

Should small Rust structs be passed by-copy or by-borrow?
source link: https://www.forrestthewoods.com/blog/should-small-rust-structs-be-passed-by-copy-or-by-borrow/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Like many good stories, this one started with a simple question. Should small Rust structs be passed by-copy or by-borrow? For example:
struct Vector3 {
x: f32,
y: f32,
z: f32
}
fn dot_product_by_copy(a: Vector3, b: Vector3) -> float {
a.x*b.x + a.y*b.y + a.z*b.z
}
fn dot_product_by_borrow(a: &Vector3, b: &Vector3) -> float {
a.x*b.x + a.y*b.y + a.z*b.z
}
This simple question sent me on a benchmarking odyssey with some surprising twists and discoveries.
Why It Matters
The answer to this question matters for two reasons — performance and ergonomics.
Performance
Passing by-copy should mean we copy 12-bytes per Vector3. Passing by-borrow should pass an 8-byte pointer per Vector3 (on 64-bit). That's close enough to maybe not matter.
But if we change f32 to f64 now it's 8-bytes (by-borrow) versus 24-bytes (by-copy). For code that uses a Vector4 of f64 we're suddenly talking about 8-bytes versus 32-bytes.
Ergonomics
In C++ I know exactly how I'd write this.
struct Vector3 {
float x;
float y;
float z;
};
float dot_product(Vector3 const& a, Vector3 const& b) {
return a.x*b.x + a.y*b.y + a.z*b.z
}
Easy peasy. Pass by const-reference and call it day.
The problem with Rust is ergonomics. When passing by-copy you can combine mathematical operations cleanly and simply.
fn do_math(p1: Vector3, p2: Vector3, d1: Vector3, d2: Vector3, s: f32, t: f32) -> f32 {
let a = p1 + s*d1;
let b = p2 + s*d2;
dot_product(b - a, b - a)
}
However when using borrow semantics it turns into this ugly mess:
fn do_math(p1: &Vector3, p2: &Vector3, d1: &Vector3, d2: &Vector3, s: f32, t: f32) -> f32 {
let a = p1 + &(&d1*s);
let b = p2 + &(&d2*t);
let result = dot_product(&(&b - &a), &(&b - &a));
}
Blech! Having to explicitly borrow temporary values is super gross. 🤮
Building a Benchmark
So, should Rust pass small structs, like Vector3, by-copy or by-borrow?
None of Twitter, Reddit, or StackOverflow had a good answer. I checked popular crates like nalgebra (by-borrow) and cgmath (by-value) and found both ways are common.
I don't like the ergonomics of by-borrow. But what about performance? If by-copy is fast then none of this matters. So I did the only thing that seemed reasonable. I built a benchmark!
I wanted some to test something slightly more than raw operator performance. It's still a silly synthetic benchmark that is not representative of a real application. But it's a good starting point. Here's roughly what I came up with.
let num_shapes = 4000;
for cycle in 0...5 {
let (spheres, capsules, segments, triangles) = generate_shapes(num_shapes);
for run in 0..5 {
for (a,b) in collision_pairs {
test_by_copy(a,b)
}
for pair in collision_pairs {
test_by_borrow(&a, &b)
}
}
}
I randomly generate 4000 spheres, capsules, segments, and triangles. Then I perform a simple overlap test for SphereSphere, SphereCapsule, CapsuleCapsule, and SegmentTriangle for all pairs. These tests are run by-copy and by-borrow. Only time spent inside test_by_copy and test_by_borrow is counted.
Each full benchmark performs 3.2 billion comparisons and finds ~220 million overlapping pairs. Here are some results running single-threaded on my beefy i7-8700k Windows desktop. All times are in milliseconds.
Rust
f32 by-copy: 7,109
f32 by-borrow: 7,172 (0.88% slower)
f64 by-copy: 9,642
f64 by-borrow: 9,601 (0.42% faster)
Well this is mildly surprising. Passing by-copy or by-borrow barely makes a difference! These results are quite consistent. Although a difference of less than 1% is well within the margin of error.
Is this the answer to our question? Should we pass by-copy and call it a day? I'm not ready to say.
Down the C++ Rabbit Hole
After my initial Rust benchmarks I decided to port my test suite to C++. The code is similar, but not identical. Both Rust and C++ implementations are what I would consider idiomatic in their respective languages.
C++
f32 by-copy: 14,526
f32 by-borrow: 13,880 (4.5% faster)
f64 by-copy: 13,439
f64 by-borrow: 13,942 (3.8% slower)
Wait, what?! At least two things are super weird here.
doubleby-value is faster thanfloatby-value- C++
floatis twice as slow as Rustf32
Inlining
Clearly something unexpected is going on. Using Visual Studio 2019 I grabbed a pair of quick CPU profiles.
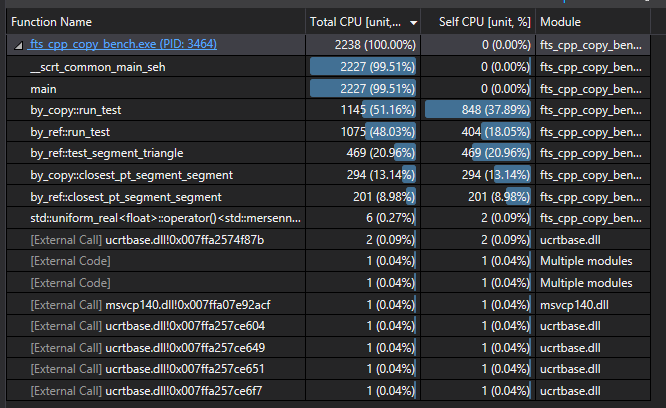
C++ Profile
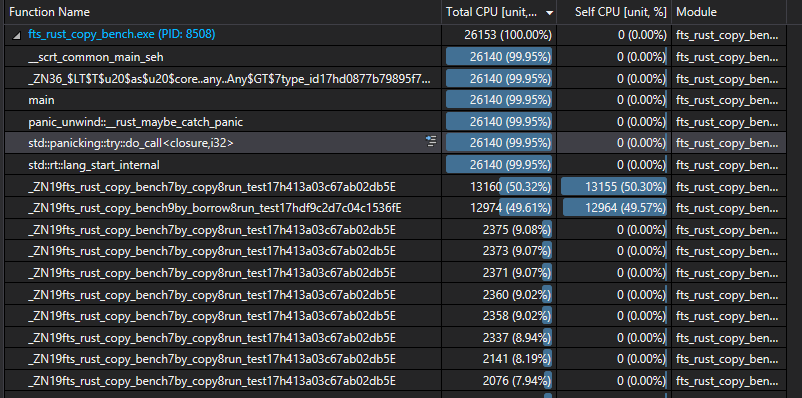
Rust Profile
Ah hah! Rust appears to be inlining almost everything. Let's copy Rust and throw a quick __forceinline infront of everything in our C++ impl.
C++ w/ inlining
f32 by-copy: 12,688
f32 by-borrow: 12,108 (4.5% faster)
f64 by-copy: 11,860
f64 by-borrow: 11,967 (0.9% slower)
Inlining C++ provides a decent ~12% boost. But double is still faster than float. And C++ is still way slower than Rust.
Aliasing
I would consider my C++ and Rust implementations to both be idiomatic. However they are different! C++ takes out parameters by reference while Rust returns a tuple. This is because Rust tuples are delightful to use and C++ tuples are a monstrosity. But I digress.
// Rust
fn closest_pt_segment_segment(p1: Vector3, q1: Vector3, p2: Vector3, q2: Vector3)
-> (T, T, T, Vector3, Vector3)
{
// Do math
}
// C++
float closest_pt_segment_segment(
Vector3 p1, Vector3 q1, Vector3 p2, Vector3 q2,
float& s, float& t, Vector3& c1, Vector3& c2)
{
// Do math
}
This subtle difference could cause a huge impact on performance. The C++ version compiler can't be sure the out parameters aren't aliased. Which may limit its ability to optimize. Meanwhile Rust uses and returns local variables which are known to be non-aliased.
Interestingly, fixing the aliasing above doesn't make a difference! With inlining the compiler handles it already. Much to my surprise, what C++ does not handle well is the following:
void run_test(
vector<TSphere> const& _spheres,
vector<TCapsule> const& _capsules,
vector<TSegment> const& _segments,
vector<TTriangle> const& _triangles,
int64_t& num_overlaps,
int64_t& milliseconds)
{
// perform overlaps
}
Changing run_test to return std::tuple<int64_t, int64_t> provides a small but noticeable improvement.
C++ w/ inlining, tuples
f32 by-copy: 12,863
f32 by-borrow: 11,555 (10.17% faster)
f64 by-copy: 11,832
f64 by-borrow: 11,524 (2.60% faster)
Compile Flags
At this point both C++ and Rust are compiling with default options. Visual Studio exposes a ton of flags. I tried tweaking a bunch of flags to improve performance.
- Favor fast code (/Ot)
- Disable exceptions
- Advanced Vector Extensions 2 (/arch:AVX2)
- Floating Point Mode: Fast (/fp:fast)
- Enable Floating Point Exceptions: No (/fp:except-)
- Disable security check /GS-
- Control flow guard: No
The only flags that made a real difference were "disable exceptions" and AVX2. Each about 10%. I decided to leave off AVX2 in an attempt to equal Rust.
C++ w/ inlining, tuples, no C++ exceptions
f32 by-copy: 11,651
f32 by-borrow: 10,455 (10.27% faster)
f64 by-copy: 10,866
f64 by-borrow: 10,467 (3.67% faster)
We've made three C++ optimizations but our two mysteries remain. Why is double faster than float? And why is C++ still so much slower than Rust?
Going Deeper
I tried looking at the disassembly in Godbolt. There's obviously differences. But I'm not smart enough to quantify them.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK