

P3Depth: Monocular Depth Estimation with a Piecewise Planarity Prior - 抚琴尘世...
source link: https://www.cnblogs.com/haifwu/p/17009081.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

1. 论文简介
论文题目:P3Depth: Monocular Depth Estimation with a Piecewise Planarity Prior
Paper地址:paper
Code地址:Github
Paper简单评论:个人觉得是2022 CVPR上depth estimation最有阅读价值的论文,它不同于之前的所有论文:1. 将几何先验用深度神经网络表达出来;2.算是开创了几何的新用法;3.共面这个特性到是不属于新东西,但作者想法奇妙。
3D场景中含有高度规律(high regularity),作者就想着是否可以利用这种规律来提升深度估计。
特别地,我们引入了分段平面先验,即对于每个像素,都有一个与前者共享相同平面3D曲面的种子像素;
在此基础上,我们设计了一个具有两个head的网络。
第一个head输出像素级平面系数,而第二个head输出密集偏移向量场,用于识别种子像素的位置。
然后利用种子像素的平面系数来预测每个位置的深度。
由此产生的预测自适应地与来自第一个头部的初始预测相融合,通过学习置信度来解释精确局部平面度的潜在偏差。
由于所提出模块的可微分性,整个体系结构是端到端训练的,它学习预测规则深度映射,在咬合边界处具有锐利的边缘。

大多数监督方法使用像素级损失,分别处理不同像素的预测。这种机制忽略了真实世界3D场景的高度规律性,这通常会产生分段平滑的深度图。
建模真实3D场景的几何先验知识的一个常见选择是平面。
平面是局部可微深度映射的局部一阶泰勒近似,它们很容易用三个独立系数参数化。
一旦一个像素与一个平面相关联,它的深度可以从像素的位置和相关平面的系数中恢复。在[83]中,这样的平面系数表示被用来学习显式地预测平面。

我们采用了[83]中的平面表示,但我们脱离了平面的显式预测,而是使用这种表示作为适当的输出空间,用于定义基于平面先验的像素之间的相互作用。
特别是,我们的网络的第一个头部输出密集 平面系数图,再转换为深度图,如图2所示。预测平面系数的动机是,两个像素p和q属于同一个平面,理想情况下具有相等的平面系数表示,而它们通常具有不同的深度。
因此,使用q的平面系数表示来预测p位置的深度,如果像素属于同一平面,则可以正确预测。


我们通过学习识别与被检查像素共享同一平面的种子像素来利用这一性质,只要这些像素存在,就可以选择性地使用这些像素的平面系数来改善预测深度。
这种方法是由分段平面先验驱动的,它表明对于每个具有相关3D平面的像素p,在p的邻域中有一个与p关联的种子像素q。要用这种方案预测深度,我们需要通过预测偏移量q−p来识别(i)先验有效的区域和(ii)这些区域中的种子像素。
通过对融合深度预测的监督,隐式地应用了偏移量和置信图的监督。由于使用种子像素进行预测,我们的模型隐式地学习根据像素在深度图平滑区域中的隶属度对像素进行分组。这有助于保存尖锐的深度不连续,如图1所示。
最后但并非最不重要的是,我们提出了平均平面损失,它加强了我们预测的3D表面与地面真相的一阶一致性,并进一步提高了性能。

4 相关工作
Supervised monocular depth estimation
假设地面真实深度图可用于训练图像,并需要对单个图像进行推断。一个著名的早期方法是Make3D[59],它在场景中显式手工制作一个分段平面结构,并使用马尔可夫随机场在局部学习相关参数。
[9]的多尺度网络通过学习从图像到深度图的端到端映射,开创了深度cnn在深度估计中的使用。后来有几项工作专注于这一设置,提出了i.a
(i)更高级的架构,如残差网络[32],卷积神经场[43,73],频域多尺度融合[34],基于变压器的块,参与全局深度统计[1]和深度合并网络处理多分辨率[50],
(ii)更适合深度预测的损失,如反向Huber损失[32]、分类损失[3]、有序回归损失[12]、两两排序损失[71]和几种深度相关损失[35]的自适应组合,以及
(iii)深度与法线或语义标签的联合学习[8,53,72]。[78]通过将3D点云编码器应用于提升的深度图,解决了混合数据设置中深度偏移和焦距刻度的模糊性。
我们的方法属于这一类,它将深度预测投射到更合适的空间,以挖掘输入场景的规律。

Other depth estimation setups
包括无监督和半监督单目深度估计,以及基于立体的深度估计。在[16]中引入了基于新型视图合成[10]的立体对深度无监督学习,该合成使用了一种图像重建损失,其中预测的深度用于将对中的一幅图像扭曲到另一幅图像的框架中,并在[18]中以完全可微的公式进行了转换。
这一方向的进一步研究利用了时间信息[47,52,82]。在该框架中对立体对的需求在[85]中得到了提升,它适用于单目视频。在[27,40,48]中强制了估计的3D结构和跨视频帧的自我运动的一致性。
深度和自我运动在[26,79]中结合了光流和语义,在[76]中结合了边缘。在[19]中实现了跨视频帧遮挡的鲁棒性,并具有最小的重投影损失。在[20,61]中,专门的损失促进了优化。
最近的方法利用了测试时的视频输入[69]、分割输出的一致性[86]以及相邻帧之间的缩放一致性[67]。无监督方法通常假设比有监督方法更复杂的训练数据,并且存在规模模糊和违反兰伯假设。在[29]中引入了半监督深度估计,它将稀疏深度测量与图像重建损失相结合。
在[39]中,对存在的特定于数据集的假设和深度监测格式的特定数据集假设也有所放宽,它利用多视图图像收集来生成可靠的大规模深度监测,而在[56]中,利用不同的数据集为单目深度估计提供不同形式的监督,以更好地泛化未见数据。早期的立体声方法依赖于手工制作的匹配成本[22]来估计视差。最初学习匹配函数的方法包括[30,65],而后续的工作依赖于全卷积架构[5,49]。在训练和测试中,立体方法也以立体对的形式假设更复杂的数据,这阻止了它们应用于更一般和不受控制的单目设置。


Geometric priors for depth
在文献中被广泛研究过。特别是在多视图立体[14]和三维重建中,传统上采用分段平面先验[2,6],以使这些问题能够更快地优化。这些方法涉及显式深度平面,并将这些平面拟合到图像超像素或输入点云的点集上。
超像素级深度平面也用于深度去噪和补全[58,66]。在最近的基于深度学习的方法中,几何先验的合并要么通过分割平面显式执行[36,41,42,81],要么通过适当设计损失隐式执行[80]。
在[77]的虚拟法线框架中利用非局部3D上下文,使用来自虚拟平面的监督,这些虚拟平面对应于深度图的非共线点的三元组。在[23]网络中通过深度注意体积嵌入非局部共面性约束。
在[46]中使用表面法线来增加规则结构的几何一致性。[74,83]中使用了一种与图像空间中3D平面系数直接相关的表示,而不依赖于相机的内在参数,用于估计场景中的主导深度平面。
[33]采用同样的平面系数表示法指导深度网络解码器部分的上采样模块,达到了最先进的性能。
我们也将这种表示法用于平面系数,但与[74,83]相反,我们学习它时不需要对平面进行注释。相反,我们优化平面系数和空间偏移向量,以学习识别共面像素,并使用这种共面性来预测深度。
虽然偏移向量在[54]中也用于仅通过重新采样预测的后处理深度,但我们将偏移向量合并到单个端到端架构中,并通过与偏移指向的种子像素相关联的平面插值生成预测。
我们的方法松散地受到[51]的启发,它训练偏移向量来从带注释的图像中识别实例分割中心,而我们专注于深度预测,并在没有监督的情况下对平面实例进行操作


5.1 Preliminaries
单目深度估计的基本定义,输入一副图像,使用一个映射函数,估计每一个像素位置到相机的距离。

全文的关键,建模深度图到3D场景点的映射过程,为后面法线和平面系数奠定基础。

5.2 Plane Coefficient Representation for Depth
最核心的东西来了。
给定相邻的3D points,我们假定他们处于同一个平面上,那么位于该平面上的点应该具有相同的平面法向量。
由此,![]() ,这个公式应当成立。将公式2中的点带进来,可以推导出公式3:
,这个公式应当成立。将公式2中的点带进来,可以推导出公式3:
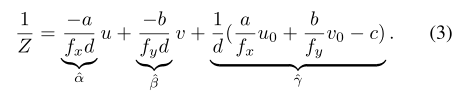
接下来,对公示3进行换元![]() ,
,![]() ,
,![]() ,然后公式3简化为公式4:
,然后公式3简化为公式4:
![]()
Z在公式2中表示的深度,根据公式4可以看出,若![]() 看成平面系数,求depth map的过程,其实是求解平面系数的过程。
看成平面系数,求depth map的过程,其实是求解平面系数的过程。
是否是神经网络中间过程输出平面系数即可,而不直接输出depth map,因为有了平面系数一个公式就能得到depth map。
似乎一切看着都很合理。
其实这就是这篇论文看着玄乎的地方,认真的思考感觉也没啥东西在里面。



5.3 Learning to Identify Seed Pixels
这种间接预测方式比直接预测depth map会更好吗?
答案是否定的,不仅作者这么认为,我也认为,我能一步到位为啥要两步。
接下来告诉你为什么:
若p属于平面A,那么是不是其他位于该平面的像素应该共享同一个平面系数C。
当预测得到这个平面的种子像素的平面系数后,是不是这个平面所有像素的平面系数也就得到了。
作者认为这个是有意义的。
但我觉得他仍然预测了所有像素的平面系数,没啥差别。
这点说实话不太理解。
继续,因此接下来假设网络会去主动找那个种子像素,然后,其他和种子像素只差一个偏移量。
由此公式5定义了每个像素的平面系数等于种子像素的平面系数加上一个偏移量。







5.3 Mean Plane Loss
除了公式(7)和(8)两个Loss之外,作者还计算了一个平面Loss,该Loss本质计算了局部平面的法线损失。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK