

直接开源!阿里公布下一代“杀手锏”语音识别模型
source link: http://www.dostor.com/p/82322.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

直接开源!阿里公布下一代“杀手锏”语音识别模型-存储在线
12月22日,阿里巴巴达摩院发布新一代语音识别模型Paraformer,该模型为业界首个应用落地的非自回归端到端语音识别模型,在推理效率上最高可较传统模型提升10倍,且识别准确率在多个权威数据集上名列第一。目前,该模型于魔搭平台面向全社会开源,适用语音输入法、智能客服、车载导航、会议纪要等众多场景。
语音作为最自然的交流途径, 一直是人机交互重要研究领域。当前语音识别基础框架已从最初复杂的混合语音识别系统,演变为高效便捷的端到端语音识别系统。其中最具代表性的模型是自回归端到端模型Transformer,它在识别过程中需逐个生成目标文字,实现了较高准确率,但计算并行度低,无法高效结合GPU进行推理。
针对该问题,学术界近年提出并行输出目标文字的非自回归模型,然而其建模难度和计算复杂度高,准确率一直有待提升。
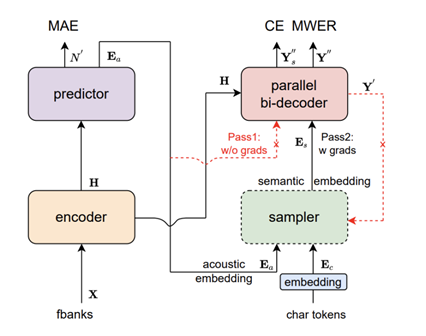
达摩院本次推出的新一代语音识别模型Paraformer,首次在工业级应用层面解决了端到端识别效果与效率兼顾的难题。Paraformer为单轮非自回归模型,达摩院团队通过创新的预测器设计,实现对目标文字个数及对应声学隐变量的高准确度预测,并引入机器翻译领域的浏览语言模型思路,显著增强了模型对上下文语义的建模。同时,Paraformer使用长达数万小时、覆盖丰富场景的超大规模工业数据集进行训练,进一步提升了识别准确率。
在学术界常用的中文识别评测任务AISHELL-1、AISHELL-2及WenetSpeech等测试集上, Paraformer-large模型均获得了最优的效果。在专业的第三方全网公共云中文语音识别评测SpeechIO TIOBE白盒测试中,Paraformer-large识别准确率超过98%,是目前公开测评中准确率最高的中文语音识别模型。

配合GPU推理,不同版本的Paraformer可将推理效率提升5~10倍,同时,Paraformer使用了6倍下采样的低帧率建模方案,可将计算量降低近6倍,支持大模型的高效推理。
达摩院语音实验室负责人鄢志杰介绍,Paraformer是阿里巴巴研发的下一代“杀手锏”级别的语音识别基础模型,未来将广泛应用于会议纪要产品“听悟”、钉钉语音转文字、高德导航等场景。为尽快惠及中小公司及开发者群体,这款重磅模型“问世即开源”,可于魔搭社区ModelScope体验并下载,企业及个人可进一步开发训练定制化模型。(https://www.modelscope.cn/models/damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch/summary)
据了解,阿里语音团队近年已推出多款重磅语音识别模型,包括首次将识别准确率提升至96%的DFSMN模型、E2E-ASR端到端语音识别技术等。Gartner今年7月发布的《云AI开发者服务关键能力报告》显示,阿里在语音识别项目上评分与谷歌等公司并列全球第一,创中国企业最好成绩。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK