

Go 学习笔记3-Go数据类型
source link: https://codeshellme.github.io/2022/06/go3/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

1,基本数据类型
- 布尔类型
bool,默认值FALSE - 字符串类型
string,默认""- 字符串类型是不可变的,提高了字符串的并发安全性和存储利用率
- 其底层存储的是 byte 类型数组
- len() 函数可以返回其包含的 byte 数,一个英文字母是 1 个 byte,一个汉字是 3 个 byte
- 可以将 string 转为 rune 类型的数组
[]rune(s),s是 string 类型的变量 - Go 的 strings 包中有很多字符串相关操作函数
- Go 的 strconv 包中有很多字符串转换函数,比如:
strconv.Itoa:将数字转成字符串strconv.Atoi:将字符串转成数字
- 整数类型,默认值是
0byterune:字符类型,存储的是 Unicode 字符- 其本质上是
int32的别名;type rune = int32 - len() 函数可以返回其包含的字符数,一个英文字母和一个汉字的长度都是 1 个字符
- 其本质上是
int/uint:在 32 位机器上占 32 位,在 64 位机器上占 64 位- 这两个是平台相关的:在编写有移植性要求的代码时,不要依赖这些类型的长度
int8/uint8:占 8 位,1 个字节(平台无关)- 取值范围:
[-128, 127]/[0, 255]
- 取值范围:
int16/uint16:占 16 位,2 个字节(平台无关)- 取值范围:
[-32768, 32767]/[0, 65535]
- 取值范围:
int32/uint32:占 32 位,4 个字节(平台无关)- 取值范围:
[-2147483648, 2147483647]/[0, 4294967295]
- 取值范围:
int64/uint64:占 64 位,8 个字节(平台无关)- 取值范围:
[-9223372036854775808, 9223372036854775807]/[0, 18446744073709551615]
- 取值范围:
- 浮点数类型:默认值是
0.0float32float64
- 复数类型
complex64complex128
高级数据类型:默认值是 nil
- 数组
array:是一个有着固定长度的、一组同类型数据组成- 数组的下标从 0 开始,不能为负值,且不能超出数组长度范围
- 数组的缺点:固定的元素个数,以及传值机制下导致的开销较大
- 切片可以弥补数组的这两个缺点
- 切片
slice - 字典
map - 通道
channel - 结构体
struct - 接口
interface - 指针(
*Xxx,unsafe.Pointer,uintptr) - 函数
function
注意:Go 中并没有 Set 类型,可以用
map[key_type]bool来实现它。
整数溢出问题:
var s int8 = 127s += 1 // 预期128,实际结果-128var u uint8 = 1u -= 2 // 预期-1,实际结果255字符串类型是不可变的:
var s string = "hello"s[0] = 'k' // 错误:字符串的内容是不可改变的s = "gopher" // okGo 中的数组结构:
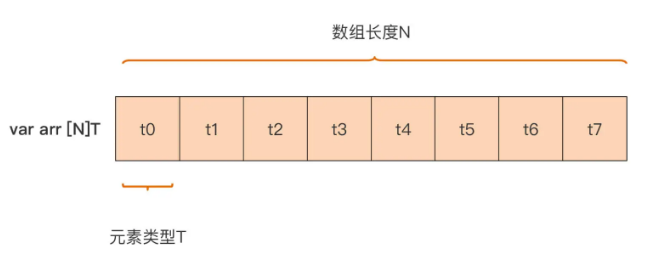
数组的定义:
// N 必须是整型数字面值或常量表达式,其值必须是确定的var arr [N]T// a 与 b 是不同的类型var a [3]int // 如果不进行显示初始化,那么值就是 0 值var b [5]intlen(a) // len 函数用于计算数组的长度unsafe.Sizeof(a) // 用于计算 a 所占空间大小// 显示初始化数组的三种方式var arr2 = [6]int { 11, 12, 13, 14, 15, 16,} // [11 12 13 14 15 16]var arr3 = [...]int { // 可以将 N 用 ... 替代,Go 会自己推算长度 21, 22, 23,} // [21 22 23]fmt.Printf("%T\n", arr3) // [3]intvar arr4 = [...]int{ 99: 39, // 将第100个元素(下标值为99)的值赋值为39,其余元素值均为0fmt.Printf("%T\n", arr4) // [100]intGo 值传递的机制让数组在各个函数间传递起来比较“笨重”,开销较大,且开销随数组长度的增加而增加。为了解决这个问题,Go 引入了切片这一不定长同构数据类型。
数组的遍历
// 方法 1for i := 0; i < len(arr); i++ { // arr[i]// 方法 2 for index, value := range arr {// index 可省略for _, value := range arr {数组的截取:
- 语法:
arr[i, j],包含开始索引i,不包含结束索引j - 注意
i, j不能是负数
arr := [...]{1, 2, 3, 4, 5}arr[1:2] // 2arr[1:3] // 2, 3arr[1:len(arr)] // 2,3,4,5arr[1:] // 2,3,4,5arr[:3] // 1,2,3arr[:] // 1,2,3,4,5切片可以提供比指针更为强大的功能,比如下标访问、边界溢出校验、动态扩容等。而且,指针本身在 Go 语言中的功能也受到的限制,比如不支持指针算术运算。
Go 中的切片类型:
type slice struct { array unsafe.Pointer len int cap int- array: 是指向底层数组的指针
- len: 是切片的长度,即切片中当前元素的个数
- 当访问下标大于等于 len 时的元素时,会报数组越界
- cap: 是底层数组的长度,也是切片的最大容量,cap 值永远大于等于 len 值
切片的定义:
// 与数组的不同是,切片不需要显示的长度,但切片也有长度// 切片的长度是变化的,可以用 len() 函数计算切片的长度var n = []int{1, 2, 3, 4, 5}// 使用 append 函数向切片中添加元素n = append(n, 6) // 切片变为[1 2 3 4 5 6]切片的底层是一个数组,其结构如下:
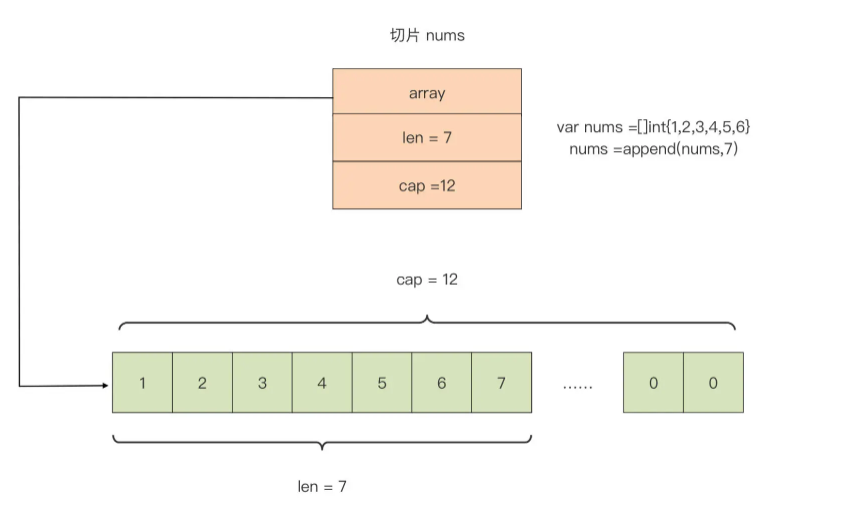
创建切片的其它方式:
1,通过 make 函数,创建切片,并指定底层数组的长度。
sl := make([]byte, 6, 10) // 其中10为cap值,即底层数组长度,6为切片的初始长度 // 切片中前 6 个元素的值是 byte 类型的零值,未初始化的元素不能访问// 如果没有在 make 中指定 cap 参数,那么底层数组长度 cap 就等于 lensl := make([]byte, 6) // cap = len = 62,采用 array[low : high : max] 语法基于一个已存在的数组创建切片,这种方式被称为数组的切片化。
我们在进行数组切片化的时候,通常省略 max,而 max 的默认值为数组的长度。
arr := [10]int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}sl := arr[3:7:9]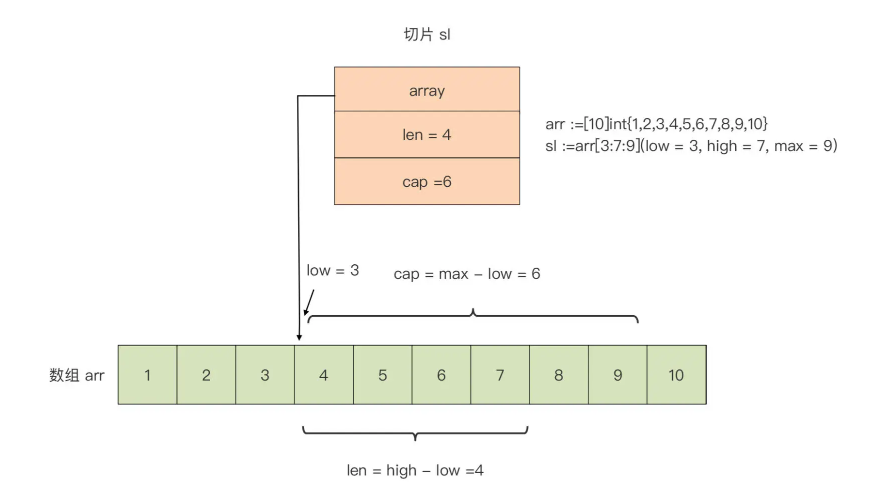
基于数组创建的切片:
- 它的起始元素从 low 所标识的下标值开始
- 切片的长度(len)是 high - low
- 它的容量是 max - low
由于切片 sl 的底层数组就是数组 arr,对切片 sl 中元素的修改将直接影响数组 arr 变量。比如,将切片的第一个元素加 10,那么数组 arr 的第四个元素将变为 14:
sl[0] += 10fmt.Println("arr[3] =", arr[3]) // 14切片好比打开了一个访问与修改数组的“窗口”,通过这个窗口,我们可以直接操作底层数组中的部分元素。
这类似于操作文件之前打开的“文件描述符”,通过文件描述符我们可以对底层的真实文件进行相关操作。
可以说,切片之于数组就像是文件描述符之于文件。
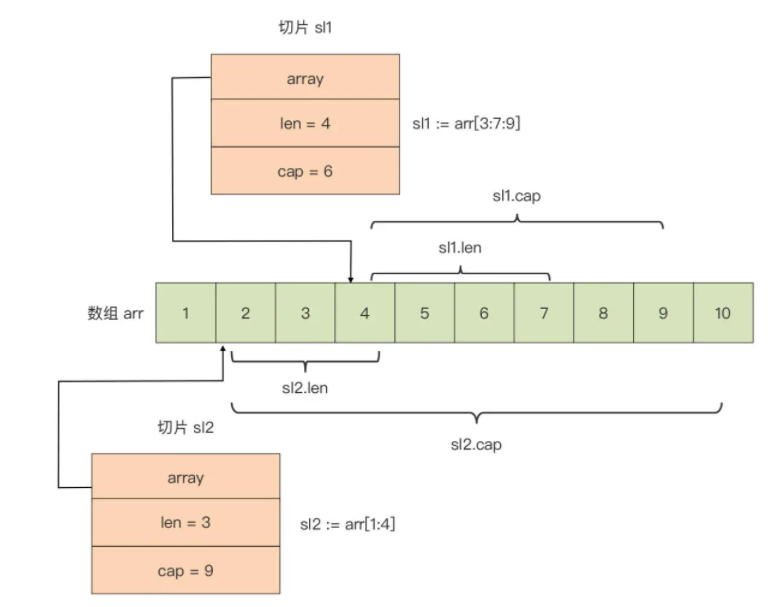
针对一个已存在的数组,可以建立多个操作数组的切片,这些切片共享同一底层数组,切片对底层数组的操作也同样会反映到其他切片中。
下面是为数组 arr 建立的两个切片的内存表示:
切片的动态扩容
“动态扩容”指的是,当通过 append 操作向切片追加数据的时候,如果这时切片的 len 值和 cap 值是相等的,也就是说切片底层数组已经没有空闲空间再来存储追加的值了,Go 运行时就会对这个切片做扩容操作,来保证切片始终能存储下追加的新值。
动态扩容时,会新建一个更大的数组,append 会把旧数组中的数据拷贝到新数组中,之后新数组便成为了切片的底层数组,旧数组会被垃圾回收掉。
如果在 for-loop 里对某个 slice 使用 append(),请先把 slice的容量很扩充到位,这样可以避免内存重新分享以及系统自动按2的N次方幂进行扩展但又用不到,从而浪费内存。
正因为 append 会动态扩容,并创建新的内存空间,所以 append 的正确使用姿势是:
sl = append(s1, item) // 要接收返回值错误的使用姿势:
append(s1, item) // 不接收返回值是错误的基于数组的切片的动态扩容问题
基于一个已有数组建立的切片,一旦追加的数据操作触碰到切片的容量上限(也是数组容量的上界),切片就会和原数组解除“绑定”,此时,会新创建一个底层数组,并将切片的元素拷贝到新数组中,后续对切片的任何修改都不会反映到原数组中了。
切片的遍历
// 方法 1for i := 0; i < len(slice); i++ { //slice[i]// 方法 2for index, value := range slice {// index 可省略for _, value := range slice {一道思考题
下面两个切片的区别:
var s1 []int // len(s1) == cap(s1) == 0var s2 = []int{} // len(s2) == cap(s2) == 0println(s1 == nil) // trueprintln(s2 == nil) // false- s1是声明,还没初始化,是nil值,底层没有分配内存空间
- 这意味着针对 s1 做操作的时候同时初始化
- 例如sl1 = append(sl1, 1),这个语句的操作就是先初始化一个长度为1的空间,然后把 “1”填入这个空间中
- s2初始化了,不是nil值,底层分配了内存空间,有地址
- 例如,sl2 = append(sl2, 2),这个语句就是直接将“2”这个值填入到已初始化的空间中
- go官方推荐使用 var sl1 []int
- 在 goland 开发时,第二种声明方式会出现黄色下划线,提示需要改动
4,map
Go 中 map 的定义方式:
// 包含了 key 类型和 value 类型map[key_type]value_type如果两个 map 类型的 key 元素类型相同,value 元素类型也相同,那么我们可以说它们是同一个 map 类型,否则就是不同的 map 类型。
map[string]string // key 与 value元素的类型相同map[int]string // key 与 value元素的类型不同map 类型对 value 的类型没有限制,但对 key 的类型却有严格要求,因为 map 类型要保证 key 的唯一性。Go 语言中要求,key 的类型必须支持==和!=两种比较操作符。
在 Go 语言中,函数类型、map 类型自身,以及切片只支持与 nil 的比较,而不支持同类型两个变量的比较。如下所示:
s1 := make([]int, 1)s2 := make([]int, 2)f1 := func() {}f2 := func() {}m1 := make(map[int]string)m2 := make(map[int]string)println(s1 == s2) // 错误:invalid operation: s1 == s2 (slice can only be compared to nil)println(f1 == f2) // 错误:invalid operation: f1 == f2 (func can only be compared to nil)println(m1 == m2) // 错误:invalid operation: m1 == m2 (map can only be compared to nil)因此,一定要注意:函数类型、map 类型自身,以及切片类型是不能作为 map 的 key 类型的。
map 的声明
var m map[string]int // 一个 map[string]int 类型的变量和切片类型变量一样,如果我们没有显式地赋予 map 变量初值,map 类型变量的默认值为 nil。
初值为零值 nil 的切片类型变量,可以借助内置的 append 的函数进行操作,这种在 Go 语言中被称为“零值可用”。
但 map 类型,因为它内部实现的复杂性,无法“零值可用”。所以,如果我们对处于零值状态的 map 变量直接进行操作,就会导致运行时异常(panic),从而导致程序进程异常退出:
var m map[string]int // m = nilm["key"] = 1 // 发生运行时异常:panic: assignment to entry in nil map所以,必须对 map 类型变量进行显式初始化后才能使用。
map 的声明初始化
和切片一样,为 map 类型变量显式赋值有两种方式:
- 使用复合字面值
- 使用 make 函数
使用复合字面值
// 这里,显式初始化了 map 类型变量 m// 此时 m 中没有任何键值对,但 m 也不等同于初值为 nil 的 map 变量// 这时对 m 进行键值对的插入操作,不会引发运行时异常m := map[int]string{} // 空 mapm1 := map[int]string{1:"a", 2:"b"} // 非空 map使用 make 函数
通过 make 函数,可以指定 map 的初始容量,但无法进行具体的键值对赋值:
m1 := make(map[int]string) // 未指定初始容量m2 := make(map[int]string, 8) // 指定初始容量为 8map 类型的容量不会受限于它的初始容量值,当其中的键值对数量超过初始容量后,Go 运行时会自动增加 map 类型的容量,保证后续键值对的正常插入。
map 的插入操作
// map 的插入操作m := make(map[int]string)m[1] = "value1"m[2] = "value2"m[3] = "value3"m[1] = "value5" // 会覆盖原来的 value1len(m) // len 函数可以计算 map 的长度 // cap 函数不能用于 map 类型获取 map 中的值
m := make(map[string]int)// 获取 map 中的值// 如果 key1 存在与 map 中,则返回其对应的 value// 如果 key1 不存在,也不会报错,会返回 value 元素的 0 值v := m["key1"] // 下面方法可判断 key1 是否存在于 map 中// 返回的 ok 是一个布尔类型v, ok := m["key1"]if !ok { // "key1"不在map中// "key1"在map中,v将被赋予"key1"键对应的value // 如果不关心某个键对应的 value,而只关心某个键是否在于 map 中// 我们可以使用空标识符替代变量 v,忽略可能返回的 value_, ok := m["key1"]map 的删除操作
// 使用 delete 函数进行删除delete(m, "key1") map 的遍历操作
// 使用 range 进行遍历for k, v := range m { fmt.Printf("[%d, %d] ", k, v) // 如果不关心值,也可以这样for k, _ := range m { // 使用k// 只遍历 keyfor k := range m { // 使用k// 只关心 valuefor _, v := range m { // 使用v对同一 map 做多次遍历的时候,每次遍历元素的次序都不相同。这是 Go 语言 map 类型的一个重要特点,所以一定要记住:程序逻辑千万不要依赖遍历 map 所得到的的元素次序。
如果 map 中的 key 或 value 的数据长度大于一定数值,那么运行时不会在 map 中直接存储数据,而是会存储 key 或 value 数据的指针。目前 Go 运行时定义的最大 key 和 value 的长度是这样的:
// $GOROOT/src/runtime/map.goconst ( maxKeySize = 128 maxElemSize = 128map 与并发
map 实例不是并发写安全的,也不支持并发读写。如果对 map 实例进行并发读写,程序运行时就会抛出异常。
fatal error: concurrent map iteration and map write这里的并发读写,指的是同时进行读和写,会出现异常 如果只是并发读,则不会发生异常 Go 1.9 版本中引入了支持并发写安全的 sync.Map 类型
5,type
type 用于创建自定义数值类型。
本质上相同的两个类型,它们的变量可以通过显式转型进行相互赋值,相反,如果本质上是不同的两个类型,它们的变量间连显式转型都不可能,更不要说相互赋值了。
// MyInt 的底层类型是 init32// 它的数值性质与 int32 完全相同// 但它们仍然是完全不同的两种类型type MyInt int32var m int = 5var n int32 = 6var a MyInt = m // 错误:在赋值中不能将m(int类型)作为MyInt类型使用var a MyInt = n // 错误:在赋值中不能将n(int32类型)作为MyInt类型使用// 需要经过显示转换var a MyInt = MyInt(m) // okvar a MyInt = MyInt(n) // ok类型定义也支持通过 type 块的方式进行:
type ( T1 int T3 string第二种方式,类型别名(并没有定义出新的类型,而只是一个别名):
// MyInt 与 int32 完全等价,所以这个时候两种类型就是同一种类型type MyInt = int32var n int32 = 6var a MyInt = n // ok6,struct
定义一个结构体 Book:
type Book struct { Title string // 书名 Pages int // 书的页数 Indexes map[string]int // 书的索引空结构体
一个空结构体,是没有包含任何字段的结构体:
type Empty struct{} // Empty是一个不包含任何字段的空结构体类型空结构体的大小是 0:
var s Emptyprintln(unsafe.Sizeof(s)) // 0基于空结构体类型内存零开销这样的特性,在 Go 开发中会经常使用空结构体类型元素,作为一种“事件”信息进行 Goroutine 之间的通信,如下:
var c = make(chan Empty) // 声明一个元素类型为Empty的channelc<-Empty{} // 向channel写入一个“事件”这种以空结构体为元素类建立的 channel,是目前能实现的、内存占用最小的 Goroutine 间通信方式。
来看下面这种代码:
// 自定义了 Person 类型type Person struct { Name string Phone string Addr string// 自定义了 Book 类型type Book struct { Title string Author Person // Person 类型为 Book 类型的内部元素 ... ...// 访问 Book 结构体字段 Author 中的 Phone 字段var book Book println(book.Author.Phone)Go 还提供了以下方式来定义 Book:
type Book struct { Title string Person // 只有类型,而没有变量名 ... ...以这种方式定义的结构体字段,叫做嵌入字段。我们也可以将这种字段称为匿名字段,或者把类型名看作是这个字段的名字。
如果我们要访问 Person 中的 Phone 字段,我们可以通过下面两种方式进行:
var book Book println(book.Person.Phone) // 将类型名当作嵌入字段的名字println(book.Phone) // 支持直接访问嵌入字段所属类型中字段结构体类型变量的声明
type Book struct {// 四种声明方式var book Book // 普通的声明方式,book为零值结构体变量var book = Book{} // Go 自推断类型book := Book{} // 短变量声明// 也可以使用 new 函数来创建结构体对象,但这种方式很少使用// 注意:new 返回的是指针类型book := new(Book)Go 结构体类型由若干个字段组成,当这个结构体的各个字段的值都是零值时,我们就说这个结构体类型变量处于零值状态。
用复合字面值初始化结构体变量
type Book struct { Title string // 书名 Pages int // 书的页数 Indexes map[string]int // 书的索引// 按照结构体中变量的顺序初始化var book = Book{"The Go Programming Language", 700, make(map[string]int)}事实上,Go 语言并不推荐我们按字段顺序对一个结构体类型变量进行显式初始化,而是推荐使用field:value的形式:
// 这种初始化方式,使得字段可以以任意次序出现// 未显式出现在字面值中的字段(比如 F5)将采用它对应类型的零值var t = T{ F2: "hello", F1: 11, F4: 14,结构体中的内存对齐问题(跟 C语言一样)
由于内存对齐的要求,结构体类型各个相邻字段间可能存在“填充物”,结构体的尾部同样可能被 Go 编译器填充额外的字节,满足结构体整体对齐的约束。
正是因为这点,我们在定义结构体时,一定要合理安排字段顺序,要让结构体类型对内存空间的占用最小。
比如下面例子:
type T struct { b byte i int64 u uint16该类型 T 的内存布局是这样的:
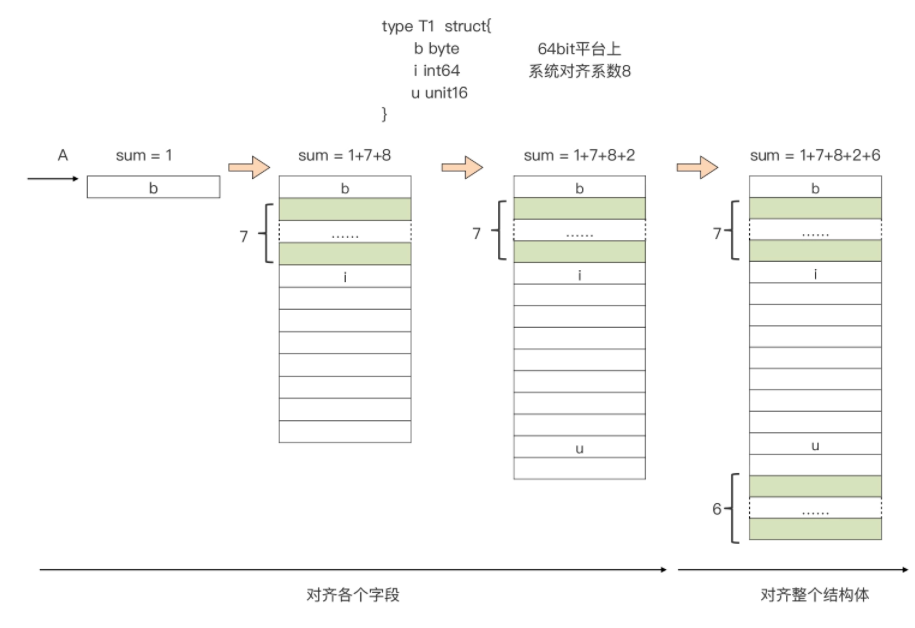
不同的排序顺序,导致了最终占用内存大小的不同:
type T struct { b byte i int64 u uint16type S struct { b byte u uint16 i int64func main() { var t T println(unsafe.Sizeof(t)) // 24 var s S println(unsafe.Sizeof(s)) // 167,复杂类型的比较
复杂类型的比较可称为深度比较(不同于浅比较),需要用到 reflect.DeepEqual(),示例:
import ( "fmt" "reflect"func main() { m1 := map[string]string{"one": "a","two": "b"} m2 := map[string]string{"two": "b", "one": "a"} fmt.Println("m1 == m2:",reflect.DeepEqual(m1, m2)) //prints: m1 == m2: true s1 := []int{1, 2, 3} s2 := []int{1, 2, 3} fmt.Println("s1 == s2:",reflect.DeepEqual(s1, s2)) //prints: s1 == s2: trueRecommend
-
9
winter老师的重学前端真的是一门很好的课程,看了第一课,收获颇多,填了很多Js类型的坑,总结如下。 Undefined Boolean String Number Symbol Object b...
-
8
python学习笔记001-python中变量数据类型和分支结构
-
5
C++ Primer学习笔记02:基本内置类型 Posted on 2022-03-10...
-
7
C++ Primer学习笔记04:复合类型 Posted on 2022-03-29...
-
6
本文主要是我在看《疯狂Java讲义》时的读书笔记,阅读的比较仓促,就用 markdown 写了个概要。 第一章 Java概述Java SE:(Java Platform, Standard Edition)整个Java技术的核心和基础,它是Java ME和Java EE编程的基础。
-
7
-
8
类型嵌入指的就是在一个类型的定义中嵌入了其他类型。Go 语言支持两种类型嵌入: 接口类型的类型嵌入 结构体类型的类型嵌入 接口类型只能嵌入接口类型,而结构体类型对嵌入类型的要求就比较宽泛了,可以是任意自定义类...
-
2
跟随【导师不教?我来教!】同济计算机博士半小时就教会了我五大深度神经网络,CNN/RNN/GAN/transformer/LSTM一次学...
-
2
MySQL学习笔记:数据类型-字段选型 精选 原创 chenlbbb 2023-04-28 18...
-
3
复杂数据类型 特点:多个数据变量地一个集合体,可以自己命名 种类:枚举、数组和结构体 枚举:整型常量的集合 数组:任意变量类型的顺序存储的数据集合 结构...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK