what about those mid functions? Here’s one for doing binary search over integers:
binary :: Integral a => a -> a -> Maybe a
binary l r
| r - l > 1 = Just ((l+r) `div` 2)
| otherwise = NothingPretty straightforward! We stop when l and r are exactly one apart; otherwise we return their midpoint (you should convince yourself that (l+r) `div` 2 is always strictly in between l and r when r - l > 1).
For example, we can use this to take an integer square root:
λ> search binary (\x -> x^2 >= 150) 0 100
(12,13)This tells us that 12 is the biggest integer whose square is less than 150, and 13 is the smallest integer whose square is greater.
But we needn’t limit ourselves to integers; as hinted previously, we can also do binary search over Fractional domains:
continuous :: (Fractional a, Ord a) => a -> a -> a -> Maybe a
continuous eps l r
| r - l > eps = Just ((l+r) / 2)
| otherwise = NothingGiven an eps value, we stop when r - l <= eps, and otherwise return their midpoint. For example, we can use this to find the square root of 150 to 6 decimal places:
λ> search (continuous 1e-6) (\x -> x^2 >= 150) 0 100
(12.247448414564133,12.247449159622192)We can even write some functions to do linear search! Why might we want to do that, you ask? Well, with some care, these can be used even with non-monotonic predicates, to find the first or last place the predicate switches from False to True (though using something like find or findIndex is typically easier than using search fwd).
fwd :: (Num a, Ord a) => a -> a -> Maybe a
fwd l r
| r - l > 1 = Just (l+1)
| otherwise = Nothing
bwd :: (Num a, Ord a) => a -> a -> Maybe a
bwd l r
| r - l > 1 = Just (r-1)
| otherwise = NothingI don’t have any great examples of using these off the top of my head, but we might as well include them.
But there’s more: we can also do exact binary search on the bit representations of floating-point numbers! That is, we do binary search as if the bit representations of l and r were unsigned integers. This is possibly more efficient than “continuous” binary search, and lets us find the two precisely adjacent floating-point numbers where our predicate switches from False to True.
binaryFloat :: Double -> Double -> Maybe Double
binaryFloat l r = decode <$> binary (encode l) (encode r)
where
encode :: Double -> Word64
encode = unsafeCoerce
decode :: Word64 -> Double
decode = unsafeCoerce
For example, we can find the closest possible floating-point approximation to the square root of 150:
λ> search binaryFloat (\x -> x^2 >= 150) 0 100
(12.247448713915889,12.24744871391589)
λ> sqrt 150
12.24744871391589This honestly seems like black magic to me, and I don’t know enough about floating-point representation to have a good idea of how this works and what the caveats might be, but it’s worked for all the examples I’ve tried. It even works when l is negative and r is positive (it seems like in that case the bit representation of l would correspond to a larger unsigned integer than r, but somehow it all works anyway!).
λ> search binaryFloat (\x -> x^2 >= 150) (-100) 100
(12.247448713915889,12.24744871391589)I’ve added the code from this post to my comprog-hs repository on GitHub. The source for this blog post itself is available on hub.darcs.net.
Challenges
And here are some problems for you to solve! I’ll discuss some of them in an upcoming post.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK