
8

什么是Rabbitmq消息队列? (安装Rabbitmq,通过Rabbitmq实现RPC全面了解,从入门到精通)...
source link: https://www.cnblogs.com/My-IronMan/p/17015001.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Rabbitmq
一: 消息队列介绍
消息队列就是基础数据结构中的 "先进先出" 的一种数据机构。想一下,生活中买东西需要排队,先排队的人先买消费,就是典型的 "先进先出"。

# 扩展
redis: 可以作为简单的消息队列
celery: 本事就是基于消息队列进行的封装。
2.MQ解决了什么问题
MQ是一直存在,不过随着微服务架构的流行,成了解决微服务和微服务之间通信的常用工具。
# 扩展
1.两个服务之间调用的方式:
1.restful七层协议oss(http协议)
2.rpc tcp socket层(远程过程调用)
2.不管是使用restful还是rpc,都涉及到使用同步还是异步:
1.异步: client使用rpc和server交互,client使用异步,不管有没有执行成功,就不停的异步的提交数据,数据在server消息队列排着队,等待着消费。
1.应用的解耦
1.以电商应用为例,应用中有订单系统,库存系统,物流系统,支付系统。用户创建订单后,如果耦合调用库存系统,物流系统,支付系统,任何一个子系统出现了故障,都会造成下单操作异常。
2.当转变成基于队列的方式后,系统间调用的问题会减少很多,比如物流系统因为发生故障,需要几分钟来修复。在这几分钟的时间里,物流系统要处理的内存被缓存在消息队列中,用户的下单操作可以正常完成。当物流系统恢复后,继续处理订单信息即可,订单用户感受不到物流系统的故障。提升系统的可用性。
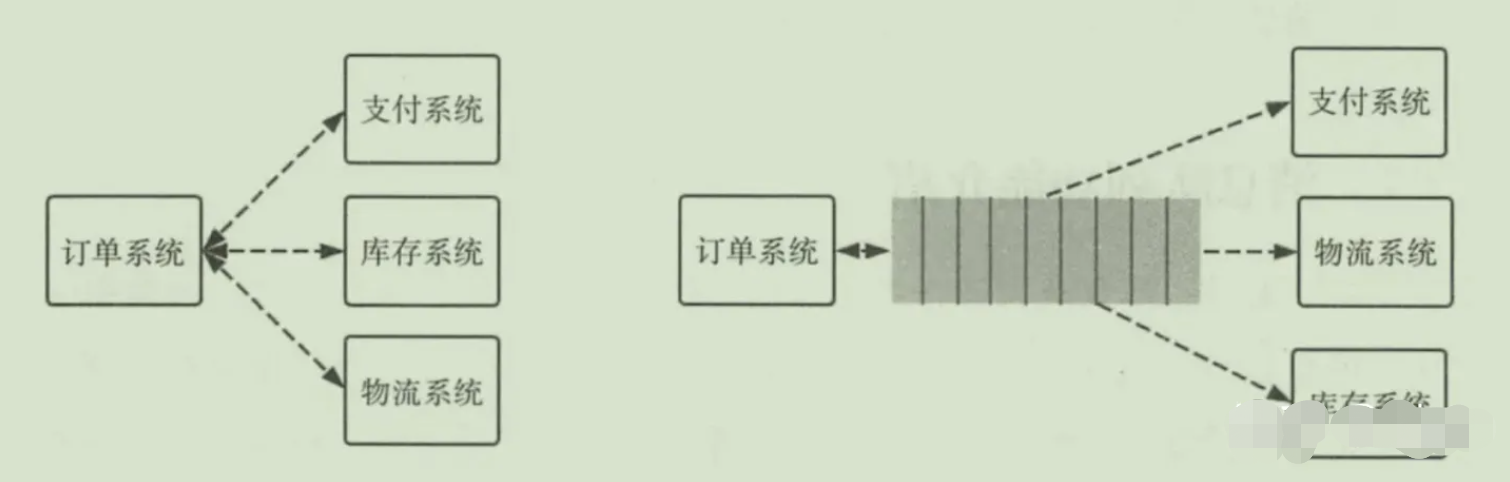
2.流量削峰
1.举个列子,如果订单系统最多能处理一万次订单,这个处理能力应付正常时段的下单时绰绰有余,正常时段我们下单一秒后就能返回结果。但是在高峰期,如果有两万次下单操作系统是处理不了的,只能限制订单超过一万后不允许用户下单。
2.使用消息队列做缓存,我们可以取消这个限制,把一秒内下的订单分散成一段时间来处理,这时有些用户可能在下单十几秒后才能收到下单成功的操作,但是比不能下单的体验要好。
# 结:
1.通常下比如有两万订单,这时我们server肯定消费不过来,我们将两万丢到消息队列中,进行消费即可。 --- 就叫流量消峰 = 如: 双十一,消息队列 多消费
3.消息分发(发布订阅: 观察者模式)
多个服务对数据感兴趣,只需要监听同一类消息即可处理。

列如A产生数据,B对数据感兴趣。如果没有消息队列A每次处理完需要调用一下B服务。过了一段时间C对数据也感兴趣,A就需要改代码,调用B服务,调用C服务。只要有服务需要,A服务都要改动代码。很不方便。
xxxxxxxxxx 有了消息队列后,A只管发送一次消息,B对消息感兴趣,只需要监听消息。C感兴趣,C也去监听消息。A服务作为基础服务完全不需要有改动。
4.异步消息(celery就是对消息队列的封装)
xxxxxxxxxx 有些服务间调用是异步的: 1.例如A调用B,B需要花费很长时间执行,但是A需要知道B什么时候可以执行完,以前一般有两种方式,A过了一段时间去调用B的查询api是否完成。 2.或者A提供一个callback api,B执行完之后调用api通知A服务。这两种方式都不是很优雅。python
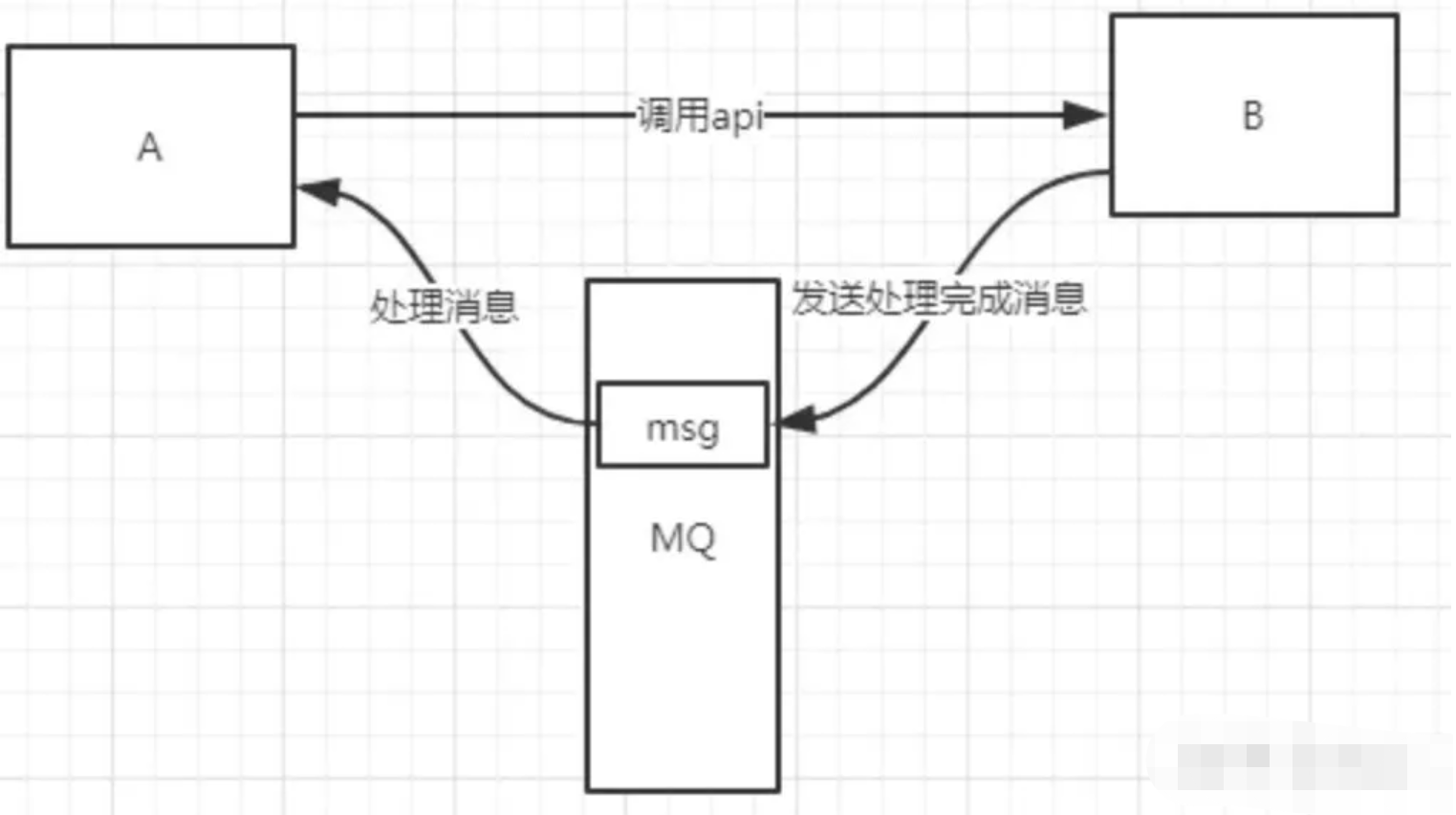
1.使用消息总线,可以很方便解决这个问题,A调用B服务后,只需要监听B处理完成的消息,当B处理完成后,会发送一条消息给MQ,MQ会将此消息转发给A服务。
2.这样A服务既不用循环调用B的查询api,也不用提供callback api。同样B服务也不用做这些操作。A服务还能及时的得到异步处理成功的消息。
3.常见消息队列及比较
xxxxxxxxxx RabbitMQ: 支持持久化,断电后,重启,数据是不会丢的。 1. 吞吐量小: 几百万都是没问题的,消息确认: 我告诉你,我消费完了,你在删 2.应用场景: 订单,对消息可靠性有要求,就用它 Kafka: 吞吐量高,注重高吞吐量,不注重消息的可靠性 1.你拿走就没了,消费过程崩了,就没了。 2.应用场景,数据量特别大。 # 结论: 1.Kafka在于分布式架构,RabbitMQ基于AMQP协议来实现,RocketMQ/思路来源于Kafka,改成了主从结构,在事务性可靠性方面做了优化。 2.广泛来说,电商,金融等对事物性要求很高的,可以考虑RabbitMQ,对性能要求或吞吐量高的可考虑Kafka。python
二:Rabbitmq安装
- 官网:https://www.rabbitmq.com/getstarted.html
- dockerhub下载指定的rabbitmq:management的RabbitMQ

1.服务端原生安装
1 原生安装
-安装扩展epel源
-yum -y install erlang
-yum -y install rabbitmq-server
# 查询是否安装
rpm -qa rabbitmq-server
-systemctl start rabbitmq-server
# 以上也有web管理页面,只不过需要配置文件配置。
# 第一种方式客户端连接服务端,可以不用配置用户和密码,只需要ip连接。第二种方式则需要配置用户名和密码。
2.服务端docker拉取
2 docker拉取
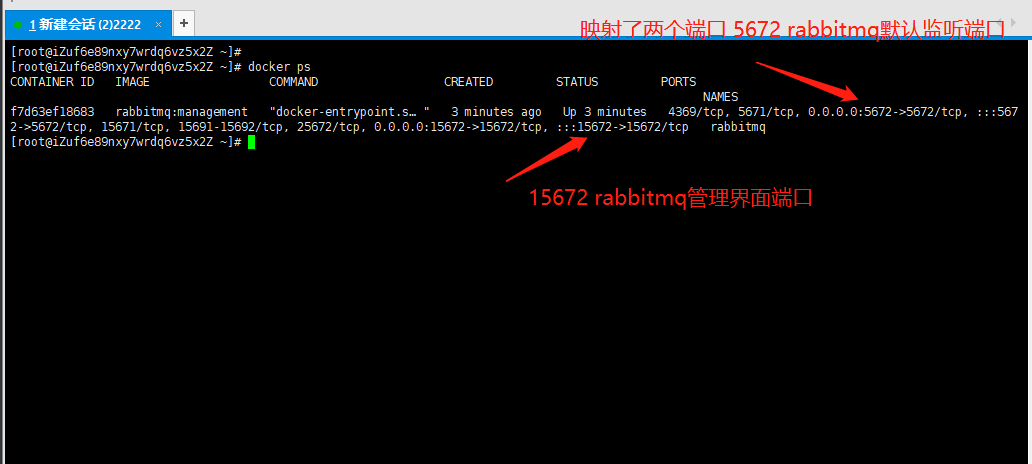
-docker pull rabbitmq:management(自动开启了web管理界面)
-docker run -di --name rabbitmq -e RABBITMQ_DEFAULT_USER=admin -e RABBITMQ_DEFAULT_PASS=admin -p 15672:15672 -p 5672:5672 rabbitmq:management # 直接 run 如果没有rabbitmq就会自动拉
"""
docker run -di --name: 指定rabbitmq
-e: 环境变量
-e RABBITMQ_DEFAULT_USER=admin:用户名
-e RABBITMQ_DEFAULT_PASS=admin:密码
-p 15672:15672: rabbitmq web管理界面端口
-p 5672:5672: rabbitmq默认的监听端口
"""

docker ps
http://47.101.159.222:15672/
3.Rabbitmq可视化界面创建用户(设置用户和密码)
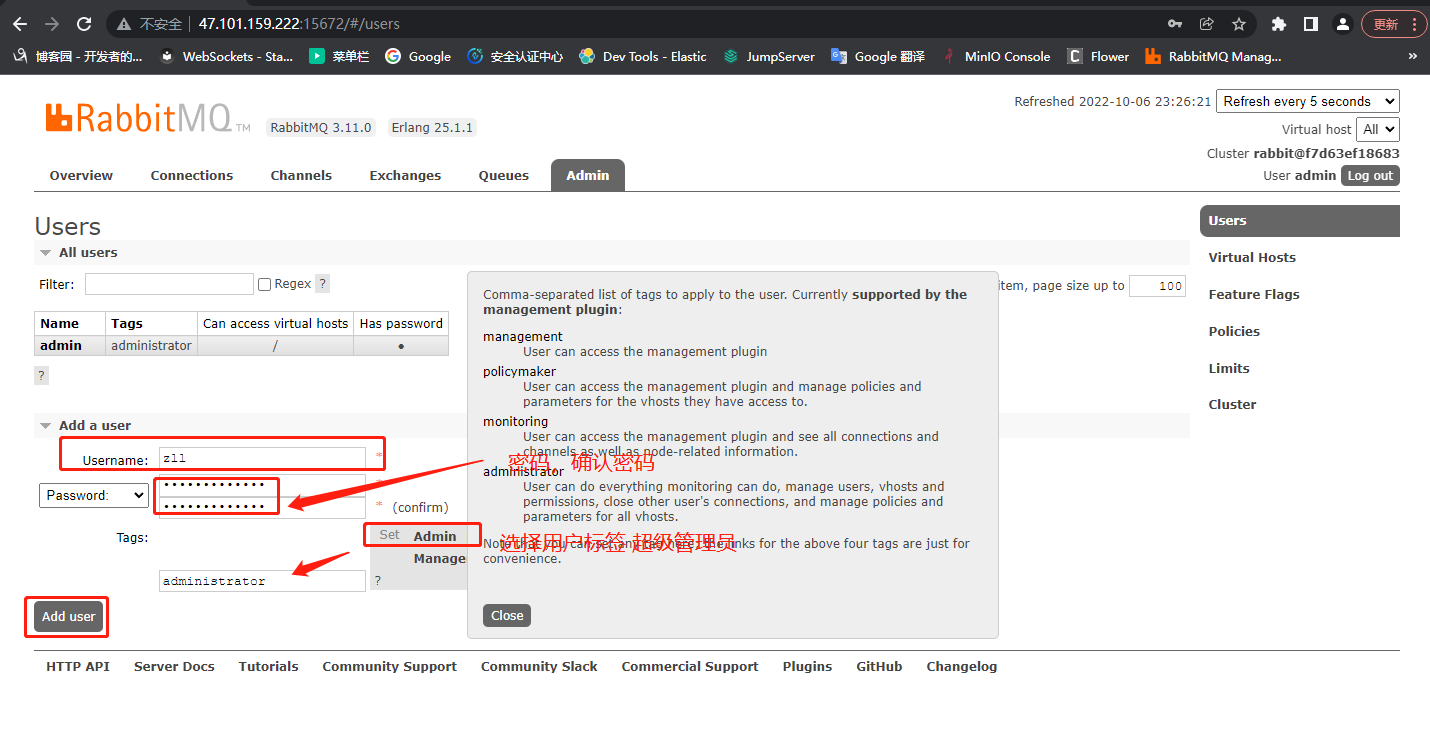
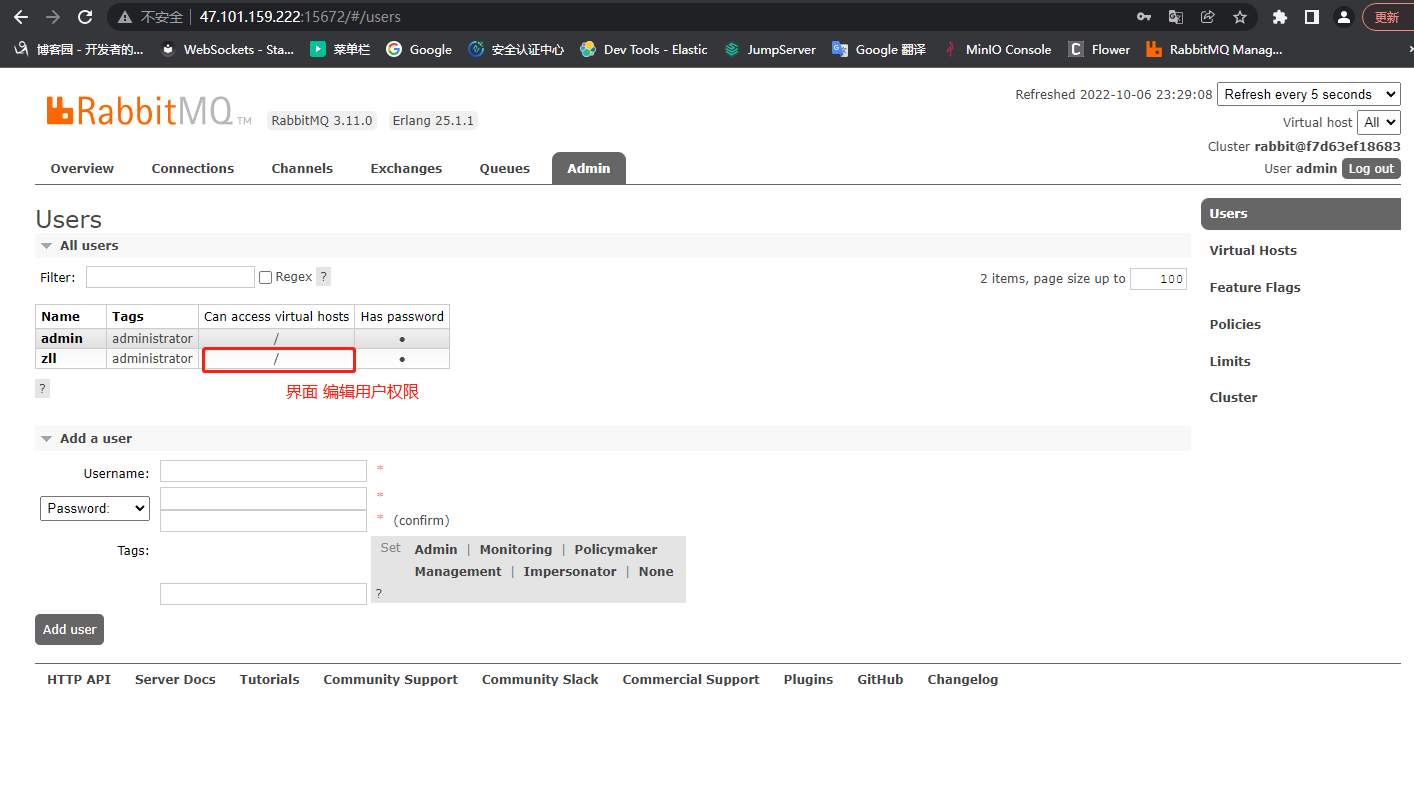
4.命令创建Rabbitmq用户(设置用户和密码)
4 创建用户
rabbitmqctl add_user lqz 123
5 分配权限
# 设置用户为admin角色
rabbitmqctl set_user_tags lqz administrator
# 设置权限
rabbitmqctl set_permissions -p "/" lqz ".*" ".*" ".*"
# rabbitmqctl set_permissions -p "/" 用户名 ".*" ".*" ".*"
三:客户端安装
pip3 install pika
四: 基本使用(生产者消费者模型)
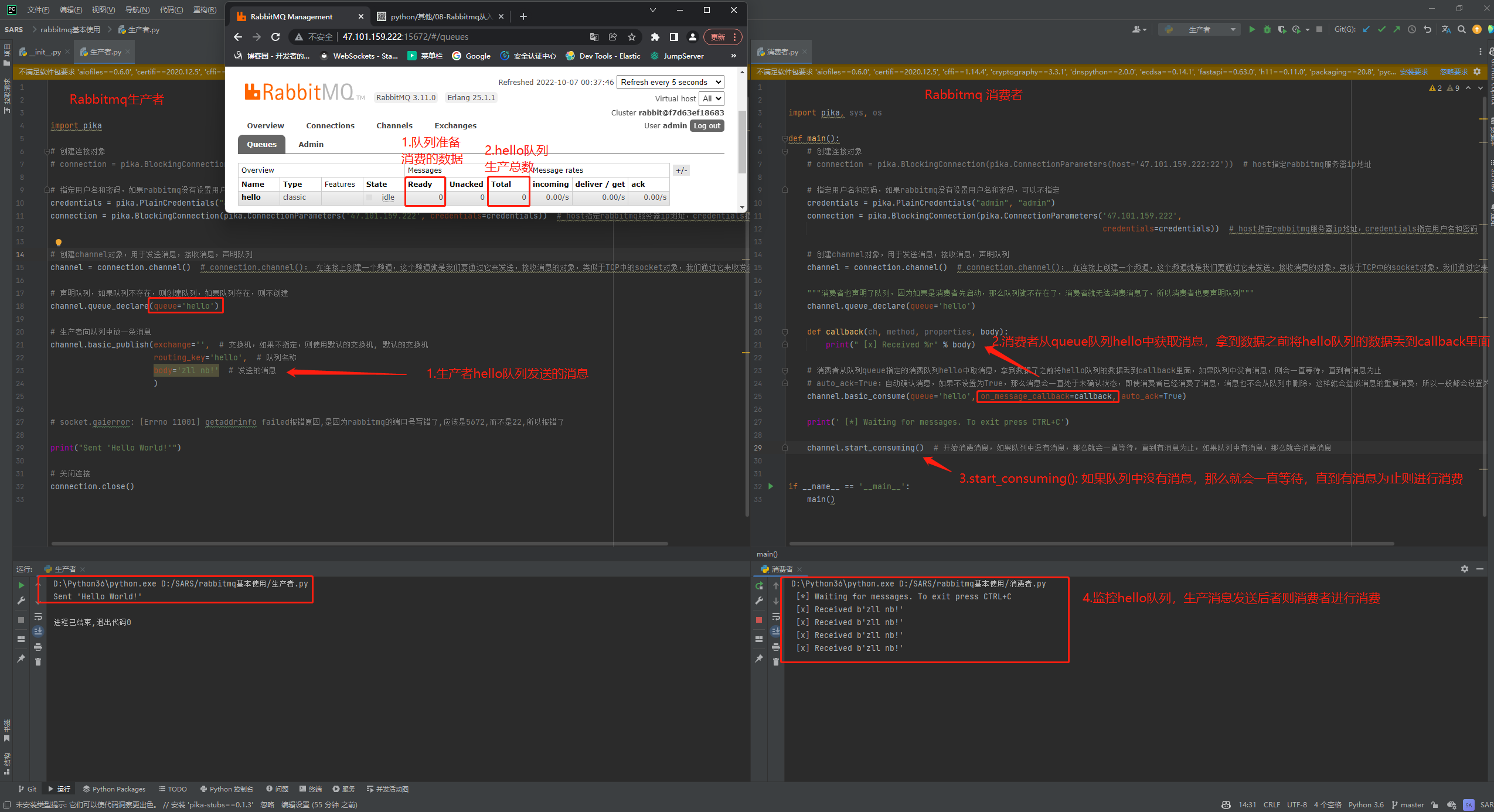
对于RabbitMQ来说,生产和消费不再针对内存里的一个Queue对象,而是某台服务器上的RabbitMQ Server实现的消息队列。
import pika
# 创建连接对象
# connection = pika.BlockingConnection(pika.ConnectionParameters(host='47.101.159.222:22')) # host指定rabbitmq服务器ip地址
# 指定用户名和密码,如果rabbitmq没有设置用户名和密码,可以不指定
credentials = pika.PlainCredentials("admin", "admin")
connection = pika.BlockingConnection(pika.ConnectionParameters('47.101.159.222', credentials=credentials)) # host指定rabbitmq服务器ip地址,credentials指定用户名和密码
# 创建channel对象,用于发送消息,接收消息,声明队列
channel = connection.channel() # connection.channel(): 在连接上创建一个频道,这个频道就是我们要通过它来发送,接收消息的对象,类似于TCP中的socket对象,我们通过它来收发消息,声明队列
# 声明队列,如果队列不存在,则创建队列,如果队列存在,则不创建
channel.queue_declare(queue='datalog')
# 生产者向队列中放一条消息
channel.basic_publish(exchange='', # 交换机,如果不指定,则使用默认的交换机, 默认的交换机
routing_key='datalog', # 队列名称
body='zll nb!' # 发送的消息
)
print("Sent 'Hello World!'")
# 关闭连接
connection.close()
import pika, sys, os
def main():
# 创建连接对象
# connection = pika.BlockingConnection(pika.ConnectionParameters(host='47.101.159.222:22')) # host指定rabbitmq服务器ip地址
# 指定用户名和密码,如果rabbitmq没有设置用户名和密码,可以不指定
credentials = pika.PlainCredentials("admin", "admin")
connection = pika.BlockingConnection(pika.ConnectionParameters('47.101.159.222',
credentials=credentials)) # host指定rabbitmq服务器ip地址,credentials指定用户名和密码
# 创建channel对象,用于发送消息,接收消息,声明队列
channel = connection.channel() # connection.channel(): 在连接上创建一个频道,这个频道就是我们要通过它来发送,接收消息的对象,类似于TCP中的socket对象,我们通过它来收发消息,声明队列
"""消费者也声明了队列,因为如果是消费者先启动,那么队列就不存在了,消费者就无法消费消息了,所以消费者也要声明队列"""
channel.queue_declare(queue='datalog')
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
# 消费者从队列queue指定的消费队列hello中取消息,拿到数据了之前将hello队列的数据丢到callback里面,如果队列中没有消息,则会一直等待,直到有消息为止
# auto_ack=True:自动确认消息,如果不设置为True,那么消息会一直处于未确认状态,即使消费者已经消费了消息,消息也不会从队列中删除,这样就会造成消息的重复消费,所以一般都会设置为True
# auto_ack=true: 队列接收到既直接确认,就会删除队列中的消息,不会管后面数据会不会消费完。
channel.basic_consume(queue='datalog', on_message_callback=callback, auto_ack=True) # 默认为false,不自动确认消息,需要手动确认
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming() # 开始消费消息,如果队列中没有消息,那么就会一直等待,直到有消息为止,如果队列中有消息,那么就会消费消息
if __name__ == '__main__':
main()
五: 消息确认机制 (消息安全之ack)
# auto_ack: 自动确认消息(队列接收到就会确认消费,会丢失数据的可能性) 默认为false
auto_ack=true: 队列接收到既直接确认,就会删除队列中的消息,不会管后面数据会不会消费完。
auto_ack=false: 设置为false的情况,那么消息会一直处于未确认状态,即使消费者已经消费了消息,消息也不会从队列中删除,这样就会造成消息的重复消费
# ch.basic_ack: 消费完后,自动确认消费(可靠性,保证数据都完整的消费): 常用推荐
ch.basic_ack(delivery_tag=method.delivery_tag): 真正的将消息消费完了后,再发确认,就会删除掉队列中的消息。
import pika
# 创建连接对象
# connection = pika.BlockingConnection(pika.ConnectionParameters(host='47.101.159.222:22')) # host指定rabbitmq服务器ip地址
# 指定用户名和密码,如果rabbitmq没有设置用户名和密码,可以不指定
credentials = pika.PlainCredentials("admin", "admin")
connection = pika.BlockingConnection(pika.ConnectionParameters('47.101.159.222', credentials=credentials)) # host指定rabbitmq服务器ip地址,credentials指定用户名和密码
# 创建channel对象,用于发送消息,接收消息,声明队列
channel = connection.channel() # connection.channel(): 在连接上创建一个频道,这个频道就是我们要通过它来发送,接收消息的对象,类似于TCP中的socket对象,我们通过它来收发消息,声明队列
# 声明队列,如果队列不存在,则创建队列,如果队列存在,则不创建
channel.queue_declare(queue='datalog')
# 生产者向队列中放一条消息
channel.basic_publish(exchange='', # 交换机,如果不指定,则使用默认的交换机, 默认的交换机
routing_key='datalog', # 队列名称
body='zll nb!' # 发送的消息
)
print("Sent 'Hello World!'")
# 关闭连接
connection.close()
import pika, sys, os
def main():
# 创建连接对象
# connection = pika.BlockingConnection(pika.ConnectionParameters(host='47.101.159.222:22')) # host指定rabbitmq服务器ip地址
# 指定用户名和密码,如果rabbitmq没有设置用户名和密码,可以不指定
credentials = pika.PlainCredentials("admin", "admin")
connection = pika.BlockingConnection(pika.ConnectionParameters('47.101.159.222',
credentials=credentials)) # host指定rabbitmq服务器ip地址,credentials指定用户名和密码
# 创建channel对象,用于发送消息,接收消息,声明队列
channel = connection.channel() # connection.channel(): 在连接上创建一个频道,这个频道就是我们要通过它来发送,接收消息的对象,类似于TCP中的socket对象,我们通过它来收发消息,声明队列
"""消费者也声明了队列,因为如果是消费者先启动,那么队列就不存在了,消费者就无法消费消息了,所以消费者也要声明队列"""
channel.queue_declare(queue='datalog')
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
# 真正的将消息消费完了,再发确认
ch.basic_ack(delivery_tag=method.delivery_tag)
# 消费者从队列queue指定的消费队列hello中取消息,拿到数据了之前将hello队列的数据丢到callback里面,如果队列中没有消息,则会一直等待,直到有消息为止
# auto_ack=True:自动确认消息,如果不设置为True,那么消息会一直处于未确认状态,即使消费者已经消费了消息,消息也不会从队列中删除,这样就会造成消息的重复消费,所以一般都会设置为True
# auto_ack=true: 队列接收到既直接确认,就会删除队列中的消息,不会管后面数据会不会消费完。
channel.basic_consume(queue='datalog', on_message_callback=callback, auto_ack=False) # 默认为false,不自动确认消息,需要手动确认
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming() # 开始消费消息,如果队列中没有消息,那么就会一直等待,直到有消息为止,如果队列中有消息,那么就会消费消息
if __name__ == '__main__':
main()
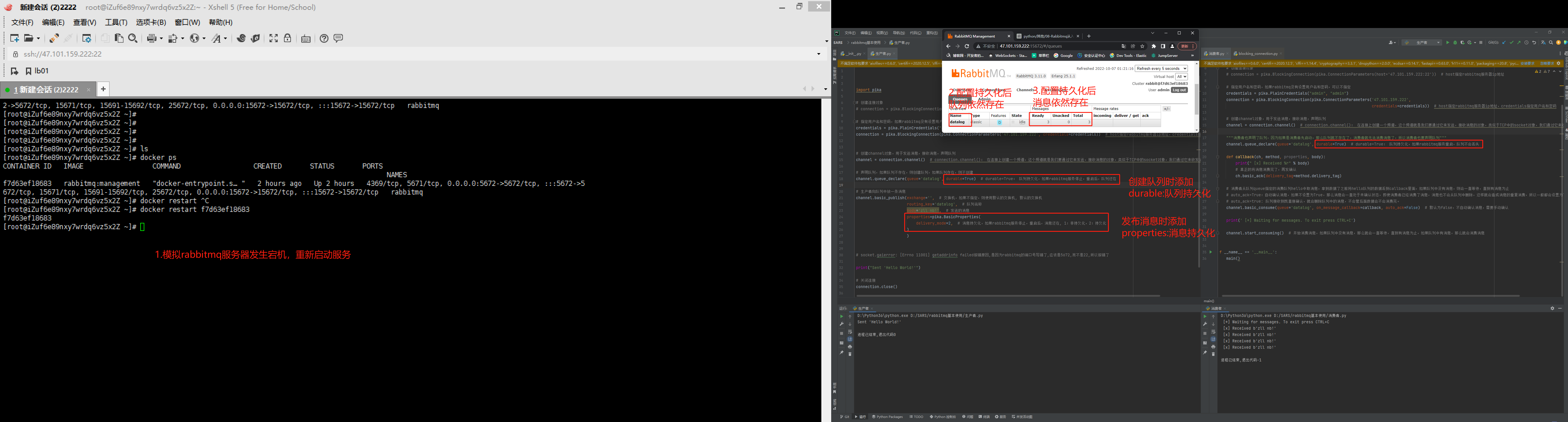
六: 持久化(消息安全之durable持久化)
1.什么是rabbitmq持久化?
数据支持持久化,运行过程中,rabbitmq宕机了,在重新启动起来,如果队列消费消息没被消费,那么就还是会存在。
2.配置队列持久化
# 在创建队列的时候增加durable=True设置队列持久化,如果rabbitmq服务重启,队列不会丢失
channel.queue_declare(queue='datalog',durable=True)
3.配置消息持久化
# 在发布消息的时候增加properties设置消息持久化,如果rabbitmq服务停止,重启后,消息还在, 1:非持久化,2:持久化,默认为1
properties=pika.BasicProperties(delivery_mode=2,)
# 注意:
1.没加持久化配置之前的队列不会支持持久化,需要加持久化配置之后重新创建。
import pika
# 创建连接对象
# connection = pika.BlockingConnection(pika.ConnectionParameters(host='47.101.159.222:22')) # host指定rabbitmq服务器ip地址
# 指定用户名和密码,如果rabbitmq没有设置用户名和密码,可以不指定
credentials = pika.PlainCredentials("admin", "admin")
connection = pika.BlockingConnection(pika.ConnectionParameters('47.101.159.222', credentials=credentials)) # host指定rabbitmq服务器ip地址,credentials指定用户名和密码
# 创建channel对象,用于发送消息,接收消息,声明队列
channel = connection.channel() # connection.channel(): 在连接上创建一个频道,这个频道就是我们要通过它来发送,接收消息的对象,类似于TCP中的socket对象,我们通过它来收发消息,声明队列
# 声明队列,如果队列不存在,则创建队列,如果队列存在,则不创建
channel.queue_declare(queue='datalog', durable=True) # durable=True: 队列持久化,如果rabbitmq服务停止,重启后,队列还在
# 生产者向队列中放一条消息
channel.basic_publish(exchange='', # 交换机,如果不指定,则使用默认的交换机, 默认的交换机
routing_key='datalog', # 队列名称
body='zll nb!', # 发送的消息
properties=pika.BasicProperties(
delivery_mode=2, # 消息持久化,如果rabbitmq服务停止,重启后,消息还在, 1:非持久化,2:持久化
)
)
print("Sent 'Hello World!'")
# 关闭连接
connection.close()
import pika, sys, os
def main():
# 创建连接对象
# connection = pika.BlockingConnection(pika.ConnectionParameters(host='47.101.159.222:22')) # host指定rabbitmq服务器ip地址
# 指定用户名和密码,如果rabbitmq没有设置用户名和密码,可以不指定
credentials = pika.PlainCredentials("admin", "admin")
connection = pika.BlockingConnection(pika.ConnectionParameters('47.101.159.222',
credentials=credentials)) # host指定rabbitmq服务器ip地址,credentials指定用户名和密码
# 创建channel对象,用于发送消息,接收消息,声明队列
channel = connection.channel() # connection.channel(): 在连接上创建一个频道,这个频道就是我们要通过它来发送,接收消息的对象,类似于TCP中的socket对象,我们通过它来收发消息,声明队列
"""消费者也声明了队列,因为如果是消费者先启动,那么队列就不存在了,消费者就无法消费消息了,所以消费者也要声明队列"""
channel.queue_declare(queue='datalog', durable=True) # durable=True: 队列持久化,如果rabbitmq服务重启,队列不会丢失
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
# 真正的将消息消费完了,再发确认
ch.basic_ack(delivery_tag=method.delivery_tag)
# 消费者从队列queue指定的消费队列hello中取消息,拿到数据了之前将hello队列的数据丢到callback里面,如果队列中没有消息,则会一直等待,直到有消息为止
# auto_ack=True:自动确认消息,如果不设置为True,那么消息会一直处于未确认状态,即使消费者已经消费了消息,消息也不会从队列中删除,这样就会造成消息的重复消费,所以一般都会设置为True
# auto_ack=true: 队列接收到既直接确认,就会删除队列中的消息,不会管后面数据会不会消费完。
channel.basic_consume(queue='datalog', on_message_callback=callback, auto_ack=False) # 默认为false,不自动确认消息,需要手动确认
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming() # 开始消费消息,如果队列中没有消息,那么就会一直等待,直到有消息为止,如果队列中有消息,那么就会消费消息
if __name__ == '__main__':
main()
七: 闲置消费
1.什么是闲置消费?
1.正常情况如果有多个消费者,是按照顺序第一个消息给第一个消费者,第二个消息给第二个消费者,以此类推,只能按照顺序。
2.但是可能第一个消费的消费者处理消息很耗时,一直没结束,此时就可以让第二个消费者优先获取闲置的消息,次方法就称之为"闲置消费"。
2.配置闲置消费
# 消费者配置,每次只接收一条消息,处理完了再接收下一条,这样可以保证消息的顺序性,不会出现消息乱序的情况
channel.basic_qos(prefetch_count=1) # 1代表每次只接收一条消息,接收完了再接收下一条
# 缺点:
1.但是会降低效率,因为每次只处理一条消息,如果消息处理很快,那么效率就会降低
import pika
# 创建连接对象
# connection = pika.BlockingConnection(pika.ConnectionParameters(host='47.101.159.222:22')) # host指定rabbitmq服务器ip地址
# 指定用户名和密码,如果rabbitmq没有设置用户名和密码,可以不指定
credentials = pika.PlainCredentials("admin", "admin")
connection = pika.BlockingConnection(pika.ConnectionParameters('47.101.159.222', credentials=credentials)) # host指定rabbitmq服务器ip地址,credentials指定用户名和密码
# 创建channel对象,用于发送消息,接收消息,声明队列
channel = connection.channel() # connection.channel(): 在连接上创建一个频道,这个频道就是我们要通过它来发送,接收消息的对象,类似于TCP中的socket对象,我们通过它来收发消息,声明队列
# 声明队列,如果队列不存在,则创建队列,如果队列存在,则不创建
channel.queue_declare(queue='datalog', durable=True) # durable=True: 队列持久化,如果rabbitmq服务停止,重启后,队列还在
# 生产者向队列中放一条消息
channel.basic_publish(exchange='', # 交换机,如果不指定,则使用默认的交换机, 默认的交换机
routing_key='datalog', # 队列名称
body='zll nb!', # 发送的消息
properties=pika.BasicProperties(
delivery_mode=2, # 消息持久化,如果rabbitmq服务停止,重启后,消息还在, 1:非持久化,2:持久化
)
)
print("Sent 'Hello World!'")
# 关闭连接
connection.close()
import time
import pika, sys, os
def main():
# 创建连接对象
# connection = pika.BlockingConnection(pika.ConnectionParameters(host='47.101.159.222:22')) # host指定rabbitmq服务器ip地址
# 指定用户名和密码,如果rabbitmq没有设置用户名和密码,可以不指定
credentials = pika.PlainCredentials("admin", "admin")
connection = pika.BlockingConnection(pika.ConnectionParameters('47.101.159.222',
credentials=credentials)) # host指定rabbitmq服务器ip地址,credentials指定用户名和密码
# 创建channel对象,用于发送消息,接收消息,声明队列
channel = connection.channel() # connection.channel(): 在连接上创建一个频道,这个频道就是我们要通过它来发送,接收消息的对象,类似于TCP中的socket对象,我们通过它来收发消息,声明队列
"""消费者也声明了队列,因为如果是消费者先启动,那么队列就不存在了,消费者就无法消费消息了,所以消费者也要声明队列"""
channel.queue_declare(queue='datalog', durable=True) # durable=True: 队列持久化,如果rabbitmq服务重启,队列不会丢失
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
time.sleep(50) # 模拟处理任务,耗时50秒
# 真正的将消息消费完了,再发确认
ch.basic_ack(delivery_tag=method.delivery_tag)
# 闲置消费
channel.basic_qos(prefetch_count=1) # 每次只接收一条消息,处理完了再接收下一条,这样可以保证消息的顺序性,不会出现消息乱序的情况,但是会降低效率,因为每次只处理一条消息,如果消息处理很快,那么效率就会降低
# 消费者从队列queue指定的消费队列hello中取消息,拿到数据了之前将hello队列的数据丢到callback里面,如果队列中没有消息,则会一直等待,直到有消息为止
# auto_ack=True:自动确认消息,如果不设置为True,那么消息会一直处于未确认状态,即使消费者已经消费了消息,消息也不会从队列中删除,这样就会造成消息的重复消费,所以一般都会设置为True
# auto_ack=true: 队列接收到既直接确认,就会删除队列中的消息,不会管后面数据会不会消费完。
channel.basic_consume(queue='datalog', on_message_callback=callback, auto_ack=False) # 默认为false,不自动确认消息,需要手动确认
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming() # 开始消费消息,如果队列中没有消息,那么就会一直等待,直到有消息为止,如果队列中有消息,那么就会消费消息
if __name__ == '__main__':
main()
import pika, sys, os
def main():
# 创建连接对象
# connection = pika.BlockingConnection(pika.ConnectionParameters(host='47.101.159.222:22')) # host指定rabbitmq服务器ip地址
# 指定用户名和密码,如果rabbitmq没有设置用户名和密码,可以不指定
credentials = pika.PlainCredentials("admin", "admin")
connection = pika.BlockingConnection(pika.ConnectionParameters('47.101.159.222',
credentials=credentials)) # host指定rabbitmq服务器ip地址,credentials指定用户名和密码
# 创建channel对象,用于发送消息,接收消息,声明队列
channel = connection.channel() # connection.channel(): 在连接上创建一个频道,这个频道就是我们要通过它来发送,接收消息的对象,类似于TCP中的socket对象,我们通过它来收发消息,声明队列
"""消费者也声明了队列,因为如果是消费者先启动,那么队列就不存在了,消费者就无法消费消息了,所以消费者也要声明队列"""
channel.queue_declare(queue='datalog', durable=True) # durable=True: 队列持久化,如果rabbitmq服务重启,队列不会丢失
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
# 真正的将消息消费完了,再发确认
ch.basic_ack(delivery_tag=method.delivery_tag)
# 闲置消费
channel.basic_qos(prefetch_count=1) # 每次只接收一条消息,处理完了再接收下一条,这样可以保证消息的顺序性,不会出现消息乱序的情况,但是会降低效率,因为每次只处理一条消息,如果消息处理很快,那么效率就会降低
# 消费者从队列queue指定的消费队列hello中取消息,拿到数据了之前将hello队列的数据丢到callback里面,如果队列中没有消息,则会一直等待,直到有消息为止
# auto_ack=True:自动确认消息,如果不设置为True,那么消息会一直处于未确认状态,即使消费者已经消费了消息,消息也不会从队列中删除,这样就会造成消息的重复消费,所以一般都会设置为True
# auto_ack=true: 队列接收到既直接确认,就会删除队列中的消息,不会管后面数据会不会消费完。
channel.basic_consume(queue='datalog', on_message_callback=callback, auto_ack=False) # 默认为false,不自动确认消息,需要手动确认
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming() # 开始消费消息,如果队列中没有消息,那么就会一直等待,直到有消息为止,如果队列中有消息,那么就会消费消息
if __name__ == '__main__':
main()

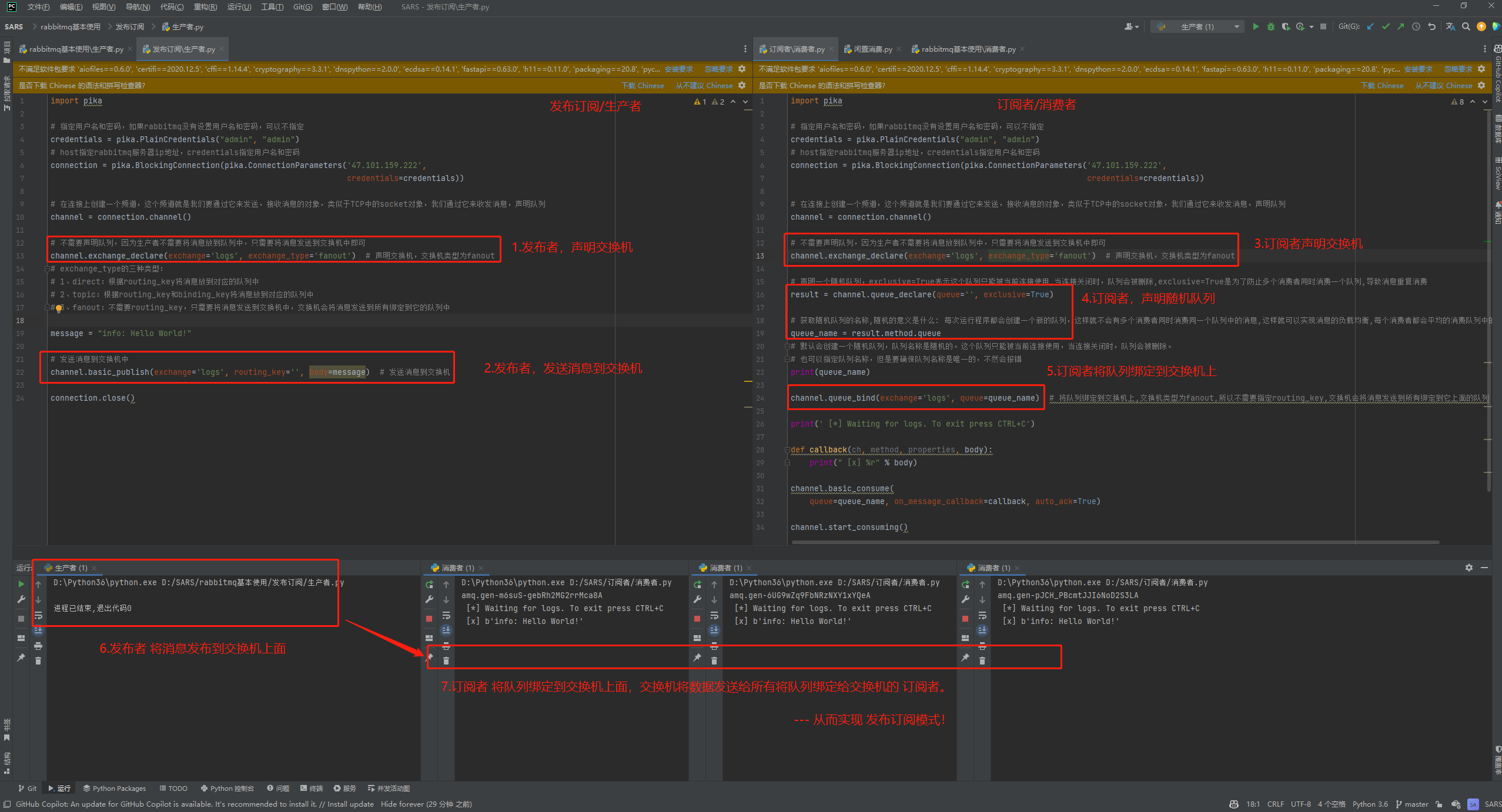
八: 发布订阅(fanout)
发布订阅: 可以有多个订阅者来订阅发布者的消息
# fanout:不需要routing_key,只需要将消息发送到交换机中,交换机会将消息发送到所有绑定到它的队列中
# 实现发布订阅逻辑
1.发布者 P 将消息发送到 X 交换机上面,
2.C1,C2,多个订阅者随机创建出多个队列,将订阅者队列绑定给 X 交换机,
3.X 交换机通过队列将数据发送给所有绑定 X 交换机的订阅者。
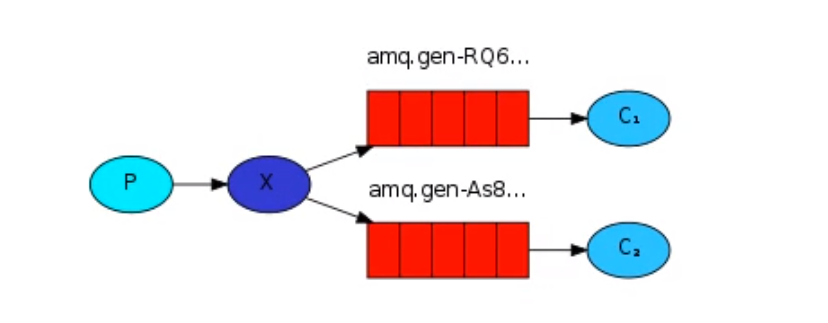
-
发布订阅/生产者
import pika
# 指定用户名和密码,如果rabbitmq没有设置用户名和密码,可以不指定
credentials = pika.PlainCredentials("admin", "admin")
# host指定rabbitmq服务器ip地址,credentials指定用户名和密码
connection = pika.BlockingConnection(pika.ConnectionParameters('47.101.159.222',
credentials=credentials))
# 在连接上创建一个频道,这个频道就是我们要通过它来发送,接收消息的对象,类似于TCP中的socket对象,我们通过它来收发消息,声明队列
channel = connection.channel()
# 不需要声明队列,因为生产者不需要将消息放到队列中,只需要将消息发送到交换机中即可
channel.exchange_declare(exchange='logs', exchange_type='fanout') # 声明交换机,交换机类型为fanout
# exchange_type的三种类型:
# 1、direct:根据routing_key将消息放到对应的队列中
# 2、topic:根据routing_key和binding_key将消息放到对应的队列中
# 3、fanout:不需要routing_key,只需要将消息发送到交换机中,交换机会将消息发送到所有绑定到它的队列中
message = "info: Hello World!"
# 发送消息到交换机中
channel.basic_publish(exchange='logs', routing_key='', body=message) # 发送消息到交换机
connection.close()
-
订阅者/消费者
import pika
# 指定用户名和密码,如果rabbitmq没有设置用户名和密码,可以不指定
credentials = pika.PlainCredentials("admin", "admin")
# host指定rabbitmq服务器ip地址,credentials指定用户名和密码
connection = pika.BlockingConnection(pika.ConnectionParameters('47.101.159.222',
credentials=credentials))
# 在连接上创建一个频道,这个频道就是我们要通过它来发送,接收消息的对象,类似于TCP中的socket对象,我们通过它来收发消息,声明队列
channel = connection.channel()
# 不需要声明队列,因为生产者不需要将消息放到队列中,只需要将消息发送到交换机中即可
channel.exchange_declare(exchange='logs', exchange_type='fanout') # 声明交换机,交换机类型为fanout
# 声明一个随机队列,exclusive=True表示这个队列只能被当前连接使用,当连接关闭时,队列会被删除,exclusive=True是为了防止多个消费者同时消费一个队列,导致消息重复消费
result = channel.queue_declare(queue='', exclusive=True)
# 获取随机队列的名称,随机的意义是什么: 每次运行程序都会创建一个新的队列,这样就不会有多个消费者同时消费同一个队列中的消息,这样就可以实现消息的负载均衡,每个消费者都会平均的消费队列中的消息
queue_name = result.method.queue
# 默认会创建一个随机队列,队列名称是随机的。这个队列只能被当前连接使用,当连接关闭时,队列会被删除。
# 也可以指定队列名称,但是要确保队列名称是唯一的,不然会报错
print(queue_name)
channel.queue_bind(exchange='logs', queue=queue_name) # 将队列绑定到交换机上,交换机类型为fanout,所以不需要指定routing_key,交换机会将消息发送到所有绑定到它上面的队列
print(' [*] Waiting for logs. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] %r" % body)
channel.basic_consume(
queue=queue_name, on_message_callback=callback, auto_ack=True)
channel.start_consuming()
九:关键字(direct)
direct:根据routing_key将消息放到对应的队列中
1.关键字
1.将随机队列绑定到交换机上,routing_key指定路由键,这里指定的是key,
2.表示只有路由键为info的消息才会被发送到该随机队列中,也就是说只有生产者发送的消息的路由键为key的消息才会被消费。
# 总结:
将随机队列绑定到交换机上,routing_key为指定消费交换机的队列名称,从而实现指定消费,然后将消息从绑定的交换机的队列获取, 消费。
routing_key监听的队列名称
-
发布订阅/生产者
import pika
# 指定用户名和密码,如果rabbitmq没有设置用户名和密码,可以不指定
credentials = pika.PlainCredentials("admin", "admin")
# host指定rabbitmq服务器ip地址,credentials指定用户名和密码
connection = pika.BlockingConnection(pika.ConnectionParameters('47.101.159.222',
credentials=credentials))
# 在连接上创建一个频道,这个频道就是我们要通过它来发送,接收消息的对象,类似于TCP中的socket对象,我们通过它来收发消息,声明队列
channel = connection.channel()
# 不需要声明队列,因为生产者不需要将消息放到队列中,只需要将消息发送到交换机中即可
channel.exchange_declare(exchange='zll', exchange_type='direct') # 声明交换机,交换机类型为direct
# exchange_type的三种类型:
# 1、direct:根据routing_key将消息放到对应的队列中
# 2、topic:根据routing_key和binding_key将消息放到对应的队列中
# 3、fanout:不需要routing_key,只需要将消息发送到交换机中,交换机会将消息发送到所有绑定到它的队列中
message = "info: Hello World!"
# 发送消息到交换机中
channel.basic_publish(exchange='zll', routing_key='bnb', body=message) # routing_key为bnb,消息会被发送到bnb队列中,如果没有bnb队列,消息会被丢弃,因为没有队列可以接收消息
connection.close()
-
订阅者/消费者
import pika
# 指定用户名和密码,如果rabbitmq没有设置用户名和密码,可以不指定
credentials = pika.PlainCredentials("admin", "admin")
# host指定rabbitmq服务器ip地址,credentials指定用户名和密码
connection = pika.BlockingConnection(pika.ConnectionParameters('47.101.159.222',
credentials=credentials))
# 在连接上创建一个频道,这个频道就是我们要通过它来发送,接收消息的对象,类似于TCP中的socket对象,我们通过它来收发消息,声明队列
channel = connection.channel()
# 不需要声明队列,因为生产者不需要将消息放到队列中,只需要将消息发送到交换机中即可
channel.exchange_declare(exchange='zll', exchange_type='direct') # 声明交换机,交换机类型为fanout
# 声明一个随机队列,exclusive=True表示这个队列只能被当前连接使用,当连接关闭时,队列会被删除,exclusive=True是为了防止多个消费者同时消费一个队列,导致消息重复消费
result = channel.queue_declare(queue='', exclusive=True)
# 获取随机队列的名称,随机的意义是什么: 每次运行程序都会创建一个新的队列,这样就不会有多个消费者同时消费同一个队列中的消息,这样就可以实现消息的负载均衡,每个消费者都会平均的消费队列中的消息
queue_name = result.method.queue
# 默认会创建一个随机队列,队列名称是随机的。这个队列只能被当前连接使用,当连接关闭时,队列会被删除。
# 也可以指定队列名称,但是要确保队列名称是唯一的,不然会报错
print(queue_name)
# 将队列绑定到交换机上,routing_key指定路由键,这里指定的是info,表示只有路由键为info的消息才会被发送到该随机队列中,也就是说只有生产者发送的消息的路由键为info的消息才会被消费。
channel.queue_bind(exchange='zll', queue=queue_name, routing_key='nb') # 将队列绑定到交换机上,routing_key为指定消费交换机的队列名称,从而实现指定消费,然后将消息从绑定到交换机的队列获取
channel.queue_bind(exchange='zll', queue=queue_name, routing_key='bnb')
print(' [*] Waiting for logs. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] %r" % body)
channel.basic_consume(
queue=queue_name, on_message_callback=callback, auto_ack=True)
channel.start_consuming()
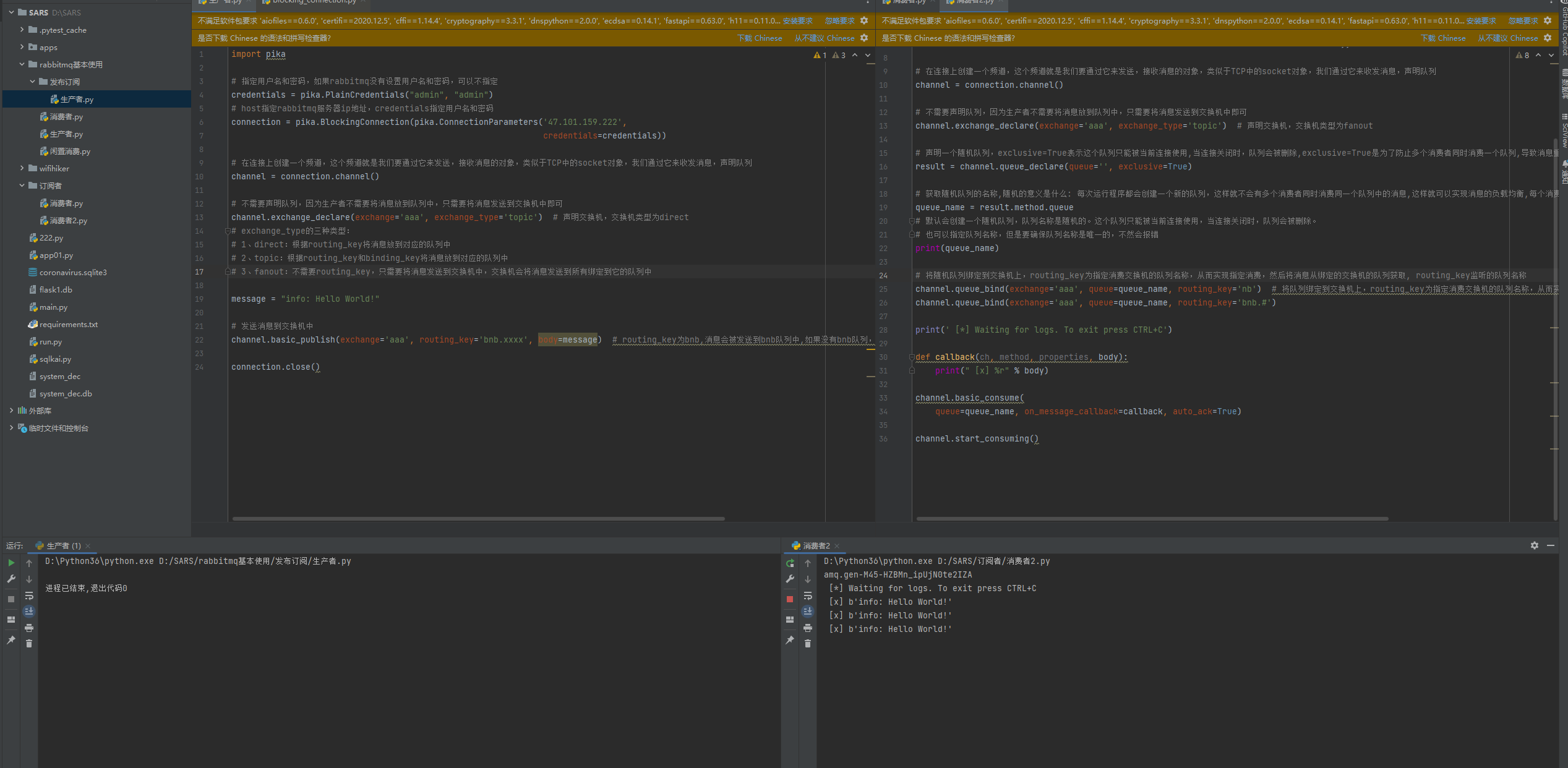
十:模糊匹配(topic)
topic:根据routing_key和binding_key将消息放到对应的队列中
# 模糊匹配的关键
# : 表示后面可以跟任意字符
* : 表示后面只能跟一个单词
-
发布订阅/生产者
import pika
# 指定用户名和密码,如果rabbitmq没有设置用户名和密码,可以不指定
credentials = pika.PlainCredentials("admin", "admin")
# host指定rabbitmq服务器ip地址,credentials指定用户名和密码
connection = pika.BlockingConnection(pika.ConnectionParameters('47.101.159.222',
credentials=credentials))
# 在连接上创建一个频道,这个频道就是我们要通过它来发送,接收消息的对象,类似于TCP中的socket对象,我们通过它来收发消息,声明队列
channel = connection.channel()
# 不需要声明队列,因为生产者不需要将消息放到队列中,只需要将消息发送到交换机中即可
channel.exchange_declare(exchange='aaa', exchange_type='topic') # 声明交换机,交换机类型为direct
# exchange_type的三种类型:
# 1、direct:根据routing_key将消息放到对应的队列中
# 2、topic:根据routing_key和binding_key将消息放到对应的队列中
# 3、fanout:不需要routing_key,只需要将消息发送到交换机中,交换机会将消息发送到所有绑定到它的队列中
message = "info: Hello World!"
# 发送消息到交换机中
channel.basic_publish(exchange='aaa', routing_key='bnb.xxxx', body=message) # routing_key为bnb,消息会被发送到bnb队列中,如果没有bnb队列,消息会被丢弃,因为没有队列可以接收消息
connection.close()
import pika
# 指定用户名和密码,如果rabbitmq没有设置用户名和密码,可以不指定
credentials = pika.PlainCredentials("admin", "admin")
# host指定rabbitmq服务器ip地址,credentials指定用户名和密码
connection = pika.BlockingConnection(pika.ConnectionParameters('47.101.159.222',
credentials=credentials))
# 在连接上创建一个频道,这个频道就是我们要通过它来发送,接收消息的对象,类似于TCP中的socket对象,我们通过它来收发消息,声明队列
channel = connection.channel()
# 不需要声明队列,因为生产者不需要将消息放到队列中,只需要将消息发送到交换机中即可
channel.exchange_declare(exchange='aaa', exchange_type='topic') # 声明交换机,交换机类型为fanout
# 声明一个随机队列,exclusive=True表示这个队列只能被当前连接使用,当连接关闭时,队列会被删除,exclusive=True是为了防止多个消费者同时消费一个队列,导致消息重复消费
result = channel.queue_declare(queue='', exclusive=True)
# 获取随机队列的名称,随机的意义是什么: 每次运行程序都会创建一个新的队列,这样就不会有多个消费者同时消费同一个队列中的消息,这样就可以实现消息的负载均衡,每个消费者都会平均的消费队列中的消息
queue_name = result.method.queue
# 默认会创建一个随机队列,队列名称是随机的。这个队列只能被当前连接使用,当连接关闭时,队列会被删除。
# 也可以指定队列名称,但是要确保队列名称是唯一的,不然会报错
print(queue_name)
# 将随机队列绑定到交换机上,routing_key为指定消费交换机的队列名称,从而实现指定消费,然后将消息从绑定的交换机的队列获取, routing_key监听的队列名称
channel.queue_bind(exchange='aaa', queue=queue_name, routing_key='nb') # 将队列绑定到交换机上,routing_key为指定消费交换机的队列名称,从而实现指定消费,然后将消息从绑定到交换机的队列获取
channel.queue_bind(exchange='aaa', queue=queue_name, routing_key='bnb.#')
print(' [*] Waiting for logs. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] %r" % body)
channel.basic_consume(
queue=queue_name, on_message_callback=callback, auto_ack=True)
channel.start_consuming()
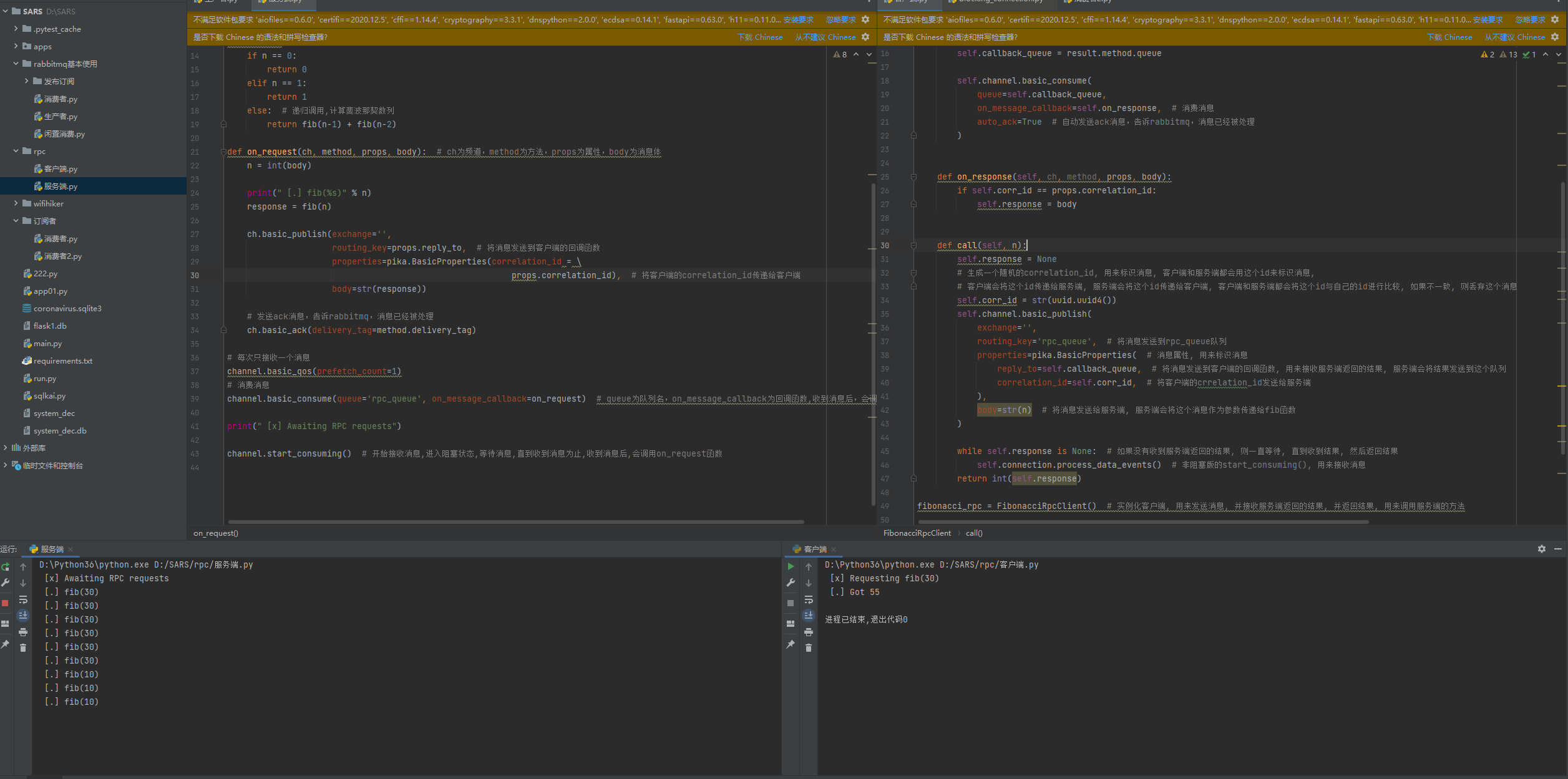
十一:通过rabbitmq实现rpc(基于RabbitMQ封装RPC)
# 通过RabbitMQ实现rpc
# 实现逻辑
1.服务端启动接收消息,监听queue队列。
2.实列化客户端,调用call方法,将消息属性内包含: 1.回调函数随机队列,接收服务端返回结果,服务端会将结果发送到这个队列。2.客户但的随机uuid,标识唯一消息。然后将body消息发送给服务端。
3.客户端,发布完消息后,进入非阻塞状态,如果没有接收到服务端返回的结果,会一直等待,直到收到结果,然后返回结果。
4.服务端接收queue队列消息,调用函数将消息进行处理,获取裴波那契数列。
5.然后服务端进行发布,将消息发送到客户端的回调函数队列,客户端的uuid。
6.客户端监听接收队列消息,调用函数处理,判断唯一uuid,确认body,然后成功收到消息并返回。
import pika
# 指定用户名和密码,如果rabbitmq没有设置用户名和密码,可以不指定
credentials = pika.PlainCredentials("admin", "admin")
# host指定rabbitmq服务器ip地址,credentials指定用户名和密码
connection = pika.BlockingConnection(pika.ConnectionParameters('47.101.159.222',
credentials=credentials))
# 在连接上创建一个频道,这个频道就是我们要通过它来发送,接收消息的对象,类似于TCP中的socket对象,我们通过它来收发消息,声明队列
channel = connection.channel()
channel.queue_declare(queue='rpc_queue') # 声明队列,如果队列不存在,会自动创建
def fib(n):
if n == 0:
return 0
elif n == 1:
return 1
else: # 递归调用,计算斐波那契数列
return fib(n-1) + fib(n-2)
def on_request(ch, method, props, body): # ch为频道,method为方法,props为属性,body为消息体
n = int(body)
print(" [.] fib(%s)" % n)
response = fib(n)
ch.basic_publish(exchange='',
routing_key=props.reply_to, # 将消息发送到客户端的回调函数
properties=pika.BasicProperties(correlation_id = \
props.correlation_id), # 将客户端的correlation_id传递给客户端
body=str(response))
# 发送ack消息,告诉rabbitmq,消息已经被处理
ch.basic_ack(delivery_tag=method.delivery_tag)
# 每次只接收一个消息
channel.basic_qos(prefetch_count=1)
# 消费消息
channel.basic_consume(queue='rpc_queue', on_message_callback=on_request) # queue为队列名,on_message_callback为回调函数,收到消息后,会调用回调函数
print(" [x] Awaiting RPC requests")
channel.start_consuming() # 开始接收消息,进入阻塞状态,等待消息,直到收到消息为止,收到消息后,会调用on_request函数
import pika
import uuid
class FibonacciRpcClient(object):
def __init__(self):
# 指定用户名和密码,如果rabbitmq没有设置用户名和密码,可以不指定
self.credentials = pika.PlainCredentials("admin", "admin")
# host指定rabbitmq服务器ip地址,credentials指定用户名和密码
self.connection = pika.BlockingConnection(pika.ConnectionParameters('47.101.159.222', credentials=self.credentials))
self.channel = self.connection.channel()
# 声明一个随机队列,用来接收rpc_server返回的结果
result = self.channel.queue_declare(queue='', exclusive=True) # exclusive=True表示这个队列只能被当前连接使用,当连接关闭时,队列会被删除,exclusive=True是为了防止多个客户端同时使用一个队列
# 获取随机队列的名称
self.callback_queue = result.method.queue
self.channel.basic_consume(
queue=self.callback_queue,
on_message_callback=self.on_response, # 消费消息
auto_ack=True # 自动发送ack消息,告诉rabbitmq,消息已经被处理
)
def on_response(self, ch, method, props, body):
if self.corr_id == props.correlation_id:
self.response = body
def call(self, n):
self.response = None
# 生成一个随机的correlation_id, 用来标识消息, 客户端和服务端都会用这个id来标识消息,
# 客户端会将这个id传递给服务端, 服务端会将这个id传递给客户端, 客户端和服务端都会将这个id与自己的id进行比较, 如果不一致, 则丢弃这个消息
self.corr_id = str(uuid.uuid4())
self.channel.basic_publish(
exchange='',
routing_key='rpc_queue', # 将消息发送到rpc_queue队列
properties=pika.BasicProperties( # 消息属性, 用来标识消息
reply_to=self.callback_queue, # 将消息发送到客户端的回调函数, 用来接收服务端返回的结果, 服务端会将结果发送到这个队列
correlation_id=self.corr_id, # 将客户端的crrelation_id发送给服务端
),
body=str(n) # 将消息发送给服务端, 服务端会将这个消息作为参数传递给fib函数
)
while self.response is None: # 如果没有收到服务端返回的结果, 则一直等待, 直到收到结果, 然后返回结果
self.connection.process_data_events() # 非阻塞版的start_consuming(), 用来接收消息
return int(self.response)
fibonacci_rpc = FibonacciRpcClient() # 实例化客户端, 用来发送消息, 并接收服务端返回的结果, 并返回结果, 用来调用服务端的方法
print(" [x] Requesting fib(30)")
response = fibonacci_rpc.call(10) # 调用call方法, 发送消息, 并接收服务端返回的结果, 然后打印结果
print(" [.] Got %r" % response)
十二:python中的rpc框架
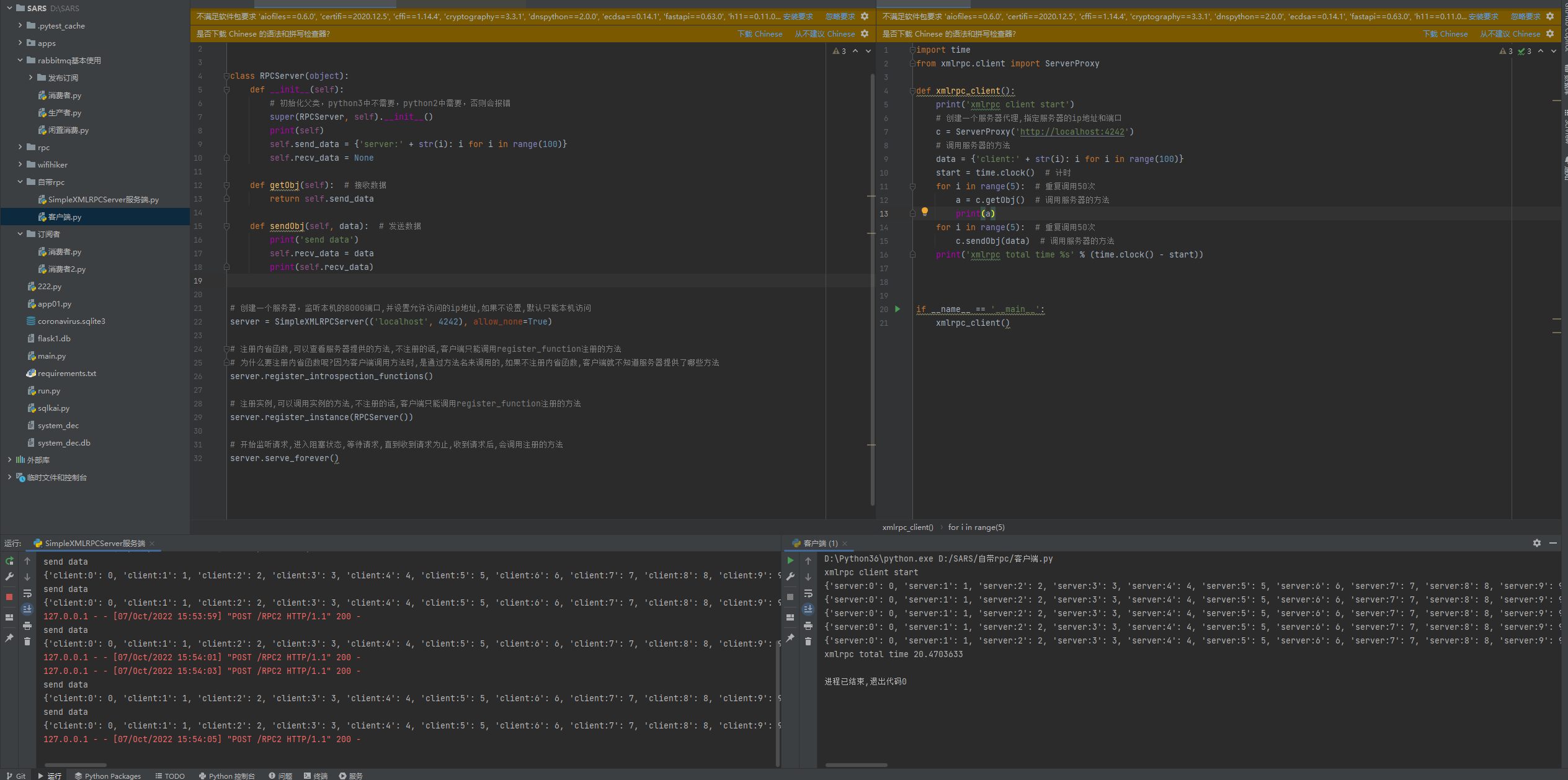
python自带的: SimpleXMLRPCServer(数据包大,数据慢) - HTTP通信
第三方: ZeroRPC(底层使用ZeroMQ和MessagePack,速度快,响应时间短,并发高),grpc(谷歌推出支持夸语言) - TCP通信
十三:SimpleXMLRPCServer
from xmlrpc.server import SimpleXMLRPCServer
class RPCServer(object):
def __init__(self):
# 初始化父类,python3中不需要,python2中需要,否则会报错
super(RPCServer, self).__init__()
print(self)
self.send_data = {'server:' + str(i): i for i in range(100)}
self.recv_data = None
def getObj(self): # 接收数据
return self.send_data
def sendObj(self, data): # 发送数据
print('send data')
self.recv_data = data
print(self.recv_data)
# 创建一个服务器,监听本机的8000端口,并设置允许访问的ip地址,如果不设置,默认只能本机访问
server = SimpleXMLRPCServer(('localhost', 4242), allow_none=True)
# 注册内省函数,可以查看服务器提供的方法,不注册的话,客户端只能调用register_function注册的方法
# 为什么要注册内省函数呢?因为客户端调用方法时,是通过方法名来调用的,如果不注册内省函数,客户端就不知道服务器提供了哪些方法
server.register_introspection_functions()
# 注册实例,可以调用实例的方法,不注册的话,客户端只能调用register_function注册的方法
server.register_instance(RPCServer())
# 开始监听请求,进入阻塞状态,等待请求,直到收到请求为止,收到请求后,会调用注册的方法
server.serve_forever()
import time
from xmlrpc.client import ServerProxy
def xmlrpc_client():
print('xmlrpc client start')
# 创建一个服务器代理,指定服务器的ip地址和端口
c = ServerProxy('http://localhost:4242')
# 调用服务器的方法
data = {'client:' + str(i): i for i in range(100)}
start = time.clock() # 计时
for i in range(5): # 重复调用50次
a = c.getObj() # 调用服务器的方法
print(a)
for i in range(5): # 重复调用50次
c.sendObj(data) # 调用服务器的方法
print('xmlrpc total time %s' % (time.clock() - start))
if __name__ == '__main__':
xmlrpc_client()
十四:ZeroRPC实现rpc
import zerorpc
class RPCServer(object):
def __init__(self):
print(self)
self.send_data = {'server:'+str(i): i for i in range(100)}
self.recv_data = None
def getObj(self):
print('get data')
return self.send_data
def sendObj(self, data):
print('send data')
self.recv_data = data
print(self.recv_data)
# 创建一个服务器,监听本机的8000端口,并设置允许访问的ip地址,如果不设置,默认只能本机访问
s = zerorpc.Server(RPCServer())
# 绑定端口,并设置允许访问的ip地址,如果不设置,默认只能本机访问
s.bind('tcp://0.0.0.0:4243')
# 开始监听请求,进入阻塞状态,等待请求,直到收到请求为止,收到请求后,会调用注册的方法
s.run()
import zerorpc
class RPCServer(object):
def __init__(self):
print(self)
self.send_data = {'server:'+str(i): i for i in range(100)}
self.recv_data = None
def getObj(self):
print('get data')
return self.send_data
def sendObj(self, data):
print('send data')
self.recv_data = data
print(self.recv_data)
# 创建一个服务器,监听本机的8000端口,并设置允许访问的ip地址,如果不设置,默认只能本机访问
s = zerorpc.Server(RPCServer())
# 绑定端口,并设置允许访问的ip地址,如果不设置,默认只能本机访问
s.bind('tcp://0.0.0.0:4243')
# 开始监听请求,进入阻塞状态,等待请求,直到收到请求为止,收到请求后,会调用注册的方法
s.run()

十五:什么是RPC?
1.RPC介绍?
RPC 是指远程过程调用,也就是说两台服务器,A 和 B,一个应用部署在A 服务器上,想要调用B 服务器上应用提供的函数或方法,由于不在一个内存空间,不能直接调用,需要通过网络来表达调用的语句和传达调用的数据。
2.RPC是如何调用的?
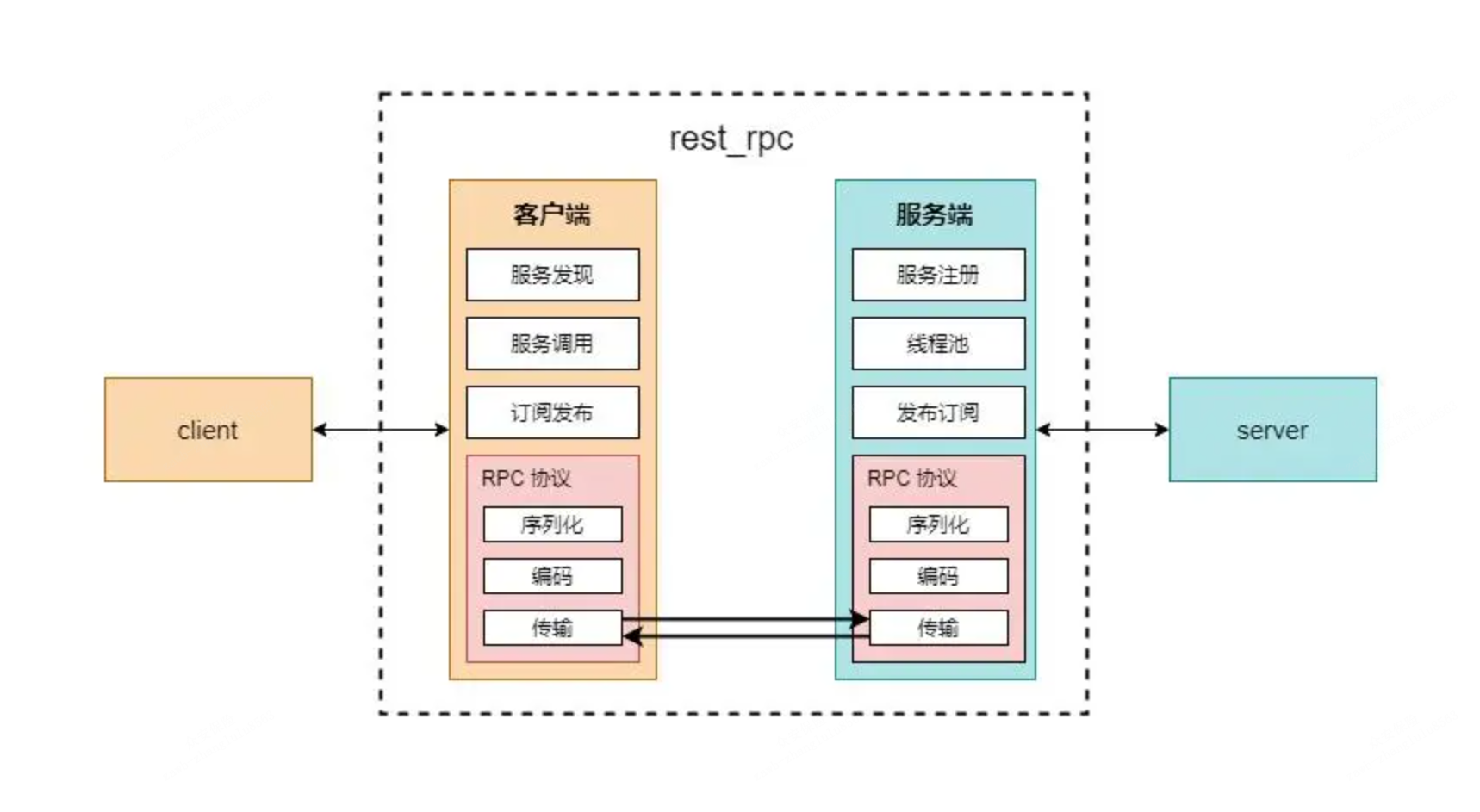
1.要解决通讯的问题,主要是通过在客户端和服务器之间建立TCP连接,远程过程调用的所有交互的数据都在这个连接里传输。连接可以是按需连接,调用结束后就断掉,也可以是长连接,多个远程调用共享同一个连接。
2.要解决寻址的问题,也就是说,A服务器上的应用怎么怎么告诉底层的 RPC 框架,如何连接到 B 服务器(如主机或IP地址)以及特定的端口,方法的名称是什么,这样才能完成调用。比如基于Wbe服务协议栈的RPC,就要提供一个endpoint URl, 或者是 UDDI服务上查找。如果是RMI调用的话,还需要一个RMI Registry 来注册服务的地址。
3.当A服务器上的应用发起远程过程调用时,方法的参数需要通过底层的网络协议如TCP传输到B服务器。由于网络协议是基于二进制的,内存中的参数的值要序列化成二进制形式,也就是序列化(Serialize) 或编组(marshal),通过寻址和传输序列化的二进制发送给B服务器。
4.B服务器收到请求后,需要对参数进行反序列化(序列化的逆操作),恢复为内存中的表达方式,然后找到对应的方法(寻址的一部分)进行本地调用,然后得到返回值。
5.返回值还要发送回服务器A上的应用,也要经过序列化的方式发送,服务器A接收到后,再反序列化,恢复为内存中的表达方式,交给A服务器上的应用。
3.为什么要使用RPC?
就是无法在一个进程内,甚至一个计算机内通过本地调用的方式完成需求,比如不同的系统间的通讯,甚至不同的组织间的通讯。由于计算能力需要横向扩展,需要在多台机器组成的集群上部署应用。
4.常见的RPC框架
| 功能 | Hessian | Montan | rpcx | gRPC | Thrift | Dubbo | Dubbox | Spring Cloud |
|---|---|---|---|---|---|---|---|---|
| 开发语言 | 跨语言 | Java | Go | 跨语言 | 跨语言 | Java | Java | Java |
| 分布式(服务治理) | × | √ | √ | × | × | √ | √ | √ |
| 多序列化框架支持 | hessian | √(支持Hessian2、Json,可扩展) | √ | × 只支持protobuf) | ×(thrift格式) | √ | √ | √ |
| 多种注册中心 | × | √ | √ | × | × | √ | √ | √ |
| 管理中心 | × | √ | √ | × | × | √ | √ | √ |
| 跨编程语言 | √ | ×(支持php client和C server) | × | √ | √ | × | × | × |
| 支持REST | × | × | × | × | × | × | √ | √ |
| 关注度 | 低 | 中 | 低 | 中 | 中 | 中 | 高 | 中 |
| 上手难度 | 低 | 低 | 中 | 中 | 中 | 低 | 低 | 中 |
| 运维成本 | 低 | 中 | 中 | 中 | 低 | 中 | 中 | 中 |
| 开源机构 | Caucho | Apache | Apache | Alibaba | Dangdang | Apache |
5.实际的场景中的选择
# Spring Cloud : Spring全家桶,用起来很舒服,只有你想不到,没有它做不到。可惜因为发布的比较晚,国内还没出现比较成功的案例,大部分都是试水,不过毕竟有Spring作背书,还是比较看好。
# Dubbox: 相对于Dubbo支持了REST,估计是很多公司选择Dubbox的一个重要原因之一,但如果使用Dubbo的RPC调用方式,服务间仍然会存在API强依赖,各有利弊,懂的取舍吧。
# Thrift: 如果你比较高冷,完全可以基于Thrift自己搞一套抽象的自定义框架吧。
# Montan: 可能因为出来的比较晚,目前除了新浪微博16年初发布的,
# Hessian: 如果是初创公司或系统数量还没有超过5个,推荐选择这个,毕竟在开发速度、运维成本、上手难度等都是比较轻量、简单的,即使在以后迁移至SOA,也是无缝迁移。
# rpcx/gRPC: 在服务没有出现严重性能的问题下,或技术栈没有变更的情况下,可能一直不会引入,即使引入也只是小部分模块优化使用。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK